갑자기 난이도가 이렇게 올라가면 어떡합니까 ㅠㅠ
학습시간 09:00~02:00(당일17H/누적445H)
◆ 학습내용
주제
- 딥러닝으로 손상된 문서 복원
목적
- 코드의 각 단계에서 어떤 작업을 수행하는지 어떤 의도를 가지고 접근했는지 명확히 표현
- 분석 과정과 결과를 설명하는 문구를 추가하여 전체 코드의 흐름을 이해할 수 있도록 마크다운 작성
- 모델 정확도 향상(RMSE, PSNR 등의 지표를 활용)
1. 데이터 다운로드
 캐글 문제다. 10년 전 문제이긴 하지만 지금의 내가 성장하기엔 전혀 손색없을 것 같다.
캐글 문제다. 10년 전 문제이긴 하지만 지금의 내가 성장하기엔 전혀 손색없을 것 같다.
 4개의 파일로 되어있다. 서브미션은 뭔지 잘 몰라서 찾아봤는데, 캐글에 제출할 때 따라야하는 양식인 것 같다.
4개의 파일로 되어있다. 서브미션은 뭔지 잘 몰라서 찾아봤는데, 캐글에 제출할 때 따라야하는 양식인 것 같다.
 구김이나 얼룩을 제거해야하는 것 같다. 학습용 파일이 144개 뿐이네. 벌써부터 벽이 느껴진다;;
구김이나 얼룩을 제거해야하는 것 같다. 학습용 파일이 144개 뿐이네. 벌써부터 벽이 느껴진다;;
2. 데이터 로드
from torchvision import datasets
train_dataset = datasets.ImageFolder(root='./mission5/train') ...........ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 세 시간째 폴더 하나 불러오지 못하고 있다. 기존에 배운 방식으로 왜 접근이 안 되지??
...........ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 세 시간째 폴더 하나 불러오지 못하고 있다. 기존에 배운 방식으로 왜 접근이 안 되지??
train_dataset = datasets.ImageFolder(root='C:/Users/yoons/Documents/dev/camp/mission/mission5/train')전체 경로를 가져와나 하나? -> 이것도 실패
결국 찾았는데,, 분류나 회귀가 아닌 복원은 각각 다른 폴더에 데이터가 있는 경우 dataset으로 불러와야 한다고....
class Dataset(Dataset):
def __init__(self, dirty_dir, clean_dir):
self.dirty_dir = dirty_dir
self.clean_dir = clean_dir
self.image_names = sorted(os.listdir(dirty_dir))
self.transform = v2.Compose([
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize(mean=[0.5], std=[0.5])
])
def __len__(self):
return len(self.image_names)
def __getitem__(self, idx):
dirty_path = os.path.join(self.dirty_dir, self.image_names[idx])
clean_path = os.path.join(self.clean_dir, self.image_names[idx])
dirty = Image.open(dirty_path).convert('L')
clean = Image.open(clean_path).convert('L')
dirty = self.transform(dirty)
clean = self.transform(clean)
return dirty, clean
train_dataset = Dataset(dirty_dir='train', clean_dir='train_cleaned')
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
test_load = DataLoader(train_dataset, batch_size=16, shuffle=False)어찌어찌 첨보는 함수도 사용해가며 완성...
import matplotlib.pyplot as plt
dirty, clean = train_dataset[4]
plt.figure(figsize=(10, 10))
plt.subplot(1, 2, 1)
plt.imshow(dirty.squeeze(), cmap='gray')
plt.subplot(1, 2, 2)
plt.imshow(clean.squeeze(), cmap='gray')
plt.show()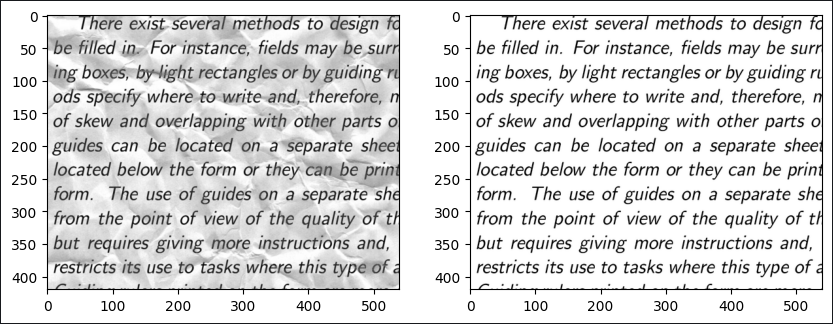 4번 사진을 꺼내봤다. 왼쪽을 오른쪽으로 만드는 게 목표인듯.
4번 사진을 꺼내봤다. 왼쪽을 오른쪽으로 만드는 게 목표인듯.
a, b = next(iter(train_loader)); print(a.shape, b.shape) 쉐입을 보려고 했는데 에러가 떴다. 이미지 사이즈가 전부 동일하지 않은 것 같다. 아, 그동안 28픽셀 32픽셀로 밥상 다 차려진 것만 떠먹었던 것 같다. 어떡하지....?
쉐입을 보려고 했는데 에러가 떴다. 이미지 사이즈가 전부 동일하지 않은 것 같다. 아, 그동안 28픽셀 32픽셀로 밥상 다 차려진 것만 떠먹었던 것 같다. 어떡하지....?
일단 512픽셀로 키우고 해봐야겠다...
self.transform = v2.Compose([
v2.Resize((512, 512)),전처리 부분에 리사이즈 추가!
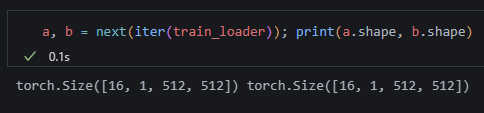 이제 쉐입이 나온다.
이제 쉐입이 나온다.
3. 모델 생성 및 훈련
class AutoEncoder1(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(512*512, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
)
self.decoder = nn.Sequential(
nn.Linear(32, 64),
nn.ReLU(),
nn.Linear(64, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 512*512),
nn.Sigmoid()
)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.encoder(x)
x = self.decoder(x)
return x.view(-1, 1, 512, 512)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = AutoEncoder1().to(device)
summary(model, (16, 1, 512, 512))일단 내가 배운 오토인코더 모델을 넣었다
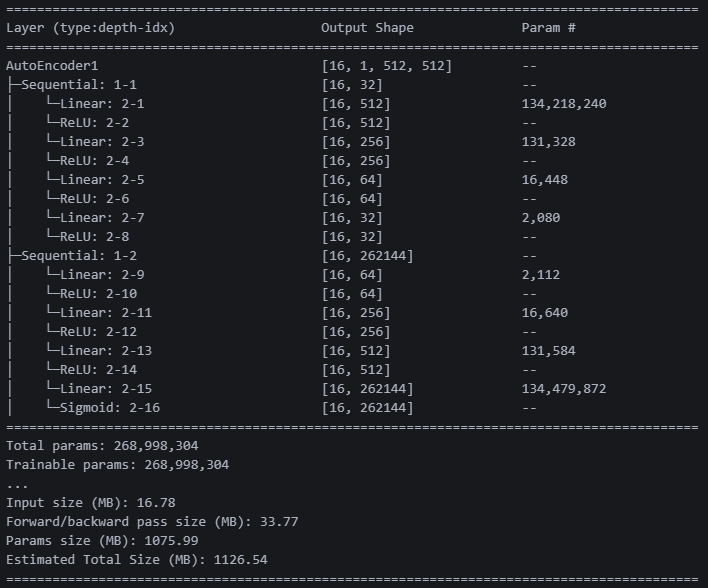 ㅎㅎㅎ 파라미터가 2억7천만 개네요?? 사이즈를 512로 해서 그런 것 같다.
ㅎㅎㅎ 파라미터가 2억7천만 개네요?? 사이즈를 512로 해서 그런 것 같다.
def train_model(model, train_loader, epochs, lr):
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
for epoch in range(epochs):
model.train()
total_loss = 0
for X, y in tqdm(train_loader):
X, y = X.to(device), y.to(device)
output = model(X)
loss = loss_fn(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item() * X.size(0)
avg_loss = running_loss / len(train_loader.dataset)
print(f"[{epoch+1}/{epochs}] Train Loss: {avg_loss:.4f}")
train_model(model, train_loader, epochs=10, lr=0.5)모르겠고 일단 학습시켜보자...
 2억 7천만 파라미터 치고 학습이 빠르다. 파라미터 수가 속도에 큰 영향을 미치는 건 아닌 것 같다. 로스가 0.4다 아주 불길하군.
2억 7천만 파라미터 치고 학습이 빠르다. 파라미터 수가 속도에 큰 영향을 미치는 건 아닌 것 같다. 로스가 0.4다 아주 불길하군.
4. 모델 평가
model.eval()
with torch.no_grad():
sample_dirty, sample_clean = next(iter(train_loader))
sample_dirty = sample_dirty.to(device)
output = model(sample_dirty)
plt.figure(figsize=(20, 9))
for i in range(5):
plt.subplot(3, 5, i + 1)
plt.imshow(sample_dirty[i].cpu().squeeze(), cmap='gray')
plt.title("Dirty", fontsize=20)
plt.axis('off')
plt.subplot(3, 5, i + 6)
plt.imshow(output[i].cpu().squeeze(), cmap='gray')
plt.title("Denoised", fontsize=20)
plt.axis('off')
plt.subplot(3, 5, i + 11)
plt.imshow(sample_clean[i].cpu().squeeze(), cmap='gray')
plt.title("Clean", fontsize=20)
plt.axis('off')
plt.tight_layout()
plt.show() ㅋㅋㅋㅋㅋ 역시 망했죠! 내일은 전처리와 모델을 손봐야겠다.
ㅋㅋㅋㅋㅋ 역시 망했죠! 내일은 전처리와 모델을 손봐야겠다.
일단 오늘은 여기까지...
모델 하나 만드는데도 하루가 부족하다..ㅠㅠ 괜히 일주일을 주신 게 아니군요 강사님..
