많은 진전이 있었던 하루. 꿈에 그리던 Cloud GPU를 손에 넣었다.
학습시간 09:00~02:00(당일17H/누적462H)
◆ 학습내용
1. Cloud GPU
 여러 모델로 데이터를 조금 과하게 밀어넣었더니 내 계정 GPU 서버가 터져버렸다. 24시간 동안 기다려야 한다고 한다...
여러 모델로 데이터를 조금 과하게 밀어넣었더니 내 계정 GPU 서버가 터져버렸다. 24시간 동안 기다려야 한다고 한다...
pro요금제나 pro+요금제를 써도 이런 일이 종종 생긴다고 하네. 그렇다면 지금 나에게 필요한 건 클라우드일 것이다. 처음이라 분명 어렵겠지만 나중을 생각해서라도 하는 법을 미리 알아둬야지.

 GCP VM, AWS이걸 주로 사용하는 것 같은데,,, 남은 GPU가 없는지 나에게 할당을 안 해준다 ㅠㅠ 결국 팀원이 알려준 사이트로 선택!
GCP VM, AWS이걸 주로 사용하는 것 같은데,,, 남은 GPU가 없는지 나에게 할당을 안 해준다 ㅠㅠ 결국 팀원이 알려준 사이트로 선택!
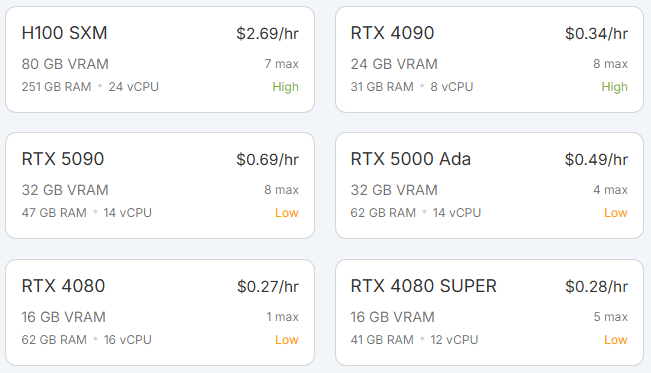 생각보다 GPU 종류가 많다. 한 30개 정도 있네. 시간당 0.2달러 쪽에도 쓸만한 게 많이 보인다.
생각보다 GPU 종류가 많다. 한 30개 정도 있네. 시간당 0.2달러 쪽에도 쓸만한 게 많이 보인다.
 바로 지갑 오픈..! 온오프 형식이니까 이정도면 한달은 쓰겠지..!?
바로 지갑 오픈..! 온오프 형식이니까 이정도면 한달은 쓰겠지..!?
 cmd로 키를 생성했다.
cmd로 키를 생성했다.
 vscode 익스텐션 다운.
vscode 익스텐션 다운.
 탐색기를 열어서
탐색기를 열어서
 키와 서버를 연동했다.
키와 서버를 연동했다.
 연결 완료!
연결 완료!
 미션 파일을 업로드했다. 리눅스 기반이라 조금 불편하네.. ㅠㅠ
미션 파일을 업로드했다. 리눅스 기반이라 조금 불편하네.. ㅠㅠ
!nvidia-smi 오마이갓 내 GPU가 A100이라니.... 이제 colab 런타임과 작별이다!!!
오마이갓 내 GPU가 A100이라니.... 이제 colab 런타임과 작별이다!!!
2. 두 번째 시도
어제 첫 번째 시도 결과는 처참했다. 아웃풋 결과물에 노이즈가 잔뜩 껴서 나왔다. 문제는 데이터 전처리와 모델 둘 중 하나일 것이다. 어차피 그 둘 밖에 없으니까. 먼저 전처리 쪽에서 승부를 보자.
어제 문제의 원인은 사이즈가 제각각인 이미지를 Resize 512x512로 통일해버린 것이 아닐까 생각했다.
NLP 잠깐 배울 때 단어박스에서 가장 긴 단어를 기준으로 두고 모든 단어에 0패딩을 입혔던 게 떠올랐다. 어쩌면 이미지도 똑같지 않을까?
리사이즈 대신 패딩을 입히는 게 맞는 것 같다.
def pad_to_size(img, target_h, target_w):
h, w = img.shape
pad_h = target_h - h
pad_w = target_w - w
pad_top = pad_h // 2
pad_bottom = pad_h - pad_top
pad_left = pad_w // 2
pad_right = pad_w - pad_left
padded = np.pad(img, ((pad_top, pad_bottom), (pad_left, pad_right)), mode='reflect')
return padded, (h, w, pad_top, pad_left)
def unpad(img, original_shape):
h, w, pad_top, pad_left = original_shape
return img[pad_top:pad_top + h, pad_left:pad_left + w]
def get_max_hw(image_list):
max_h = max(img.shape[0] for img in image_list)
max_w = max(img.shape[1] for img in image_list)
return max_h, max_w
def load_images(folder_path):
image_list = []
shape_list = []
file_names = sorted(os.listdir(folder_path))
for file in file_names:
img = Image.open(os.path.join(folder_path, file)).convert('L')
img = np.array(img, dtype=np.float32) / 255.0
shape_list.append(img.shape)
image_list.append(img)
return image_list, shape_list, file_names이미지에 0패딩 하나 두르는 데도 함수가 4개나 필요하다.
- 이미지 사이즈가 다 제각각이라는 가정하에, 모든 이미지를 루프돌면서 가장 큰 사이즈를 찾아야 한다.
- 그 이미지에 패딩을 입힐 함수가 필요하다.
- 혹시 시각화할 때 필요할지도 모르니 언패딩할 함수도 필요하다.
- 이미지 이름의 순서가 제각각일 수도 있으니 정렬할 함수도 필요하다.
class CustomDataset(Dataset):
def __init__(self, noisy_imgs, clean_imgs=None, target_h=None, target_w=None):
self.noisy_imgs = noisy_imgs
self.clean_imgs = clean_imgs
self.target_h = target_h
self.target_w = target_w
def __len__(self):
return len(self.noisy_imgs)
def __getitem__(self, idx):
x, _ = pad_to_size(self.noisy_imgs[idx], self.target_h, self.target_w)
x = torch.tensor(x).unsqueeze(0)
if self.clean_imgs is not None:
y, _ = pad_to_size(self.clean_imgs[idx], self.target_h, self.target_w)
y = torch.tensor(y).unsqueeze(0)
return x, y
return x어제 만든 데이터셋 클래스를 그대로 사용!
a, b = next(iter(train_loader)); print(a.shape, b.shape) 일단 사이즈는 어제와 똑같이 나온다.
일단 사이즈는 어제와 똑같이 나온다.
class AutoEncoder2(nn.Module):
def __init__(self):
super().__init__()
# Encoder
self.enc1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.enc2 = nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1)
self.enc3 = nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1)
# Decoder
self.dec1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)
self.dec2 = nn.ConvTranspose2d(64, 32, kernel_size=2, stride=2)
self.dec3 = nn.Conv2d(32, 1, kernel_size=3, stride=1, padding=1)
# Activation
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# Encoder
x = self.relu(self.enc1(x))
x = self.relu(self.enc2(x))
x = self.relu(self.enc3(x))
# Decoder
x = self.relu(self.dec1(x))
x = self.relu(self.dec2(x))
x = self.sigmoid(self.dec3(x))
return x모델은 어제 Linear만 있는 버전에서 CNN과 비슷한 요소를 추가했다. 사실 이정도면 그냥 CNN이라고 봐야할듯.. 이렇게 하면 안 되나..?
from tqdm import tqdm
import torch.nn as nn
import torch
import os
from torch.optim.lr_scheduler import StepLR
def train_model(model, train_loader, epochs, save_dir=None):
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.003)
scheduler = StepLR(optimizer, step_size=5, gamma=0.5)
for epoch in range(epochs):
model.train()
total_loss = 0
for x, y in tqdm(train_loader, desc=f"Epoch {epoch+1}/{epochs}"):
x, y = x.to(device), y.to(device)
out = model(x)
loss = criterion(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
scheduler.step()
print(f"▶ [{epoch+1}/{epochs}] Loss: {total_loss/len(train_loader):.6f}")
if save_dir:
model.eval()
os.makedirs(os.path.dirname(save_dir), exist_ok=True)
torch.save(model.state_dict(), save_dir)
print(f"▶ MODEL SAVED AS {save_dir}")
train_model(model, train_loader, epochs=30)
모델 학습에서 Cloud GPU를 사용하는거라 꼭 pth 파일 저장이 필요하다. 그래서 학습 후에 지정한 경로로 모델을 저장하는 코드를 추가했다.
아 옵티마이저 스케줄러라고 배웠는데 아주 좋은 기능인 것 같다. 에폭이 진행될 때마다 가중치를 늘리거나 줄일 수 있다.
그러나,,
 결과는 처참했다고 한다...
결과는 처참했다고 한다...
심플한 모델인데 다 검은색인 걸 보면 뭔가 이상하다. 아무래도 모델이 이미지를 제대로 인식하지 못한 것 같다. 전처리하는 과정에서 모델에 영향을 줄만한 게 있었던 것 같다.
그래도 패딩을 추가해서 인풋 이미지 사이즈를 지키는 건 성공했다..!
다음 주에는 모델만 어떻게 해보자...
