드디어 결과물이 나왔다. 하지만 아직 내 마음에 들진 않는다. 어떻게 해야 더 잘할 수 있을까. 생각과 고민의 연속인 하루다.
학습시간 09:00~02:00(당일17H/누적479H)
◆ 학습내용
어제 두 번째 시도에 아웃풋 이미지가 검은색만 나왔다. 인풋 이미지는 패딩까지 적용되어 사이즈가 잘 출력되는데,, 그럼 분명 전처리가 아니라 모델의 문제일 것이다. 첫 번째 시도에 사용했던 모델부터 다시 차근차근 해보자.
1. Linear 기반 모델
class AutoEncoder1(nn.Module):
def __init__(self):
super().__init__()
# Encoder
self.encoder = nn.Sequential(
nn.Linear(420*540, 512),
nn.ReLU(),
nn.Linear(512, 128),
nn.ReLU(),
nn.Linear(128, 32),
nn.ReLU()
)
# Decoder
self.decoder = nn.Sequential(
nn.Linear(32, 128),
nn.ReLU(),
nn.Linear(128, 512),
nn.ReLU(),
nn.Linear(512, 420*540),
nn.Sigmoid()
)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.encoder(x)
x = self.decoder(x)
x = x.view(-1, 1, 420, 540)
return x첫 번째로 시도했던 모델. Linear 기반이고 활성화 함수로 렐루를 사용했다. 다시 해보자!
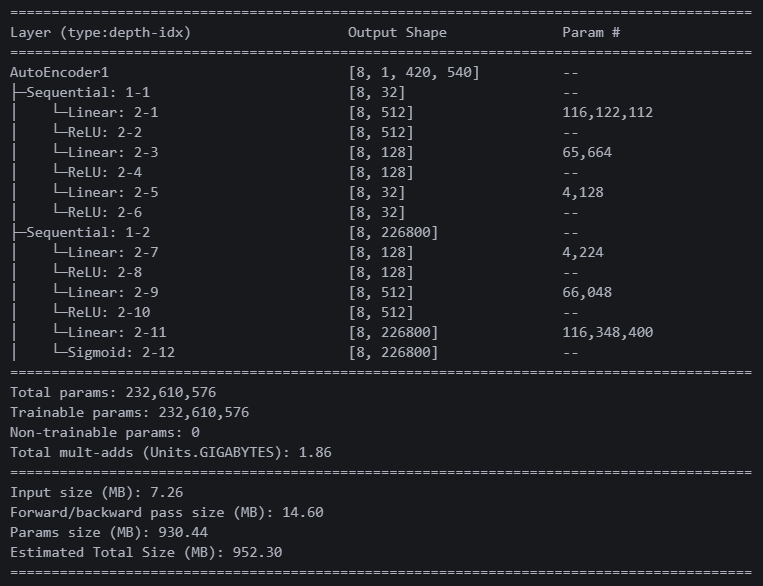 파라미터는 2억 7천만 개에서 2억 3천만 개로 줄었다. 아마 사이즈가 512x512에서 420x540으로 바뀌어서 그런듯하다.
파라미터는 2억 7천만 개에서 2억 3천만 개로 줄었다. 아마 사이즈가 512x512에서 420x540으로 바뀌어서 그런듯하다.
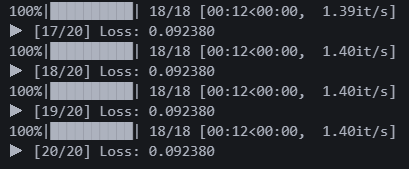 20에폭 돌렸다. 로스는 0.092
20에폭 돌렸다. 로스는 0.092
 음 뭐가 나오긴 했다. 근데 제대로 인식을 못하는 것 같다. 그래도 검은 화면이 아니니까 다행이다.....
음 뭐가 나오긴 했다. 근데 제대로 인식을 못하는 것 같다. 그래도 검은 화면이 아니니까 다행이다.....
내 생각에 Linear의 한계는 MNIST 숫자 인식인 것 같다. 여러 글자 인식에는 무리가 있는 게 아닐까.
2. CNN 기반 모델
class AutoEncoder2(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(16, 32, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(32, 16, 2, 2, 0),
nn.ReLU(),
nn.ConvTranspose2d(16, 1, 2, 2, 0),
nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
두 번째는 어제 검은색만 나왔던 CNN 기반의 모델이다. 어제와 다른 점은 레이어를 3개에서 2개로 줄인 것. 그리고 각 레이어마다 맥스풀을 추가했다는 것. 이게 먹히면 원인은 maxpool의 여부다.
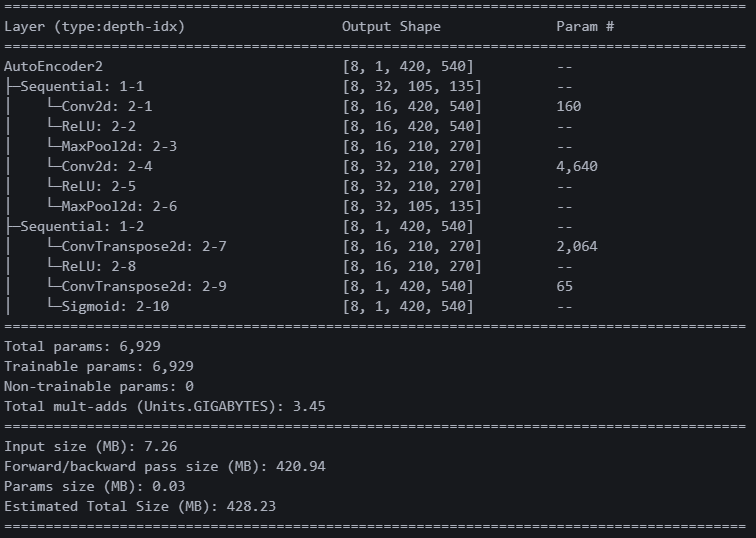 파라미터 수가 7000개 밖에 안 된다. 계속 2억 몇 천만 개 짜리를 봐서 그런지 적응이 안 된다.
파라미터 수가 7000개 밖에 안 된다. 계속 2억 몇 천만 개 짜리를 봐서 그런지 적응이 안 된다.
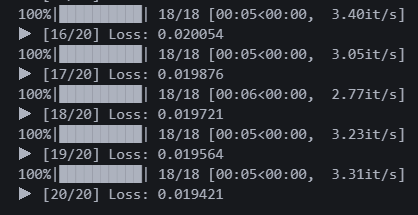 20에폭 돌렸다. 로스는 0.019다 Linear 모델보다 4배 좋은 성능..?
20에폭 돌렸다. 로스는 0.019다 Linear 모델보다 4배 좋은 성능..?
 오!!!!!!!!!!!!!!!!! 드디어 그럴듯한 결과물이 나왔다!! ㅠㅠㅠㅠ 감격... 이제야 텍스트를 인식한다.
오!!!!!!!!!!!!!!!!! 드디어 그럴듯한 결과물이 나왔다!! ㅠㅠㅠㅠ 감격... 이제야 텍스트를 인식한다.
그래도 아직 흐릿한 느낌이 꽤 있다. 조금 더 선명했으면 좋겠는데...
3. CNN 기반 모델 + LeakyReLU
class AutoEncoder3(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, 3, 1, 1),
nn.LeakyReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(16, 32, 3, 1, 1),
nn.LeakyReLU(),
nn.MaxPool2d(2, 2),
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(32, 16, 2, 2, 0),
nn.LeakyReLU(),
nn.ConvTranspose2d(16, 1, 2, 2, 0),
nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
세 번째 모델. 방금 모델에 활성화 함수만 렐루에서 리키렐루로 변경했다. 과연 리키렐루의 위력은 어느 정도일까?
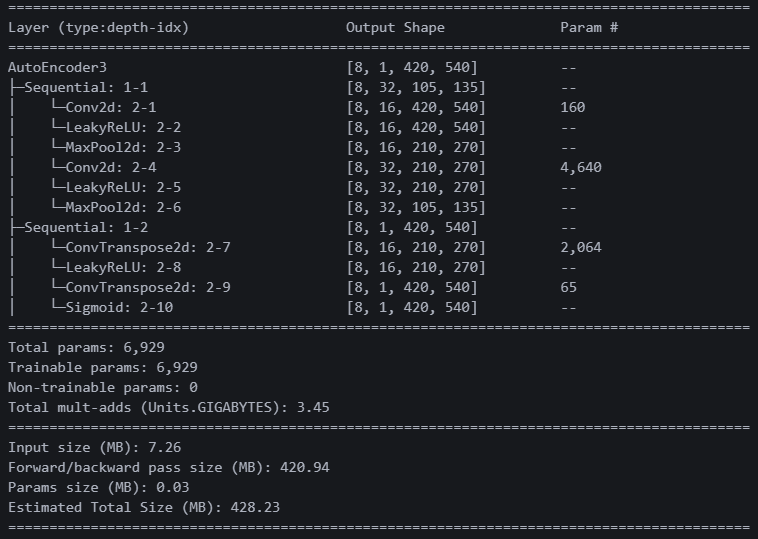 파라미터 수의 차이는 없다. 활성화 함수만 바꾸어서 그런 듯하다.
파라미터 수의 차이는 없다. 활성화 함수만 바꾸어서 그런 듯하다.
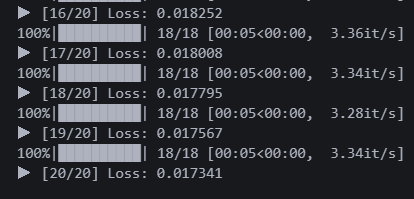 20에폭 돌렸다. 활성화 함수만 바꿨는데 로스가 0.017로 전 모델 대비 0.002 감소했다.
20에폭 돌렸다. 활성화 함수만 바꿨는데 로스가 0.017로 전 모델 대비 0.002 감소했다.
 오?? 확실히 조금 더 선명해진 것 같기도 하다.
오?? 확실히 조금 더 선명해진 것 같기도 하다.
고딕체는 꽤 잘 잡는 것 같은데 아직 아라비아틱한 폰트는 잘 잡지 못한다. 뭔가 더 추가해야하는 것 같다.
4. CNN 기반 모델 + LeakyReLU + BarchNorm + OutLayer
class AutoEncoder4(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, 3, 1, 1),
nn.BatchNorm2d(16),
nn.LeakyReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(16, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.LeakyReLU(),
nn.MaxPool2d(2, 2),
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(32, 16, 2, 2, 0),
nn.LeakyReLU(),
nn.ConvTranspose2d(16, 8, 2, 2, 0),
nn.LeakyReLU(),
nn.Conv2d(8, 1, 3, 1, 1),
nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x네 번째 모델이다. 인코더 각 레이어마다 배치놈 정규화를 넣었다. 디코더 마지막에 채널을 한 번 더 모아주기 위해 Conv2d 레이어를 넣었다.
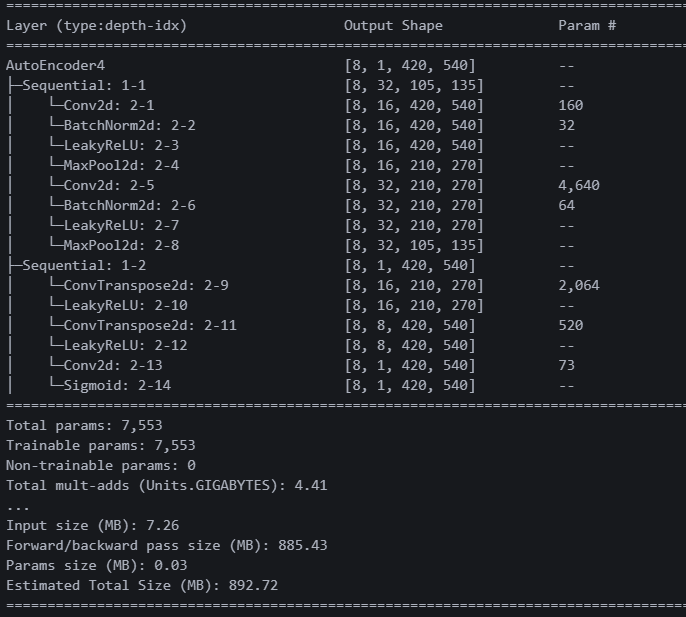 파라미터가 약 500개 가량 늘었다.
파라미터가 약 500개 가량 늘었다.
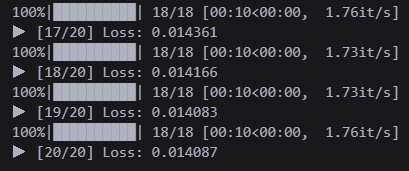 20에폭 돌렸다. 로스는 0.014다. 3번 모델보다 0.003 감소했다. 과연 결과는?
20에폭 돌렸다. 로스는 0.014다. 3번 모델보다 0.003 감소했다. 과연 결과는?
 오? 엄청난 차이는 느껴지지 않지만, 그래도 확실한 건 아라비안 폰트의 외곽선이 조금 더 선명해졌다.
오? 엄청난 차이는 느껴지지 않지만, 그래도 확실한 건 아라비안 폰트의 외곽선이 조금 더 선명해졌다.
음,, 더 선명하게는 못하나?
5. CNN 기반 모델 + 더블 레이어
class AutoEncoder5(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, 3, 1, 1),
nn.Conv2d(16, 16, 3, 1, 1),
nn.BatchNorm2d(16),
nn.LeakyReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(16, 32, 3, 1, 1),
nn.Conv2d(32, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.LeakyReLU(),
nn.MaxPool2d(2, 2)
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(32, 16, 2, 2),
nn.Conv2d(16, 16, 3, 1, 1),
nn.LeakyReLU(),
nn.ConvTranspose2d(16, 8, 2, 2),
nn.Conv2d(8, 8, 3, 1, 1),
nn.LeakyReLU(),
nn.Conv2d(8, 1, 3, 1, 1),
nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x5번 모델이다. 4번 모델 디코더 마지막 OutLayer에 영감을 받았다. 마지막 말고 그냥 모든 레이어마다 채널을 유지하면서 Conv레이어로 한 번씩 더 보고 이동하면 더 선명해지지 않을까?
근데 이렇게 해도 되나? ㅋㅋㅋㅋ모르겠다
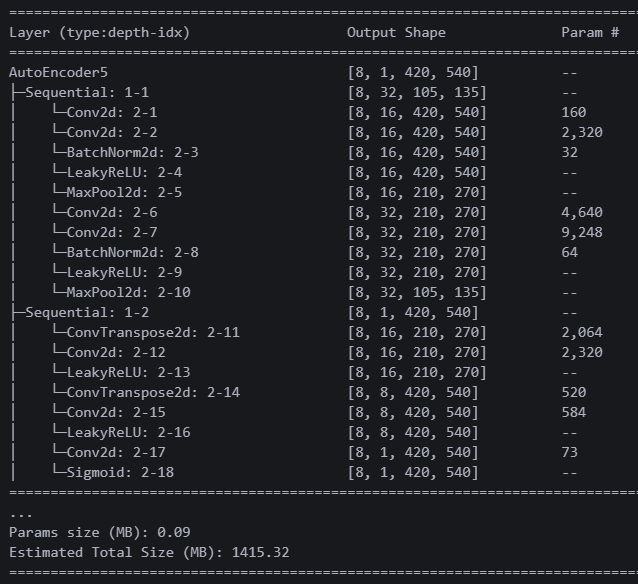 ... 레이어가 많아지니 파라미터 수가 안 보인다.
... 레이어가 많아지니 파라미터 수가 안 보인다.
View as a scrollable element 버튼을 누르면 다 보이긴 하지만, 공부하는 입장이니 다른 방법을 찾아봐야지.
print("▶ Total Parameters:", sum(p.numel() for p in model.parameters()))numel() 함수를 사용하면 모델 파라미터를 돌면서 sum 할 수 있다고 한다.
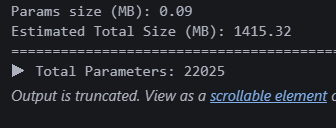 파라미터 수는 22000개. 4번 모델보다 3배 가량 많다. 성능도 더 좋으려나?
파라미터 수는 22000개. 4번 모델보다 3배 가량 많다. 성능도 더 좋으려나?
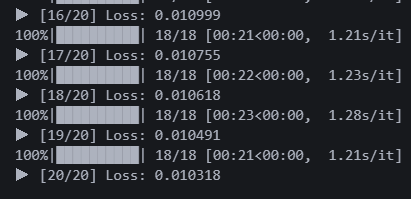 어쩐 일로 에러없이 돌아간다. 괜히 더 불안하네. 일단 20에폭 돌렸다. 로스는 0.010이다. 전 모델보다 0.004 감소했다.
어쩐 일로 에러없이 돌아간다. 괜히 더 불안하네. 일단 20에폭 돌렸다. 로스는 0.010이다. 전 모델보다 0.004 감소했다.
 오!! 뭔가 이제 폰트 테두리를 꽤 잘 인식하는 것 같다. 잉크 얼룩도 거의 안 보인다.
오!! 뭔가 이제 폰트 테두리를 꽤 잘 인식하는 것 같다. 잉크 얼룩도 거의 안 보인다.
하,, 근데 영 마음에 들지 않는다. 아직 내 눈에는 원본이랑 해상도 차이가 너무 많이 느껴진다.
방법이 없나..?? 그동안 배운 건 싹 다 적용한 것 같은데,,, 이게 내 한계인가?
ㅠㅠ
잠들기 전에 오토인코더 관련 논문을 하나 발견했다.
Thomas Brox 박사님이 운영하는 Computer Vision Group 이라는 곳에서 나온 논문이다.
흐흫ㅎ 내일 할게 생겼다. 개발 인생 첫 논문으로 잡아먹어주마. 7시간 뒤에 보자.
