내가 이걸 해냈다니 도저히 믿기지 않는다 ㅠㅠ 역시 노력은 배신하지 않는다!
학습시간 09:00~02:00(당일17H/누적496H)
◆ 학습내용
1. U-Net 논문 확인

논문 링크: https://link.springer.com/chapter/10.1007/978-3-319-24574-4_28
어제 잠들기 전 우연히 CNN 관련 논문을 발견했다. 오늘 일용할 양식으로 제격인 것 같다.
분할 및 복원에 특화된 모델이라고 한다. 2015년이니까 10년 전에 나왔네. 생각해 보니 지금 내가 푸는 문제도 10년 전 껀데...?

2015 ISBI 대회 세포 추적 부분에서 짱을 먹었다고 한다.
ISBI가 뭐지?

The International Symposium on Biomedical Imaging(국제 생의학 이미지처리 학술대회)의 약자다. 매년 열리는 것 같다.
아주 믿음직스럽다.
 모델에 어떤 레이어를 넣어야 하는지도 나와있다.
모델에 어떤 레이어를 넣어야 하는지도 나와있다.
Conv(3x3)+ReLU 2회, 맥스풀(2x2) 1회, 업다운 샘플링을 concatenate 하는 게 핵심인 것 같다.
논문은 총 23 레이어를 구성했다고 한다. 덜덜덜,,,,
근데 글로만 봐선 딱 이해가 되진 않네.
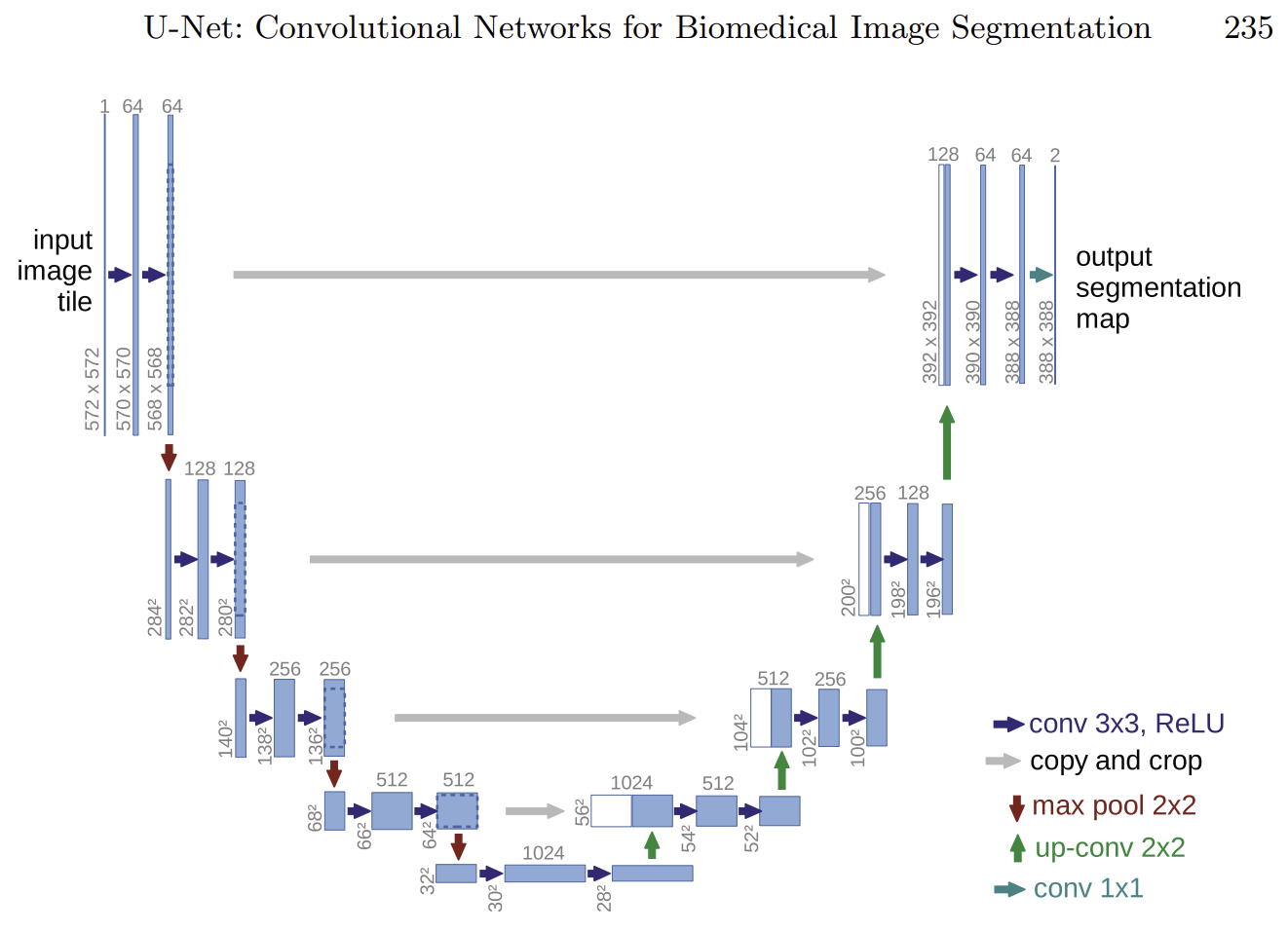 오 다행히 그림이 있다. 역시 그림이 직관적이라 좋다.
오 다행히 그림이 있다. 역시 그림이 직관적이라 좋다.
U자형으로 생겨서 U-Net이라고 한다. 연구원들 작명 센스가 썩 좋은 것 같진 않다.
인코더와 디코더를 copy and crop으로 연결하는 게 핵심이라고 한다. 이걸 skip connection 이라고 한다네. 저 회색 화살표가 스킵커넥션인 것 같다. 깊이가 5단계로 되어있는데 마지막 단계 제외하고 다 연결하는 것 같다.
기존 오토인코더 모델은 업샘플링 과정에서 해상도가 강제 확대되기에 픽셀이 깨질 수밖에 없다. 그래서 온전한 픽셀을 가지고 있는(다운샘플링 하기 직전) 정보를 하나씩 이어붙이는 것.
헐 천재 아냐?? 왜 이 생각을 못했지??
바로 해보자.
2. 모델 구현
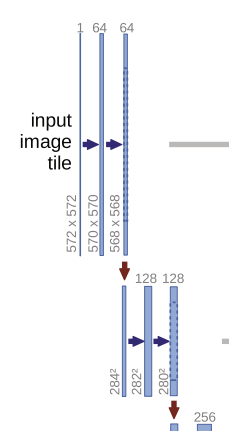
 다운샘플링 단계다.
다운샘플링 단계다.
각 단계마다 conv(3x3) 2회 + maxpool(2x2) 1회씩 하며 내려간다. 인풋 사이즈가 572인데, 채널 수는 64로 동일하고 이미지 사이즈만 레이어 1개당 2씩 줄어든다.
570 = ((572 - K + 2P) / S) + 1
사이즈가 2씩 줄어드려면, 이 공식에 따라 K=3, S=1, P=0이 된다.
self.enc1_1 = nn.Conv2d(572*572, 64, 3, 1, 0)
self.enc1_2 = nn.Conv2d(64, 64, 3, 1, 0)
down = F.relu(self.enc1_2(F.relu(self.enc1_1(x))))
pool = F.max_pool2d(2, 2)그럼 이런 느낌이겠지..? 내 모델은 이미지 사이즈를 계속 유지해야 하니까 패딩을 1로 해야겠다.
근데 가만 보니까 이거 내가 5번 모델에서 더블레이어 한거랑 모습이 비슷하다.
어쩌면 더블레이어가 이미지 인식의 핵심일지도 모르겠다.
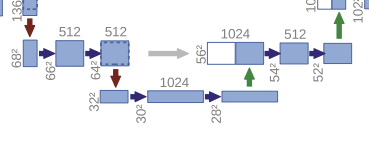 문제는 이부분인데,, 무슨 소린지 잘 모르겠다. 이게 뭐지??
문제는 이부분인데,, 무슨 소린지 잘 모르겠다. 이게 뭐지??
512채널이 1024채널이 되었다가 -> 다시 1024채널이 1024채널로 나오는데, 이때 나오는 채널은 2개가 겹쳐있다.
회색 화살표가 있는 걸 보니 1024채널 중 절반은 다운샘플링 채널에서 스킵커넥션한 것 같은데...
그럼 (512, 1024) -> (1024, (512+512)) -> ((512+512), 512) -> ((256+256), 256) 이런 느낌인가??
self.down = nn.Conv2d(512, 1024, 3, 1, 1)
self.bottleneck = nn.Conv2d(512, 1024, 3, 1, 1)
self.bottleneck = nn.Conv2d(1024, (512+512), 3, 1, 1)
self.up_t = nn.ConvTranspose2d((512+512), 32, 2, 2)
self.up_c = nn.Conv2d((512+512), 32, 3, 1, 1)찾아보니 이렇게 (기존채널, 더블채널) -> (더블채널, 기존채널) 시작해주는 부분을 보틀넥이라 부르는 것 같다.
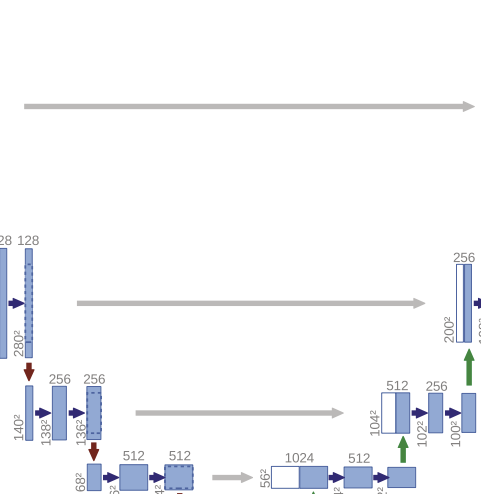 보틀넥을 기점으로 아웃풋이 출력될 때까지 계속 더블채널이 있다. 아~! 그래서 깊이가 5인데 회색 화살표는 4개였던 거다.
보틀넥을 기점으로 아웃풋이 출력될 때까지 계속 더블채널이 있다. 아~! 그래서 깊이가 5인데 회색 화살표는 4개였던 거다.
스킵커넥션은 torch.cat([up, down], dim=1 이런 식으로 합쳐주면 된다고 한다.
대충 감을 잡았으니 이제 만들어 보자. 논문을 그대로 구현할 실력은 없으니 최대한 간소화해야지.
일단 구상한 순서는 다운1 -> 다운2 -> 보틀넥 -> 업2 -> 업1 -> 아웃 이다.
업2 & 다운2를 concat 하고 업1 & 다운1을 concat 하면 될 것 같다.
class AutoEncoder6(nn.Module):
def __init__(self):
super().__init__()
# Others
self.pool = nn.MaxPool2d(2, 2)
self.bn16 = nn.BatchNorm2d(16)
self.bn32 = nn.BatchNorm2d(32)
self.bn64 = nn.BatchNorm2d(64)
self.pool = nn.MaxPool2d(2, 2)
self.leakyrelu = nn.LeakyReLU()
self.sigmoid = nn.Sigmoid()일단 사용할 활성화 함수, 풀링, 배치놈을 정의했다.
# Down 1
self.down1_conv1 = nn.Conv2d(1, 16, 3, 1, 1)
self.down1_conv2 = nn.Conv2d(16, 16, 3, 1, 1)
# Down 2
self.down2_conv1 = nn.Conv2d(16, 32, 3, 1, 1)
self.down2_conv2 = nn.Conv2d(32, 32, 3, 1, 1)다운 1, 2 각각 Conv2d 레이어를 2개씩 깔아줬다. 논문에는 다운 4까지 있던데 차마 거기까진 못하겠다.
# Bottleneck
self.bottleneck_down = nn.Conv2d(32, 64, 3, 1, 1)
self.bottleneck_up = nn.Conv2d(64, (32+32), 3, 1, 1)
문제는 여기서 부턴데,, 장담하진 못하겠지만 일단 이해한 바로 보틀넥은 이런 모습일 것 같다. 64채널로 들어갔다가 32+32 더블 채널로 나온다.
# Up 2
self.up2_trans = nn.ConvTranspose2d((32+32), 32, 2, 2, 0)
self.up2_conv1 = nn.Conv2d((32+32), 32, 3, 1, 1)
self.up2_conv2 = nn.Conv2d(32, 32, 3, 1, 1)
# Up 1
self.up1_trans = nn.ConvTranspose2d((16+16), 16, 2, 2, 0)
self.up1_conv1 = nn.Conv2d((16+16), 16, 3, 1, 1)
self.up1_conv2 = nn.Conv2d(16, 16, 3, 1, 1)
# Output
self.out = nn.Conv2d(16, 1, 1)업 2, 1도 생성. 이 단계에서는 업샘플링을 위한 trans 레이어가 먼저 들어가야 한다.
다운샘플링과 합쳐지는 부분은 32+32, 16+16로 표기 했다. 역순으로 합쳐야 해서 헷갈리지 않으려고 2부터 번호를 매겼다.
머리 터지겠다.. 이제 순전파를 만들어 보자..!
def forward(self, x):
# Down 1
down1 = self.leakyrelu(self.bn16(self.down1_conv1(x)))
down1 = self.leakyrelu(self.bn16(self.down1_conv2(down1)))
pool = self.pool(down1)
# Down 2
down2 = self.leakyrelu(self.bn32(self.down2_conv1(pool)))
down2 = self.leakyrelu(self.bn32(self.down2_conv2(down2)))
pool = self.pool(down2)down 1, 2에서는 conv->bathnorm->leakyrelu를 2번씩 거친 뒤 풀링으로 추출한다.
결과물: pool
# Bottleneck
bottleneck_down = self.leakyrelu(self.bn64(self.bottleneck_down(pool)))
bottleneck_up = self.leakyrelu(self.bn64(self.bottleneck_up(bottleneck_down)))전 단계에서 나온 pool을 보틀넥에 통과시킨다. bottleneck_up부터 더블채널이라는 것을 잊어선 안 된다...!!
결과물: bottleneck_up
# Up 2
up2 = self.up2_trans(bottleneck_up)
up2 = torch.cat([up2, down2], dim=1)
up2 = self.leakyrelu(self.bn32(self.up2_conv1(up2)))
up2 = self.leakyrelu(self.bn32(self.up2_conv2(up2)))
# Up 1
up1 = self.up1_trans(up2)
up1 = torch.cat([up1, down1], dim=1)
up1 = self.leakyrelu(self.bn16(self.up1_conv1(up1)))
up1 = self.leakyrelu(self.bn16(self.up1_conv2(up1)))여기가 가장 헷갈리는 부분인데,, 보틀넥 결과물을 trans 레이어에 넣어서 먼저 이미지 사이즈를 늘려준다.
그후 업샘플링 레이어와 다운샘플링 레이어를 채널이 같은 것끼리 concatenate하고, conv레이어를 2회 통과시킨다.
# Output
return self.sigmoid(self.out(up1))마지막은 시그모이드로 돌려서 출력
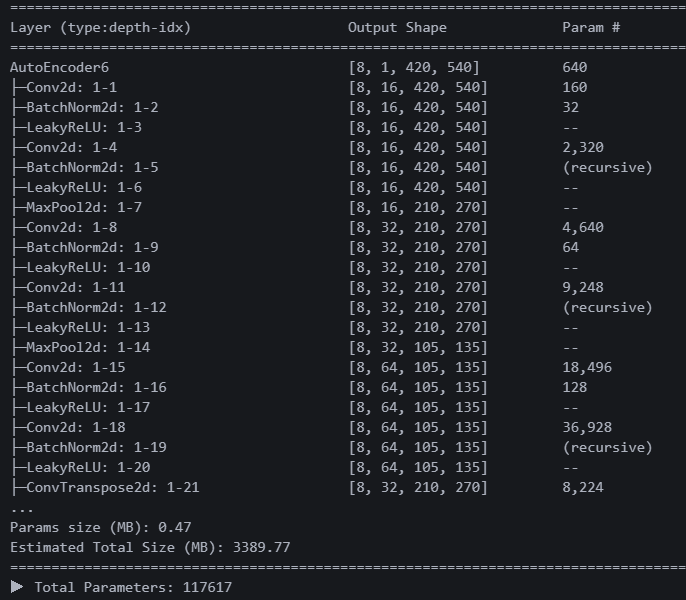 파라미터가 약 11만7천 개다. 2억 3천만 개짜리 모델을 제외하면 지금까지 모델 중에서 가장 높은 수치다. 근데 recursive라는 처음 보는 게 있다. 흠 이건 뭘까
파라미터가 약 11만7천 개다. 2억 3천만 개짜리 모델을 제외하면 지금까지 모델 중에서 가장 높은 수치다. 근데 recursive라는 처음 보는 게 있다. 흠 이건 뭘까
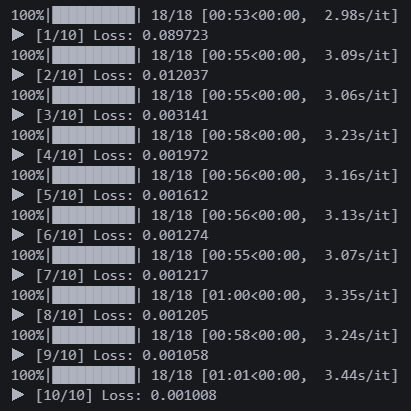 또 에러없이 돌아간다. 불안하다...
또 에러없이 돌아간다. 불안하다...
시간이 오래 걸려서 10에폭만 돌렸는데 로스가 0.001이다.
로스만 보면 전 모델 0.01에 비해 무려 10배 좋은 성능이다.
제발 좋은 결과가 있기를...
3. 모델 평가
 역시 한번에 잘 나올리가 없지 ^^
역시 한번에 잘 나올리가 없지 ^^
 근데 회색인 것만 제외하면 텍스트가 엄청 또렷한 것 같다. 내가 원하던 선명도다. 색상만 잘 잡으면 좋을 것 같은데 ㅠㅠ
근데 회색인 것만 제외하면 텍스트가 엄청 또렷한 것 같다. 내가 원하던 선명도다. 색상만 잘 잡으면 좋을 것 같은데 ㅠㅠ
뭐가 문제일까?
어디가 문제일까????
왜 문제일까?????????????
아, 예전에 꽃사진 데이터 증강했을 때가 떠올랐다.
transform.v2에 Normalize(0.5, 0.5) 적용 후 시각화한 결과물이 칙칙하게 나와서 당황했던 적이 있다.
그럼 이것도 마찬가지로 정규화인 batchnorm이 원인인가?
init에 하나만 지정하고 여러 번 돌려 써서 그런가?
# Down 1
self.down1_conv1 = nn.Conv2d(1, 16, 3, 1, 1)
self.down1_bn1 = nn.BatchNorm2d(16)
self.down1_conv2 = nn.Conv2d(16, 16, 3, 1, 1)
self.down1_bn2 = nn.BatchNorm2d(16)
self.down1_pool = nn.MaxPool2d(2, 2)init 메서드에 선언했던 self.bn을 삭제하고 각 레이어마다 지정해줬다.
혹시 몰라서 맥스풀도 선언식에서 레이어별 지정하는 것으로 변경했다.
def forward(self, x):
# Down 1
down1 = self.leakyrelu(self.down1_bn1(self.down1_conv1(x)))
down1 = self.leakyrelu(self.down1_bn2(self.down1_conv2(down1)))
pool = self.down1_pool(down1)순전파 부분에서도 bn16~64로 선언 후 중복 사용하던 것을 모든 레이어와 단계마다 down1_bn1, down1_bn2 같은 식으로 나눴다.
이걸로 해결되면 대박인데,, 당연히 안 되겠지?
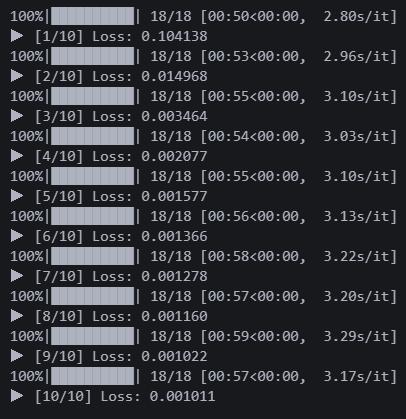 다시 10에폭 돌렸다.
다시 10에폭 돌렸다.
로스는 수정 전과 똑같다.
과연...!!!!
 헉!!!!! 나왔어!!!!?????
헉!!!!! 나왔어!!!!?????
 확실히 다르다. 업다운 샘플링 정보를 서로 엮어주는 게 이렇게 큰 영향을 미치다니...
확실히 다르다. 업다운 샘플링 정보를 서로 엮어주는 게 이렇게 큰 영향을 미치다니...
이제야 만족스럽다. 오늘은 꿀잠잘 수 있을 것 같다.
논문 하나 보는데 하루가 끝났다. 그래도 개발자 인생 첫 논문으로 아주 합리적인 난이도였던 것 같다. 잘 먹고 갑니다!
