전이학습의 장점은 내가 직접 모델을 만들 필요가 없다는 것이다. 근데 그래서인지 뭔가 느낌이 묘하다. 살짝 뭐랄까, 3분 카레 돌린 다음에 내가 카레 요리했다고 우기는 느낌이다.
학습시간 16:00~02:00(당일10H/누적557H)
◆ 학습내용
ResNet18 모델에 CIFAR100 데이터 학습시킨 후 분류하기.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
transform = v2.Compose([
v2.Resize(256),
v2.CenterCrop(224),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize(?????)
])CIFAR100 이미지를 불러오기 위해 trainsform 변수를 먼저 만들었다. 정규화 값을 넣어야 하는데, resnet 맞춤으로 이미 나온 값이 있을 것이다. 찾으러 가자!!
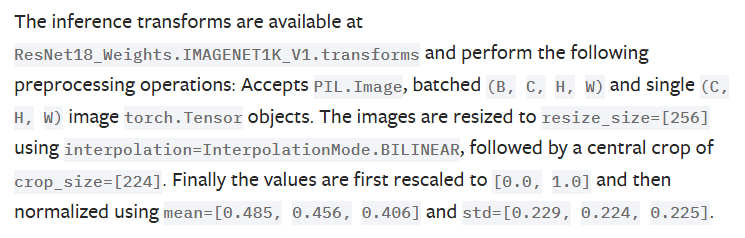
역시 있다.
transform = v2.Compose([
v2.Resize(256),
v2.CenterCrop(224),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])바로 넣어줬다.
train_dataset = torchvision.datasets.CIFAR100(root='./data', train=True, download=True, transform=transform)
test_dataset = torchvision.datasets.CIFAR100(root='./data', train=False, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)
데이터셋이랑 로더까지 만들어줬다.
라이브러리로 불러오면 데이터셋 클래스를 안 만들어도 되서 참 좋다. 편함에 익숙해지면 안 되는데 ㅠㅠ 후...
model = models.........어,,, 모델을 불러오려고 했는데 모델 코드를 모르겠다. 이것도 찾아야 하네 ㅠㅠ

아까 링크를 다시 들어가 보니까 뭔가 적혀 있다.
음, 뭔지는 잘 모르겠지만 일단 models.resnet18() 이렇게 불러오면 되는 것 같다.
괄호 안에는 아래처럼

weights='DEFAULT' 이렇게 추가로 넣으면 되는 것 같다. 디폴트, 모델명, 파일명 중에 뭐를 넣든 딱히 상관없는 듯함.

일단 풀네임 넣었다. 불러오기 성공!
print(model)모델이 어떻게 생겼나 함 보자.
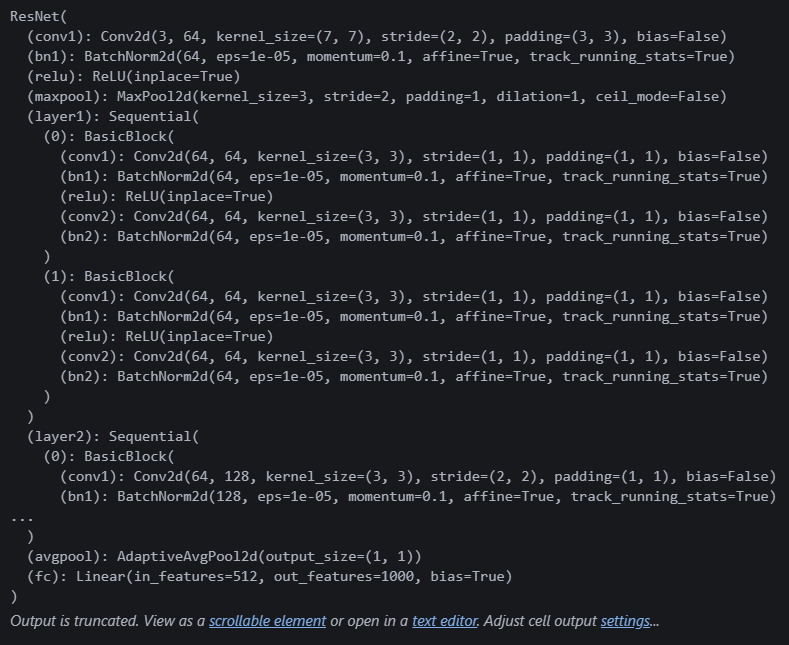
역시 복잡하다. 일단 마지막 (fc): Linear(in_features=512, out_features=1000, bias=True) 이 부분에 아웃피처만 바꾸면 될 것 같다!
model.fc = nn.Linear(model.fc.in_features, 100)
print(model)
오케이 100으로 변경했다.
model.to(device)
아차 가장 중요한 걸 까먹을 뻔했다. 수정하면 반드시 device를 통일해줘야 한다.
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
epochs = 5
for epoch in range(epochs):
model.train()
total_loss = 0.0
for inputs, labels in tqdm(train_loader):
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch [{epoch+1}/{epochs}], Loss: {total_loss/len(train_loader):.4f}")간단한 학습 코드를 만들었다.
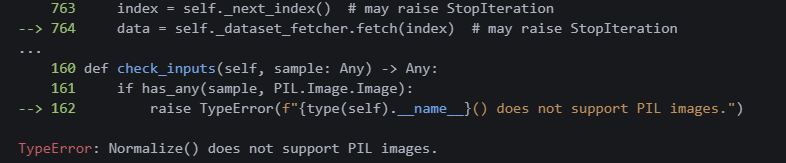
?? 에러가 났다?? PIL타입을 정규화할 수 없다고 한다.
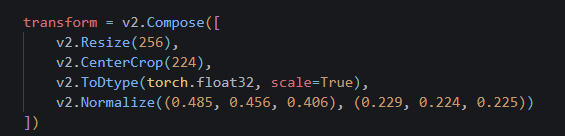 아 다시 보니
아 다시 보니 ToImage() 를 빼먹었다 ㅋ
transform = v2.Compose([
v2.Resize(256),
v2.CenterCrop(224),
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])적절한 위치에 다시 넣어줬다!
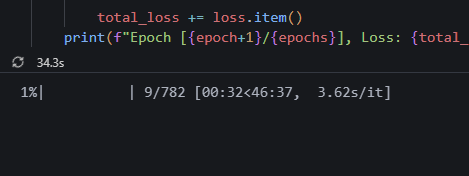
ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 저기요...? 에폭당 45분 걸린다구요???
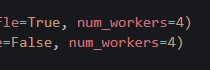
num_workers 라는 하이퍼 파라미터를 추가했다. 동시 연산을 몇 개나 할 껀지 결정하는 듯하다.
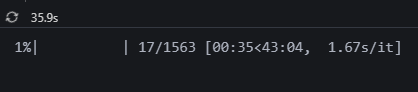
와!!!!!!!!! 무려 3분이나 더 빨라진다구?????????????
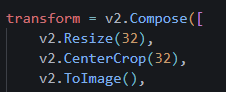
이미지 사이즈를 32로, 배치를 512로 변경했다. ResNet은 224사이즈를 사용하라고 했던 것 같은데,, 이럼 에러가 나려나?
일단 돌아가긴 한다. 에폭당 1분 남짓 걸린다. 아무래도 학습시간을 결정짓는 요소 제 1위는 이미지 사이즈인 것 같다.
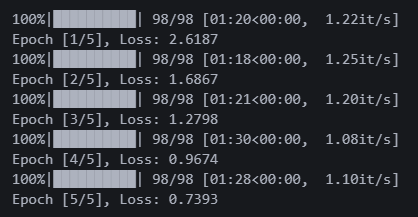
5에폭 돌렸다. 로스가 0.73이다.
수치를 보니까 계속 떨어질 것 같긴 한데,,, 도저히 학습시간 감당할 자신이 없다.
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in tqdm(test_loader):
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f"Test Accuracy: {accuracy:.2f}%")
모르겠고 일단 성능을 보자.
정확도 측정하는 코드를 만들었다. 흠,, 불안하군

정확도 50%가 나왔다.
정확도가 낮은 이유는 2개 중 하나일 것이다.
첫 번째는 학습을 충분히 하지 않은 것.
두 번째는 이미지 사이즈를 권장인 224에서 32로 낮추어 진행한 것. + 사이즈를 변경하고 정규화 수치를 그대로 둔 것까지
일단 첫 번째부터 승부를 보자. 근데 에폭당 45분을 기다릴 순 없는데.. 뭐 방법이 없나?

MIXED PRECISION TRAINING 이라는 논문을 찾았다.
나 생각보다 이런 논문 찾는 재주가 있는 것 같다.
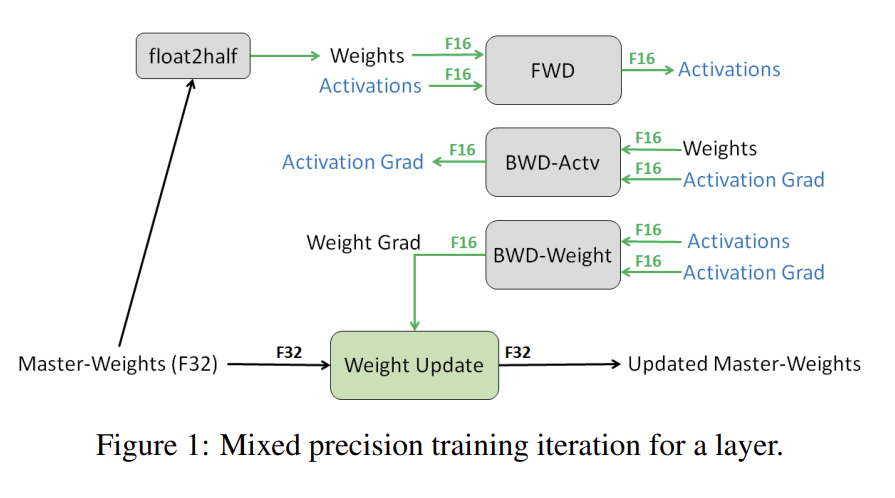
학습 속도 향상을 위해 여러 floating point를 섞는 기술이라고 한다. Activation과 gradient를 계산할 때는 FP16를 사용하고, 그렇게 나온 값을 다시 FP32로 변경해 웨이트를 업데이트 한다고 한다.
와 미쳤다!!!! 이거 어떻게 하는 거지!!!!!!!!!

어느 천사님이 사용 방법을 친절히 블로그에 올려주셨다. 논문 다 읽어볼 시간이 없었는데 다행이다...
optimizer = optim.Adam(model.parameters(), lr=0.001)
scaler = torch.cuda.amp.GradScaler()나온대로 옵티마이저 아래 넣어줬다.
amp는 뭐의 약자인 걸까? Automatic Mixed Precision 뭐 이런 건가?

zzzzzzㅋㅋㅋㅋㅋ 맞음 내가 연구원들 작명센스는 U-Net 때 어느정도 파악했지 ㅋㅋㅋㅋㅋ
## MP 적용 전
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
## MP 적용 후
with torch.cuda.amp.autocast(): # 새로 생김!
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
scaler.scale(loss).backward() # 코드 바뀜!
scaler.step(optimizer) # 코드 바뀜!
scaler.update() # 새로 생김!학습루프 안에 코드가 살짝 변경됐다. 그래도 이정도면 막 엄청 어렵진 않은 것 같다.
순식간에 10에폭이 끝났다. 로스는 0.09다. 아까 0.73에 비하면 엄청나게 개선이 됐다.
과연 성능은....!?!?
with torch.no_grad():
for inputs, labels in tqdm(test_loader, desc="Testing"):
inputs, labels = inputs.to(device), labels.to(device)
with torch.cuda.amp.autocast(): # 새로 생김!
outputs = model(inputs)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()MP를 사용하면 평가 코드에도 이렇게 할 수 있다고 한다. 필수는 아닌데 평가도 더 빨라진다고 한다.

정확도 53.72%가 나왔다. 조금 오르긴 했는데, 기대했던 수치가 나오지 않았다.
그렇다면 문제는 아래 3개 중 하나일 것 같다.
-
이미지 사이즈를 ResNet 권장 사이즈에 맞추지 않은 것
-
이미지 사이즈 변경 후 정규화를 다시 하지 않은 것
-
이미지 사이즈 변경 후 ResNet 모델 안에 입력 사이즈를 변경하지 않은 것
음.. 일단 오늘은 여기까지 해보자!
