드디어 새로운 미션 시작..! 과연 이번엔 얼마나 성장할 수 있을 것인가!!
학습시간 09:00~02:00(당일17H/누적574H)
◆ 학습내용
흉부 X-Ray 사진을 바탕으로 폐렴 환자 분류 모델 생성
[ 필요사항 ]
-
데이터 증강 기법 사용
-
Transfer Learning 적용
-
Frozen, Fartial Fine-Tuning, Full Fine-Tuning 기법 사용
-
평가 지표(Accuracy, Precision, Recall, F1-score 등) 사용해 모델 비교
1. 데이터 다운로드
이번 미션은 캐글에 7년 전 올라온 분류 문제다.
일단 다운로드하긴 했는데, 데이터가 많아서 클라우드에 업로드 하는 게 너무 오래 걸린다.
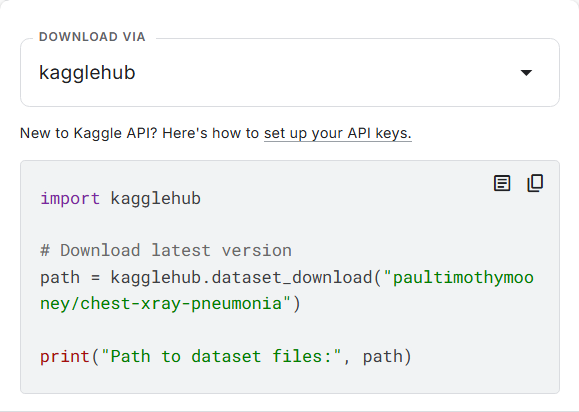
개발환경에서 저 코드만 입력해도 다운로드 된다고 한다.
캐글 API를 이용하면 클라우드에 바로 다운받고 압축까지 풀 수 있다고 한다.
내가 또 이걸 안 배우고 지나칠 수 없지.
캐글 계정 셋팅에 가니 API 뭐시기가 있다.
 토큰 생성하니 무슨 파일이 생겼다. json이라는 확장자는 처음 본다.
토큰 생성하니 무슨 파일이 생겼다. json이라는 확장자는 처음 본다.
!mkdir -p ~/.kaggle
!cp /content/kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json지선생 도움으로 코드 하나를 만들었다.
!kaggle datasets download -d paultimothymooney/chest-xray-pneumonia -p /content/drive/MyDrive/dev/mission/mission6/
!unzip /content/drive/MyDrive/dev/mission/mission6/chest-xray-pneumonia.zip -d /content/drive/MyDrive/dev/mission/mission6/클라우드에 압축파일 다운로드 및 압축 해제까지 진행하는 코드다.
 오오 된다 된다!!
오오 된다 된다!!
클라우드에 받으니 로컬에서도 보인다. test, train, val set이 있다. 이미지는 5800장 정도니 지난 미션 144장에 비하면 상당히 넉넉한 수준. 학습이 얼마나 오래 걸릴지 벌써부터 두렵다.

폴더를 열어봤다. 진짜 엑스레이 사진이다. 의학 지식이 전혀 없는데 큰일이다.
일단 폐렴이 뭔지부터 알아보는 게 옳은 순서인 듯하다.
2. 도메인 지식 확보
폐렴은 쉽게 말해 폐에 생기는 염증이다.

세균, 바이러스, 곰팡이가 원인이다.

보통 항생제로 치료한다.

엑스레이로 폐렴을 진단하는 방법을 찾아봤다. 폐 부분은 원래 검은색이어야 정상이라고 한다. 염증이 심각할수록 하얀 부분이 많다고 한다. CT로 보면 엄청 잘 나오는데, 비싸서 X-ray를 많이 쓴다고 함.
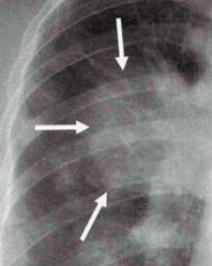
이런 느낌으로 되어 있으면 폐렴인 것 같다.
어느정도 공부하고 이미지 폴더를 다시 열어보니까 대충 차이점이 보인다.
이제 전반적인 계획을 짜보자!
3. 모델 구현 계획
이번 미션은 폐렴인지 아닌지만 확인하면 끝나는 이진 분류다.
크로스 엔트로피를 손실함수로 사용하고 소프트맥스로 값을 뽑으면 될 것이다.
일단 손상된 문서를 복원하는 테스크에서 꽤 좋은 성능이 나왔던 더블 레이어 모델을 기본으로 잡고 가보자.
Transfer Learning에 Fine-Tuning까지 하라고 했으니, 어떤 Teacher 모델을 선택할지 먼저 생각해야 한다.
당장 생각나는 건 AlexNet과 ResNet 정도인데, 어제 ResNet을 연습하고 있었으니 이번 기회에 조금 더 깊게 파고들어 봐야겠다.
Classifier, Feature Extraction Half & Full 이렇게 3개로 나누어 실험해보면 될 것 같다!
최종 평가는 머신러닝 앙상블 때 열심히 공부했던 오차행렬을 적용해 보자.
그럼 시작!!
4. 데이터 로드
def develop(x):
if x == 'local':
return {
'train': './chest_xray/train',
'val': './chest_xray/val',
'test': './chest_xray/test'
}
elif x == 'cloud':
import os, sys; pip = '/content/drive/MyDrive/dev/pip'
if pip not in sys.path: sys.path.insert(0, pip)
if not os.path.exists('/content/mission6'):
os.symlink('/content/drive/MyDrive/dev/mission/mission6', '/content/mission6')
os.chdir('/content/mission6')
return {
'train': '/content/drive/MyDrive/dev/mission/mission6/chest_xray/train',
'val': '/content/drive/MyDrive/dev/mission/mission6/chest_xray/val',
'test': '/content/drive/MyDrive/dev/mission/mission6/chest_xray/test'
}
DIR = develop('local')로컬과 클라우드에 있는 모델을 동시에 돌리기 위해 폴더 경로를 쉽게 바꾸는 스위치 함수를 만들었다.
transform_train = v2.Compose([
v2.RandomResizedCrop(224, scale=(0.9, 1.0)),
v2.RandomHorizontalFlip(p=0.5),
v2.RandomRotation(10),
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True)
])
transform = v2.Compose([
v2.Resize((224, 224)),
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True)
])데이터 증강을 위한 transform 변수를 두 개로 나누었다.
증강에 사용 가능한 하이퍼 파라미터도 참 다양한 것 같다. 리사이즈, 센터크롭, 플립, 로테이션 등등,,,
어차피 폐는 양쪽에 있으니까 좌우 반전 정도는 괜찮겠지? 결과가 어찌 나올지 잘 모르겠다.
일단 해보고 나중에 수정하지 뭐
train_dataset = datasets.ImageFolder(root=DIR['train'], transform=transform_train)
val_dataset = datasets.ImageFolder(root=DIR['val'], transform=transform)
test_dataset = datasets.ImageFolder(root=DIR['test'], transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False, num_workers=4)데이터셋과 로더를 만들었다. 어제 찾은 num_workers도 추가했다. 실전에서 함 써보자고!
class_names = train_dataset.classes
print("CLASS:", class_names)
클래스는 단 두 개. 정상, 폐렴만 분류하면 된다.
근데 사실 이게 젤 어려운 건데 ㅋ,,,
5. 모델 구현
지난 번 문서 복원 테스크에서 더블레이어 모델을 만들었는데 생각보다 성능이 좋았다.
그때는 레이어 2개 X 2겹이었는데, 이번에는 2개 X 4겹을 해보자.
오늘 강의에서 보니까 클래스를 2개로 나누어서 모델을 만들더라.
나도 이번엔 클래스를 나누어서 해봐야겠다.
class DoubleConv(nn.Module):
def __init__(self, in_c, out_c):
super().__init__()
self.double_conv = nn.Sequential(
nn.Conv2d(in_c, out_c, 3, 1, 1),
nn.BatchNorm2d(out_c),
nn.ReLU(),
nn.Conv2d(out_c, out_c, 3, 1, 1),
nn.BatchNorm2d(out_c),
nn.ReLU()
)
def forward(self, x):
return self.double_conv(x)
일단 더블레이어를 만들어주는 클래스를 만들었다.
(16, 32), (32, 32) 이런 식으로 나와야 하니까 (in, out) (out, out) 이렇게 하면 될 것이다.
배치놈, 렐루를 중간중간 하나씩 넣었다.
이제 이걸 모델에 4번 적용하면 된다.
class DoubleLayerCNN(nn.Module):
def __init__(self):
super().__init__()
self.features = nn.Sequential(
DoubleConv(3, 32),
nn.MaxPool2d(2, 2),
DoubleConv(32, 64),
nn.MaxPool2d(2, 2),
DoubleConv(64, 128),
nn.MaxPool2d(2, 2),
DoubleConv(128, 256),
nn.MaxPool2d(2, 2)
)DoubleLayerCNN 클래스를 만들었다.
features 시퀀셜에 아까 만든 더블레이어 클래스와 맥스풀을 번갈아가며 넣었다.
흠,, 채널은 256까지만 하면 되려나?? 뭔가 한참 부족한 느낌이다.
self.pool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(256*7*7, 128),
nn.Dropout(0.2),
nn.Linear(128, 2)
)글로벌 풀링과 classifier 시퀀셜을 만들었다. 글로벌 풀링은 처음 써보는데,, 어떻게 될지 잘 모르겠다.
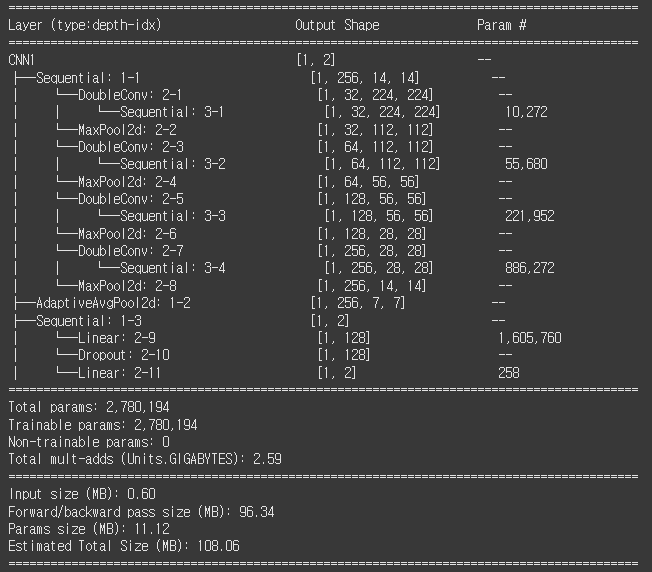
파라미터 수는 약 278만 개. 단순한 모델인 것 같은데 왤캐 많지?
def train_model(model, train_loader, val_loader, device, num_epochs=10):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
scaler = GradScaler()
for epoch in range(1, num_epochs+1):
model.train()
train_loss = 0.0
correct = 0
total = 0
loop = tqdm(train_loader, desc=f'Epoch [{epoch}/{num_epochs}]', leave=False)
for inputs, labels in loop:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
# AMP
with autocast():
outputs = model(inputs)
loss = criterion(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
train_loss += loss.item() * inputs.size(0)
_, preds = outputs.max(1)
correct += preds.eq(labels).sum().item()
total += labels.size(0)
loop.set_postfix(loss=loss.item(), acc=100.*correct/total)
train_loss /= total
train_acc = 100. * correct / total어제 알아낸 AMP 적용해 본다고 한세월 걸렸다 ㅠㅠ
어제는 분명 쉽게 됐는데, 오늘은 val 까지 추가해야 해서 뭐가 더 복잡하다.
역시 좋은 건 쉽게 얻을 수 없는 것인가...
set_postfix() 라는 함수를 처음 사용해봤다. tqdm()은 에폭마다 값을 갱신해주는데, 이건 배치마다 값을 갱신해준다. 학습 현황을 거의 초단위로 볼 수 있다. 완전 짱임.
20 에폭 돌렸다. 아니, 돌리고 싶은데 시간이 넘 오래 걸린다.
어림잡아 2시간은 넘게 걸릴 것 같다.
흠,, 오늘은 컴퓨터 켜놓고 자야겠다 ㅠㅠ 결과는 내일 일어나서 확인해야지!
이번 미션도 화이팅 해보자!!
