확실히 Transfer Learning을 하니까 분류가 잘 된다. 더 좋은 모델이 많이 생겼으면 좋겠다!!
학습시간 09:00~02:00(당일17H/누적608H)
◆ 학습내용
딥러닝으로 폐렴 환자 자동 분류
어제(6~8번)에 이어 9번 할 차례다.
9. 모델 평가
(1) 가중치 로드
가중치들이 잘자고 있어났냐며 나를 반겨준다.
제발 아무 문제 없기를...!!
model.load_state_dict(torch.load('./model/DoubleLayerCNN_0428_1.pth', map_location=device))
model_resnet50_1.load_state_dict(torch.load('./model/resnet50_1.pth', map_location=device))
model_resnet50_2.load_state_dict(torch.load('./model/resnet50_2.pth', map_location=device))
model_resnet50_3.load_state_dict(torch.load('./model/resnet50_3.pth', map_location=device))
model_densenet121_1.load_state_dict(torch.load('./model/densenet121_1.pth', map_location=device))
model_densenet121_2.load_state_dict(torch.load('./model/densenet121_2.pth', map_location=device))
model_densenet121_3.load_state_dict(torch.load('./model/densenet121_3.pth', map_location=device))
모든 가중치를 로드했다.
(2) CM & CR 지표
def evaluate_model(model, test_loader):
model.eval()
y_true = []
y_pred = []
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
with torch.amp.autocast(device_type=device.type):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
y_true.extend(labels.cpu().numpy())
y_pred.extend(preds.cpu().numpy())
print("▶ Confusion Matrix & Classification Report")
print(confusion_matrix(y_true, y_pred))
print(classification_report(y_true, y_pred, target_names=['NORMAL', 'PNEUMONIA']))일단 더블레이어 평가할 때 사용했던 CM & CR 함수를 그대로 사용하려고 한다.
A. DoubleLayerCNN
evaluate_model(model, test_loader)
B. ResNet50, Classifier Tuning
evaluate_model(model_resnet50_1, test_loader)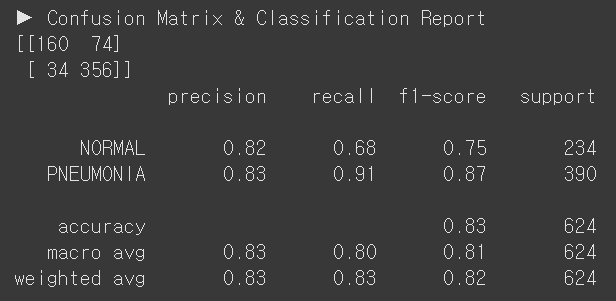
C. ResNet50, Partial Fine Tuning
evaluate_model(model_resnet50_2, test_loader)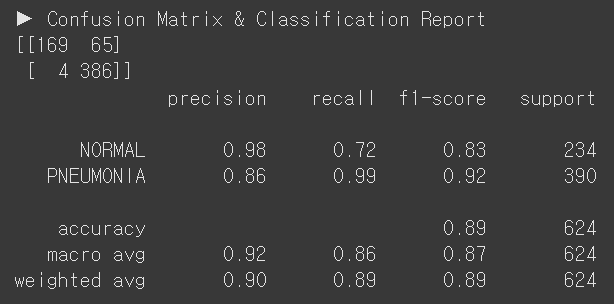
D. ResNet50, Full Fine Tuning
evaluate_model(model_resnet50_3, test_loader)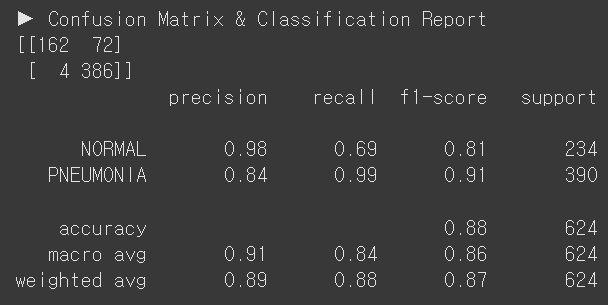
E. DenseNet121, Classifier Tuning
evaluate_model(model_densenet121_1, test_loader)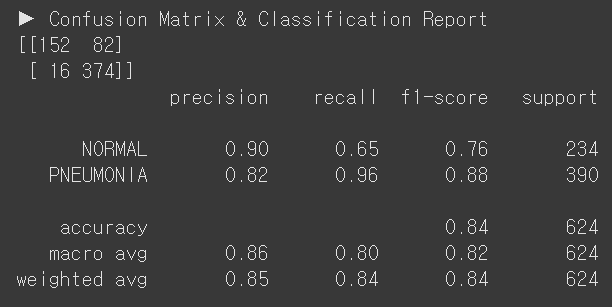
F. DenseNet121, Partial Fine Tuning
evaluate_model(model_densenet121_2, test_loader)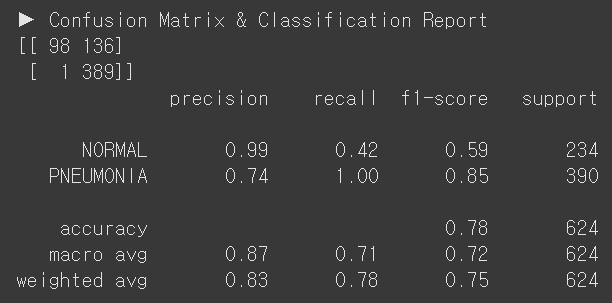
G. DenseNet121, Full Fine Tuning
evaluate_model(model_densenet121_3, test_loader)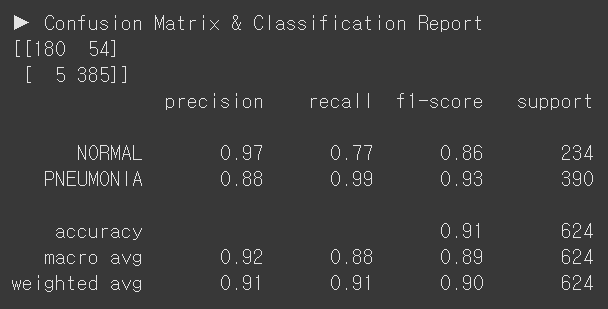
(3) ROC-AUC 지표
ROC(Receiver Operating Characteristic curve)는 모델의 임곗값을 변화시키며 False Positive Rate(X축) True Positive Rate(Y축)의 관계를 나타낸 곡선이다.
ROC-AUC(Receiver Operating Characteristic Area Under the Curve)는 ROC 곡선 아래의 면적으로, 모델이 다양한 임곗값에서 얼마나 잘 분류할 수 있는지 나타내는 지표이다. 일반적으로 1에 가까울수록 좋은 수치다. ROC-AUC는 특정 임곗값에 의존하지 않고, 모델의 전반적인 성능을 평가할 수 있다는 장점이 있다.
쉽게 말해, 왼쪽 상단 모서리에 가까울 수록 좋은 모델이라는 뜻.
plot_multi_roc(
models,
test_loader,
device,
dot_labels=dot_labels,
figsize=(14, 10),
title_fontsize=20,
label_fontsize=16,
legend_fontsize=14
)지선생 도움으로 시각화 함수를 하나 만들었다.
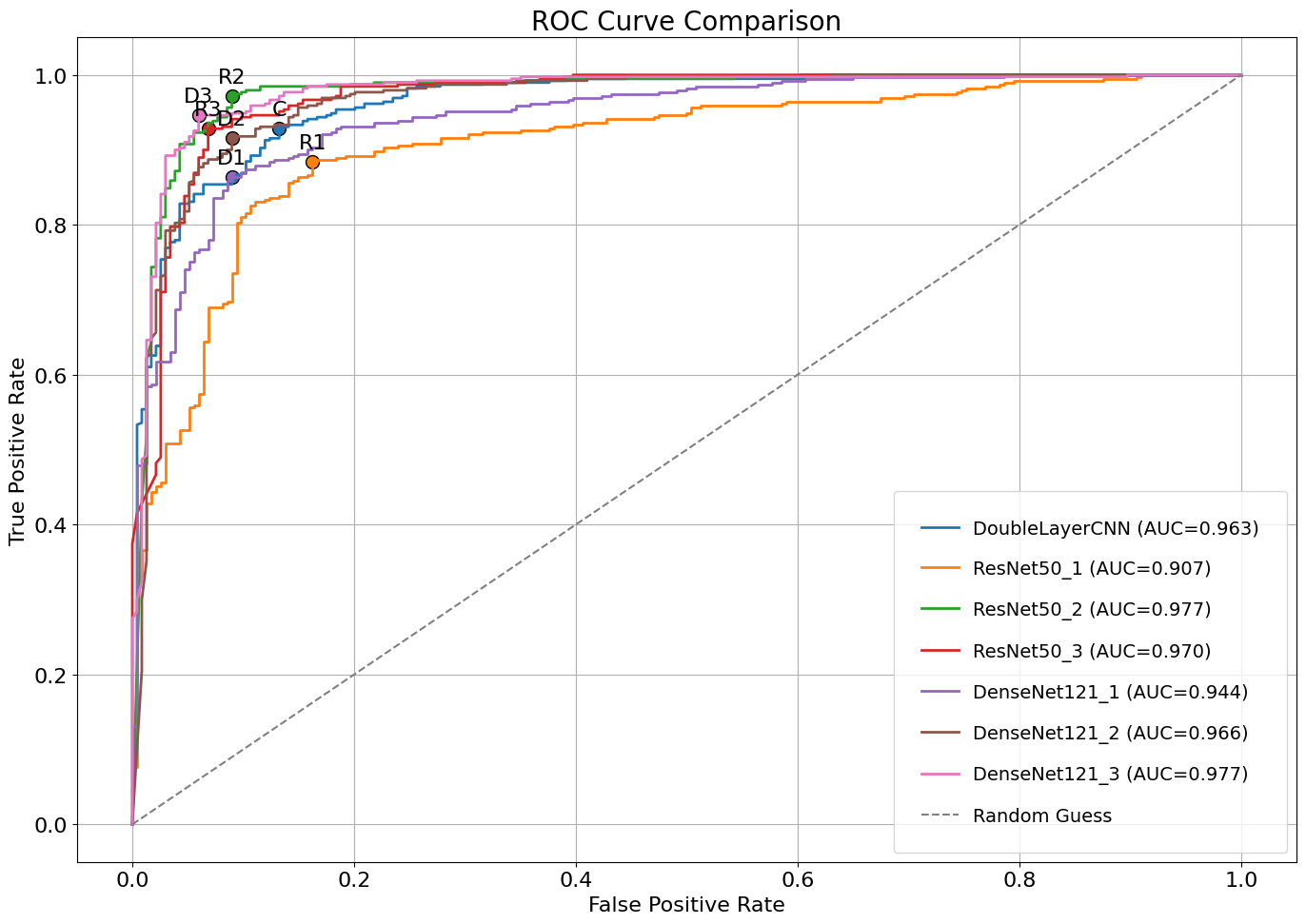
C = A. DoubleLayerCNN
R1 = B. ResNet50, Classifier Tuning
R2 = C. ResNet50, Partial Fine Tuning
R3 = D. ResNet50, Full Fine Tuning
D1 = E. DenseNet121, Classifier Tuning
D2 = F. DenseNet121, Partial Fine Tuning
D3 = G. DenseNet121, Full Fine Tuning
그래프로 보면 D3, R2, R3 성능이 좋은 것 같다.
10. 모델 성능 비교
(1) 지표 수치 분석
A. DoubleLayerCNN
Train 정확도 모름 & 로스 모름
Test 정확도 85% & 폐렴 리콜 99% & 정상 리콜 62%
B. ResNet50, Classifier Tuning
Train 정확도 92.5% & 로스 0.2204
Test 정확도 83% & 폐렴 리콜 91% & 정상 리콜 68%
C. ResNet50, Partial Fine Tuning
Train 정확도 99%, 로스 0.0202
Test 정확도 89% & 폐렴 리콜 99% & 정상 리콜 72%
D. ResNet50, Full Fine Tuning
Train 정확도 99.3%, 로스 0.0175
Test 정확도 88% & 폐렴 리콜 99% & 정상 리콜 69%
E. DenseNet121, Classifier Tuning
Train 정확도 93% & 로스 0.1894
Test 정확도 84% & 폐렴 리콜 96% & 정상 리콜 65%
F. DenseNet121, Partial Fine Tuning
Train 정확도 99.4% & 로스 0.0154
Test 정확도 78% & 폐렴 리콜 100% & 정상 리콜 42%
G. DenseNet121, Full Fine Tuning
Train 정확도 98.9% & 로스 0.0283
Test 정확도 91% & 폐렴 리콜 99% & 정상 리콜 77%
| 항목 | 모델 | Train Acc | Train Loss | Test Acc | 정상 Recall | 폐렴 Recall | Correct | Wrong |
|---|---|---|---|---|---|---|---|---|
| A | DoubleLayerCNN | – | – | 85% | 62% | 99% | 533 | 91 |
| B | ResNet50, Classifier Tuning | 92.5% | 0.2204 | 83% | 68% | 91% | 516 | 108 |
| C | ResNet50, Partial Fine Tuning | 99.0% | 0.0202 | 89% | 72% | 99% | 555 | 69 |
| D | ResNet50, Full Fine Tuning | 99.3% | 0.0175 | 88% | 69% | 99% | 548 | 76 |
| E | DenseNet121, Classifier Tuning | 93.0% | 0.1894 | 84% | 65% | 96% | 526 | 98 |
| F | DenseNet121, Partial Fine Tuning | 99.4% | 0.0154 | 78% | 42% | 100% | 487 | 137 |
| G | DenseNet121, Full Fine Tuning | 98.9% | 0.0283 | 91% | 77% | 99% | 565 | 59 |
(2) 결론
7개 모델을 종합하면,
G. DenseNet121 Full Fine Tuning 모델이 가장 좋아 보인다.
근거는 다음과 같다.
Overall Accuracy 가장 높음
(전체 문제 중에서 맞춘 비율)
- DenseNet121 Full FT: 0.91
- ResNet50 Partial FT: 0.89
- ResNet50 Full FT: 0.88
Macro Avg F1-score 가장 높음
(정확도와 재현율 평균) + 샘플 수 미반영
- DenseNet121 Full FT: 0.89
- ResNet50 Partial FT: 0.87
- ResNet50 Full FT: 0.86
Weighted Avg F1-score 가장 높음
(정확도와 재현율 평균) + 샘플 수 반영
- DenseNet121 Full FT: 0.90
- ResNet50 Partial FT: 0.89
- ResNet50 Full FT: 0.87
다른 모델은 NORMAL 리콜이 상대적으로 낮아, 실제 운영 시 정상 환자를 폐렴으로 오진할 위험이 더 높다.
따라서 DenseNet121 Full Fine Tuning 모델이 전반적인 균형 측면에서 가장 안정적이고 좋은 선택이라 할 수 있다.
12. 마지막 도전
이대로 끝낼 수 없지.
생각해 보니까 내가 10에폭만 돌렸다.
그래서 만족스러운 성능이 안 나온 것 같다는 생각을 했다.
model_densenet121_final = densenet121(weights=DenseNet121_Weights.IMAGENET1K_V1)
model_densenet121_final.classifier = nn.Linear(1024, 2)
for name, param in model_densenet121_final.named_parameters():
print(f"{name}: {param.requires_grad}")
model_densenet121_final = model_densenet121_final.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model_densenet121_final.parameters(), lr=1e-4)
train_model(model_densenet121_final, train_loader, val_loader, epochs=100)
torch.save(model_densenet121_final.state_dict(), './model/densenet121_final.pth')가장 좋은 성능을 보여준 DenseNet121 Full Fine Tuning을 더 학습시켜 보려고 한다.
100에폭 돌리면 10에폭 보다는 결과가 좋겠지?
학습 시작. 후후 끝장을 봐주마!!!
====================
학습 돌리는 동안 할게 없어서 뽀모도로 타이머 자동화 프로그램을 만들었다.
프로그램을 처음 만들어 봐서 비주얼은 그냥 엑셀 VBA 수준이다.
그래도 설정한 시간마다 자동으로 알람 울렸다가 꺼졌다가 재설정되니까 진짜 좋다. 한번만 켜두면 손댈 게 없다.
이제 편하게 뽀모도로 하자고!!
====================
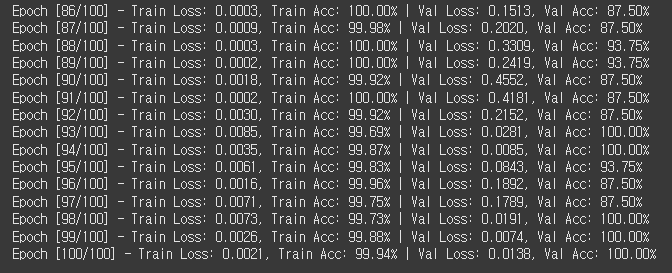
타이머를 만들고 나니 마침 100에폭 학습이 끝났다.
확실히 DenseNet 풀튜닝인데도 학습이 빠르다. ResNet이었으면 오늘도 켜놓고 자야 했겠지..?
일단 Train set 기준으로 보면 로스가 0.0002 까지도 내려간다.
근데 이게 계속 내려가기만 하는 게 아니구나.
중간에 베스트 값이 나오면 저장하는 방식으로 해야하나??
evaluate_model(model_densenet121_final, test_loader)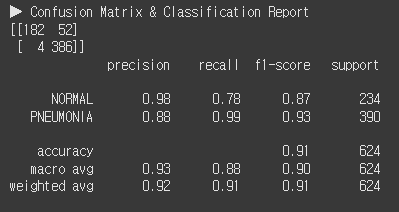
어쨌든 CMCR을 찍어보니 정확도가 91% 나온다. 정상 리콜은 78%로 10에폭 돌렸을 때보다 1% 더 높다.
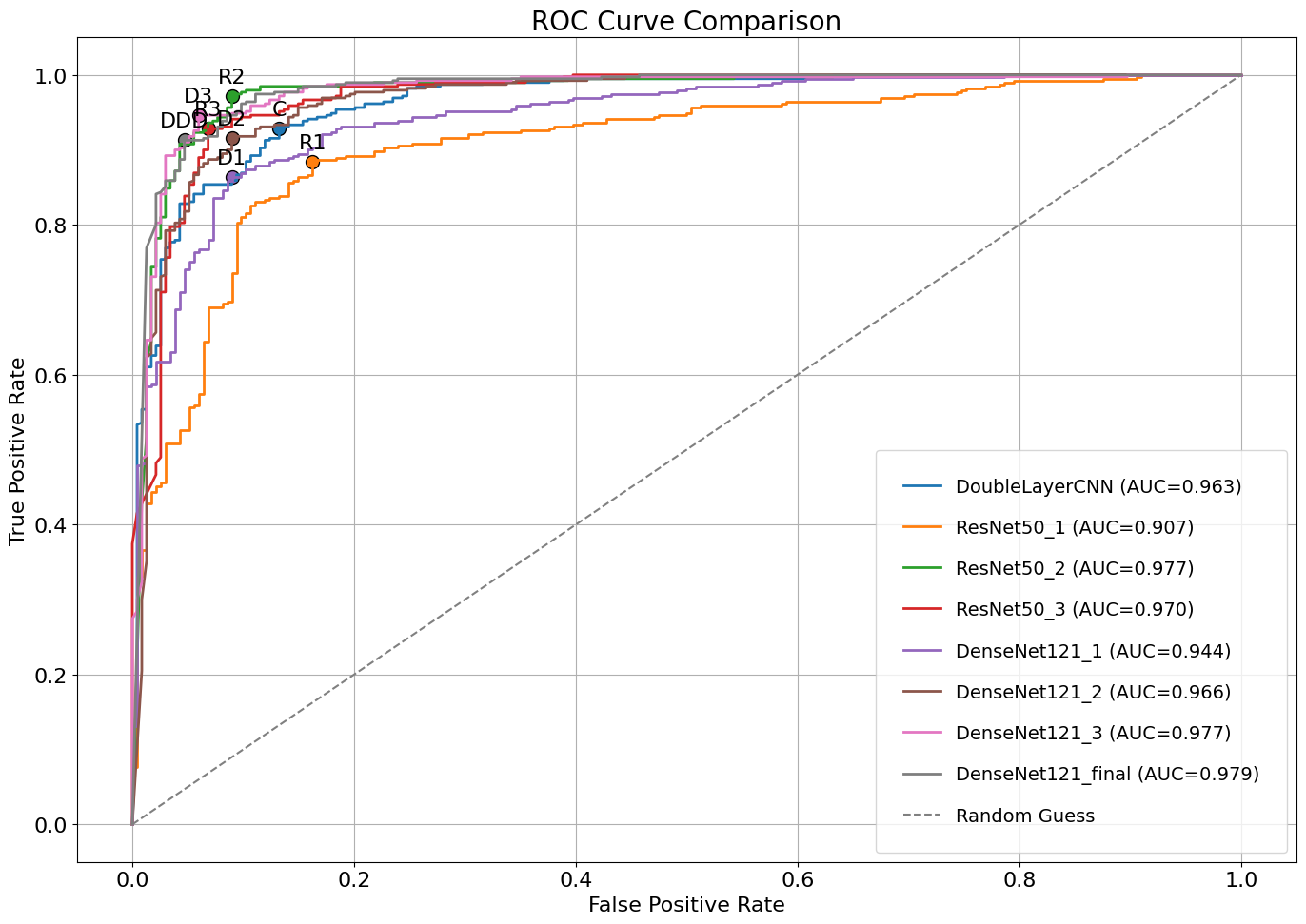
ROC-AUC로 보면 10에폭 돌렸을 때보다 AUC 수치가 0.002 정도 높다.
10에폭이나 100에폭이나 성능 차이가 크게 없다는 것인데,,,
그렇다면 이건 학습량의 문제가 아니라 데이터의 문제라는 뜻이다.
결국, 전이학습은 데이터 전처리와 증강을 얼마나 섬세하게 하냐에 승부가 갈린다.
이번 미션 덕분에 정말 중요한 깨달음을 얻었다!!
다음에 할 때는 전처리와 증강에 조금 더 신경을 써보자!
근데,,, 보고서 언제 적지 ㅠㅠ
