와,,, 오랜만에 하니까 진짜 어렵다.
학습시간 10:00~18:00(당일8H/누적616H)
◆ 학습내용
데이터 프레임 복습
문제 1
loan_df라는 DataFrame에서 각 컬럼의 데이터 타입과 결측치가 아닌 값의 개수를 확인하려면 어떤 코드를 작성해야 하는지 고르세요.
loan_df.info()loan_df라는 DataFrame의 통계 정보를 요약해서 보려면 어떤 코드를 작성해야 하는지 고르세요.
loan_df.describe()loan_df라는 DataFrame을 applicant_income 컬럼을 기준으로 내림차순 정렬해서 보려면 어떤 코드를 작성해야 하는지 고르세요.
loan_df.sort_values(by='applicant_income', ascending=False)loan_df라는 DataFrame의 로우의 개수와 컬럼의 개수를 확인하려면 어떤 코드를 작성해야 하는지 고르세요.
loan_df.shape문제 2
loan_df의 property_area 컬럼 지역별 비중을 한눈에 확인할 수 있도록 코드 작성
loan_df['property_area'].value_counts()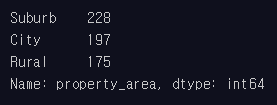
오잉? 틀렸다.
loan_df['property_area'].value_counts(normalize=True)
아하 노말라이즈를 해야하는군.
문제 3
대출이 승낙된 사람들 중에서 자영업자가 아니고, 수입이 중간값 이상인 사람들을 추출
group1 = loan_df[
(loan_df['loan_status'] == 'Y') &
(loan_df['self_employed'] == 'N') &
(loan_df['income'] >= loan_df['income'].median())
]
group1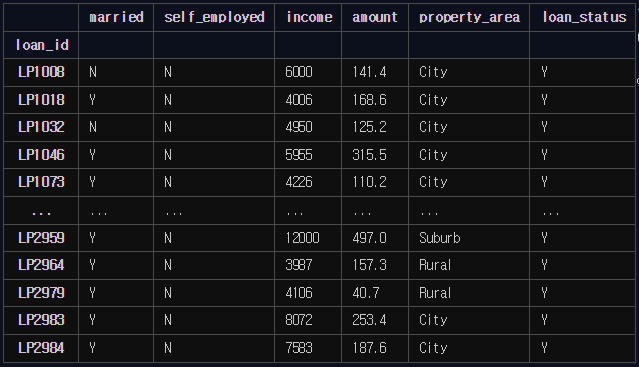
살짝 당황했지만 정답!
loan_df에서 loan_status 컬럼을 삭제해 주세요.
loan_df = loan_df.drop(columns='loan_status')
loan_df
아직까진 쉽다.
문제 4
cellphone_df에서 중복값은 1개씩만 남기고 나머지는 삭제해 주세요.
cellphone_df = cellphone_df.drop_duplicates()
cellphone_dfcellphone_df에서 가격을 기준으로 이상점으로 볼 수 있는 데이터는 삭제해 주세요.
q1 = cellphone_df['price'].quantile(0.25)
q3 = cellphone_df['price'].quantile(0.75)
iqr = q3 - q1
lower_bound = q1 - 1.5 * iqr
upper_bound = q3 + 1.5 * iqr
cellphone_df = cellphone_df[(cellphone_df['price'] >= lower_bound) & (cellphone_df['price'] <= upper_bound)]
cellphone_df와 오랜만에 하니까 기억이 안 난다. 1사분위, 3사분위 코드는 진짜 외워야겠다...
brand, name, size 컬럼에 있는 데이터 가공
brand 컬럼 첫 글자는 대문자로, 나머지 글자는 소문자
name 컬럼 iPhone 14 Pro (256GB) 모델명, 용량 분리
size 컬럼 " 기호를 없앤 뒤 숫자 타입으로 변환
# 대소문자 표기 통일하기
cellphone_df['brand'] = cellphone_df['brand'].str.capitalize()
# 문자열 분리하기
cellphone_df['model'] = cellphone_df['name'].str.split('(').str[0]
cellphone_df['capacity'] = cellphone_df['name'].str.split('(').str[1]
# 불필요한 문자 제거하기
cellphone_df['model'] = cellphone_df['model'].str.strip()
cellphone_df['capacity'] = cellphone_df['capacity'].str.replace(')', '', regex=False)
# 기존 컬럼 삭제하기
cellphone_df = cellphone_df.drop(columns='name')
# 불필요한 문자 제거하고 데이터 타입 변경하기
cellphone_df['size'] = cellphone_df['size'].str.replace('"', '', regex=False).astype('float')
cellphone_df이것도 오랜만에 하니까 헷갈린다...
문제 5
patient_df에 있는 각 환자의 BMI 값을 계산해서 bmi라는 컬럼에 저장
patient_df['bmi'] = (patient_df['weight'] / (patient_df['height'] ** 2)).round(1)
patient_df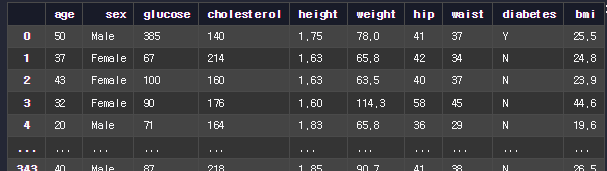
weight 컬럼이 0과 1 사이의 값을 가지도록 정규화(Min Max Normalization)
헉 정규화 공식이 생각이 안 난다.
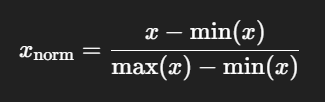
아 맞다 이거였찌...
patient_df['weight'] = (patient_df['weight'] - patient_df['weight'].min()) / (patient_df['weight'].max() - patient_df['weight'].min())
patient_df이렇게 수동으로 해도 되고,
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
patient_df['weight'] = scaler.fit_transform(patient_df[['weight']])sklearn 쓰면 더 쉽게 가능...?
weight 컬럼에 있는 값들이 평균은 0, 표준편차는 1이 되도록 표준화(Standardization)
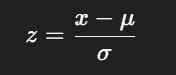
μ: 평균 (mean()) & σ: 표준편차 (std())
patient_df['weight'] = (patient_df['weight'] - patient_df['weight'].mean()) / patient_df['weight'].std()
수동 계산
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
patient_df['weight'] = scaler.fit_transform(patient_df[['weight']])
sklearn 계산
비만도를 분류해서 obesity라는 컬럼에 저정
18.5 미만(저체중): under
18.5 이상 25 미만(정상): healthy
25 이상 30 미만(과체중): over
30 이상(비만): obese
bmi_max = patient_df['bmi'].max() + 1
bins = [0, 18.5, 25, 30, bmi_max]
labels = ['under', 'healthy', 'over', 'obese']
patient_df['obesity'] = pd.cut(
patient_df['bmi'],
bins=bins,
labels=labels,
right=False
)
patient_dfcut함수는 처음 써본다. 어렵다 어려워...
문제 6
delivery.csv에서 2022년 10월 17일의 데이터만 뽑아서 확인. 주문 시각(order_time)을 기준으로 데이터를 추출
delivery_df['order_time'] = pd.to_datetime(delivery_df['order_time'])
delivery_df = delivery_df.set_index('order_time')
delivery_df.loc['2022-10-17']
먼가 배운 것 같으면서도 기억이 안 난다.
주문 시각(order_time)과 배달 소요 시간(time_taken)을 가지고 배달 완료 시간을 계산해서 DataFrame에 delivery_time이라는 컬럼을 추가
delivery_df['time_taken'] = pd.to_timedelta(delivery_df['time_taken'], unit='T')
delivery_df['delivery_time'] = delivery_df['order_time'] + delivery_df['time_taken']
delivery_df
unit='T' 이게 이해가 안 된다. unit='m'로 해도 되는 거 아닌가..?
문제 7
sales_2020, sales_2021, sales_2022 세 개의 DataFrame을 하나로 합쳐서 sales_df라는 변수에 저장
sales_df = pd.concat([sales_2020_df, sales_2021_df, sales_2022_df])
sales_dfconcat은 참 쓸모가 많은 것 같다.
asteroid_df, orbit_df 데이터를 inner join한 결과물을 nasa_df라는 변수에 저장
nasa_df = pd.merge(asteroid_df, orbit_df, left_on='id', right_on='asteroid_id')
nasa_df
merge함수가 익숙하지 않다 ㅠ 데이터프레임이 갑자기 어렵게 느껴짐
asteroid_df와 orbit_df을 inner join한 결과물을 nasa_df라는 이름의 변수에 저장
nasa_df = asteroid_df.join(orbit_df, how='inner')
nasa_dfmerge와 join은 비슷한 것 같으면서 다르네.
-> 둘 다 조인 연산을 하지만 merge가 더 기능이 많고 어렵다고 함
문제 8
'olympic.csv'에 Groupby를 사용해서 각 종목별로 메달리스트들의 평균 키와 체중을 계산
olympic_df.groupby('sport')[['height', 'weight']].mean()
올림픽 메달리스트들의 키와 체중의 평균을 운동 종목별, 성별 기준으로 계산
olympic_df.groupby(['sport', 'sex'])[['height', 'weight']].mean()만능 그룹바이
메달리스트들의 나이의 최솟값, 최댓값을 운동 종목별로 계산
olympic_df.groupby('sport')['age'].agg(['min', 'max'])
groupby.agg 하면 컬럼 2개를 여러 통계로 시각화할 수 있다.
몬트리올 올림픽의 국가별 금메달, 은메달, 동메달의 개수를 계산.
결측값은 0으로 채우고, 금메달, 은메달, 동메달 개수, 나라 이름 순서대로 내림차순 정렬
pd.pivot_table( olympic_df, index='team', columns='medal', aggfunc='size' ).fillna(0).sort_values( by=['1st', '2nd', '3rd', 'team'], ascending=False )
판다스 피벗테이블은 처음 본다. 왠지 잘만 쓰면 엄청 좋을 것 같다.
