지금까지 한 CNN은 튜토리얼 수준이었구나...
학습시간 09:00~02:00(당일17H/누적633H)
◆ 학습내용
1. Object Detection이란?
(1) 종류
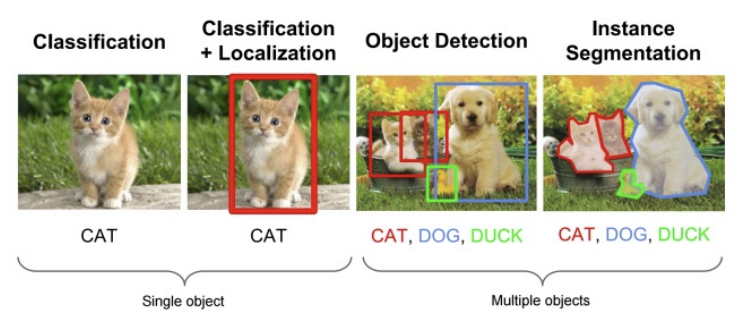
- Classification: 이미지 전체 또는 특정 영역에 대해 객체의 클래스(정체)를 판별
- (예: "이 이미지는 고양이다")
- Localization: 이미지 내 객체의 위치를 예측 (bounding box로 표현)
- (예: "고양이가 이미지의 중앙에 있음")
- Object Detection: 여러 객체의 클래스와 위치를 동시에 예측
- (예: "고양이 좌측, 강아지 우측에 있음")
- Segmentation: 객체의 형태를 픽셀 단위로 분할
- (Bounding box보다 더 정밀한 윤곽선 표현)
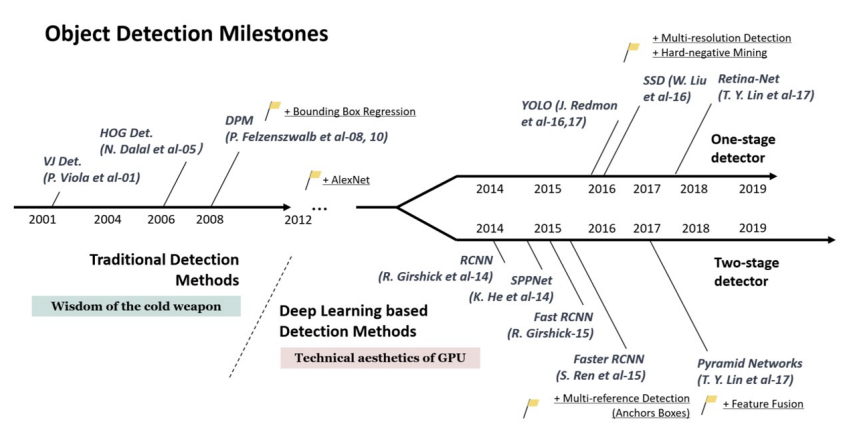
(2) 역사
(3) 모델 유형
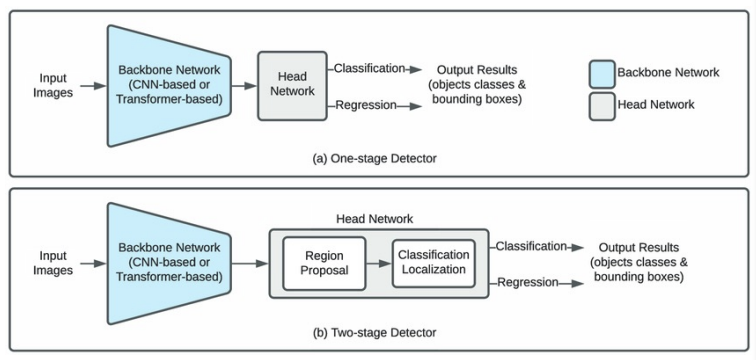
A. 2-stage Detector
- Stage 1 – 영역 제안 (Region Proposal) 이미지에서 객체가 있을 법한 후보 영역을 먼저 추출 (예: Selective Search, RPN 등)
- Stage 2 – 분류 및 위치 정밀 보정 제안된 각 영역에 대해 객체의 클래스를 예측하고 정확한 bounding box를 재조정
- 특징
- 정확도(Precision)가 높음
- 처리 속도는 느림 (특히 R-CNN은 매우 느림)
- 대표 모델
- R-CNN
- Fast R-CNN
- Faster R-CNN (Region Proposal Network 도입으로 속도 개선)
B. 1-stage Detector
- 단일 단계에서 전체 이미지 처리 전체 이미지를 한 번에 처리하여 객체의 위치와 클래스를 동시에 예측
- 특징
- 속도가 빠름 (실시간 처리 가능)
- 정확도는 2-stage보다 다소 낮을 수 있음 (최근 모델들은 개선됨)
- 대표 모델
- YOLO (You Only Look Once)
- SSD (Single Shot MultiBox Detector)
(4) 객체 탐지가 어려운 이유
A. 동시 예측이 어려움
- 이미지에서 여러 객체의 분류와 위치 예측을 동시에 수행해야 함
B. 스케일과 형태가 다양함
- 객체마다 크기, 모양, 방향, 위치가 달라서 일관된 예측이 어려움
C. 이미지가 명확하지 않음
- 배경이 복잡하거나 객체 간 겹침(Occlusion) 이 발생해 인식이 어려움
- 대부분의 영역이 배경으로 구성되어 있어 객체 비중이 낮음
D. 실시간 처리가 까다로움
- 특히 영상에서의 객체 탐지는 속도와 정확도를 모두 요구함
E. 데이터와 어노테이션이 부족함
- 정확한 학습을 위해 정밀한 박스 라벨링이 필요한데, 수작업 비용이 큼
- 탐지용 공개 데이터셋도 상대적으로 적음
(5) 평가 지표
A. IoU (Intersection over Union)
- 정의: 예측한 바운딩 박스와 실제 바운딩 박스의 겹치는 영역(IoU) 비율
- 계산:
IoU = (예측 박스 ∩ 실제 박스) / (예측 박스 ∪ 실제 박스)
- 해석:
- IoU ≥ 0.5일 경우 일반적으로 정탐(True Positive) 으로 간주
- 값이 높을수록 정확하게 위치 예측한 것
- 예시:
- IoU ≈ 0.4 → Poor
- IoU ≈ 0.7 → Good
- IoU ≈ 0.9 → Excellent
B. mAP (mean Average Precision)
- 정의: Precision-Recall 곡선의 면적을 클래스별로 구해 평균
- 구성 요소:
- 정확도(Accuracy):
(TP + TN) / (전체) - 정밀도(Precision):
TP / (TP + FP) - 재현율(Recall):
TP / (TP + FN)
- 정확도(Accuracy):
- 의미:
- 다양한 클래스, 다양한 IoU 기준(예: 0.5, 0.75 등)에서의 모델 평균 성능
- 객체 탐지 대회에서 공식 평가 지표로 사용됨 (ex. COCO 기준 mAP@[.5:.95])
2. 2-Stage Detection
(1) Localization
지금까지 배운 CNN 신경망으로 어떻게 이미지를 Localize 할 수 있을까??
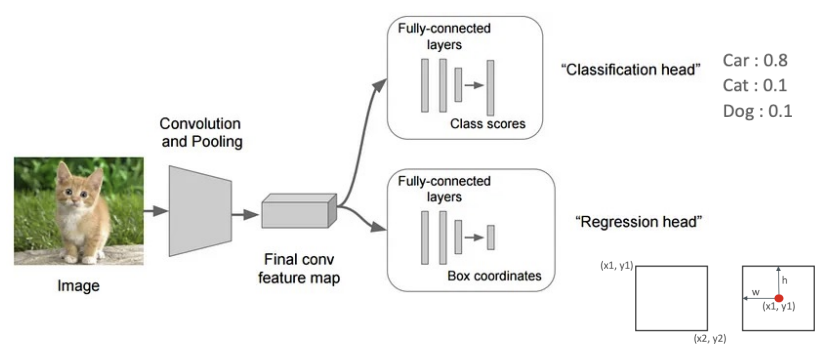
Classification, Regression Head를 동시에 진행하면 된다.
Fully-connected layer → 클래스별 확률(score) 출력
예시:
Car: 0.8
Cat: 0.1
Dog: 0.1
가장 높은 확률의 클래스를 최종 예측 결과로 사용 후
바운딩 박스 좌표(x1, y1, x2, y2) 또는 (x, y, w, h) 형식으로 출력
하지만!!! Bounding Box 회귀를 바로 하면 문제가 있다.
(2) Bounding Box 문제점
객체탐지에 Bounding Box 회귀를 바로 적용하면 다음과 같은 이유로 문제 발생
A. 검색 공간이 너무 넓음
- 전체 이미지에서 모든 위치와 크기를 탐색해야 하므로 학습 효율이 매우 낮아짐
- → 효율적인 객체 탐색 어려움
B. 초기 추정치 부재
- 사전 후보 영역 없이 시작되면 네트워크가 불안정하게 학습되며
- → 잘못된 위치로 수렴할 위험이 커짐
C. 데이터의 불균형
- 전체 이미지 중 실제 객체가 있는 영역은 적고 배경이 대부분
- → 네트워크가 배경 위주로 학습될 수 있음
D. 학습 복잡도 증가
- 다양한 크기·비율·위치를 동시에 회귀해야 하므로
- → 정확한 바운딩 박스 예측이 어려워지고, 성능 저하
따라서, Region Proposal과 2-stage detect 기법으로 문제 해결
(3) Region Proposal
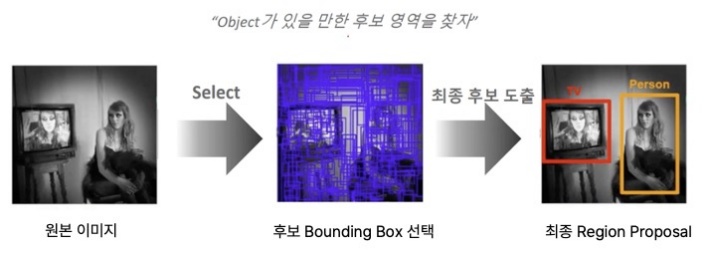
이미지 내에서 객체가 있을 가능성이 높은 영역만 골라내 후보 영역(Proposal) 으로 제시하는 기법
-
연산 비용 절감
- 전체 이미지의 모든 위치를 탐색하지 않고,
→ 후보 영역만 세밀하게 처리함으로써 계산량 대폭 감소
- 전체 이미지의 모든 위치를 탐색하지 않고,
-
정확도 향상
- 후속 단계(분류/위치 회귀)를 제안된 영역에 집중시켜
→ 잘못된 탐지를 줄이고 성능을 높임
- 후속 단계(분류/위치 회귀)를 제안된 영역에 집중시켜
(4) R-CNN
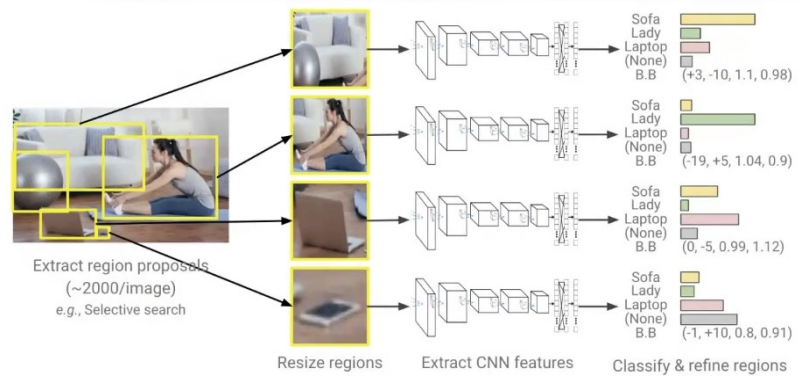
이미지에서 객체의 위치(바운딩 박스)와 클래스(종류)를 동시에 예측
A. 작동 흐름
- Region Proposal 생성
- Selective Search를 통해 후보 영역(Region) 수천 개 추출
- CNN을 통한 특징 추출
- 각 후보 영역을 CNN(예: VGGNet) 에 넣어 고차원 feature 벡터로 변환
- SVM 분류기 적용
- 추출된 feature를 기반으로 SVM을 이용해 객체 클래스 분류
- Bounding Box 회귀 적용
- 위치 정밀 보정을 위한 회귀기(Regression) 를 따로 학습하여 바운딩 박스 좌표 보정
B. 장점
- 높은 정확도
- CNN 기반 특징 추출 → 기존 HoG+SVM 방식보다 훨씬 높은 성능
- 사전 학습된 모델 활용 가능
- ImageNet 등에서 미리 학습된 CNN을 전이 학습으로 사용 가능
C. 단점
- CPU 기준 한 장당 약 50초 소요 (VOC 2007 기준)
- Selective Search에 너무 많은 연산 필요
- 저장 공간 과다
- CNN 결과를 디스크에 저장 → 이후 SVM에 입력 → 중간 저장 부담 큼
- End-to-End 학습 불가
- 전체 과정이 각 파트(Sel. Search / CNN / SVM / 회귀기) 로 나뉨
(5) Fast R-CNN
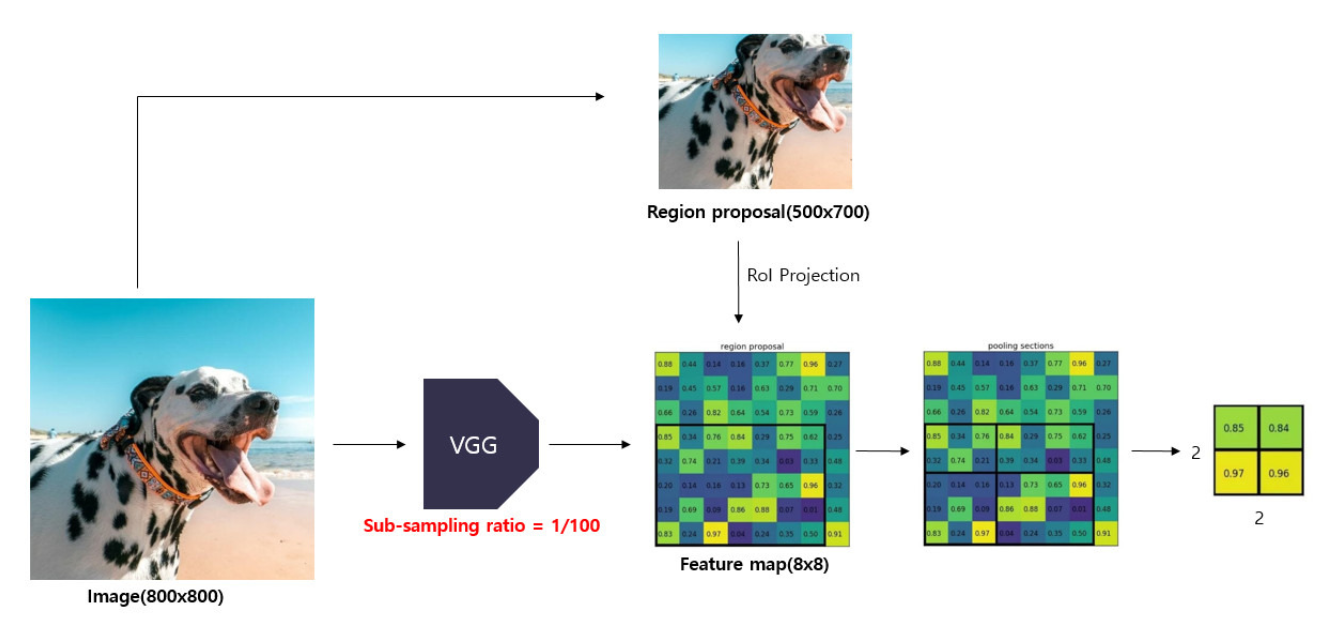
CNN을 전체 이미지에 한 번만 적용하고, 공유된 feature map 위에서 각 Region Proposal(ROI)에 대해 클래스와 바운딩 박스 좌표를 동시에 예측
→ R-CNN의 속도 병목(중복 CNN 연산)을 개선한 모델
A. 작동 흐름
- CNN 연산 한 번만 수행 → feature map 생성
- ROI Pooling: 다양한 크기의 ROI를 고정 크기(예: 7×7)로 변환
- Fully Connected Layer를 통해
- 클래스 분류 + 바운딩 박스 회귀를 동시에 수행
- 전체 구조가 End-to-End로 학습 가능
B. 장점
- End-to-End 학습 가능
- 분류와 회귀를 하나의 네트워크에서 동시에 최적화
- 공유 합성곱 특징
- CNN 연산을 한 번만 수행 → 중복 제거로 속도 향상
- ROI Pooling 도입
- 고정 크기 특징 벡터 생성 가능
- 속도 향상
- R-CNN 대비 학습 속도 9배↑, 테스트 속도 최대 213배↑
- 저장 공간 효율화
- 디스크 저장 없이 학습 가능
C. 단점
- ROI 품질 의존
- Region Proposal(예: Selective Search)이 부정확하면 전체 성능 저하
- 작은 객체 탐지 어려움
- 고정 해상도 처리로 인해 작은 객체는 놓칠 수 있음
- 메모리 사용량 증가
- 깊은 네트워크 사용 시 GPU 자원 부담
- 스케일 변화에 민감
- 다양한 크기의 객체에 대한 대응이 부족
- → Multi-scale 기법 필요
(6) Faster R-CNN
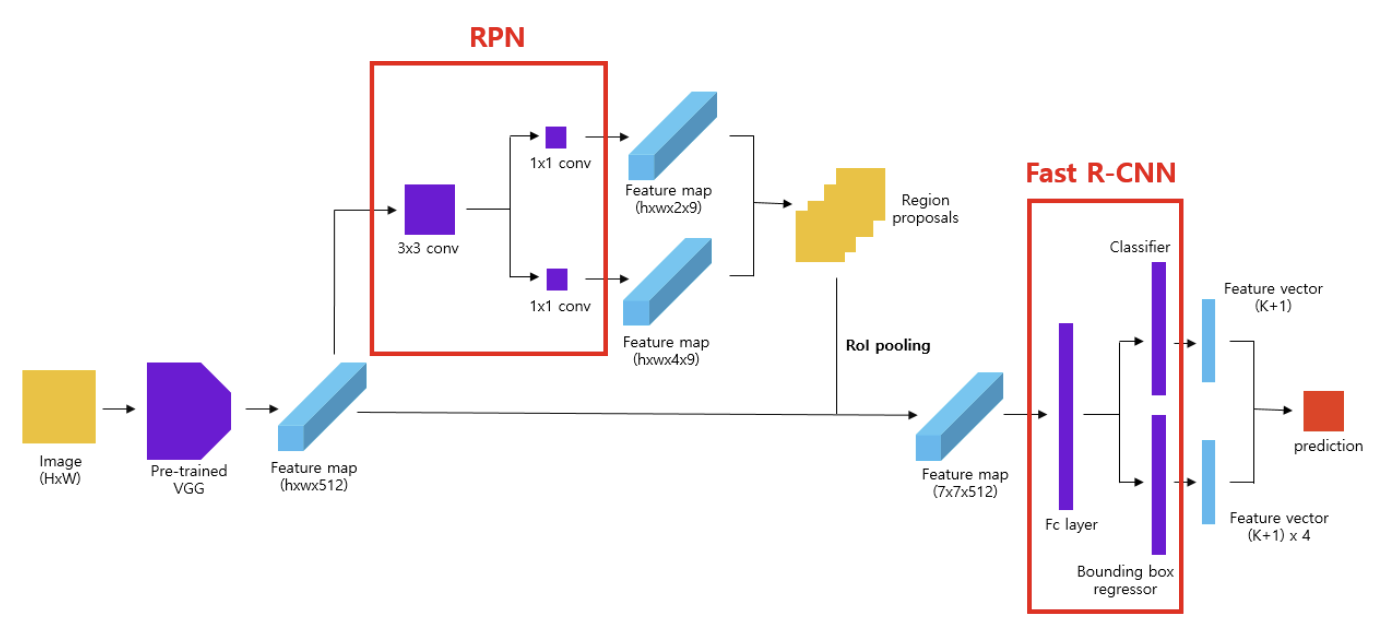
R-CNN과 Fast R-CNN의 병목 원인이던 Selective Search 기반 후보 영역 생성을 CNN 내부로 통합
→ Region Proposal Network (RPN) 을 도입하여 속도 및 성능 개선
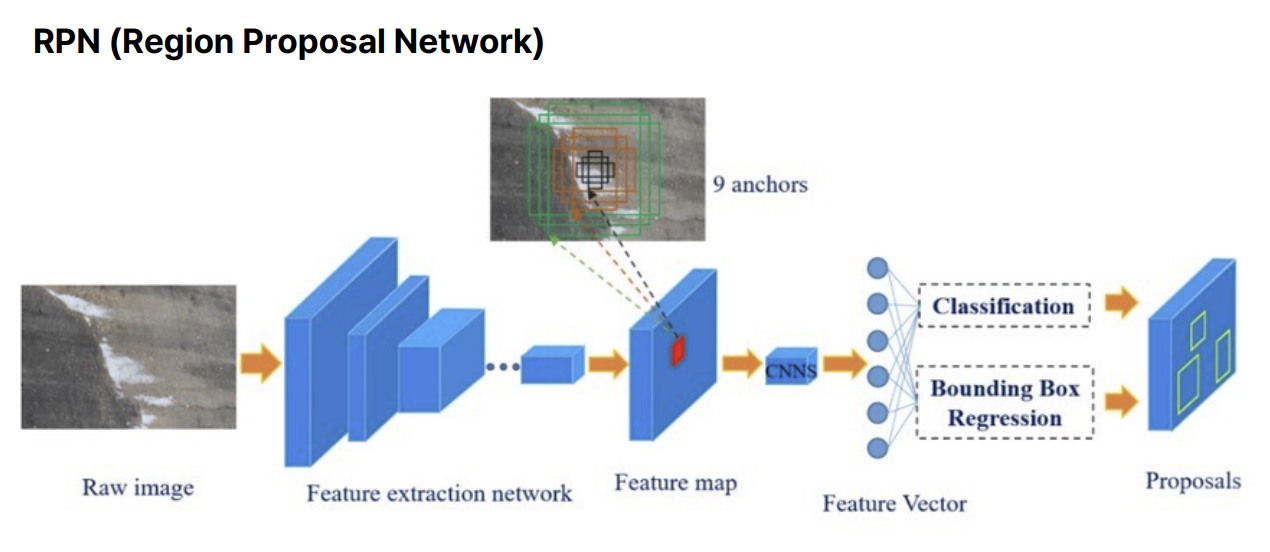
A. 작동 흐름
- CNN Backbone으로 전체 이미지의 feature map 추출
- RPN을 통해 여러 anchor에서 객체 존재 여부 + 위치 회귀를 예측
- ROI Pooling을 통해 RPN이 제안한 영역을 고정 크기로 변환
- Fast R-CNN 분류기로 클래스 예측 + 바운딩 박스 좌표 보정
B. 장점
- Selective Search 제거 → End-to-End 통합 구조 완성
- 속도와 정확도 동시 향상
- 학습 가능한 후보 영역 생성기(RPN) 내장
- 다양한 스케일/비율의 anchor 적용 가능
C. 핵심 구성: RPN (Region Proposal Network)
- 목표: 사전 정의된 anchor를 기준으로 객체가 있을 법한 region proposal 생성
- 회귀: Anchor를 실제 객체 경계에 맞게 조정
- 분류: Anchor가 객체인지(positive) or 배경인지(negative) 판별
D. RPN의 작동 방식
- CNN backbone의 feature map 위에서 슬라이딩 윈도우 방식으로 각 위치에 대해 9개의 anchor 배치 (스케일 × 비율 조합)
- 각 anchor에 대해 두 가지 예측 수행:
- 분류 (cls): 객체인지 배경인지 (2-class softmax)
- 회귀 (reg): 바운딩 박스 좌표 오프셋
(tx, ty, tw, th)
E. Anchor Box 개념 및 처리
- 모든 anchor를 학습에 사용하는 것이 아님 → 경계를 넘는 anchor는 제외, 손실 계산에 불필요한 영향 방지
- Anchor Labeling 기준
- Positive: IoU ≥ 0.7 or 가장 높은 IoU
- Negative: IoU ≤ 0.3
- Ignored: 그 외 (loss 계산에서 제외)

📌 2-Stage Detection 요약
| 구분 | 설명 |
|---|---|
| 대표 모델 | R-CNN, Fast R-CNN, Faster R-CNN |
| Detection 단계 | 1단계: 후보 영역 생성 (Region Proposal) 2단계: 객체 분류 + 위치 보정 |
| 주요 구성 요소 | - CNN Backbone - ROI 추출 (Selective Search or RPN) - ROI Pooling - 분류기 + 회귀기 |
| Region Proposal 방식 | - R-CNN, Fast R-CNN: Selective Search - Faster R-CNN: RPN (Region Proposal Network) |
| Anchor Box 사용 여부 | Faster R-CNN부터 사용 (9개 anchor) |
| 장점 | - 높은 정확도 - 정밀한 위치 보정 - 작은 객체 탐지 유리 |
| 단점 | - 속도 느림 (특히 R-CNN) - 구조 복잡 - 실시간 처리 어려움 |
| 적합한 환경 | 정확도가 중요한 작업 (ex. 의료, 정밀 검사 등) |
📌 1-Stage Detection 요약
| 구분 | 설명 |
|---|---|
| 대표 모델 | YOLO (v1~v8), SSD, RetinaNet |
| Detection 단계 | 단일 단계에서 객체 분류 + 위치 회귀를 동시에 수행 |
| 주요 구성 요소 | - CNN Backbone - Feature Map 위에서 직접 클래스 + 바운딩 박스 예측 - Anchor box 기반 회귀 (YOLO v2 이후) |
| Region Proposal 방식 | 없음 (후보 영역 없이 전체 이미지 직접 처리) |
| Anchor Box 사용 여부 | 대부분 사용 (YOLO, SSD 모두 anchor 기반 설계 포함) |
| 장점 | - 속도 매우 빠름 (실시간 가능) - 구조 단순 - 경량화 쉬움 |
| 단점 | - 2-stage에 비해 정확도 낮을 수 있음 - 작은 객체 탐지에 취약 |
| 적합한 환경 | 실시간 성능이 중요한 작업 (ex. 자율주행, CCTV, 로봇 등) |
아무것도 모르겠어요 살려주세요 강사님 ㅠㅠ
