객체 탐지 진짜 어렵다... 이 또한 극복해야 할 벽이겠지! 넘어보자 화이팅!!
학습시간 09:00~02:00(당일17H/누적650H)
◆ 학습내용
1. 핵심 용어
| 용어 | 설명 |
|---|---|
| Anchor Box | 정해진 크기/비율을 갖는 기준 박스. 예측은 이 anchor를 기준으로 오프셋 회귀함. |
| Confidence Score | 박스 안에 객체가 있을 확률 × 예측 박스와 정답 박스 간 IoU. |
| NMS (Non-Max Suppression) | 겹치는 박스 중 score가 가장 높은 것만 남기고 나머지를 제거하는 후처리 기법. |
| FPN (Feature Pyramid Network) | 서로 다른 크기의 feature map을 융합하여 다양한 객체 크기에 대응할 수 있게 하는 구조. |
| Passthrough Layer | 낮은 층의 feature를 상위로 연결해 작은 객체 정보를 보존. (YOLOv2에서 사용됨) |
| IoU (Intersection over Union) | 예측 박스와 실제 박스의 겹친 영역 ÷ 전체 영역. 객체 탐지 정확도 계산에 필수 지표. |
| mAP (mean Average Precision) | 클래스별 Precision-Recall 곡선의 평균. 탐지 모델 전체 성능을 평가하는 대표 지표. |
| Hard Negative Mining | 배경(음성 샘플)이 너무 많을 때, 손실이 큰 것만 골라 학습에 반영하는 기법. |
| Focal Loss | 어려운 샘플(예측 실패)에 더 집중하도록 만든 손실 함수. 클래스 불균형 문제에 효과적. |
| YOLO Head | YOLO 모델의 최종 예측 모듈. feature map을 예측값(좌표, 클래스 등)으로 변환. |
| Multiscale Training | 학습 중 이미지 크기를 계속 바꿔서 다양한 해상도에 강건하게 만드는 기법. |
2. 모델 요약
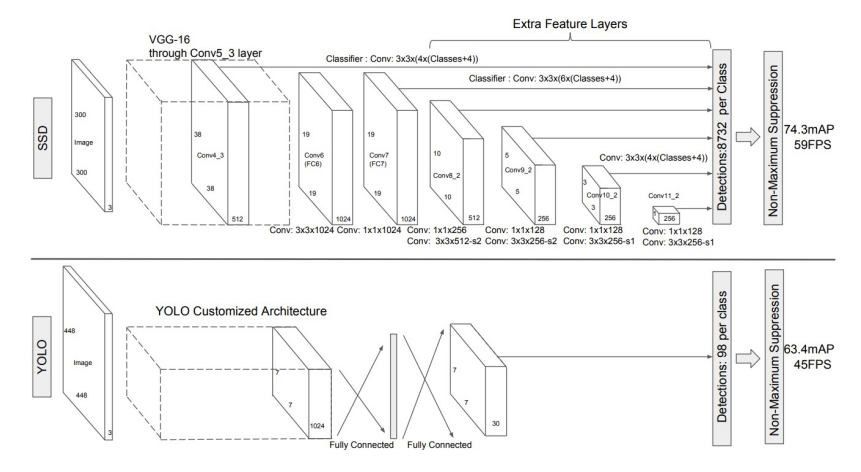
| 항목 | YOLO v1 | YOLO v2 | YOLO 9000 | YOLO v3 | SSD |
|---|---|---|---|---|---|
| 발표년도 | 2016 (CVPR) | 2016/2017 | 2016/2017 | 2018 (arXiv) | 2016 |
| Backbone | 커스텀 CNN | Darknet-19 | Darknet-19 | Darknet-53 | VGG, ResNet |
| Anchor 사용 | ✗ | ✓ | ✓ | ✓ | ✓ |
| 스케일 | 1 | 1 + Multi | 계층적 | 3 | 다중 |
| 구조 특징 | 단순 회귀 구조 | Anchor 도입 | WordTree + 공동 학습 | FPN + Residual | Multi-Scale Box |
| 예측 방식 | 그리드 단위 회귀 | Anchor 기반 회귀 | Anchor 기반 회귀 | 각 스케일에서 3개씩 예측 | 다양한 feature map에서 anchor 예측 |
| 주요 개선점 | 실시간 처리빠른 속도 | Anchor + BatchNormHigh-res ClassifierYOLO9000 확장 | 분류 + 탐지 데이터 동시 학습클래스 수 대폭 증가 | 다중 스케일 예측Darknet-53구조 모듈화 | 다중 해상도Hard Negative Mining |
| 속도 | ★★★★★ | ★★★★ | ★★★★ | ★★★★ | ★★★★ |
| 작은 객체 탐지 | ★ | ★★ | ★★ | ★★★★ | ★★★ |
| 정확도 | ★★★ | ★★★★ | ★★★★ | ★★★★★ | ★★★★ |
3. 1-Stage Detection
1-Stage Detection은 복잡한 후보 영역(Region Proposal) 생성 과정을 생략하고, 단 한 번의 네트워크 전파로 객체의 위치와 클래스를 동시에 예측하는 방식이다.
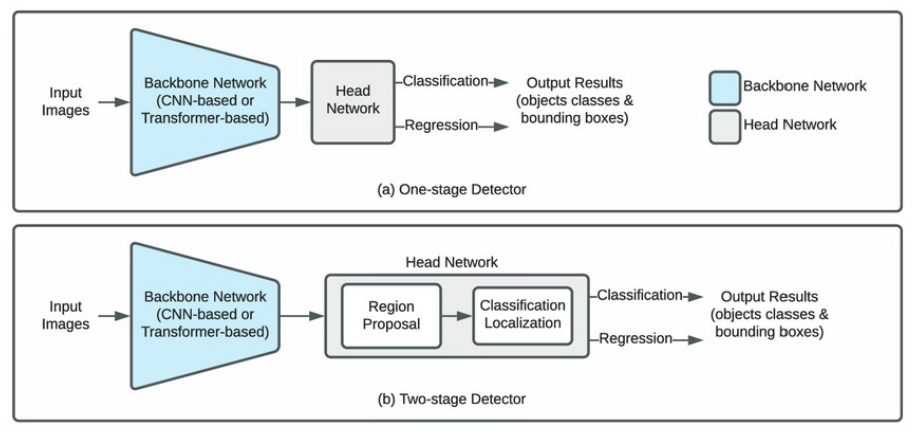
속도와 구조적 단순함 덕분에 실시간 응용 분야에서 널리 사용된다.
| 항목 | One-Stage Detector | Two-Stage Detector |
|---|---|---|
| 구조 | 단일 네트워크로 분류 + 회귀 동시에 처리 | 후보 영역 생성 후 분류 단계 추가 |
| 예시 모델 | YOLO, SSD, RetinaNet | R-CNN, Fast R-CNN, Faster R-CNN |
| 속도 | 빠름 (실시간 가능) | 느림 (정확도 우선) |
| 정확도 | 중상 | 높음 |
| 작은 객체 탐지 | 상대적으로 약함 | 상대적으로 강함 |
| Anchor Box 사용 | 필수 | 일부 모델만 사용 |
| 구현 복잡도 | 낮음 | 높음 |
| 활용 분야 | 실시간 영상, 드론, 로봇비전 | 의료영상, 정밀 탐지, 대형 모델링 |
(1) YOLO v1
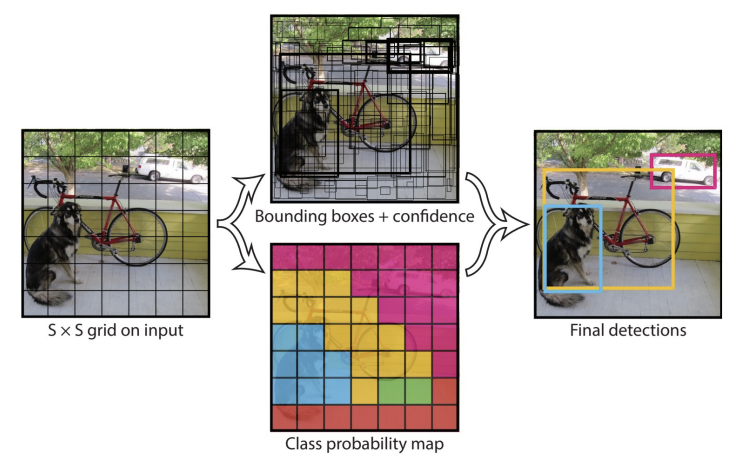
- You Only Look Once
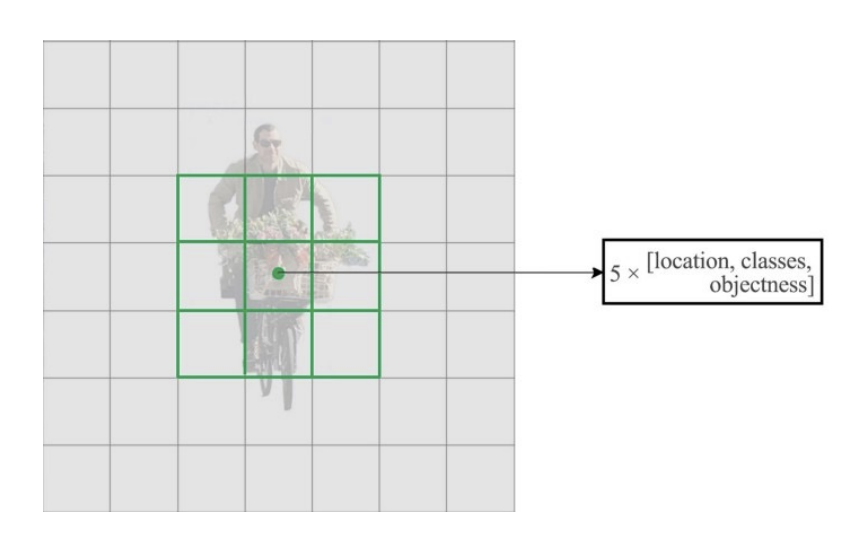
- YOLO는 이미지 전체를 SxS 그리드로 나누고, 각 셀이 객체를 감지한다고 가정함
- 바운딩 박스는 (x, y, w, h, confidence)로 구성됨.
- confidence는 객체 존재 확률 × IoU
- 그리드 S, 바운딩 박스 B, 클래스 C를 입력
- 출력 텐서 크기: (S, S, B×5 + C)
- 예: S=7, B=2, C=20이면 (7, 7, 30) 텐서
A. 손실 함수
- Locallization Loss + Confidence Loss + Classification Loss
- 위치 오차(좌표): x, y는 중심좌표 / w, h는 sqrt로 스케일 조정
- 객체 유무 오차: confidence 예측 오차
- 클래스 오차: 클래스 확률에 대한 cross-entropy
- 객체 없는 셀에 대한 confidence에는 낮은 가중치 부여 (λ_noobj = 0.5 등)
B. 장점
- 단일 네트워크로 단순함
- 처리속도 빠름 (Fast YOLO: 최대 150 FPS)
- 전체 이미지를 보기여 문맥 반영 가능
C. 단점
- 그리드 셀당 1개 객체만 예측 가능 → 겹친 객체 탐지 불가
- 작은 객체를 잘 잡지 못함 (큰 receptive field가 불리하게 작용)
- Anchor가 없어서 위치 예측 정확도가 낮음
(2) SSD
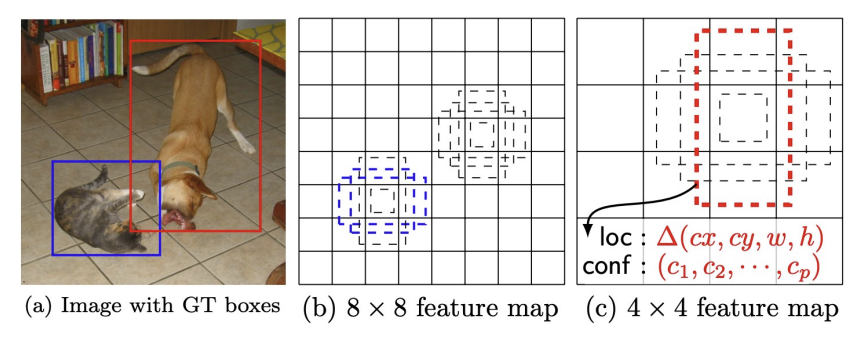
- Single Shot Multibox Detector
- 좌표와 클래스를 동시에 예측
- Region proposal 미사용(그래서 빠름)
- 다중 스케일 예측(다양한 피처맵 활용)
- 정의된 default box(anchor box)를 기반으로 오프셋 예측
- Default box aspect ratio 1:1, 2:1, 1:2 등 설정
- 총 anchor 수는 수천 개에 달함
- 각 anchor는 4개의 위치 오프셋 + 클래스 확률 예측
A. 손실 함수
- Localization: Smooth L1 (박스 좌표 회귀)
- Confidence: Softmax Cross-Entropy (클래스 확률)
- Hard Negative Mining: 배경 클래스가 너무 많기 때문에, confidence loss 기준 상위 음성 샘플만 선택
B. 장점
- 다양한 스케일 탐지 (Multi-scale feature map)
- 속도와 정확도 균형
- 구조가 비교적 직관적이며 학습 효율이 좋음
C. 단점
- 작은 객체는 여전히 탐지 성능이 낮음 (해상도 제한)
- Anchor box 설계가 성능에 큰 영향을 미침
[ YOLO와 SSD 차이점? ]
[ 코드 예시 ]
class SSD(nn.Module):
def __init__(self, backbone):
super(SSD, self).__init__()
self.backbone = backbone
self.extra_layers = nn.ModuleList([...])
self.loc_layers = nn.ModuleList([...])
self.cls_layers = nn.ModuleList([...])
def forward(self, x):
features = []
x = self.backbone(x)
features.append(x)
for layer in self.extra_layers:
x = layer(x)
features.append(x)
locs, confs = [], []
for f, l, c in zip(features, self.loc_layers, self.cls_layers):
locs.append(l(f))
confs.append(c(f))
return torch.cat(locs, dim=1), torch.cat(confs, dim=1)
(3) YOLO v2
- YOLOv1 개선 모델.
- FC 삭제, Anchor 도입, Batch Norm 도입, Multi-scale 학습
- 입력 해상도 224 → 448
- Backbone: Darknet-19
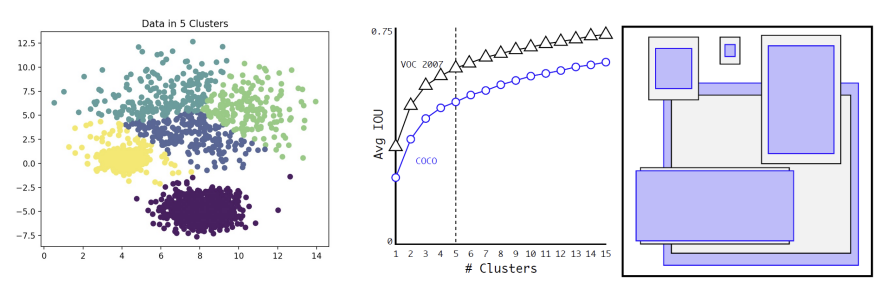
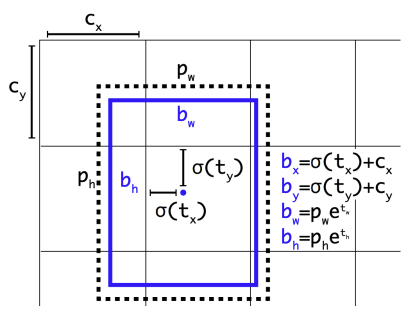
- Anchor box 사용: k-means 클러스터링으로 자동 결정 (IoU 기반)
- Anchor 기반 예측 구조 → 회귀보다 안정적 예측 가능
- Passthrough Layer → 낮은 계층의 feature 사용 (작은 객체 보완)
- 입력 크기 랜덤 조정 (Multi-scale)으로 일반화 향상
A. 장점
- 실시간 처리, 정확도 상승,
- 경량 네트워크, 유연한 입력크기
B. 단점
- Anchor 도입으로 복잡성 증가
- Hyperparameter 세부조정 필요
(4) YOLO 9000
- YOLOv2 구조 기반
- 분류 데이터셋과 탐지 데이터셋 동시 학습 (joint training)
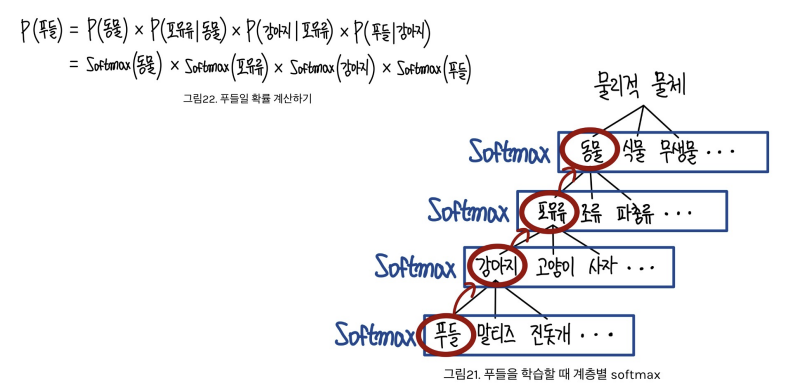
- WordTree라는 계층적 클래스 구조 도입 (WordNet 기반)
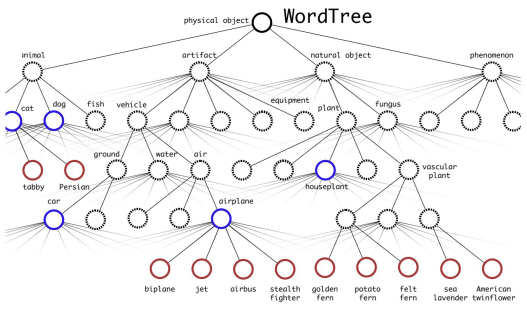
A. 장점
- 수천 개 클래스 탐지 가능 (9000개 이상)
- 분류 데이터만 있는 객체도 탐지 가능
- 하위 분류 대체 예측으로 유연성 향상
B. 단점
- 라벨 불일치 문제 발생 가능
- WordTree에 의한 계산량 증가
- 분류용 손실과 탐지용 손실 균형 맞추기 어려움
(5) YOLO v3

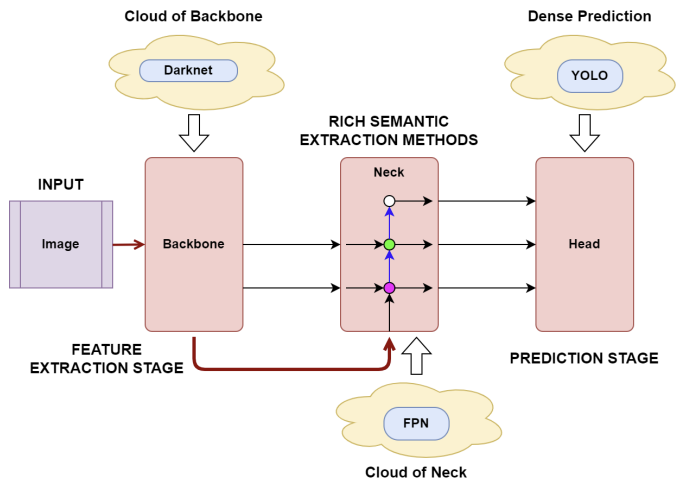
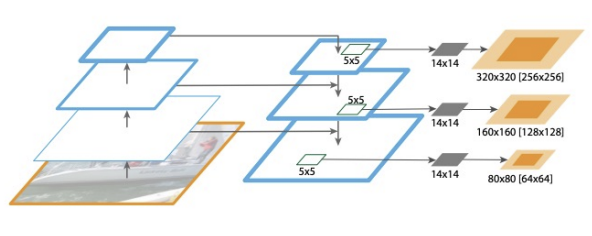
- Backbone: Darknet-53 (Residual Block 기반, 53층)
- Neck: FPN (Feature Pyramid Network)
- Head: 세 가지 스케일의 YOLO detection block (13x13, 26x26, 52x52)
- Sigmoid 사용: 멀티레이블 분류 대응
- IOU threshold와 NMS 처리 포함
- 고수준에서 저수준으로 전파(FPN)하면서 두 특징을 결합하는 측면 연결(lateral connection) 도입
- FPN: bottom-up path + top-down path + lateral connection
A. 장점
- 다양한 객체 크기 대응 (multi-scale prediction)
- 속도 유지 + 정확도 증가
- 잔차 블록 기반으로 학습 안정성 향상
B. 단점
- 모델 크기 증가 (높은 GPU 메모리 요구)
- 학습 시간이 다소 증가
어렵다 어려워... 다음 미션 어쩌면 좋니 ㅠㅠ?

AI Engineer