지금까지의 미션 중 가장 복잡하고 이해하기 어려운 모델이었다. 이번 벽도 어찌어찌 넘은 것 같다... ㅠㅠ
학습시간 11:00~21:00(당일10H/누적700H)
◆ 학습내용
SSD 300 모델로 강아지 고양이 얼굴 탐지하기
어제 11번에 이어 12번부터 시작.
12. 가중치 로드
어제 학습 돌려놓고 잤는데, 다행이도 가중치가 클라우드에 잘 저장되어 있다.
로스가 몇이나 나왔는지 확인을 못해서 아쉽네...
다음에 돌려놓고 잘 때는 최종 학습 정보를 텍스트 파일로 저장해놓는 코드를 추가해야겠다.
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model_SSD300 = ssd300_vgg16(pretrained=True).to(device)
my_classes = 3
my_classification_head = nn.ModuleList([
nn.Conv2d(512, 4*my_classes, 3, 1, 1),
nn.Conv2d(1024, 6*my_classes, 3, 1, 1),
nn.Conv2d(512, 6*my_classes, 3, 1, 1),
nn.Conv2d(256, 6*my_classes, 3, 1, 1),
nn.Conv2d(256, 4*my_classes, 3, 1, 1),
nn.Conv2d(256, 4*my_classes, 3, 1, 1),
])
model_SSD300.head.classification_head.module_list = my_classification_head
model_SSD300.head.classification_head.num_classes = my_classes
model_SSD300.head.classification_head.num_columns = my_classes
가중치를 로드할 모델 뼈대를 다시 잡았다.
model_SSD300.load_state_dict(torch.load('model/ssd300_1.pth', map_location=device))
로드 성공!
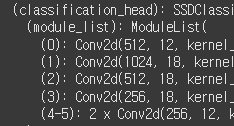
head부분 아웃채널도 잘 변경되어 있다.
이제 val dataset을 시각화할 차례다.
13. 모델 평가
(1) 예측값 시각화
def visualize(model, dataset, index, label_map, score_threshold=0.5):
model.eval()
img_tensor, target = dataset[index]
img_device = img_tensor.to(device)
with torch.no_grad():
prediction = model([img_device])[0]
# 예측 정보
pred_boxes = prediction['boxes']
pred_labels = prediction['labels']
pred_scores = prediction['scores']
keep = pred_scores >= score_threshold
pred_boxes = pred_boxes[keep]
pred_labels = pred_labels[keep]
pred_scores = pred_scores[keep]
pred_texts = [
label_map.get(lbl.item(), str(lbl.item())) + f" ({score:.2f})"
for lbl, score in zip(pred_labels, pred_scores)
]
# 정답 정보
gt_boxes = target['boxes']
gt_labels = target['labels']
gt_texts = [label_map.get(lbl.item(), str(lbl.item())) for lbl in gt_labels]
# 이미지 byte 변환
img_draw = (img_tensor * 255).byte().cpu()
# 예측 박스 (빨간색)
img_with_preds = draw_bounding_boxes(img_draw, pred_boxes.cpu(), labels=pred_texts, colors="red", width=2)
# 정답 박스 (초록색)
final_img = draw_bounding_boxes(img_with_preds, gt_boxes.cpu(), labels=gt_texts, colors="green", width=2)
# 시각화
plt.figure(figsize=(8, 8))
plt.imshow(F.to_pil_image(final_img))
plt.axis("off")
plt.title(f"val dataset [{index}]")
plt.show()시각화 함수는 지선생에게 부탁해서 만들었다.
초록색 박스는 정답, 빨간색 박스는 예측이다.
visualize(model_SSD300, val_dataset, index=0, label_map=label_map)0번 인덱스 사진부터 확인해 보자.
긴장되는 순간...!

오...!? 이렇게 한번에 성공한다고??
근데 얼굴 영역을 정확히 인식하진 못한 것 같다.
에폭을 더 돌렸어야 했나??
BBOX 중심점을 기준으로 회귀를 하면 좋아진다고 들었던 것 같기도 한데,,,
근데 왜 초록색 박스 라벨 이름이 0이지?
일단 다음 이미지도 보자.

?????
탐지는 꽤 잘한 것 같은데 라벨이 cat이다???
초록색 라벨도 cat인걸 보면 뭔가 라벨 매핑이 잘못된 것 같다.
흠,,, 일단 몇 개만 더 보자.

이것도 cat이네.
탐지 박스가 여러 개 나올 수도 있구나.
아마 thread hold인가 그걸 몇 이상으로 제한하는 작업을 추가해야 하는 것 같다.
지금 0.5인데 0.9로 한번 올려봐야겠다.
visualize(model_SSD300, val_dataset, index=2, label_map=label_map, score_threshold=0.9)
오 역시 이렇게 하면 박스가 사라지는군.
다시 0.5로 변경하고 하나만 더 보자.

그래도 아예 쌩뚱맞은 곳을 탐지하는 건 아닌 것 같다. 어쨌든 얼굴 영역 일부가 포함되어 있긴 하니까.
문제는 고양이 강아지 상관없이 라벨이 다 cat으로 되어 있다는 것인데,,,,
심지어 초록색 박스는 강아지=cat, 고양이=0 이다.
(2) 코드 수정
흠,,, 역시 한번에 성공하는 법이 없군.
뭐가 문제지?
내가 뭘 잘못했지?
왜 라벨이 틀리게 나오지?
라벨이 문제가 될만한 곳이 어디지?
class PetDataset(Dataset):
def __init__(self, parser, img_ids, transform=None, label_map=None):
self.parser = parser
self.img_ids = img_ids
self.transform = transform
self.label_map = label_map or {'cat': 0, 'dog': 1}코드를 처음부터 읽어보다가 Dataset 클래스에서 문제가 될만한 부분을 발견했다.
비교해보자.
데이터셋 라벨:
'cat': 0, 'dog': 1
예측결과 라벨:
'cat': 0, 'dog': cat
근데 내가 분류해야할 클래스는 2개가 아니라 배경까지 3개다.
강의 자료에서 배경은 0으로 분류한다고 들었던 것 같다.
그렇다면 xml 상에서 cat 라벨이 붙은 결과값은 0이 나올 것이고, dog 라벨이 붙은 것은 1이 나올 것이다.
그럼 고양이 사진 초록색 박스에 0이 나오는 이유가 설명이 된다.
추가로, SSD 모델이 배경: 0, cat: 1, dog: 2 로 분류한다고 가정하면, 데이터셋에 2에 관한 맵핑을 한 게 없으니 전부 배경으로 예측을 하거나 cat만 나올 것이다.
그럼 강아지 사진 빨간색 박스에 cat만 나오는 이유도 설명이 된다.
class PetDataset(Dataset):
def __init__(self, parser, img_ids, transform=None, label_map=None):
self.parser = parser
self.img_ids = img_ids
self.transform = transform
self.label_map = label_map or {'cat': 1, 'dog': 2}라벨 숫자를 바꿨다.
학습을 다시 돌려야 할 것 같긴 한데,, 일단 다시 확인해보자.
visualize(model_SSD300, val_dataset, index=2, label_map=label_map, score_threshold=0.5)

오케이 일단 초록색 박스의 라벨은 cat과 dog 제대로 분류되어 나온다.
빨간색 박스는 학습 결과니까 변함없는 게 맞겠지...
train_model(model_SSD300, train_loader, 10)
torch.save(model_SSD300.state_dict(), 'model/ssd300_2.pth')흑흑,,, 인내의 시간 다시 시작 ㅠㅠ

10에폭 돌렸다. 시간이 없어서 비싼 GPU를 썼더니 생각보다 금방 된다.
역시 인공지능은 장비빨이다.
로스가 3.26 나왔다. 엄청 높은 수치인 것 같은데,, 일단 다시 시각화를 해보자.
visualize(model_SSD300, val_dataset, index=2, label_map=label_map, score_threshold=0.5)
아까보다 예측박스 수치가 낮게 나왔다. 어제보다 10에폭 덜 돌려서 그런 것 같다.
근데 라벨 이름이 dog가 아니라 2로 나왔다.
고양이 쪽이 1로 나오면 괜찮을 것 같은데,,
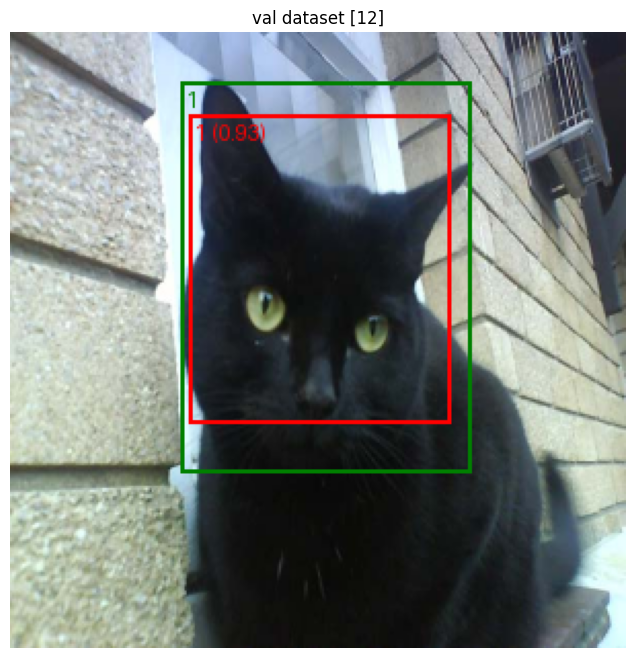
오호 고양이 라벨 이름이 1이다.
예측박스&결과박스 값도 일치하고, 고양이&강아지 분류도 잘했다.
그럼 인덱스 번호에 지정된 이름이 나오도록 딕셔러니 앞뒤만 변경해주면 될 것 같다.
def visualize(model, dataset, index, label_map, score_threshold=0.5):
model.eval()
idx_to_label = {v: k for k, v in label_map.items()}시각화 코드에 라벨이 담긴 딕셔너리를 좌우 반전하는 코드를 넣었다.
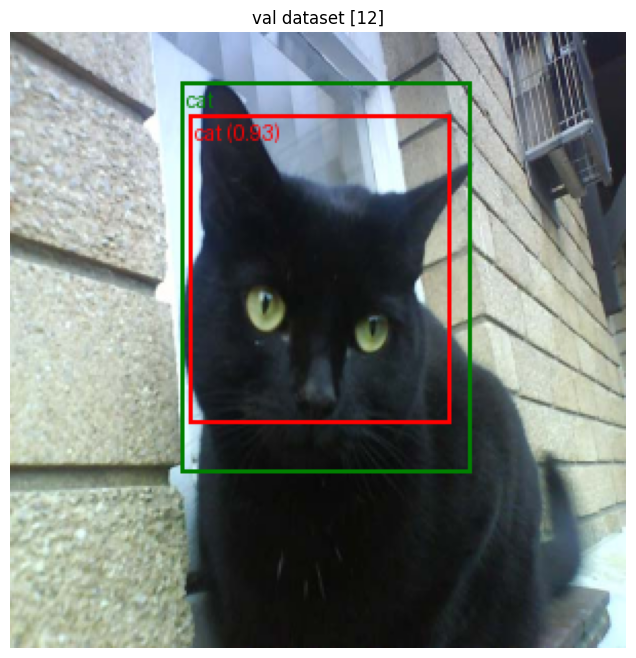
나온다!

이것도 잘 나온다!

흠, 멍이를 냥이라고 잘못 예측한 것도 있다.
그렇다면 이제 모델 성능을 올려야한다는 뜻인데,
일단 그 전에 평가지표로 정확한 수치부터 확인해 보자.
(3) 평가지표 확인
강의 때 배운 내용에 따르면 평가지표에는 mAP와 IoU가 있다.
이게 뭔지 모르겠으니까 공부를 먼저 해야겠다.
| 항목 | IoU (Intersection over Union) | mAP (mean Average Precision) |
|---|---|---|
| 정의 | 예측 박스와 정답 박스가 얼마나 겹치는지 측정 | 전체 모델의 탐지 성능을 평균 정밀도로 요약 |
| 계산 대상 | 개별 예측 박스 vs 정답 박스 (1:1 비교) | 모든 이미지, 모든 클래스에 대해 전체 평가 |
| 계산 방법 | IoU = 교집합 넓이 / 합집합 넓이 | 각 클래스의 AP 계산 후 평균 (mAP = mean(AP_1, AP_2, ...)) |
| 결과값 의미 | 예측의 위치 정확도 (정답 위치와 얼마나 일치하는지) | 모델의 탐지 성능 종합 점수 (정확도와 재현율 반영) |
| 기준값 예시 | 일반적으로 IoU ≥ 0.5 이상이면 정탐(True Positive)으로 간주 | mAP\@0.5: IoU ≥ 0.5 기준으로 평가한 mAP |
| 사용 목적 | "이 박스는 잘 맞았는가?" 위치 정밀도 판단 | "모델이 전체적으로 잘 맞췄는가?" 탐지 성능 요약 |
| 결과값 범위 | 0 ~ 1 (1에 가까울수록 더 정확) | 0 ~ 1 (1에 가까울수록 더 뛰어남) |
| 직관적 예시 | IoU = 0.8 → 박스가 거의 일치 | mAP = 0.65 → 전체 탐지 모델 성능 양호 |
| 중요성 | 단일 예측 평가에 중요 | 모델 전체 성능을 평가할 때 중요 |
아하 쉽게 말해 한 장일 때는 IoU로 평가를 하는데, 여러 장이면 IoU도 여러 개가 되기 때문에 평균을 내야 한다. 그게 mAP인가 보다.
from torchvision.ops import box_iou
def compute_iou(boxes1, boxes2):
return box_iou(boxes1, boxes2)
def evaluate_model(model, dataset, device, iou_threshold=0.5, score_threshold=0.5):
model.eval()
TP = 0
FP = 0
FN = 0
for i in tqdm(range(len(dataset)), desc="Evaluating"):
img, target = dataset[i]
img_device = img.to(device)
with torch.no_grad():
pred = model([img_device])[0]
pred_boxes = pred['boxes']
pred_labels = pred['labels']
pred_scores = pred['scores']
keep = pred_scores >= score_threshold
pred_boxes = pred_boxes[keep]
pred_labels = pred_labels[keep]
gt_boxes = target['boxes']
gt_labels = target['labels']
if len(pred_boxes) == 0:
FN += len(gt_boxes)
continue
iou = compute_iou(pred_boxes.cpu(), gt_boxes.cpu())
matched_gt = set()
for pred_idx in range(iou.size(0)):
best_iou, best_gt_idx = iou[pred_idx].max(0)
if best_iou >= iou_threshold and best_gt_idx.item() not in matched_gt:
TP += 1
matched_gt.add(best_gt_idx.item())
else:
FP += 1
FN += len(gt_boxes) - len(matched_gt)
precision = TP / (TP + FP + 1e-6)
recall = TP / (TP + FN + 1e-6)
print(f"\n▶Evaluation Result (IoU > {iou_threshold})")
print(f"- TP: {TP}, FP: {FP}, FN: {FN}")
print(f"- Precision: {precision:.4f}")
print(f"- Recall: {recall:.4f}")
코드는 다른 곳에서 복붙을 해왔다.
무슨 평가 코드가 이렇게 복잡하냐...
머신러닝 때 오차행렬 보는거랑 차원이 다르네.
evaluate_map_iou_subset(model_SSD300, val_dataset, list(range(len(val_dataset))), device)
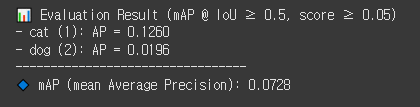
가독성 좋게 print문만 조금 변경했다.
지표를 이용한 평가값은 아래와 같다.
- cat: 0.1260
- dog: 0.0196
- mAP: 0.0728
윽,, 완전 형편없는 수치다.
첨부터 다시 해보자.
14. 성능 개선
어떻게 하면 성능을 개선할 수 있을까?
이번 모델에서 내가 놓친 게 뭐가 있을까?
일단 내가 10에폭만 돌렸기 때문에 이걸 더 늘려서 시도해볼 필요가 있다.
학습 관련 파라미터도 너무 대충 때려넣었기에 조금 더 세부조정할 필요가 있다.
그리고 이번에 backbone은 다 freeze하고 학습했었는데, 어느정도는 열어놓고 학습해볼 필요가 있다.
DenseNet 전이학습 할 때도 풀튜닝에 가까울수록 성능이 좋았기 때문이다.
좋아 일단 이대로 부딪혀 보자.
my_classes = 3
my_classification_head = nn.ModuleList([
nn.Conv2d(512, 4*my_classes, 3, 1, 1),
nn.Conv2d(1024, 6*my_classes, 3, 1, 1),
nn.Conv2d(512, 6*my_classes, 3, 1, 1),
nn.Conv2d(256, 6*my_classes, 3, 1, 1),
nn.Conv2d(256, 4*my_classes, 3, 1, 1),
nn.Conv2d(256, 4*my_classes, 3, 1, 1),
])
model_SSD300.head.classification_head.module_list = my_classification_head
model_SSD300.head.classification_head.num_classes = my_classes
model_SSD300.head.classification_head.num_columns = my_classes
for name, param in model_SSD300.named_parameters():
if name.startswith("head"):
param.requires_grad = True
elif name.startswith("backbone.extra"):
param.requires_grad = True
elif name.startswith("backbone.features.19"):
param.requires_grad = True
elif name.startswith("backbone.features.21"):
param.requires_grad = True
else:
param.requires_grad = False
print(f"{name} = {param.requires_grad}")
model_SSD300.to(device)모델을 새로 만들었다.
내부 파라미터 확인 후 backbone의 절반 정도를 열었다.
저수준만 남기고 싹 다시 학습하면 더 좋은 결과가 나오지 않을까?
params = [p for p in model_SSD300.parameters() if p.requires_grad]
optimizer = optim.SGD(params, lr=0.001, momentum=0.9, weight_decay=0.0005)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer,
mode='min',
factor=0.5,
patience=2,
verbose=True,
min_lr=1e-6
)
학습 루프를 수정했다.
스케줄러를 넣어서 learning rate이 점차 감소하도록 만들었다.
train_model(model_SSD300, train_loader, 50)50에폭 정도 돌리면 되겠지?
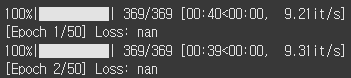
뭐지? 갑자기 학습이 안 된다.

backbone의 learning rate이 head과 같아서 터져버린 건가??
backbone_params = []
head_params = []
for name, param in model_SSD300.named_parameters():
if param.requires_grad:
if name.startswith("head"):
head_params.append(param)
else:
backbone_params.append(param)
optimizer = optim.SGD([
{"params": backbone_params, "lr": 0.0001},
{"params": head_params, "lr": 0.001}
], momentum=0.9, weight_decay=0.0005)옵티마이저에 넣을 lr 파라미터를 2개로 나눴다.
head 파라미터는 그대로 학습하고 backbone 파라미터는 10배 낮은 0.0001로 학습해보자.

흠... 그래도 학습이 안 된다.
원인을 확인할 코드가 필요하다.
with torch.no_grad():
for img, _ in val_dataset:
img = img.unsqueeze(0).to(device)
feat = model_SSD300.backbone(img)['0']
if torch.isnan(feat).any():
print("NaN detected in backbone feature")
break좋은 코드를 하나 발견했다.
val_dataset의 이미지 하나를 가져와서 차원을 맞추고 backbone 0번 피처맵에 넣어보는 디버깅 코드라고 한다. 이 코드에서 NaN이 나오면 원인은 backbone이다.

다행인지 모르겠지만 NaN이 나왔다.
backbone 쪽 학습이 안 되는 것 같다. 왜지???
backbone도 extra 레이어층이 있고 features 레이어층이 있다.
features가 더 앞쪽에 있는 레이어 층인데, 너무 앞쪽 레이어라서 학습을 못시키는 건가??
for name, param in model_SSD300.named_parameters():
if name.startswith("head"):
param.requires_grad = True
elif name.startswith("backbone.extra"):
param.requires_grad = True
elif name.startswith("backbone.features.19"):
param.requires_grad = False
elif name.startswith("backbone.features.21"):
param.requires_grad = False
else:
param.requires_grad = False
print(f"{name} = {param.requires_grad}")
model_SSD300.to(device)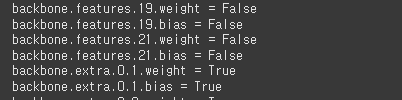
실험해 보자. backborn의 features 레이어층 19번과 21번을 닫았다.
train_model(model_SSD300, train_loader, 50)다시 도전! 과연 될까...!?

된다!!! 문제는 backbone을 너무 많이 열어서였나???
추측컨대, SSD 모델은 backbone.extra 까지만 학습시킬 수 있는 것 같다.
아 50에폭 동안 뭐하지...
나가서 산책좀 하고 와야겠다.
나갔다 오니까 학습이 끝나있다.
세 번째 시도 최종 로스는 0.1이다.
두 번째 로스가 3.2 였으니까, 로스만 보면 무려 32배 좋아졌다고 할 수 있다.
다시 시각화해보자.
visualize(model_SSD300, val_dataset, index=9, score_threshold=0.5)
오 됐니!?


이정도면 꽤 양호하게 인식하는 것 같다.
평가지표도 다시 한번 보자.
evaluate_map_iou_subset(model_SSD300, val_dataset, list(range(len(val_dataset))), device)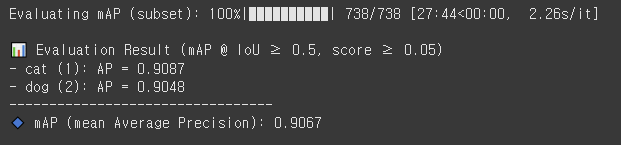
오!!!!
- cat: 0.9087 (전 0.1260)
- dog: 0.9048 (전 0.0196)
- mAP: 0.9067 (전 0.0728)
생각보다 수치가 잘 나온 것 같다.
물론 엄청 만족스러운 수치는 아니지만, 그래도 첫 번째 객체탐지 모델을 완성했다는 것에 의미를 두자.
어찌어찌 해냈다. 근데 내 주말... 어디갔니...
