이번 주말은 SSD와 친해지는 시간이다.
학습시간 20:00~02:00(당일6H/누적690H)
◆ 학습내용
SSD 모델로 강아지 고양이 얼굴 탐지하기.
어제(6번~10번)에 이어 11번 부터 진행!
11. 모델 학습
(1) 학습 전처리
드디어 학습을 돌릴 차례다.
학습 코드를 만들기 전에, 어떤 레이어를 프리즈할 것인지부터 확인해야 한다.
전이학습 때 배웠던 코드를 그대로 이용해보자.
for name, param in model_SSD300.named_parameters():
print(f"{name} = {param.requires_grad}")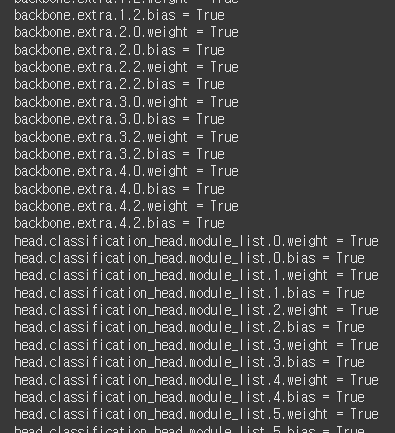
backbone과 head 모두 True인 상태다. 아직 아무것도 손대지 않아서 그렇다.
음,, 이건 어디까지 프리즈해야 할지 모르겠네. 전이학습이랑 똑같은 개념인가..?
for name, param in model_SSD300.named_parameters():
if name.startswith("head"):
param.requires_grad = True
else:
param.requires_grad = False
print(f"{name} = {param.requires_grad}")
model_SSD300.to(device)일단 뭐든 해보자.
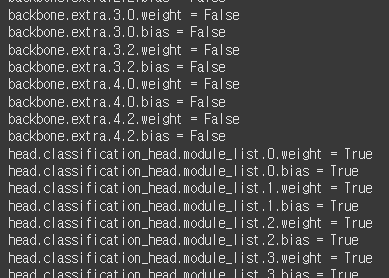
backbone만 프리즈 후에 디바이스에 올렸다.
이대로면 전이학습 때 classifier만 튜닝하는 것과 같은 개념일 것이다.
이제 옵티마이저를 설정할 차례다. 강사님이 만든 코드를 보니까 기존 CNN 코드와 약간 다른 부분이 있는 것 같다.
params = [p for p in model_SSD300.parameters() if p.requires_grad]
optimizer = optim.SGD(params, lr=0.001, momentum=0.9, weight_decay=0.0005)일단 강사님이 사용했던 코드를 그대로 가져와서 모델명만 변경했다.
CNN 옵티마이저 정의 때와 다른 것이 3가지 있다.
params를 정의해줘야 한다는 것
params는 내가 프리즈한 것을 제외하고 True로 설정된 파라미터만 옵티마이저에 넣기 위한 변수다.
- 옵티마이저 파라미터에
weight_dacay가 들어간다는 것
웨이트가 너무 커지지 않도록 막는 역할이라고 하는데,,, 처음 써봐서 뭔지 잘 모르겠다.
criterion을 정의하지 않는다는 것
criterion 을 정의하지 않는 이유는 이미 모델 내부에서 손실함수를 계산해서 값을 반환하기 때문이라고 한다.
신기하긴 한데, 기존 알고 있던 것에서 조금 변경되니까 벌써 어지럽다.
(2) 학습 루프 생성
def train_model(model, dataloader, epochs=0):
model.train()
for epoch in range(epochs):
total_loss = 0
for images, targets in tqdm(dataloader):
images = list(img.to(device) for img in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())
optimizer.zero_grad()
losses.backward()
optimizer.step()
total_loss += losses.item()
avg_loss = total_loss / len(dataloader)
print(f"[Epoch {epoch+1}/{epochs}] Loss: {avg_loss:.6f}")학습을 위한 함수를 정의했다. 기본 구조는 일반 CNN 학습 코드와 비슷하다.
하지만 큰 차이점이 2가지 있다.
- dataloader를 리스트로 받는다.
일반 CNN 코드는 아래처럼 images, labels를 곧장 디바이스에 올린다.
for images, labels in dataloader:
images = images.to(device)
labels = labels.to(device)하지만 SSD는 다르다.
for images, targets in dataloader:
images = list(img.to(device) for img in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]먼저 labels 대신 targets를 받는다. 그리고 디바이스에 올리기 전에 리스트 형태로 dataloader 값을 변경한다.
그 이유는, 일반 CNN에선 (B, C, H, W) 형태의 텐서 하나를 모델에 넣기 때문이고,
탐지 모델은 각 이미지마다 bbox, label이 달라서 리스트에 담아줘야 하기 때문이다.
images = 텐서 리스트
List(Tensor])
targets = Dict형태 텐서 리스트
{'boxes': Tensor, 'labels': Tensor}
- loss가 dict로 반환된다.
일반 CNN 모델에서는 아래처럼
outputs = model(images)
loss = criterion(outputs, labels)outputs와 loss를 구하면 된다.
근데 탐지 모델에서는
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())classification_loss 와 bbox_regression_loss 를 동시에 구해야 하기 때문에, loss_dict.values()를 sum() 으로 합쳐서 최종 loss로 만드는 구조가 필요하다.
(3) 학습 시작
train_model(model_SSD300, train_loader, 20)전이학습 때 느꼈던 바로는 10에폭 돌렸을 때와 100에폭 돌렸을 때 드라마틱한 차이가 없다는 것이다.
하지만 오늘은 주말이니 한 20에폭 정도 돌려볼까?

자 과연 몇 분이나 걸릴 것인가..!
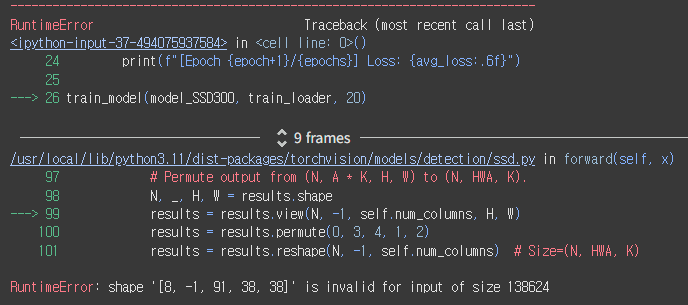
????????
잘 돌아가는 줄 알았는데 갑자기 에러가 떴다.
학습 코드에 문제가 있는 것 같다. 뭘 잘못 한거지...
근데 에러명이 조금 이상하네.
RuntimeError: shape '[8, -1, 91, 38, 38]' is invalid for input of size 138624
[8, -1, 91, 38, 38] 이 쉐입이 틀렸다는 뜻이다.
앞에 8은 내가 설정한 배치 사이즈일 거고, 뒤에 (38, 38)은 피처맵 크기일 것이다. -1은 뭔지 잘 모르겠네 뭔가 자동으로 해준다는 건가?
근데,,, 불길한 숫자가 보인다. 91은 클래스 수였던 걸로 기억하는데,,,
어제 분명히 클래스 3개로 바꿔서 classification head에 붙이는 것까지 성공했는데???
오늘도 호락호락하지 않구나.


흑흑,,,,
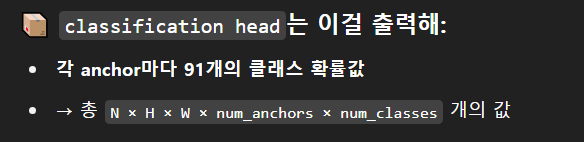


아!!!!!!!!!!!!! 와 진짜 멍청했다.
맞다. 내가 어제 만든 건 classification head다.
여기에 (앵커 수 X 클래스 수)한 값을 아웃채널에 넣었지만, 나는 SSD 모델 그 어디에도 분류해야 할 클래스가 3개라고 알려준 적이 없다.
그러니까 지금 이 모델은 그냥 아웃채널만 바뀐 이상한 모델이 된 것이다.
my_classification_head = nn.ModuleList([
nn.Conv2d(512, 4*3, 3, 1, 1),
nn.Conv2d(1024, 6*3, 3, 1, 1),
nn.Conv2d(512, 6*3, 3, 1, 1),
nn.Conv2d(256, 6*3, 3, 1, 1),
nn.Conv2d(256, 4*3, 3, 1, 1),
nn.Conv2d(256, 4*3, 3, 1, 1),
])
model_SSD300.head.classification_head.module_list = my_classification_head
model_SSD300.head.classification_head.num_classes = 3
model_SSD300.to(device)
classification_head.num_classes 파라미터로 분류해야 할 클래스가 3개라는 것을 정확히 명시 후 모델을 다시 불러왔다.
이제 무조건 된다.
train_model(model_SSD300, train_loader, 20)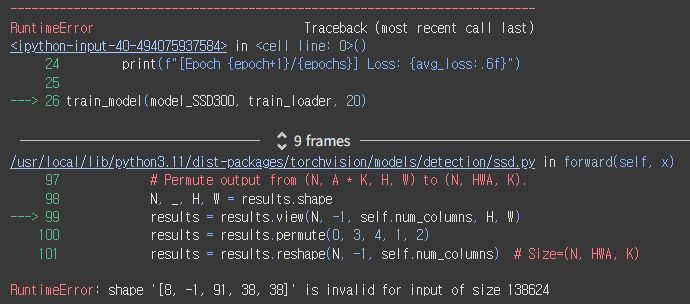
하... ^^ 또 뭐가 문제일까?
호흡을 가다듬고 에러를 다시 확인해 보자.
문제가 된 곳은 두 군데다.
내가 만든 train_model 함수와 모델 내부에 있는 99번 코드.
내 함수에 문제가 없다고 가정하면, 모델 내부에서 내 코드를 제대로 못받았다는 뜻이다.
head 코드는 어제 분명 제대로 만들어서 붙였고, 클래스 파라미터도 방금 3개로 명시해서 모델에 저장했다.
어라,, 근데 99번 줄 코드가 조금 이상하다.
---> 99 results = results.view(N, -1, self.num_columns, H, W)
나는 num_classes가 3개라고 지정했는데, 지금 에러가 난 곳에는 num_columns 이라고 되어 있다. 뭐지?????
num_columns도 3개라고 명시해주면 되나?
my_classification_head = nn.ModuleList([
nn.Conv2d(512, 4*3, 3, 1, 1),
nn.Conv2d(1024, 6*3, 3, 1, 1),
nn.Conv2d(512, 6*3, 3, 1, 1),
nn.Conv2d(256, 6*3, 3, 1, 1),
nn.Conv2d(256, 4*3, 3, 1, 1),
nn.Conv2d(256, 4*3, 3, 1, 1),
])
model_SSD300.head.classification_head.module_list = my_classification_head
model_SSD300.head.classification_head.num_classes = 3
model_SSD300.head.classification_head.num_columns = 3num_classes, num_columns 둘 다 3개라고 명시 후에 저장했다.
train_model(model_SSD300, train_loader, 20)이번엔 제발 되기를.

오!!!!!!!!!!!!!!!!!! 된다!!!!!!!!!!!
근데 에폭당 1시간 30분이라고...?
GPU 켜서 돌려놓고 자야겠다...
내일 다시 보자고!
