큰일이다. 이제 막 탐지 끝났는데 더 어려워진다.
학습시간 09:00~02:00(당일17H/누적717H)
◆ 학습내용
1. Image Segmentation

- Object Detection은 "객체 단위"로 경계 상자를 찾아내고 분류함
→ 예: ‘사람’이 어디 있는가? - Segmentation은 "픽셀 단위"로 분류함
→ 예: 어떤 픽셀이 사람이고, 어떤 픽셀이 도로인가? - Segmentation을 통해 정확한 경계 정보 획득 가능
→ 세밀한 영역 분석에 필수 - 대표 응용 분야:
- 자율주행 (차선, 보행자 인식 등)
- 의료 영상 분석 (종양 검출 등)
- 위성 영상 (농지, 도로, 건물 분할 등)
Segmentation 종류:
| 종류 | 객체 구분 | 배경 구분 | 예시 |
|---|---|---|---|
| Semantic | ✓ | 고양이, 사람, 배경 | |
| Instance | ✓ | 고양이 A, B, 사람 A, B | |
| Panoptic | ✓ | ✓ | 둘 다 |
대표 모델:
| 모델 | 구조 특징 | 출력 형식 | 강점 | 단점 |
|---|---|---|---|---|
| FCN | Conv-only, Skip | 전체 픽셀 | 간단, 빠름 | 경계 흐림 |
| U-Net | U자형 대칭 | 전체 픽셀 | 정밀, 의료 특화 | 일반용도 한계 |
| Mask R-CNN | Detection + Mask | 객체별 마스크 | 정밀, 유연성 | 복잡, 느림 |
2. Semantic Segmentation
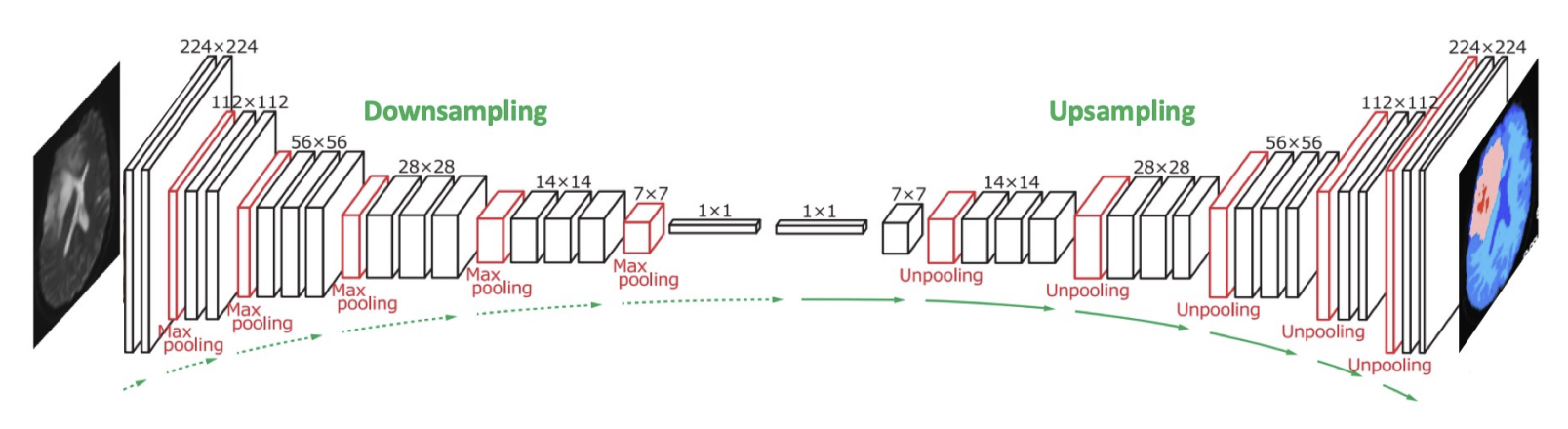
- 각 픽셀에 ‘무엇인지’ 태그를 부여
- 개별 객체는 구분하지 않음
- Patch 기반 분류: 이미지에서 타겟 픽셀 주변 패치를 CNN에 넣어 중심 픽셀 클래스 예측
- 단점: 연산량 큼, 국소 정보만 학습
- CNN은 보통 이미지 전체를 분류하기 위해 설계됨 → 출력이 1개 벡터
- Segmentation은 픽셀 단위 예측이 필요함 → 출력 해상도 = 입력 해상도
| 방법 | 설명 |
|---|---|
| Nearest Neighbor | 가장 가까운 픽셀 값 복사 |
| Bed of Nails | 값을 그대로 복사, 나머지는 0 |
| Max Unpooling | MaxPooling 위치 기억해서 복원 |
| Bilinear Interpolation | 4개 픽셀로 보간, 매끄러움 |
| Deconvolution (Transposed Conv) | 학습 가능한 필터로 복원, 더 선명함 |
(1) FCN
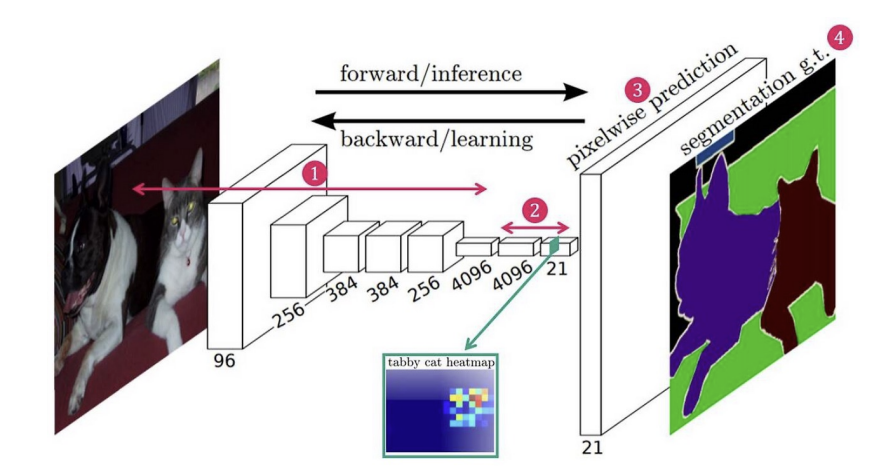
- Fully Convolutional Networks, 2014년
- 최초의 end-to-end 세그먼테이션 학습 구조
- 다양한 backbone에 적용 가능
- skip connection으로 공간 정보 보완 가능
- 기존 CNN에서 완전 연결층(Fully Connected Layer)을 제거
- 대신 모든 연산을 Convolution만 사용
- 어떤 크기의 이미지에도 대응 가능
구조:
1. Convolution Layer → Feature 추출
2. 1x1 Convolution → Class 채널 수로 변경
3. Upsampling → 입력과 동일한 크기 복원
4. Loss 계산 → Cross Entropy(Pixel-wise)
장점:
- End-to-End 훈련
- 다양한 Backbone 가능 (VGG, ResNet 등)
- Skip Connection을 통해 정보 보존
단점: - 단순 업샘플링이라 경계 복원 한계
- 복잡한 장면에서 성능 저하 가능
(2) U-Net
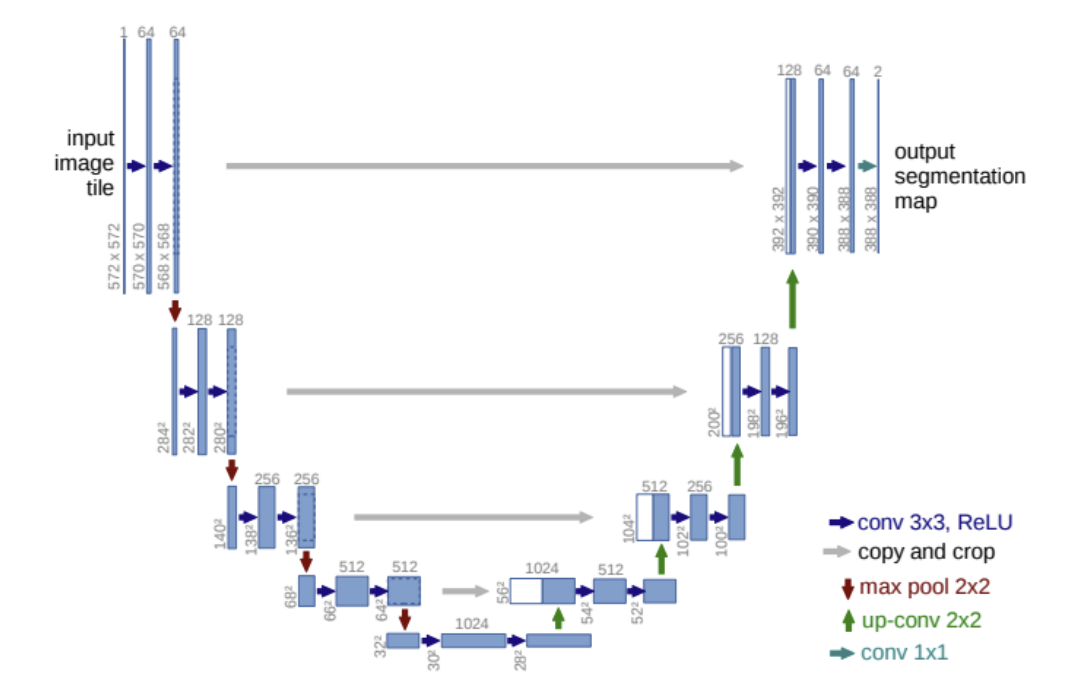
- 의료 영상에 특화된 세그멘테이션 네트워크, 2015년
- 인코더-디코더 대칭 구조 + 스킵 연결
- 인코더 (Contracting Path)
- 3x3 Conv + ReLU → 특징 추출
- 2x2 MaxPool → 해상도 감소
- 디코더 (Expansive Path)
- 업샘플링
- 대응되는 인코더 특징맵과 Concatenate (Skip Connection)
- 3x3 Conv 2번 + ReLU
- 최종 출력
- 1x1 Conv로 클래스 수만큼 출력 채널 생성 → Softmax
데이터 처리 전략:

- Overlap Tile 전략: 큰 이미지 → 겹치는 타일로 자르기
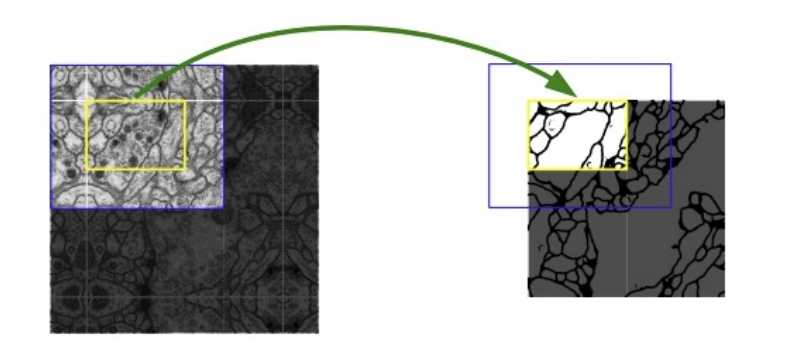
- Mirroring: 경계 넘어간 부분을 대칭으로 채우기
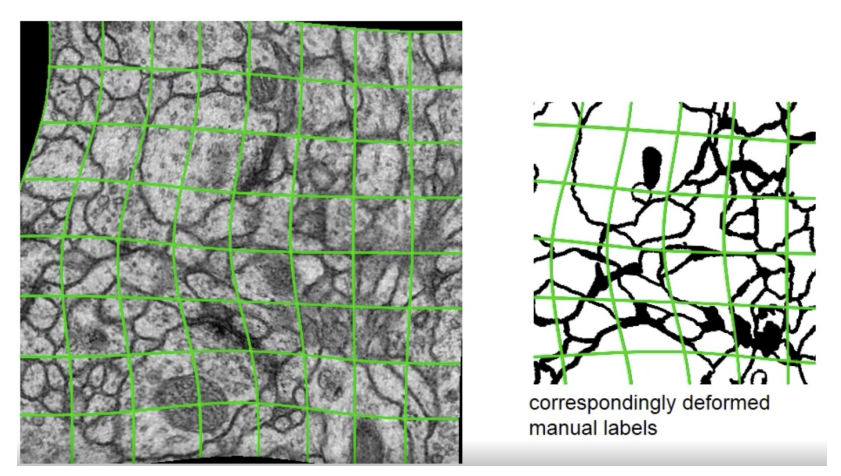
- Elastic Deformation(탄성변형) 등 다양한 Augmentation
손실 함수:
- Pixel-wise Softmax + Cross Entropy
- 경계 픽셀에 가중치 부여
장점:
- 소량 데이터에서도 성능 우수
- 경계 복원에 탁월
- 빠른 연산으로 실시간 응용 가능
단점:
- 메모리 사용 많음
- 주로 의료 영상에 특화됨
- padding 보정 신경 써야 함
3. Instance Segmentation
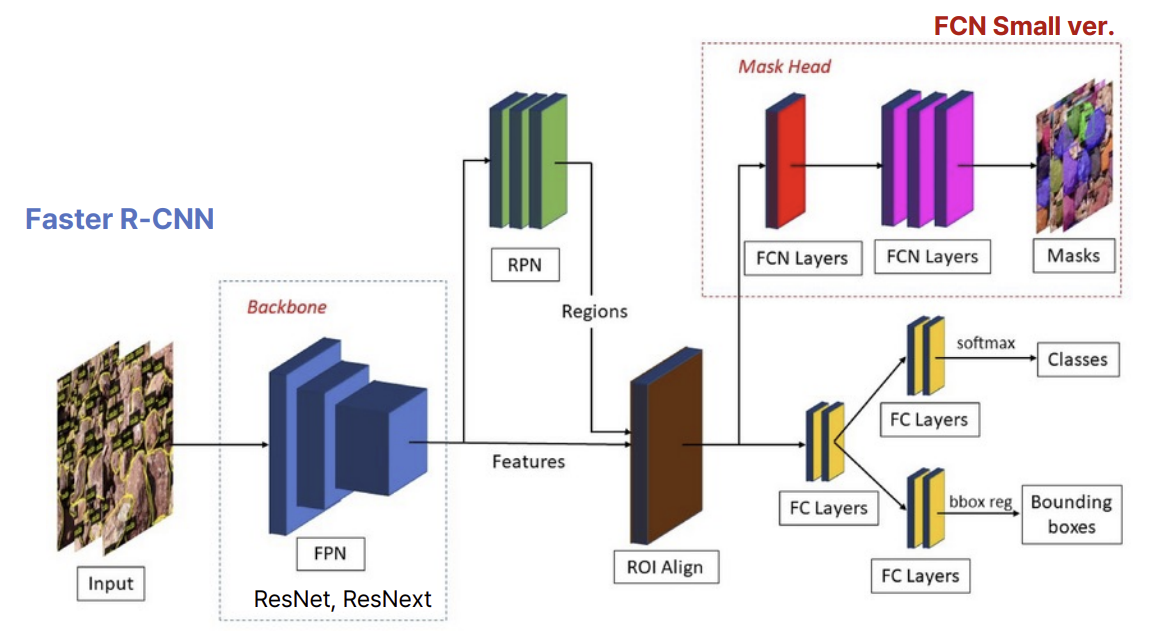
- 대표 모델: Mask R-CNN(Faster R-CNN + 마스크 분기)
- detection + segmentation 구조 결합
- 같은 클래스 내 각 객체마다 분리된 마스크 생성
- RoIAlign 사용으로 정확한 마스크 정렬
- Backbone으로 ResNet + FPN 사용
구조:
- 입력 이미지 → Resize (800x1024)
- Backbone (ResNet101) → Feature Map 생성
- FPN → 멀티 스케일 Feature
- RPN → RoI 후보 영역 생성
- NMS → 겹치는 RoI 제거
- RoIAlign → 고정 크기 정렬 (ex. 7x7)
- 분기 처리:
- Classification
- Bbox Regression
- Mask Prediction (ex. 28x28 이진 마스크)
- 최종 출력: Class, Confidence, Bbox, Mask
RoIAlign:
| 비교 | RoIPool | RoIAlign |
|---|---|---|
| 방식 | Quantization 후 Pool | 소수점 좌표 보간 |
| 문제 | 경계 정렬 안 됨 | 정밀도 매우 높음 |
| 특징 | 성능 하락 | Keypoint, Mask 정확 |
4. 보간법
| 방식 | 특징 | 학습 여부 | 특징 요약 |
|---|---|---|---|
| Bilinear Interpolation | 이웃 4픽셀 평균 기반 예측 | ✖ | 빠르나 부정확 가능 |
| Deconvolution (Transposed Conv) | 필터 학습을 통해 업샘플링 | ✔ | 경계 표현 개선 가능 |
(1) Linear Interpolation
- 선형 보간법
- 두 점 사이의 값을 직선 방정식 기반으로 예측하는 방식
- 한 방향(x축 또는 y축)에서 중간 지점의 값을 선형 비율로 추정
- 기준 점: (x₀, y₀), (x₁, y₁)
- 예측 대상: 중간 좌표 x에 해당하는 y값
(2) Bilinear Interpolation
- 이중 선형 보간법
- 2차원 격자에서 4개 점을 이용해 중간 지점의 값을 예측
- 두 방향(x, y)으로 각각 선형 보간 수행
- x축 기준으로 아래쪽 두 점 보간 → R₁
- x축 기준으로 위쪽 두 점 보간 → R₂
- R₁과 R₂를 y축 기준으로 다시 보간 → 최종값 P
5. RoI 기법 종류
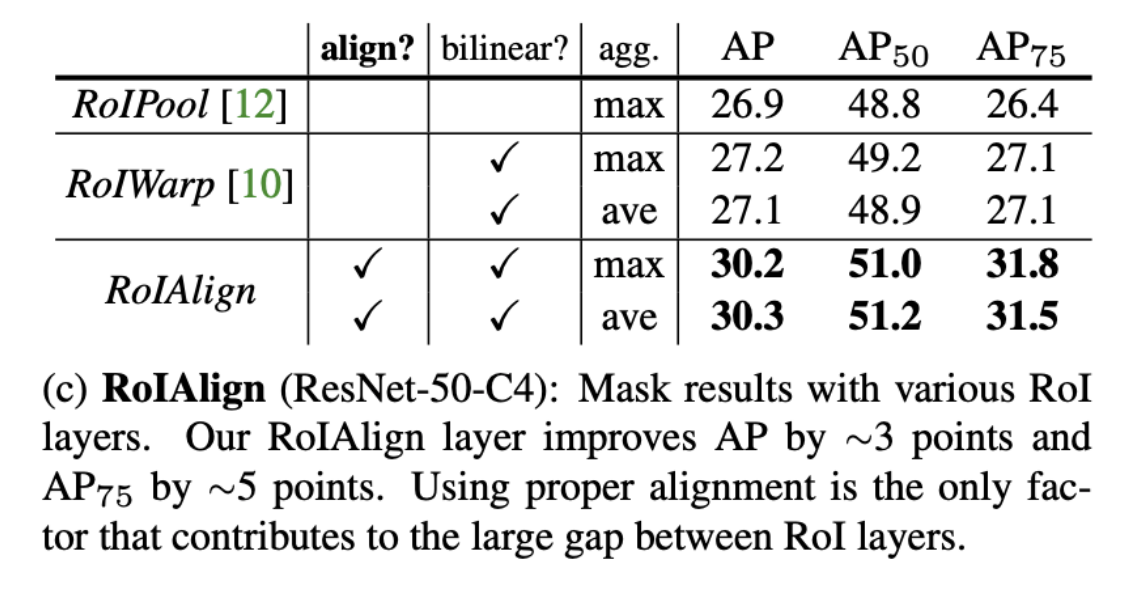
| 방식 | 주요 특징 | 양자화 | 보간 | 정확도 |
|---|---|---|---|---|
| RoI Pooling | 정해진 크기로 나눠 max pooling | ✅ | ❌ | ★ |
| RoI Warping | affine 변환 + 보간 | ❌ | bilinear | ★★ |
| RoI Align | 정확한 실수 좌표에서 보간 | ❌ | bilinear | ★★★ |
(1) Pooling
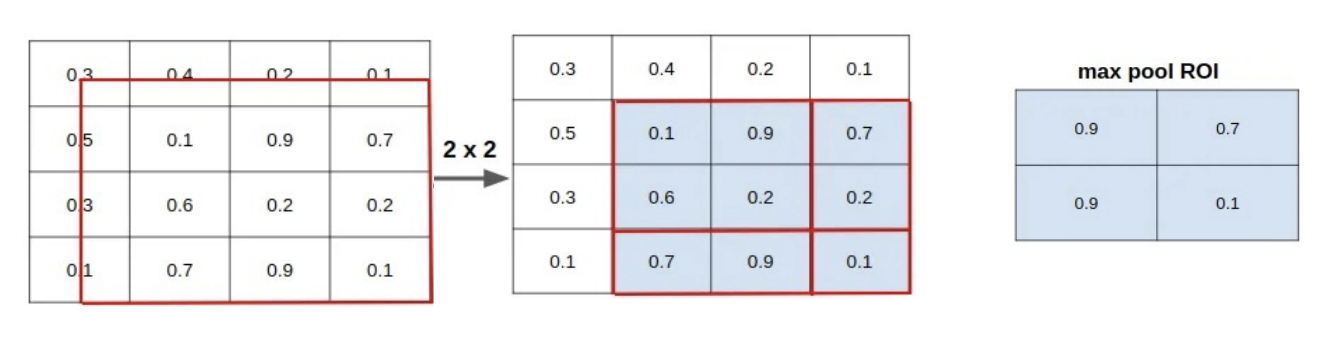
- 입력 특징맵에서 Region of Interest(ROI) 부분을 정해진 크기 (ex: 7×7)로 나눔
- 각 영역에서 max pooling 수행
- 단점: 정수 grid로 강제 양자화하므로, RoI 경계 부정확 → 미세한 위치 정보 손실
예시:
RoI 좌표: (23.2, 42.7, 87.6, 140.3)
→ (23, 42, 87, 140)로 잘림
(2) Warping
- RoI 영역을 정확히 변형(affine transform)해서 고정된 크기로 변환
- 위치는 정수로 자르지 않고, 보간법 (Bilinear) 사용해 값을 추정
- 장점: 연속 좌표 처리 가능
- 단점: RoI에 특화된 구조가 아님 → 일반적인 Spatial Transformer에 가까움
(3) Align
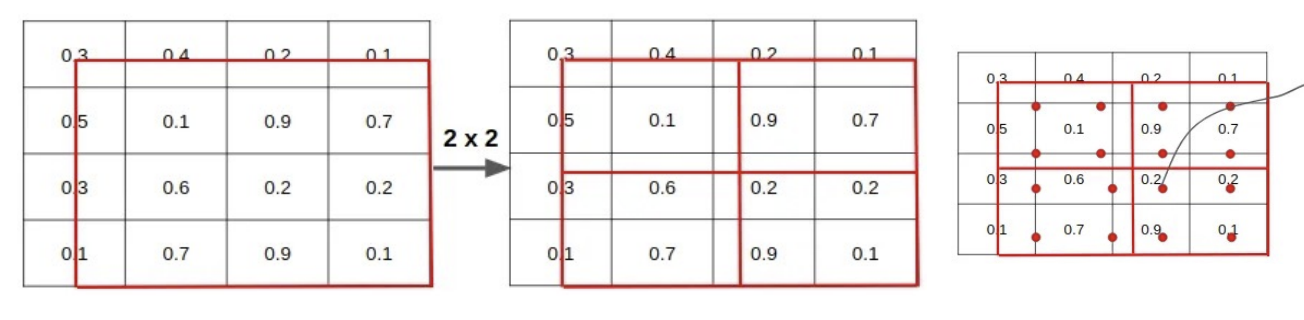
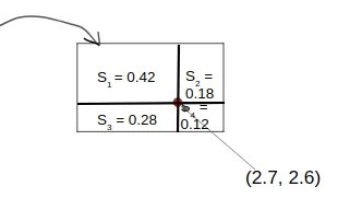
- RoI의 좌표값을 실수 좌표 그대로 유지
- 정확한 위치에서 bilinear interpolation으로 특징값 추출
- Pooling 없이 정확한 특성 유지
- Mask R-CNN이 픽셀 단위 마스크를 예측할 수 있는 핵심 기술
6. Instance Segmentation이 배경을 감지하지 못하는 이유?
(1) 기본 구조가 객체 중심이기 때문
- Instance Segmentation은 객체 단위의 마스크 생성이 목적
- 즉, 관심 있는 object class (예: 사람, 자동차)에 대해서만 마스크를 생성함
- "배경"은 객체가 아니기 때문에 굳이 인스턴스로 예측하지 않음
(2) 기술적으로는 Detection 기반이라서
- 대부분의 인스턴스 분할 모델은 객체 탐지 모델(Faster R-CNN 등)을 기반으로 동작함
- 이들은 RoI(Region of Interest)를 찾고, 해당 영역에만 마스크를 씌움
- ➜ RoI 밖의 영역은 관심이 없음 = 배경은 다 무시됨
(3) 그래서 Panoptic Segmentation 등장
- Semantic과 Instance를 통합하여 객체와 배경을 모두 분리
- 사람 1, 사람 2처럼 객체도 구분하고, 도로/하늘 같은 배경 클래스도 함께 마스킹함

AI Engineer