헬퍼 클래스 만들기에 시간이 너무 많이 든다. 어쩌면 좋지??
학습시간 09:00~02:00(당일17H/누적734H)
◆ 학습내용
U-Net으로 축구 경기 객체 세분화.
요청사항:
- U-Net 모델 사용
- Semantic Segmentation 작업 수행
- 데이터셋을 학습용과 테스트용으로 분할
- Cross Entropy Loss, Dice Loss 등 평가 지표 사용
- 다양한 증강 기법을 적용
1. 계획
Segmentation은 Detection과 비슷한 것 같으면서도 또 다른 것 같다.
탐지 때 했던 분류+회귀에 예측까지 추가로 하는 것인데, 강의 때는 오히려 분류만 진행하는 것처럼 보였다.
아무래도 semantic segmentation에 대해 조금 더 공부를 하고 시작하는 게 맞는 것 같다.
일단 전반적인 계획을 세워보자면, 아래 순서로 진행하면 되지 않을까?
- 데이터 확인
- 헬퍼 클래스 생성
- 데이터셋 생성
- 원본 이미지와 정답 마스크 맵핑
- train, test set 나누기
- 모델 생성 및 학습
- 예측 및 마스크 시각화
- 평가지표 확인
- 성능 개선
맞나 모르겠네. 해보면 알겠지 뭐 ㅋ...
2. Semantic segmentation에 관하여
시작하기 전에 내가 무엇을 해야하는지부터 공부해야겠다.
Semantic segmentation은 정확히 뭘까??
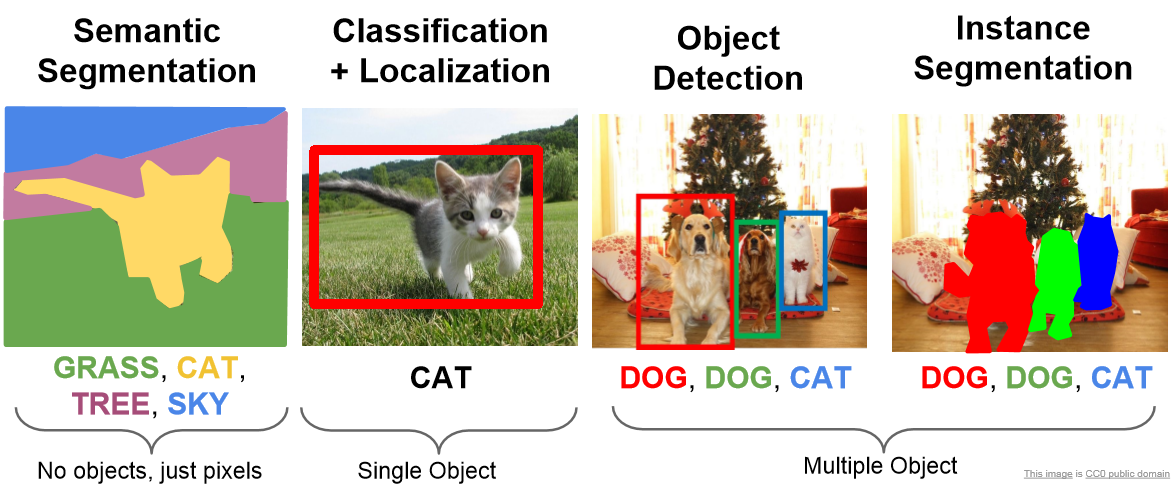
일단 Semantic segmentation을 번역하면 의미론적 분할이다. 말 그대로 픽셀의 의미를 기준으로 분류하겠다는 뜻이다.
기존 Object Detection과 다른 점은, 객체의 경계를 제대로 파악하는 게 중요하다는 것이다. 그래서 고해상도 정보를 다루는 모델이 적합한 것이다.
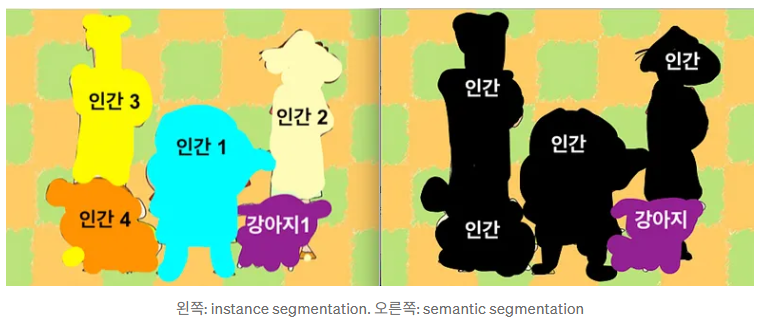
다른 분할 방법인 Instance segmentation과 비교되는 점은, 객체 중심으로 이미지를 다루느냐다.
Semantic은 객체보다 이미지 전체 문맥을 파악하기 때문에 배경까지 분할 가능하다. Instance는 각 객체마다 그것이 무엇인지를 더 세밀하게 파악하기 때문에 배경은 분할할 수 없다.
이런 이유로 Semantic segmentation은 분류에 가깝고, Instance segmentation은 탐지에 가깝다. 사용하는 모델이 다른 근본적인 이유다.
의미 분류 분할 & 객체 탐지 분할 두 테스크를 동시에 수행하고 싶다면, Panoptic Segmentation 방법을 사용해야 한다. 대표 모델은 UPSNet이다.

[ Google Pixel 2 Portratr mode ]
Semantic segmentation을 활용하면 이렇게 DSLR 카메라로 찍은 것처럼 배경을 흐리게 하는 효과를 적용할 수도 있다.
신기하네.
이제 느낌이 왔으니 시작해 보자.
3. 데이터 다운로드

Football Semantic Segmentation!
캐글에 2년 전 올라온 문제다.
지금까지 만난 문제 중에서 가장 뜨끈뜨끈한 녀석이다.
흠 근데 2015년에 나온 U-Net 모델로 제대로 할 수 있으려나??

UEFA 슈퍼컵 2017 레알 마드리드 vs 맨체스터 유나이티드 경기 하이라이트 영상을 기반으로 만들어진 데이터셋이라고 한다.
내가 분류해야 할 클래스는 11개(배경까지 12개)다.
Goal Bar(골대)
Referee(심판)
Advertisement(광고판)
Ground(잔디)
Ball(축구공)
Coaches & Officials(코칭 스태프 및 심판진)
Audience(관중)
Goalkeeper A(팀 A 골키퍼)
Goalkeeper B(팀 B 골키퍼)
Team A(팀 A 선수)
Team B(팀 B 선수)
파밀명을 보니 데이터셋은 COCO 포맷으로 되어있는 것 같다.
파일은 300개 정도뿐이다. 데이터 증강을 하라는 뜻인가??
데이터는 kagglehub에 등록되어 있는 것 같다.
API로 클라우드에 다운받아 보자.
!mkdir -p ~/.kaggle; cp /content/kaggle.json ~/.kaggle/; chmod 600 ~/.kaggle/kaggle.json
!kaggle datasets download -d {kaggle_path} -p {folder_path} --force
!unzip -q "{folder_path}/{unzip_folder}.zip" -d "{folder_path}"
다운로드 완료!

images 폴더에 들어가니 이런 식으로 되어 있다.
첫 번째는 원본, 두 번째는 마스크인데, 세 번째는 뭔지 모르겠다.
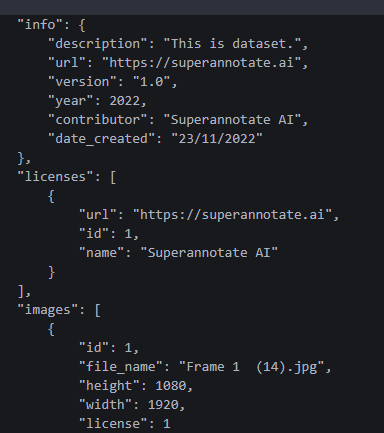
json 파일도 열어봤다. 딕셔너리 비슷한 형태로 데이터가 엄청 많다.
들여다 봐도 뭔지 잘 모르겠군...
4. 헬퍼 클래스에 관하여
뭐부터 해야할까? 감이 1도 안 온다.
Detection 할 때는 BBOX 좌표가 annotation 파일이 있어서 parse를 위한 헬퍼 클래스를 따로 만들었다.
이번에도 헬퍼 클래스가 필요하나?
근데 왜 강사님은 헬퍼 클래스를 안 만들었지?
헬퍼 클래스가 정확히 뭐지?
헬퍼 클래스를 안 만들면 문제가 생기나?
헬퍼 클래스가 필요없는 상황은 뭐지?
헬퍼 클래스가 필요한 상황에서도 사용하지 않을 수 있나?
미치겠다.
지선생과 헬퍼 클래스가 뭔지부터 공부하고 시작해야겠다.
(1) 헬퍼 클래스가 정확히 뭐지?
"헬퍼 클래스"는 Helper Class, 즉 도와주는 용도의 클래스를 의미함
프로그램의 주 흐름(Main flow)이 아닌, 특정 기능을 효율적이고 깔끔하게 처리하기 위한 보조 클래스
보통 반복적인 로직, 자주 쓰이는 전처리 또는 후처리 과정, 복잡한 구조를 단순화하기 위해 사용
사용 예시:
- "정답 마스크를 생성한다"는 기능을 위해
- JSON 파일을 읽고
- Polygon 좌표를 추출하고
- 이미지를 불러와서 크기를 계산하고
- 마스크 배열을 만들고
- 그 위에 다각형을 그려서
- category_id에 따라 픽셀 값을 지정하고
- PNG로 저장하는 작업을 반복하는 구조
- 위의 일련의 과정을 함수로 따로 떼어내고, 그걸 묶어서 하나의 객체로 구성한 것이 헬퍼 클래스
코드 예시:
class CocoMaskGenerator:
def __init__(self, json_path, image_root, output_dir):
... # JSON 불러오기, 출력 경로 설정
def generate_all_masks(self):
... # 이미지 전체에 대해 마스크 생성 반복
def _generate_mask_for_image(self, image_info):
... # 개별 이미지에 대해 마스크 그리기 및 저장
(2) 헬퍼 클래스 사용의 장점?
- 코드의 재사용성을 높임
- 코드 가독성이 좋아짐 (main loop에서 복잡한 로직이 사라짐)
- 유지보수에 유리함 (한 곳만 고치면 전체에 적용됨)
- 다른 프로젝트나 파이프라인에서도 쉽게 이식 가능
- 팀 개발 시 모듈화된 구조로 협업에 유리
(3) 헬퍼 클래스가 필요한 상황?
필요한 상황:
- 동일한 로직이 3회 이상 반복됨
- 이미지 수가 많음 (100장 이상)
- JSON, XML 등의 구조화된 비정형 데이터를 정제해야 함
- 코드가 40줄 이상으로 반복되기 시작함
- 실험을 여러 번 돌릴 예정임
필요없는 상황:
- 이미지 5장 이하의 소규모 실습
- 한 번만 실행하면 되는 정적 코드
- 빠르게 해치워야 하는 과제성 작업
(4) 헬퍼 클래스 vs 데이터셋 클래스?
| 구분 | 헬퍼 클래스 | Dataset 클래스 |
|---|---|---|
| 목적 | 마스크 파일 등을 생성하는 작업 전처리용 | 학습/평가 루프에서 샘플을 불러오기 위함 |
| 시점 | 학습 전 | 학습 중 |
| 저장 | 파일로 저장 (.png 등) | 메모리 or 텐서로 반환 |
| 반복성 | 반복적인 마스크 생성 작업을 단순화 | 배치 단위 학습 반복에 사용됨 |
| 예시 | CocoMaskGenerator | CustomSegmentationDataset |
(5) 헬퍼 클래스 부재로 문제가 생기는 상황?
- 기능은 돌아가지만 코드 유지보수가 어렵다
- 학습 루프 안에 마스크 생성 로직이 들어가면
- 디버깅이 어렵고
- 재사용성이 떨어지고
- 가독성이 매우 나빠짐
- 실험 결과마다 다르게 처리해야 할 때 불편함
- "필수"는 아니나, "있으면 좋은 것" 이상의 가치가 있음
(6) 요약
| 항목 | 요약 |
|---|---|
| 핵심 역할 | 반복적인 처리 과정을 한 번에 처리하게 도와줌 |
| 존재 목적 | 복잡한 전처리를 깔끔하게 정리, 코드 재사용성 확보 |
| 쓰는 이유 | 가독성, 유지보수성, 구조화, 효율성 향상 |
| 쓰기 좋은 때 | 반복 많은 전처리, 다수 이미지 처리, JSON/좌표 기반 마스크 생성 |
| 사용 안 해도 되는 때 | 실습용 소규모 데이터, 한 번 실행하는 코드 |
| Dataset과의 차이 | Dataset은 학습 루프용, Helper는 준비용 |
그냥 코드만 짜는 사람 → 개발자
구조를 설계하는 사람 → 엔지니어
그렇구나. 무조건 만들어야할 필요는 없지만 코드 구조가 복잡해질수록 필요성이 커진다. 특히 협업이나 유지보수를 위해서는 만드는 편이 좋다.
미래를 위해 만들어보는 쪽을 선택하자.
나는 엔지니어가 될 꺼니까!!
5. 데이터 구조 확인
헬퍼 클래스를 만들기 전에 데이터 구조부터 확인해야 한다.
이번에는 annotation 파일 대신 무슨 Pixel.json 파일이 있다.
json_path = DIR['data']+'/FootballSegmentation/COCO_Football Pixel.json'
with open(json_path, 'r') as f:
data = json.load(f)
print(data.keys())open 명령어를 사용하면 json 파일 key값을 확인할 수 있다고 한다.

키값이 나왔다. annotation이 여기에 있군.
이중에서 필요한 건 'images', 'annotations', 'categories' 이렇게 3가지일 것 같다.
추측해 보자면,
images는 파일명, annotations는 마스크 좌표, categories 클래스 이름일 것 같다.
print("\n▶ Images")
print(data['images'][0])
print("\n▶ Annotations")
print(data['annotations'][0])
print("\n▶ Categories")
print(data['categories'][0])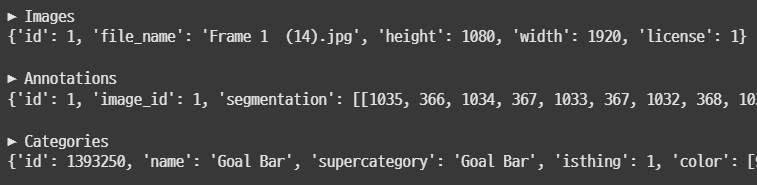
0번 인덱스에 해당하는 데이터 정보가 쭉 나왔다.
생각한 것보다 정보가 많다.
카테고리만 다 확인하고 다음으로 넘어가자.
with open(json_path, 'r') as f:
data = json.load(f)
for cat in sorted(data['categories'], key=lambda x: x['id']):
print(f"{cat['id']}: {cat['name']}")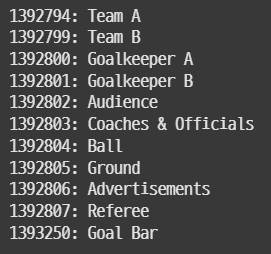
11개 클래스의 이름과 id가 나왔다.
이제 헬퍼를 만들어 보자!
6. 헬퍼 클래스 생성
class SegmentationHelper:
def __init__():
흠...흠....
뭘 넣어야 할까?
일단 json 안에 있는 데이터 중 이미지, 마스크 좌표, 클래스 이렇게 3개를 가져와야 한다.
class SegmentationHelper:
def __init__(self, json_path, image_dir, mask_dir, category_map=None):
self.json_path = json_path
self.image_dir = image_dir
self.mask_dir = mask_dir
self.category_map = category_map
def _load_json():
def generate_masks():
def _generate_mask():def _load_json(): (클래스 전용 함수)
json파일 로드
image 폴더 로드
마스크 저장할 폴더 선택
클래스 id에 1~11 인덱스 부여
딕셔너리 형태로 저장
def _generate_mask(): (클래스 전용 함수)
단일 이미지 id, 크기, 이름 로드
0 레이어 생성 후 마스크 좌표 입력
생성한 마스크 폴더에 저장
def generate_masks(): (실제 사용할 함수)
모든 이미지 돌면서 위 함수 적용
일단 이렇게 하면 될 것 같다!
1번 함수부터 만들어 보자.
def _load_json(self):
with open(self.json_path, 'r') as f:
data = json.load(f)
self.images = data['images']
self.annotations = data['annotations']
self.categories = data['categories']아까 json 확인했던 것처럼 불러와서 이미지, 좌표, 카테고리로 나눠준다.
# 이미지 매핑
self.map_image_id = {img['id']: img['file_name'] for img in self.images}이미지 id를 기반으로 파일을 찾을 수 있도록 딕셔너리를 만들었다.
# 마스크 좌표 매핑
self.map_annotations = {}
for ann in self.annotations:
image_id = ann['image_id']
self.map_annotations.setdefault(image_id, []).append(ann)이미지 id에 마스크 좌표를 매핑한 딕셔너리를 만들었다.
이걸로 한 이미지에 클래스가 몇 개 있는지 알 수 있다.
# 카테고리 번호 매핑
if self.map_category_id is None:
self.category_map = {cat['id']: idx + 1 for idx, cat in enumerate(self.categories)}카테고리를 인덱스 번호로 변경하는 코드다.
지금 카테고리가 1392794처럼 되어 있는데, 이걸 1~11로 부여해준다.
def _generate_mask(self, image_info):
image_id = image_info['id']
width = image_info['width']
height = image_info['height']
file_name = image_info['file_name']
anns = self.map_annotations.get(image_id, [])
mask = np.zeros((height, width), dtype=np.uint8)마스크 생성 함수다.
이미지 정보를 가져와서 빈 마스크를 만든다.
for ann in anns:
segmentation = ann['segmentation']
category_id = ann['category_id']
class_id = self.map_category_id[category_id]
for poly in segmentation:
pts = np.array(poly).reshape(-1, 2).astype(np.int32)
cv2.fillPoly(mask, [pts], class_id)
# 저장 경로
mask_name = os.path.splitext(file_name)[0] + '.png'
mask_path = os.path.join(self.mask_dir, mask_name)좌표를 찍어서 저장한다.
def generate_masks(self):
for image in self.images:
self._generate_mask(image)실제로 내가 사용할 함수다.
이걸 사용하면 헬퍼 클래스가 싹 실행된다.
helper = SegmentationHelper(
json_path=DIR['data']+'/FootballSegmentation/COCO_Football Pixel.json',
image_dir=DIR['data']+'/FootballSegmentation/images',
mask_dir=DIR['data']+'/FootballSegmentation/masks',
overwrite=True
)만든 클래스를 healper 변수에 저장했다.
helper.generate_masks()함수 실행!!
이미지 마스크가 쭉 생성된다.
def summary(self):
print(f"Total Images: {len(self.images)}")
print(f"Total Annotations: {len(self.annotations)}")
print(f"Total Categories: {len(self.categories)}")
print("Category Index:")
for cat in self.categories:
mapped_id = self.category_map[cat['id']]
print(f" - ({mapped_id}) {cat['id']}: {cat['name']}")생성된 폴더를 요약하는 코드를 추가했다.
helper.summary()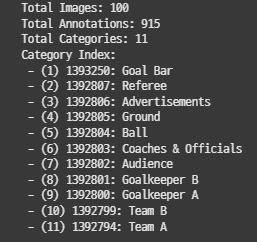
오잉?? 이미지가 총 100장이네?
아 총 300장 중에 원본이미지만 가져와서 그런 것 같다.
카테고리 번호도 잘 매핑됐다.
폴더 열어서 함 확인해 보자!

???? 만든 마스크가 다 검은색이다.

근데 자세히 보니까 뭔가 윤곽이 있긴 하다.
for poly in segmentation:
pts = np.array(poly).reshape(-1, 2).astype(np.int32)
cv2.fillPoly(mask, [pts], class_id)이 부분에서 픽셀을 클래스 id 숫자로 넣어서 그런 것 같다.
컬러가 1~11 사이니까 어둡게 나오는 것 같다.
mask_path = DIR['data']+'/FootballSegmentation/masks/Frame 1 (1).png'
mask = np.array(Image.open(mask_path))
plt.imshow(mask, cmap='gray')
plt.show()
print("Classes:", np.unique(mask))플롯으로 컬러맵을 넣으면 볼 수 있나??
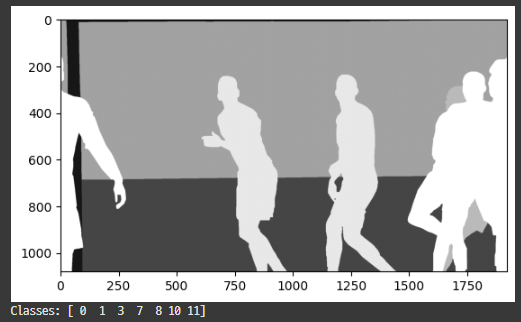
나온다!! 클래스는 총 7개라고 한다.
어라? 근데 내 눈에는 5개인데...???
- (0) Background
- (1) 1393250: Goal Bar
- (3) 1392806: Advertisements
- (7) 1392802: Audience
- (8) 1392801: Goalkeeper B
- (10) 1392799: Team B
- (11) 1392794: Team A
골키퍼, 선수 A B 구분이 안 되는 것 같다.
음 컬러맵을 gray로 한 게 문제인가...
plt.imshow(mask, cmap='hot')hot으로 재출력!
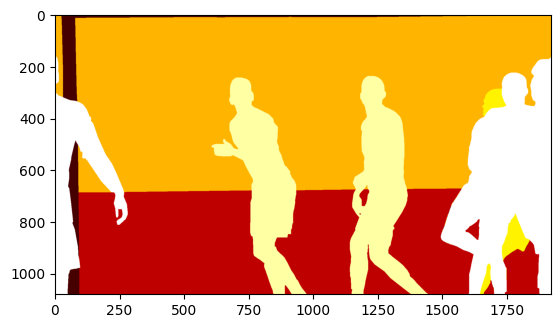
오! 7개가 딱 맞네. 좋다 좋다.
이제 데이터셋을 만들 차례다.
근데 벌써 하루가 끝났네...
오늘도 헬퍼클래스에서 시간을 너무 많이 낭비했다.
이것도 시간 안에 못할 것 같은 불길한 예감이 든다.
일단 내일 이어서 해보자.
