어렵다 어려워.
학습시간 16:00~02:00(당일10H/누적790H)
◆ 학습내용
cGAN으로 패션 아이템 이미지 생성하기
어제(1번~2번)에 이어서 3번부터 시작!
3. 모델 생성
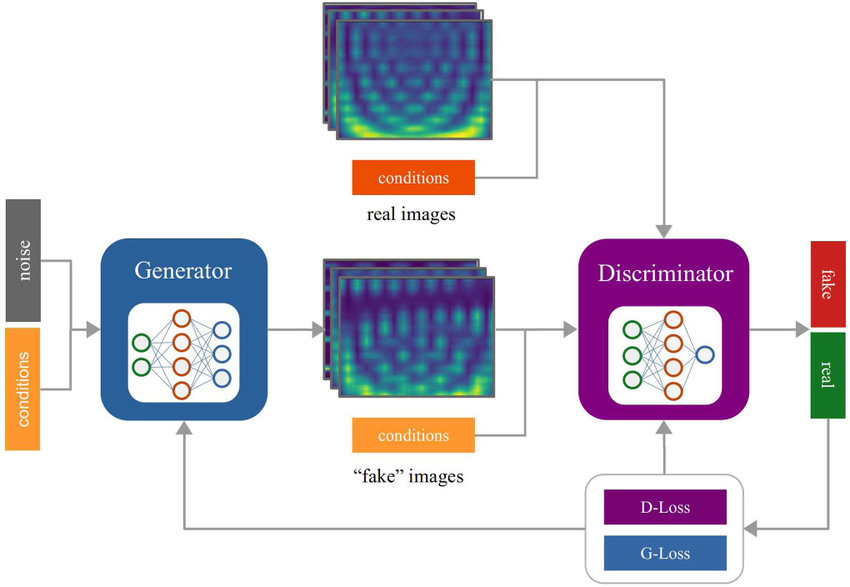
모델 구조를 어떻게 해야하나 찾아보다가, 괜찮은 이미지를 하나 발견했다.
일단 Generator와 Discriminator 클래스를 만들어야 한다.
G에는 노이즈와 컨디션을 넣고, D에는 가짜값과 컨디션을 넣어야 한다.
만들어 보자!!
noise_dim = 100
embedding_dim = 100
img_dim = 28 * 28
num_classes = 10모델에 공통적으로 들어갈 변수를 만들었다.
- noise_dim: 가짜 생성 시 필요한 노이즈값
- embedding_dim: 임베딩 할 차원 수
- img_dim: 이미지 사이즈
- num_classes: 클래스 수
class Generator(nn.Module):
def __init__(self, noise_dim, embedding_dim, img_dim, num_classes):
super().__init__()
self.label_embed = nn.Embedding(num_classes, embedding_dim)생성자 클래스부터 만들어 보자.
도입부에 아까 정의한 변수를 싹 다 넣었다.
일단 클래스를 임베딩 차원에 넣어준다.
self.model = nn.Sequential(
nn.Linear(noise_dim + embedding_dim, 256),
nn.ReLU(inplace=True),
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Linear(512, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(inplace=True),
nn.Linear(1024, img_dim),
nn.Tanh()
)그 후 노이즈+임베딩차원을 해서 FC 레이어로 보낸다.
마지막에 하이퍼볼릭탄젠트를 써보는 건 처음이다.
하볼탄을 쓰는 이유는 픽셀값을 -1 ~ 1로 표현하기 위함이다.
def forward(self, z, labels):
label_vec = self.label_embed(labels)
x = torch.cat([z, label_vec], dim=1)
out = self.model(x)
return out만든대로 순전파한다.
파라미터에 z와 labels를 넣었는데, 이건 학습할 때 노이즈를 랜덤으로 넣어서 concatenate 하기 위함이다.
생성자 만드는 건 생각보다 간단한 것 같다.
나중에 디멘션 관련해서 조금만 더 공부해야겠다.
class Discriminator(nn.Module):
def __init__(self, embedding_dim, img_dim, num_classes):
super().__init__()
self.label_embed = nn.Embedding(num_classes, embedding_dim)이번엔 판별자 클래스 도입부다.
생성자와 동일하게 임베딩하는 것부터 만들었다.
self.model = nn.Sequential(
nn.Linear(img_dim + embedding_dim, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(256, 1),
nn.Sigmoid()
)메인 부분이다.
생성자에 ReLu를 쓰고 판별자에 LeakyReLu를 쓰는 이유는 판단 여부를 확고히 하기 위함이다.
렐루는 음수를 버리고 양수만 보낸다. 그래서 결과값이 더 크다. 물론 뉴런이 죽는 경우가 생긴다. 그래서 배치놈으로 정규화를해서 그 확률을 줄여주는 것이다. 쉽게 말해, 생성자는 거침없이 창작해야 하기 때문.
리키렐루를 쓰면 뉴런이 죽지 않는다. 그래서 미세한 신호까지 잡아낼 수 있다. 판별자에 배치놈을 안 쓰는 이유는 가짜 이미지와 진짜 이미지의 차이를 평준화하면 안 되기 때문이다. 쉽게 말해, 판별자는 아주 꼼꼼하게 들여다 보아야 하기 때문.
과적합을 막기 위해 중간중간 드롭아웃을 넣었다.
진짜&가짜 이진분류이기에 마지막 FC 아웃풋은 1로 했다.
마무리 시그모이드로 감싸주면 끝.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
G = Generator(noise_dim, embedding_dim, img_dim, num_classes).to(device)
D = Discriminator(embedding_dim, img_dim, num_classes).to(device)
print(summary(G, input_data=(torch.randn(1, noise_dim).to(device), torch.tensor([0]).to(device))))
print(summary(D, input_data=(torch.randn(1, img_dim).to(device), torch.tensor([0]).to(device))))인포를 확인해 보자!
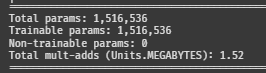
G의 웨이트
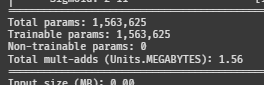
이건 D의 웨이트
둘 다 약 150만 개 정도 된다.
4. 모델 학습
학습 루프가 이번 미션의 가장 큰 난관이다.
일단 차근차근 해보자.
def train(G, D, dataloader, noise_dim, num_classes, epochs, lr):
criterion = nn.BCELoss()
G_optimizer = optim.Adam(G.parameters(), lr=lr, betas=(0.5, 0.999))
D_optimizer = optim.Adam(D.parameters(), lr=lr, betas=(0.5, 0.999))
G_scheduler = optim.lr_scheduler.ReduceLROnPlateau(
G_optimizer, mode='min', factor=0.8, patience=2, verbose=True
)
train 함수를 만들고, 아까 만든 모델과 변수를 넣어준다.
에폭과 lr는 수동으로 설정할 예정
모델에 2개라 옵티마이저도 G와 D 2개로 나눴다.
for epoch in range(epochs):
G.train()
D.train()
total_G_loss = 0
total_D_loss = 0
for real_imgs, labels in tqdm(dataloader):
batch_size = real_imgs.size(0)
real_imgs = real_imgs.view(batch_size, -1).to(device)
labels = labels.to(device)
real_labels = torch.ones(batch_size, 1, device=device)
fake_labels = torch.zeros(batch_size, 1, device=device)늘 만들던 for문 2개를 만들어 준다.
다른 점은 ones, zeors 레이어가 추가되었다는 것이다.
D는 둘 다 학습에 사용하고, G는 ones 레이어만 사용한다.
# Discriminator
z = torch.randn(batch_size, noise_dim, device=device)
fake_imgs = G(z, labels)
D_loss_real = criterion(D(real_imgs, labels), real_labels)
D_loss_fake = criterion(D(fake_imgs.detach(), labels), fake_labels)
D_loss = D_loss_real + D_loss_fake
D_optimizer.zero_grad()
D_loss.backward()
D_optimizer.step()Discriminator 학습 부분이다.
아까 모델 forwar() 파라미터로 넣은 z를 여기서 정의해준다.
랜덤으로 노이즈를 만들어서 라벨과 concatenate 해준다.
# Generator
z = torch.randn(batch_size, noise_dim, device=device)
gen_imgs = G(z, labels)
G_loss = criterion(D(gen_imgs, labels), real_labels)
G_optimizer.zero_grad()
G_loss.backward()
G_optimizer.step()Generator 학습 부분이다.
똑같이 z에 노이즈를 만들어서 넣어준다.
둘의 로스에 차이점이 있는데, D 로스는 D_loss_real + D_loss_fake 이고, G 로스는 criterion(D(gen_imgs, labels), real_labels) 이다.
total_G_loss += G_loss.item()
total_D_loss += D_loss.item()
avg_G_loss = total_G_loss / len(dataloader)
avg_D_loss = total_D_loss / len(dataloader)
G_scheduler.step(avg_G_loss)
print(f"[{epoch+1}/{epochs}] | G Loss: {avg_G_loss:.4f} | D Loss: {avg_D_loss:.4f}")로스를 담을 변수를 만들고 프린트문에 넣어준다.
학습 루프가 뭔가 내가 기존에 알고 있던 구조인 것 같으면서도 또 다르다.
train(G, D, dataloader, noise_dim, num_classes, epochs=100, lr=0.00001)일단 한 100에폭 정도 돌려보자.
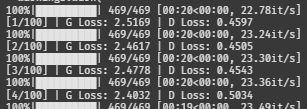
G 로스가 점점 내려가는 것 같다.
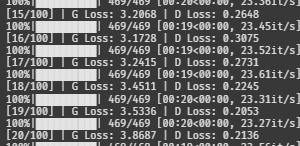
??? 잠시만요 ???
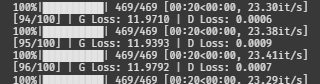
G 로스가 점점 늘더니 12까지 올라갔다.
D 로스는 0.001이다. 이건 내려가면 안 되는 건데,,,
완전 망했다고 할 수 있다 ^^
5. 모델 개선(1차)
뭐가 문제일까?
G 로스가 계속 올라간다는 건 진짜처럼 보이는 것을 생성하지 못하고 있다는 뜻이다.
D 로스가 계속 내려간다는 건 전부다 가짜로 판별하고 있다는 뜻이다.
쉽게 말해, 도둑놈이 두들겨 맞고 있다는 뜻이다.
어떻게 하면 도둑을 강하게 만들 수 있을까?
반대로 생각해야 하나??
어떻게 하면 경찰을 약하게 만들 수 있을까?
self.model = nn.Sequential(
nn.Linear(img_dim + embedding_dim, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.5),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.5),
nn.Linear(512, 1),
nn.Sigmoid()
)D 시퀀셜 부분에 FC 레이어를 한줄 없앴다.
원래 최종 아웃풋이 (256, 1)인데 (512, 1)로 변경했다.
조금 덜 자세히 보면 괜찮아지지 않을까?
그리고 드롭아웃도 0.3에서 0.5로 변경했다.
train(G, D, dataloader, noise_dim, num_classes, epochs=100, lr=0.00001)다시 돌려보자
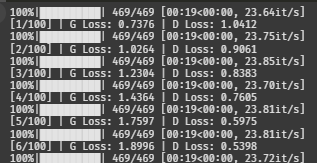
흠,,, 시작부터 망한 느낌이 든다.
조금만 더 기다려볼까.
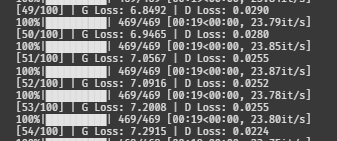
에라이...^^
6. 모델 개선(2차)
지난 번 VGG16 전이학습 할 때가 떠올랐다.
backbone이 두 개로 나누어져 있었는데 extra부분만 학습이 가능했다. backbone이 너무 예민해서 head와의 learning rate을 다르게 주니까 학습이 잘 되었던 기억이 있다.
만약 현재 D가 너무 강하다면, lr을 각각 다르게 주면 되지 않을까??
G에게 초반 부스터를 달아주면 조금 괜찮아지지 않을까!?
def train(G, D, dataloader, noise_dim, num_classes, epochs):
criterion = nn.BCELoss()
G_optimizer = optim.Adam(G.parameters(), lr=0.0001, betas=(0.5, 0.999))
D_optimizer = optim.Adam(D.parameters(), lr=0.00001, betas=(0.5, 0.999))
시작 lr을 10배 차이나도록 조정했다.
어차피 스케줄러가 G에만 적용되기 때문에 괜찮을 것 같다.
train(G, D, dataloader, noise_dim, num_classes, epochs=100)G야 제발 힘내주렴...

오!! 일단 G 심폐소생술은 성공한 것 같다...!?
D에게 처참한 수치가 나왔지만 일단 조금 더 기다려보자.
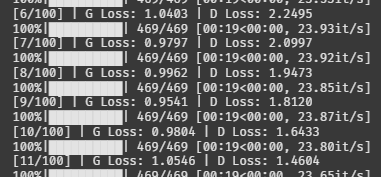
오!! 신기하게도 두 모델의 밸런스가 잡혀가고 있다.
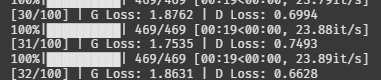
헉.. 갑자기 G가 너무 강하지고 있다.
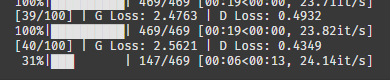
이번엔 D가 점점 약해지고 있다.
어쩌면 좋지..? 이대로면 100에폭 도달 시 망할 확률이 높다.
일단 20에폭만 돌려서 시각화를 해보자.
train(G, D, dataloader, noise_dim, num_classes, epochs=20)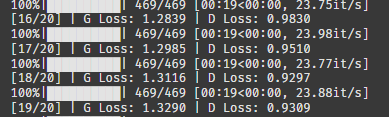
로스는 최악까진 아닌 것 같다.
@torch.no_grad()
def show_cgan_samples(G, noise_dim, num_classes, device):
G.eval()
z = torch.randn(num_classes, noise_dim, device=device)
labels = torch.arange(num_classes, device=device)
gen_imgs = G(z, labels).view(-1, 1, 28, 28).cpu()
fig, axes = plt.subplots(2, 5, figsize=(12, 5))
axes = axes.flatten()
for i in range(num_classes):
axes[i].imshow(gen_imgs[i].squeeze(), cmap='gray')
axes[i].set_title(class_names[i], fontsize=20)
axes[i].axis("off")
plt.tight_layout()
plt.show()
show_cgan_samples(G, noise_dim, num_classes, device)
시각화 코드를 후딱 컨닝했다.
엇 @이거는 클래스 메소드였나? 오랜만에 본다.
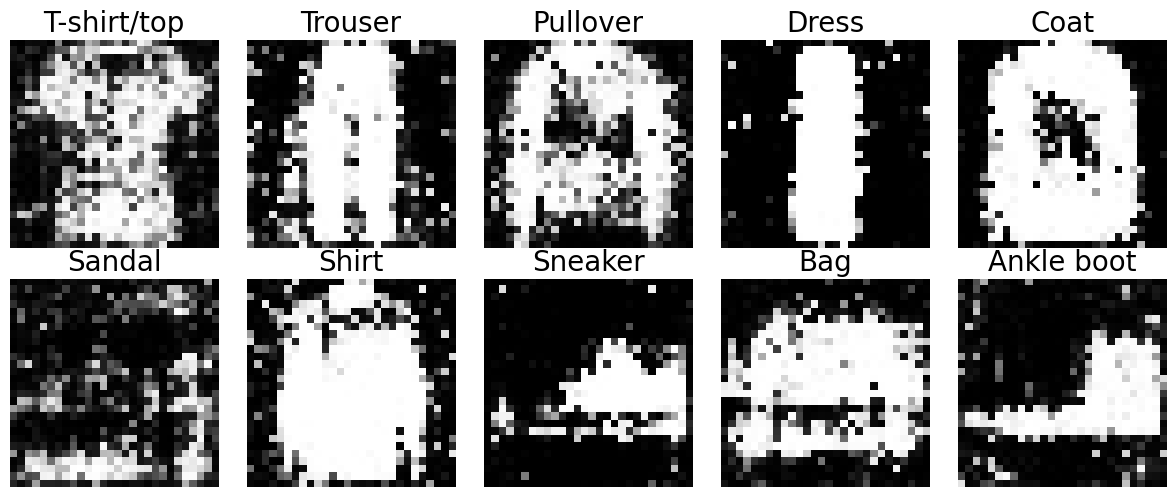
흠,,, 원래 이렇게 생겼었나. 나이가 들어서 눈이 침침해진 건가.

원본과 비교해보니 확실히 문제점이 보인다.
그래도 일단 윤곽은 대충 잡은 것 같아서 다행이다.
내일은 성능 개선에 집중해야겠다.
D 모델 레이어를 원래대로 돌려서 판별자에게 다시 힘을 실어주고, lr 조절을 통해 밸런스를 잡는 게 맞는 것 같다.
후,,, 어렵다 어려워
