이번 주말도 쉬긴 글렀어요.
학습시간 09:00~21:00(당일17H/누적780)
◆ 학습내용
딥러닝으로 패션 아이템 이미지 생성하기
요청사항:
- FashionMNIST 데이터셋의 각 패션 아이템 생성
- cGAN(Conditional GAN) 모델을 직접 설계하고 학습
- 생성된 이미지의 품질을 정성적(시각적 평가) 및 정량적(FID, IS 등, optional)으로 평가
1. 데이터 확인
이번 미션은 MNIST 데이터셋으로 진행한다.
얼마만에 보는지 모르겠다. 아주 반가워 죽겠네.
data_dir = develop('local')['data']
data_dir개발환경을 빠르게 설정해주고,
dataset_temp = torchvision.datasets.FashionMNIST(
root=data_dir,
train=True,
download=True,
transform=transforms.ToTensor()
)데이터를 불러와 준다.
음 정규화를 하기 위해서 mean, std 값을 찾아야 한다.
찾아보면 어딘가에 있겠지만, 이번엔 내가 한번 구해보자.
images, _ = next(iter(DataLoader(dataset_temp, batch_size=len(dataset_temp), shuffle=False)))
mean, std = images.mean().item(), images.std().item()
print(f"Mean: {mean:.6f}, Std: {std:.6f}")현재 로더에 len()을 찍어서 next(iter())를 돌리면 금방 나온다.

FashionMNIST 데이터셋의 정규화 값이 나왔다. 7만 장을 전부 다 돌렸고, 아래와 같은 평균&표준편차 값이 나왔다.
Mean: 0.286041, Std: 0.353024
확실히 간단한 데이터셋이 맞긴 한 것 같다.
해상도가 크면 100장만 돌려도 시간이 오래걸리는데,,,
transform = v2.Compose([
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize((0.286041,), (0.353024,))
])
dataset = torchvision.datasets.FashionMNIST(
root=data_dir,
train=True,
download=False,
transform=transform
)어쨌든, 정규화 수치를 넣고 데이터셋을 다시 만들었다.
import matplotlib.pyplot as plt
class_names = [
"T-shirt/top", "Trouser", "Pullover", "Dress", "Coat",
"Sandal", "Shirt", "Sneaker", "Bag", "Ankle boot"
]
def show_images(dataset):
shown = set()
class_to_img = {}
for img, label in dataset:
label = label.item() if isinstance(label, torch.Tensor) else label
if label not in shown:
class_to_img[label] = img
shown.add(label)
if len(shown) == 10:
break
fig, axes = plt.subplots(2, 5, figsize=(12, 5))
axes = axes.flatten()
for i in range(10):
img = class_to_img[i]
if img.shape[0] == 1:
img = img.squeeze(0)
ax = axes[i]
ax.imshow(img, cmap="gray")
ax.set_title(class_names[i], fontsize=20)
ax.axis("off")
plt.tight_layout()
plt.show()
show_images(dataset)이미지가 어떻게 생겼나 간단하게 확인해 보자.
사실 이미 해봐서 어떤 데이터인지 다 알고 있긴 하지만,,, 그래도 연습은 배신하지 않으니까 ^^

이미지가 나왔다.
이걸로 전처리는 끝인 것 같다.
2. cGAN에 관하여
이번 미션이 어렵게 느껴지는 건, 데이터 때문이 아니라 모델 때문이다.
Generative Modeling 배운지도 고작 하루됐고, 심지어 cGAN은 코드가 어떻게 생겼는지도 모르기 때문이다.
일단 모델을 생성하기 전에 cGAN 정확히 뭐하는 녀석인지 알고 시작해야할 것 같다.
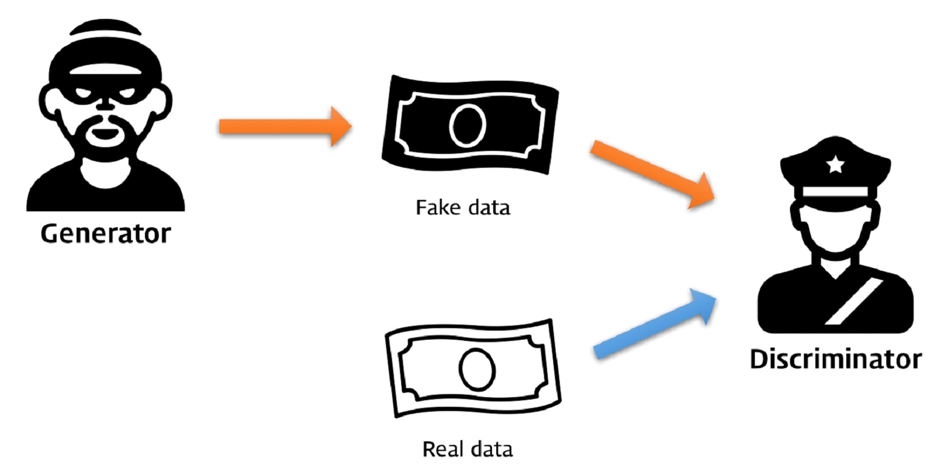
일단 GAN부터 복습해보자.
GAN은 Generator(G)와 Discriminator(D) 두 모델이 서로 경쟁하는 구조로 되어 있다.
생성자 G는 무작위 잡음으로 가짜 데이터를 생성하고, 판별자 D는 그 데이터의 진짜 여부를 판단한다.
여기서 핵심은 어느 모델에게 어떤 것이 목적이냐는 거다.
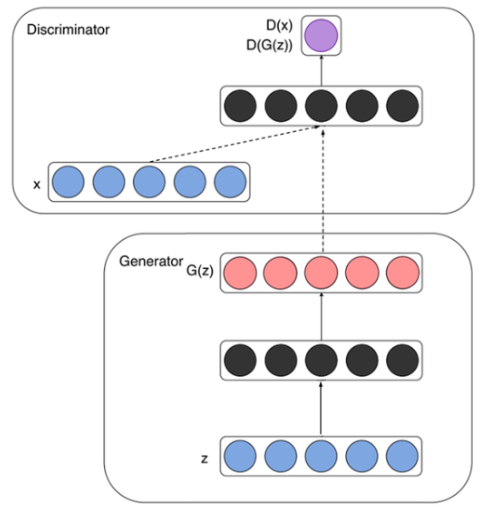
G의 핵심은 가짜고 D의 핵심은 진짜다.
그럼 cGAN은 뭐냐?
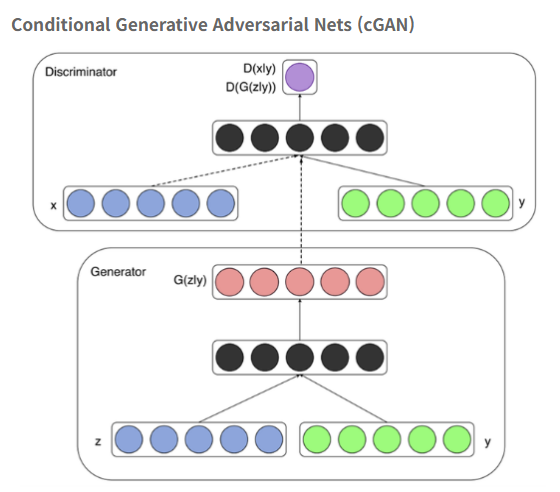
condition은 제공하느냐의 차이로, 쉽게 말해 y 라벨링 값의 유무다.
이미지로 보았을 때, GAN 구조에서 초록색 y값이 추가된 것을 제외하고 전부다 일치한다.
그렇다는 건, 이번 cGAN 미션을 진행할 때는 라벨링이 핵심 요소라는 뜻이다.
아직 어느 부분에 필요할지는 모르겠지만, G가 가짜 데이터를 생성하고 D가 진짜 데이터를 학습하는 구조를 만들 때 라벨링을 어떻게 처리할 것인지에 대해 집중해야 한다.

G는 z와 y를 입력하고, D는 x와 y를 입력한다고 한다.
여기서 입력이란 아마도 모델 초기부분 혹은 학습 내부 구조일 테다.

사실 구조만 보면 모델 자체를 구현하는 건 크게 어려울 것 같지 않다. 막 어텐션 게이트 같은 걸 만드는 게 아니니까.
하이퍼볼릭 탄젠트 함수는 써음 써본다. 이건 약간 설레네.
| 항목 | GAN | cGAN |
|---|---|---|
| 조건 사용 | 사용하지 않음 | 조건을 사용함 (예: 라벨, 텍스트 등) |
| 생성기 입력 | 잡음 벡터만 입력함 | 잡음과 조건을 함께 입력함 |
| 판별기 입력 | 이미지만 입력함 | 이미지와 조건을 함께 입력함 |
| 생성 결과 제어 | 불가능함 (무작위 생성) | 가능함 (조건에 맞게 생성) |
| 조건 정보 필요 여부 | 필요 없음 | 반드시 필요함 |
| 활용 예시 | 랜덤 이미지 생성 (예: 사람 얼굴) | 특정 클래스 이미지 생성 (예: 숫자 5만 생성) |
| 모델 구조 | 단순함 | 조건 입력 구조로 인해 다소 복잡함 |
| 적합한 상황 | 자유로운 이미지 생성이 필요한 경우 | 특정 조건을 만족하는 이미지 생성이 필요한 경우 |
GAN과 cGAN 비교표를 만들어봤다.
표에서도 느껴지듯, cGAN는 조건이라는 단어가 계속 반복된다. 여기서 조건은 y값일 것이다.

한 블로그에서 cGAN을 통해 MNIST 손글씨 데이터를 생성한 것을 봤다.
숫자를 어느 정도 잘 생성한 것 같긴 한데, 내가 원하는 수준의 결과는 아니다.
원래 cGAN의 성능이 이정도 뿐인 건가?
만약 저 데이터가 cGAN의 최대 역량이라면, 내가 만드는 이미지도 큰 차이는 없을 것이다.
큰일이다. 난 성능이 좋지 않으면 만족할 수 없는데,,,
이번 미션의 핵심은 모델 생성과 학습인데, 아무래도 공부를 조금 더 하고 시작해야 할 것 같다.
미션을 금요일에 주는 건 아마도 주말에 쉬지 말라는 거겠지...?
