후..............
학습시간 09:00~02:00(당일17H/누적807H)
◆ 학습내용
cGAN으로 패션 아이템 이미지 생성하기
어제(3번~6번)에 이어서 7번부터 시작!
7. 모델 개선(3차)

(원본)
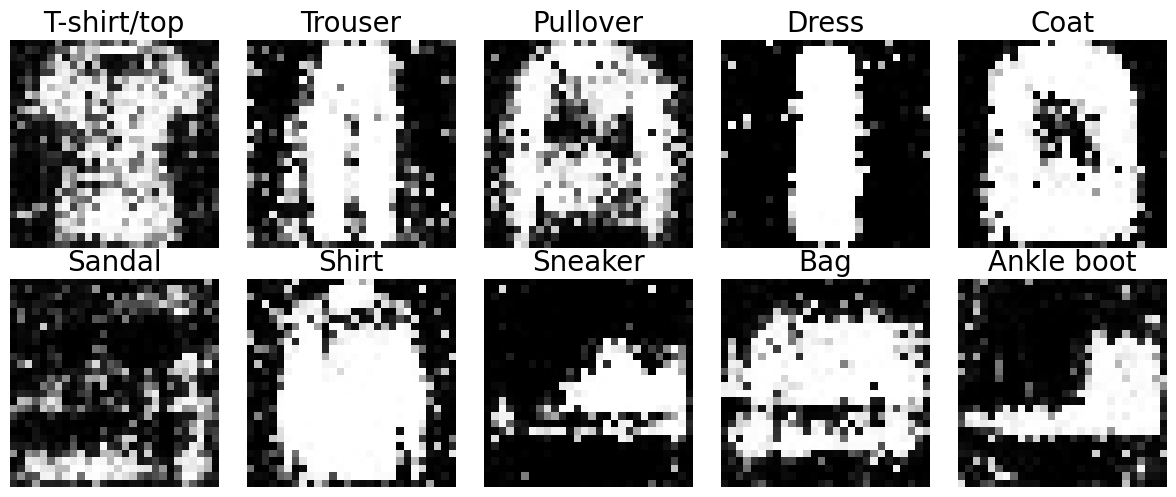
(2차 시도)
2차 시도에 생성한 이미지는 윤곽만 대충 잡히고 제대로 나오지 않았다.
G가 너무 약해서 조금 수정해줬더니, 오히려 너무 강해지는 일이 발생했다.
이번엔 D에 힘을 다시 실어주는 방향으로 시도해봐야겠다.
class Discriminator(nn.Module):
def __init__(self, embedding_dim, img_dim, num_classes):
super().__init__()
self.label_embed = nn.Embedding(num_classes, embedding_dim)
self.model = nn.Sequential(
nn.Linear(img_dim + embedding_dim, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(256, 1),
nn.Sigmoid()
)D 모델에 레이어를 하나 더 추가하고, 드롭은 0.5에서 0.3으로 줄였다.
G_optimizer = optim.Adam(G.parameters(), lr=0.0001, betas=(0.5, 0.999))
D_optimizer = optim.Adam(D.parameters(), lr=0.00002, betas=(0.5, 0.999))D의 옵티마이저 lr 계수도 5배 올렸다.
train(G, D, dataloader, noise_dim, num_classes, epochs=20)과연 성과가 있을까!?

흠,,, 뭔가 거뭇한 픽셀이 더 추가된 느낌이다.
만족스럽지가 않네 이거. 어디 시원하게 등을 긁어줄만 한 코드가 없을까...
8. 모델 개선(4차)
for epoch in range(epochs):
G.train()
D.train()
total_G_loss = 0
total_D_loss = 0
for real_imgs, labels in tqdm(dataloader):
batch_size = real_imgs.size(0)
real_imgs = real_imgs.view(batch_size, -1).to(device)
labels = labels.to(device)
real_labels = torch.full((batch_size, 1), 0.9, device=device)
fake_labels = torch.zeros(batch_size, 1, device=device)
label smoothing 이라는 방법을 찾았다. real_label을 1 대신 0.9로 반환하여 너무 확고한 판별을 하도록 하지 않기 위함이다.
self.model = nn.Sequential(
nn.BatchNorm1d(128 * 7 * 7),
nn.ReLU(True),
nn.Unflatten(1, (128, 7, 7)),
nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.ConvTranspose2d(64, 1, 4, stride=2, padding=1),
nn.Tanh()
)G의 모델 구조를 Linear 기반에서 ConvT2d 기반으로 변경했다.
self.features = nn.Sequential(
nn.Conv2d(1, 64, 4, 2, 1), # (B, 64, 14, 14)
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 128, 4, 2, 1), # (B, 128, 7, 7)
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True)
)D의 구조도 Conv2d 기반으로 변경했다.
train(G, D, dataloader, noise_dim, num_classes, epochs=20)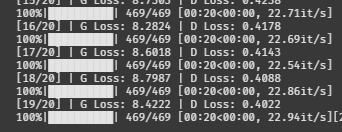
D 로스는 0.4~0.5 왔다갔다하고, G 로스는 서서히 올라간다.
show_cgan_samples(G, noise_dim, num_classes, device, class_names=class_names)시각화 해보자!

???????????
음,,,, 이건 잘했다고 해야하나 못했다고 해야하나
윤곽은 꽤 잘잡은 것 같은데, 속이 전부 흰색으로 나온다
뭐가 문제인 거니 도대체 ㅠㅠ..
9. 모델 개선(5차)
GELU라는 활성화 함수를 이용해 보기로 했다.
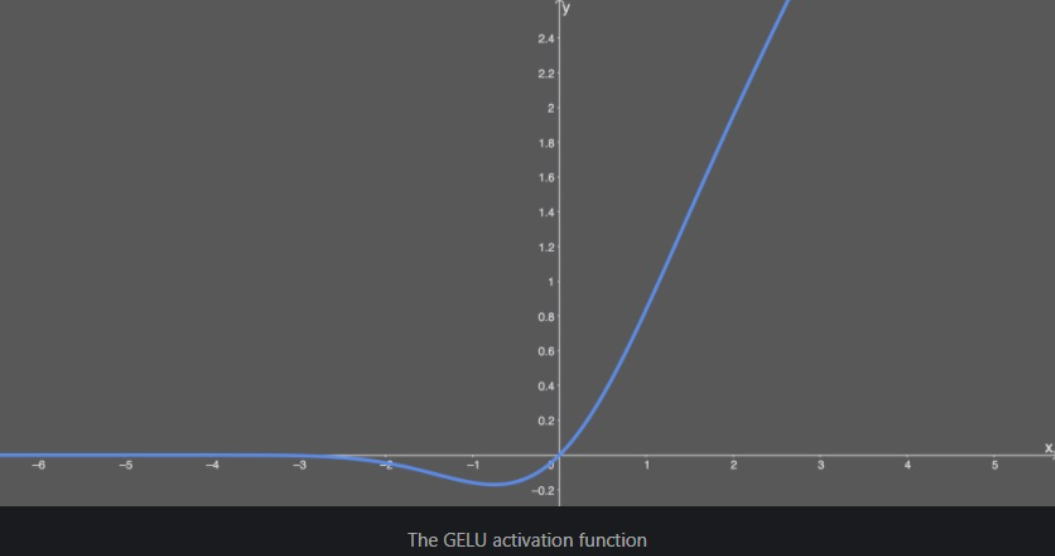
LeakyRelu보다 안정적이라고 한다. 그래프는 위 이미지처럼 생겼다.
음수를 고정폭으로 쭉 내보내는 게 아니라, 0에 가까운 일부만 살려주고 나머지는 버린다.
자연어 쪽에서 많이 사용하는 활성화 함수라고 한다.
self.model = nn.Sequential(
nn.BatchNorm1d(128 * 7 * 7),
nn.GELU(),
nn.Unflatten(1, (128, 7, 7)),
nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.GELU(),
nn.Dropout(0.2),
nn.ConvTranspose2d(64, 1, 4, stride=2, padding=1),
nn.Tanh() # [-1, 1]
)
G 모델 내부에 넣었다. 수학을 1도 몰라도 GELU() 하나만 넣으면 끝이니 얼마나 감사한지 모르겠다.
def __init__(self, num_classes, embedding_dim=100):
super().__init__()
self.label_embed = nn.Embedding(num_classes, embedding_dim)
self.features = nn.Sequential(
nn.Conv2d(1, 64, 4, 2, 1),
nn.GELU(),
nn.Conv2d(64, 128, 4, 2, 1),
nn.BatchNorm2d(128),
nn.GELU()
)D 모델 내부에도 GELU로 변경했다.
noise_dim = 256노이즈 디멘션을 조금 더 올려봤다.
train(G, D, dataloader, noise_dim, num_classes, epochs=20)다시 20에폭 도전
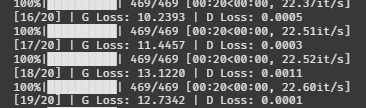
이런
굳이 안 봐도 망했구나를 알 수 있는 로스가 나왔다.
10. 모델 개선(6차)
뭔가 처음부터 단단히 꼬인 것 같다.
코드를 전부 지우고 처음부터 차근차근 다시 해봐야겠다.
transform = v2.Compose([
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize((0.5,), (0.5,))
])
train_data = torchvision.datasets.FashionMNIST(
root=data_dir,
train=True,
transform=transform,
download=True
)
train_loader = DataLoader(train_data, batch_size=128, shuffle=True)데이터부터 다시 다운받았다.
내가 정규화를 잘못했을 수도 있으니까 이번엔 정규화 수치를 0.5로 그냥 두고 해봐야겠다.
noise_dim = 100
embedding_dim = 10
num_classes = 10
image_size = 28 * 28모델 설정값도 다시 만들었다.
다 동일한데, embedding_dim만 100에서 10으로 변경했다.
임베딩 차원을 클래스 수와 맞추는 게 좋은지 테스트 해보려고 한다.
class Generator(nn.Module):
def __init__(self, noise_dim, embedding_dim, image_size, num_classes):
super().__init__()
self.class_embedding = nn.Embedding(num_classes, embedding_dim)
self.model = nn.Sequential(
nn.Linear(noise_dim + embedding_dim, 256),
nn.ReLU(inplace=True),
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Linear(512, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(inplace=True),
nn.Linear(1024, image_size),
nn.Tanh()
)
def forward(self, z, labels):
label_embed = self.class_embedding(labels)
x = torch.cat([z, label_embed], dim=1)
return self.model(x)G 모델도 다시 만들었다.
진짜 아주 단순하게 필요한 것만 넣었다.
class Discriminator(nn.Module):
def __init__(self, embedding_dim, image_size, num_classes):
super().__init__()
self.label_embedding = nn.Embedding(num_classes, embedding_dim)
self.model = nn.Sequential(
nn.Linear(image_size + embedding_dim, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(512, 1),
nn.Sigmoid()
)
def forward(self, img, labels):
label_embed = self.label_embedding(labels)
x = torch.cat([img, label_embed], dim=1)
return self.model(x)D 모델도 다시 만들었따.
첫 번째 시도했던 것 그대로다.
def train(G, D, dataloader, noise_dim, num_classes, epochs):
criterion = nn.BCELoss()
G_opt = optim.Adam(G.parameters(), lr=0.0002, betas=(0.5, 0.999))
D_opt = optim.Adam(D.parameters(), lr=0.0002, betas=(0.5, 0.999))
G.train()
D.train()학습 루프도 다시 만들었다.
옵티마이저에 lr은 두 모델 다 똑같이 줬다.
나머지 학습 루프 코드는 첫 번째 시도와 똑같다.
train(G, D, train_loader, noise_dim, num_classes, epochs=20)20에폭 돌려보자.
만약 잘 된다면 그이유는,
정규화를 0.5로 한 것과 디멘션을 10으로 맞춰준 게 효과를 본 것이다.
과연!?

오?? 지금까지 나온 결과물 중에 가장 그럴듯한 결과물이 나왔다.
show_multiple_samples(G, noise_dim=noise_dim, num_classes=num_classes, device=device, n_per_class=5, class_names=class_names)클래스별로 5개씩 뽑아보자.

신발을 은근 잘 만드는 것 같다.
어째서인지 처음부터 다시 하니까 성능이 좋아졌다.
아마도 정규화와 디멘션이 뭔가 영향을 준 것 같은데,,,
둘 중에 뭐가 영향을 줬는지 확인해 보자.
11. 모델 개선(7차)
noise_dim = 100
embedding_dim = 200
num_classes = 10
image_size = 28 * 28임베딩 차원을 10에서 원래대로 200으로 변경했다.
과연 임베딩 차원을 클래스 수와 맞춘 게 성능이 좋아진 이유일까??
train(G, D, train_loader, noise_dim, num_classes, epochs=20)20에폭 돌려보자.
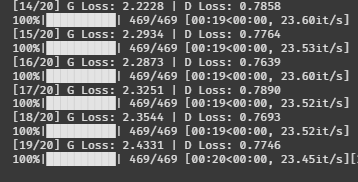
G 로스 2.43 / D 로스 0.77
살짝 불길한 느낌이 든다.
show_generated_samples(G, noise_dim, num_classes, device, class_names)시각화 해보자.

임베딩이 10차원일 때보다 이상하게 나왔다.
여러개 확인해 보자.

생성 이미지가 이상할뿐만 아니라 다양한 종류를 생성하지도 못한다.
이렇게 되면 근본적인 원인이 임베딩 차원에 있다는 뜻이 된다.
12. 모델 개선(8차)
이번엔 다시 임베딩 차원을 10으로 낮추고, 내가 구했던 정규화 수치를 넣어보자.
transform = v2.Compose([
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize((0.286041,), (0.353024,))
])
train_data = torchvision.datasets.FashionMNIST(
root=data_dir,
train=True,
transform=transform,
download=False
)
평균과 표준편차를 (0.286041,), (0.353024,)로 변경했다.
noise_dim = 100
embedding_dim = 10
num_classes = 10
image_size = 28 * 28임베딩 차원도 다시 10으로 줄였다.
train(G, D, train_loader, noise_dim, num_classes, epochs=20)20에폭 시작!!
제발 정규화 전보다 성능이 좋았으면 좋겠다.
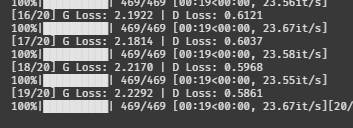
음,, 로스가 그렇게 좋아보이진 않는다.
show_generated_samples(G, noise_dim, num_classes, device, class_names)시각화!!

역시 문제가 있네.
show_multiple_samples(G, noise_dim=noise_dim, num_classes=num_classes, device=device, n_per_class=5, class_names=class_names)여러 개도 뽑아보자.

그래도 임베딩 200차원일 때보다 다양하게 생성하긴 한다.
왜 정규화를 하니까 성능이 안 좋아지는 걸까?
13. 모델 개선(9차)
지금까지 확인해본 결과, 정규화는 0.5일 때가 성능이 더 좋았다.
임베딩 차원은 클래스 수와 같을 때 성능이 더 좋았다.
뭐가 문제일까...
지선생에게 물어보자.

그렇다고 한다.
0.5로 정규화해야 출력값이 하볼탄 범위인 -1 ~ 1로 맵핑이 되는 것이었다.
아하! 하볼탄을 처음 써봐서 몰랐는데 이제 알았다.
만약 이게 사실이라면, 정규화를 아예 빼버렸을 때 성능이 안 좋게 나와야 한다.
당장 테스트 해보자.
transform = v2.Compose([
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True)
])정규화는 빼주고,
train(G, D, train_loader, noise_dim, num_classes, epochs=20)20에폭 돌려돌려~
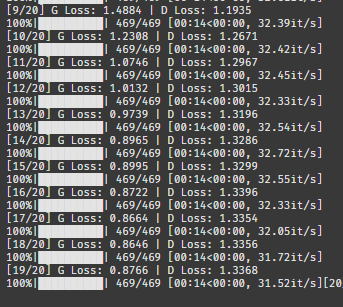
G 로스가 1.4에서 0.8로 갑자기 추락했다.
이건 안봐도 비디오네.

예상했던대로 성능이 좋지 않다.

다양하게 생성하긴 하는데, 그래도 성능이 좋지 않다.
결국 원인은 정규화와 임베딩 차원 둘 다에게 있었던 것이다.
14. 모델 개선(10차)
원인을 알았으니 마지막으로 한번만 더 해보자.
transform = v2.Compose([
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize((0.5,), (0.5,)),
])하볼탄을 위해 정규화는 0.5로 했다.
noise_dim = 100
embedding_dim = 10
num_classes = 10
image_size = 28 * 28임베인 차원을 클래스와 맞췄다.
class Generator(nn.Module):
def __init__(self, noise_dim, embedding_dim, image_size, num_classes):
super().__init__()
self.class_embedding = nn.Embedding(num_classes, embedding_dim)
self.model = nn.Sequential(
nn.Linear(noise_dim + embedding_dim, 64),
nn.ReLU(inplace=True),
nn.Linear(64, 128),
nn.BatchNorm1d(128),
nn.ReLU(inplace=True),
nn.Linear(128, 256),
nn.BatchNorm1d(256),
nn.ReLU(inplace=True),
nn.Linear(256, image_size),
nn.Tanh()
)G 모델 레이어 입출력을 조금 낮췄다.
생각해 보니 픽셀이 28인데 굳이 1024까지 늘릴 필요가 없었던 것 같다.
class Discriminator(nn.Module):
def __init__(self, embedding_dim, image_size, num_classes):
super().__init__()
self.label_embedding = nn.Embedding(num_classes, embedding_dim)
self.model = nn.Sequential(
nn.Linear(image_size + embedding_dim, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(256, 128),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(128, 1),
nn.Sigmoid()
)D 모델 레이어도 마찬가지로 입출력 값을 낮췄다.
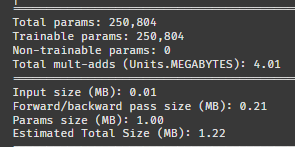
두 모델 다 파라미터가 150만에서 25만으로 줄었다.
train(G, D, train_loader, noise_dim, num_classes, epochs=20)20에폭 돌려보자
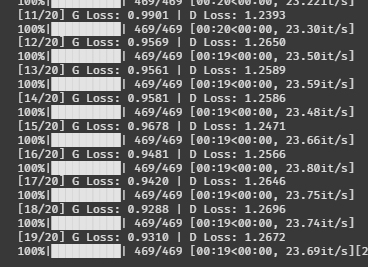
G가 살짝 힘이 딸린 것 같긴 한데, 그래도 무난해 보인다.

흠 이정도면 지금까지 한 것 중에선 젤 괜찮은 것 같다.
이걸 하려고 10번이나 시도를 했네...
만족스럽진 않지만, 그래도 파라미터 수도 줄고 성능도 확보했으니 다행이다.
아쉽다. 딱 일주일만 더 있었으면 디퓨전 모델도 해보는 건데,,,
생성 테스크가 진짜 헷갈리고 어렵다. 많이 공부해야겠다.
다음은 프로젝트인가...
