어제는 이해가 하나도 안 됐는데, 하루 종일 실습하면서 코드를 들여다 보니까 감이 잡힌다. 그새 또 실력이 조금 늘은 것 같다. 텍스트 데이터를 학습하는 건 머신러닝과 굉장히 흡사하다. 챗봇 만드는 게 이렇게 간단한 거였다니... 조금 놀랐다. 갑자기 자연어가 엄청 재밌어졌다.
학습시간 09:00~02:00(당일17H/누적1113H)
◆ 학습내용
1. TF-IDF(이진 분류)
positive_reviews = [
"이 영화는 정말 훌륭하고 재미있었습니다",
"완벽한 연기와 스토리가 인상적이었어요",
"최고의 영화 중 하나입니다 강력 추천",
"감동적이고 아름다운 영화였습니다",
"배우들의 연기가 정말 좋았어요"
]
negative_reviews = [
"이 영화는 너무 지루하고 재미없었습니다",
"스토리가 예측 가능하고 실망스러웠어요",
"돈이 아까운 영화였습니다",
"연기도 별로고 내용도 흥미롭지 않았어요",
"시간 낭비였던 영화입니다"
]영화 리뷰를 긍정 혹은 부정으로 분류하기!
reviews = positive_reviews + negative_reviews
labels = [1] * len(positive_reviews) + [0] * len(negative_reviews)리뷰를 더해서 1과 0으로 라벨링 해준다.
X_train, X_test, y_train, y_test = train_test_split(reviews, labels, test_size=0.3, random_state=42)
vectorizer = TfidfVectorizer()머신러닝 하는 것처럼 데이터를 스플릿한다. test셋과 랜덤 넣어주는 것도 센스있게!
X_train_tfidf = vectorizer.fit_transform(X_train)
X_test_tfidf = vectorizer.transform(X_test)머신러닝에서 정규화 하는 것처럼 벡터화 해준다. test셋은 fit_transform 이 아니라 transform 으로 하는 것 명심하기!!
model = LogisticRegression()
model.fit(X_train_tfidf, y_train)로지스틱 모델로 학습시킨다.
근데 이게 딥러닝이 맞나? 뭔가 머신러닝과 순서가 똑같다.
y_pred = model.predict(X_test_tfidf)
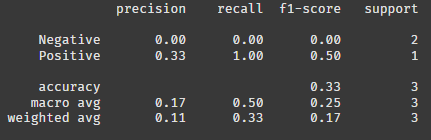
report = classification_report(y_test, y_pred, target_names=['Negative', 'Positive'])
print(report)평가를 위해 지표를 호출한다.
new_reviews = [
"정말 재미있었다",
"예측 가능하고 실망스러웠어요",
"아쉬운 영화였다",
"돈이 아까운 영화였다"
]
new_reviews_tfidf = vectorizer.transform(new_reviews)
new_predictions = model.predict(new_reviews_tfidf)최종 검증을 위해 새로운 텍스트 데이터를 넣어본다.
벡터화랑 예측까지 이어서 해준다.
print("새로운 리뷰 예측 결과:")
for i, review in enumerate(new_reviews):
sentiment = "Positive" if new_predictions[i] == 1 else "Negative"
print(f"- '{review}' -> {sentiment}\n")어떻게 예측했는지 확인해 본다. 데이터가 몇 개 없으니 그냥 개별 확인.

아쉬운 게 긍정이라고 한다. 학습 데이터가 적어서 성능이 안 좋은 것 같다.
2. Word2Vec(유사도 확인)
!pip install gensim
import gensim.downloader as api
dataset = api.load('text8')
data = [d for d in dataset]
print(len(data))gensim에서 제공하는 text8 데이터를 불러와서 리스트에 담아준다.
출력해 보니 1701개의 데이터가 있다고 한다.
from gensim.models import Word2Vec
num_data_to_use = int(len(data) * 0.3)
partial_data = data[:num_data_to_use]
len(partial_data)gensim에서 Word2Vec 모델을 호출한다. 데이터가 너무 많으니까 30%만 사용!
출력해 보니 510개의 데이터가 있다고 한다.
model = Word2Vec(
sentences=partial_data,
vector_size=100, # 임베딩 벡터 차원
window=5, # 컨텍스트 윈도우 크기
min_count=5, # 5회 이하 등장하는 단어 무시
workers=4,
sg=1 # 0은 CBOW, 1은 Skip-gram
)
model.train(partial_data, total_examples=model.corpus_count, epochs=10)
model.save("text8_30_percent.model")model 변수에 하이퍼 파라미터 값을 넣고 10에폭 학습시킨다.
# 'man'과 'woman'의 유사도 확인하기
print(model.wv.similarity('man', 'woman'))
# 'king'과 'queen'의 유사도 확인하기
print(model.wv.similarity('king', 'queen'))
# 'king - man + woman' 연산 결과와 가장 유사한 단어 찾기
print(model.wv.most_similar(positive=['king', 'woman'], negative=['man']))결과: ('consort', 0.6171676516532898), ('uzziah', 0.6060155034065247), ('sancho', 0.5950433611869812),,,,,,,
이런 식으로 단어 별 유사도를 확인할 수 있다.
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
import numpy as np
# 상위 100개 단어 시각화
vocab = list(model.wv.index_to_key)[:100]
word_vectors = np.array([model.wv[word] for word in vocab])
# t-SNE를 사용해서 2차원으로 차원 축소
tsne = TSNE(n_components=2, random_state=42)
vectors_2d = tsne.fit_transform(word_vectors)
# 시각화
plt.figure(figsize=(12, 12))
for i, word in enumerate(vocab):
plt.scatter(vectors_2d[i, 0], vectors_2d[i, 1])
plt.annotate(word, xy=(vectors_2d[i, 0], vectors_2d[i, 1]), xytext=(5, 2),
textcoords='offset points', ha='right', va='bottom')
plt.title('Word Embeddings Visualization with t-SNE') # 그래프 제목
plt.xlabel('Dimension 1') # x축 이름
plt.ylabel('Dimension 2') # y축 이름
plt.show()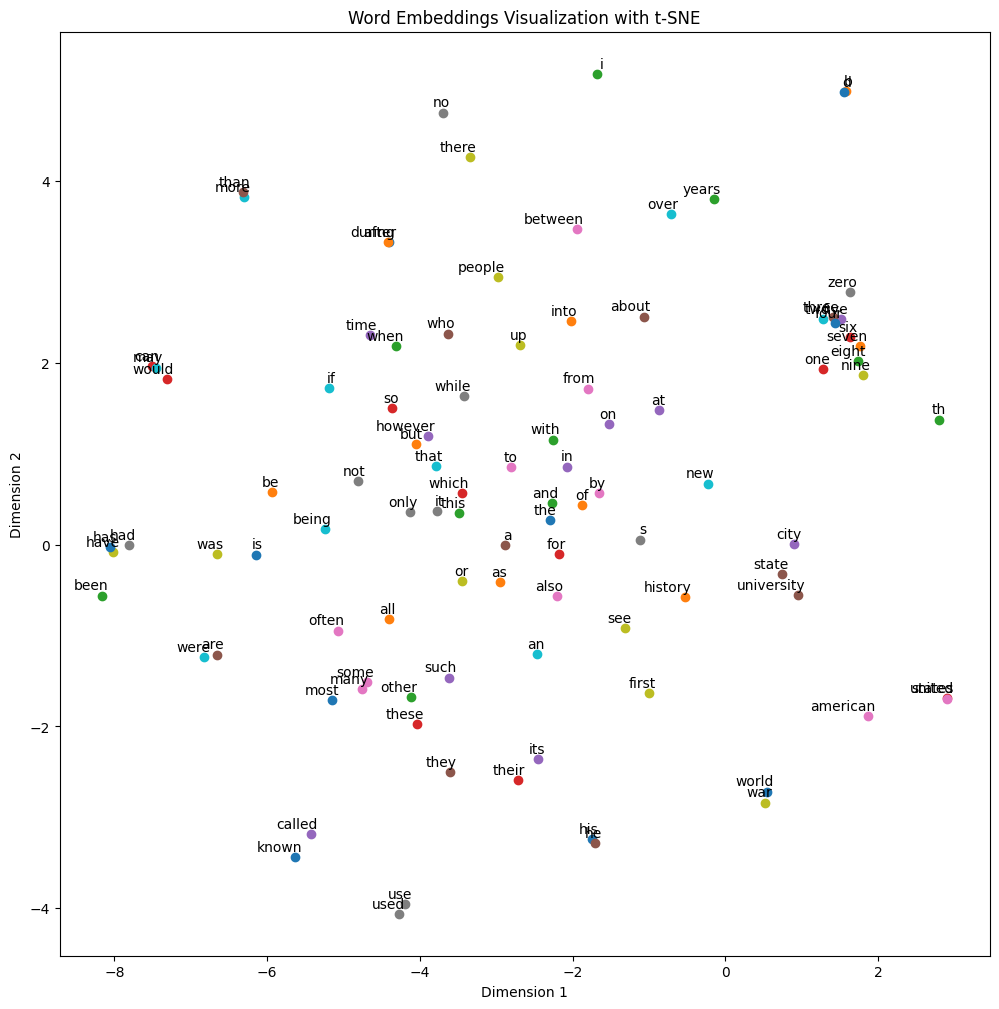
단어들이 어느 벡터공간에 매핑되어 있는지 확인할 수 있다.
3. Word2Vec(심화)
!pip install numpy==1.26.4 scipy==1.11.4 gensim==4.3.2 kiwipiepy
import pandas as pd
from kiwipiepy import Kiwi
from gensim.models import Word2Vec필요한 라이브러리를 불러온다. 토큰화, 불용어 처리를 위해 kiwi까지 불러온다.
★gensim, scipy 서로 버전 충돌이 생겨서 의존성 지옥에 빠질 수 있다. 꼭 버전을 잘 확인해 줘야 한다.
!wget -q https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt
train_data = pd.read_table('ratings_train.txt')
train_data = train_data.drop_duplicates(subset=['document'])
train_data = train_data.dropna(how='any')
train_data['document'] = train_data['document'].str.replace("([^ㄱ-ㅎㅏ-ㅣ가-힣 ])", "", regex=True)예제 txt파일을 다운한다.
테이블 형태로 데이터를 로드한다.
document 컬럼 기준으로 중복 데이터를 다 지운다.
how='any'로 결측값이 존재하는 행을 전부 삭제한다.
정규표현식으로 한글과 띄어쓰기 제외한 모든 것을 삭제한다.
kiwi = Kiwi()
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
def tokenize(text):
tokens = kiwi.tokenize(text)
return [token.form for token in tokens if token.form not in stopwords and token.tag in ['NNG', 'NNP', 'VV', 'VA', 'MAG', 'XR']]
train_data['tokenized'] = train_data['document'].apply(tokenize)
train_data = train_data[train_data['tokenized'].map(len) > 0]kiwi 형태소 분석기를 사용해 토큰화 한다. 불용어는 따로 지정했다.
토큰화 함수를 만든다.
불용어가 없으면서도 동시에 명사, 동사, 형용사, 부사, 어근인 것만 골라서 train_data['tokenized'] 컬럼에 저장한다.
단어가 0개 이상인 것만 다시 데이터에 저장한다.
model = Word2Vec(sentences=train_data['tokenized'], vector_size=100, window=5, min_count=5, workers=4, sg=1)전처리 끝난 데이터를 모델에 학습시킨다. 이 코드엔 에폭 수가 없는데, 이렇게 해도 기본 5에폭 돌아간다고 한다.
try:
similar_words = model.wv.most_similar('영화')
print("\n'영화'와 유사한 단어들:", similar_words)
except KeyError:
print("\n'영화'라는 단어가 학습 데이터에 충분히 없어 유사도를 계산할 수 없습니다.")'영화'라는 단어와 유사한 단어를 뽑는다.
'영화'와 유사한 단어들: [('꺼리', 0.7633889317512512), ('공포물', 0.7542524933815002), ('에니메이션', 0.7473456859588623), ('과제', 0.7360882759094238), ('마니아', 0.7208049297332764), ('애니매이션', 0.7207610607147217), ('여튼', 0.717522144317627), ('인셉션', 0.7159642577171326), ('파라노말 액티비티', 0.7133312225341797), ('간만', 0.7119172811508179)]이런 느낌으로 결과가 나온다.
4. Transformer (군집화 & 챗봇)
from sentence_transformers import SentenceTransformer, util
import numpy as np
from sklearn.cluster import KMeans필요한 라이브러리를 불러온다.
documents = [
"정부, 부동산 규제 완화 정책 발표", "여야, 예산안 협상 난항",
"한국은행, 기준 금리 동결 결정", "코스피, 외인 매도세에 하락 마감",
"손흥민, 환상적인 드리블 후 시즌 10호골 기록", "이강인, 선발 출전하여 팀 승리 이끌어",
"새로운 AI 모델, 인간 수준의 언어 능력 보여줘", "오픈AI, 차세대 대규모 언어 모델 공개"
]처리할 텍스트 데이터다. 비슷한 텍스트끼리 비지도학습으로 군집화하는 것이 목표다.
model = SentenceTransformer('jhgan/ko-sroberta-multitask')
e, k = model.encode(documents), KMeans(n_clusters=4)
clusters = k.fit_predict(e)트랜스포머는 영어 기반 모델이다. 따라서, 'jhgan/ko-sroberta-multitask' 를 사용해 한국어를 학습한 모델을 불러온다.
encode() 함수를 사용해 임베딩하고, KMeans() 함수를 사용해 군집화할 그룹 수 를 지정한다.
fit_predict()로 군집화를 실행한다.
for i, doc in enumerate(documents):
print(f"[{clusters[i]}] {doc}")텍스트 데이터를 돌면서 그룹 번호를 부여한다.

오 확실히 사전학습된 모델을 사용하니까 성능이 좋다.
이 모델로 챗봇을 만들어 보자.
faq_data = [
["배송은 보통 얼마나 걸리나요?", "주문일로부터 평균 2~3일(주말/공휴일 제외) 소요됩니다."],
["반품이나 교환은 어떻게 하나요?", "상품 수령 후 7일 이내에 고객센터로 문의하시면 절차를 안내해 드립니다."],
["회원가입은 꼭 해야 하나요?", "비회원으로도 상품 구매가 가능하지만, 회원가입 시 더 많은 혜택을 받으실 수 있습니다."],
["주문 취소는 어떻게 하죠?", "'마이페이지 > 주문내역'에서 직접 취소하시거나 고객센터로 연락 주세요."],
["상품 배송지를 변경하고 싶어요", "이미 상품이 발송된 경우 변경이 어려우니, 즉시 고객센터로 문의 바랍니다."],
...
(중략)
...
]챗봇이 사용할 텍스트 리스트를 정의해 준다. 0번은 질문이고 1번은 답변이다.
def QnA(model, query):
q = [i[0] for i in faq_data]
a = [i[1] for i in faq_data]
e = model.encode(q)함수를 만든다. model과 query를 인자로 받는다.
q에는 질문은 0번을, a에는 답변인 1번을 저장 후 encode() 함수로 벡터화한다.
query_embed = model.encode(query)
query_search = util.semantic_search(query_embed, e, top_k=1)
query_match = query_search[0][0]['corpus_id']
return a[query_match]이번엔 새로 들어오는 질문을 벡터 공간으로 넘겨줘야 한다.
인자로 받은 query(사용자의 질문)를 벡터화 한다.
아까 질문 리스트를 넣어둔 벡터공간에서 사용자 질문과 가장 가까운 거리의 답변을 찾는다.
query_search[0][0] 하는 이유: semantic_search의 결과는 리스트 안에 리스트가 중첩된 형태라, 첫 번째 [0]으로 밖의 리스트를 벗겨내야 한다. 그 후, 두 번째 [0]으로 가장 유사한 질문 정보(딕셔너리 형태)를 가져온다.
while True:
query = input("Q. ")
if query.lower() in ['종료', 'q']:
print("***** 챗봇 종료 *****")
break
print("A.", QnA(model, query))간단한 챗봇 트리거를 만든다.
코드를 실행하면 바로 input() 함수가 실행된다.
질문을 입력하면 자동으로 답변을 찾아서 결과를 출력한다.

아주 잘 작동한다!!
