하,,, 어제까지 살짝 할만한 것 같았는데 다시 길을 잃어버렸다. 내가 볼 때 이건 몸으로 부딪히면서 배우는 수밖에 없을 것 같다.
학습시간 09:00~02:00(당일17H/누적1130H)
◆ 학습내용
1. 임베딩(심화)
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
sentences = [
("i love this movie", "positive"),
("this film is great", "positive"),
("what a wonderful film", "positive"),
("i hated this movie", "negative"),
("this is a boring and terrible film", "negative"),
("the worst movie i have ever seen", "negative")
]
임베딩이 작동하는 원리를 익히기 위해 직접 구현하는 연습이다. 일단 이진 분류를 위한 텍스트를 준비했다.
texts = [s[0] for s in sentences]
labels = [1 if s[1] == 'positive' else 0 for s in sentences]
tokenized_texts = [text.split() for text in texts]
word_set = set(word for text in tokenized_texts for word in text)텍스트와 라벨을 맵핑하고 토큰화 한다.
word_to_index = {"<PAD>": 0, "<UNK>": 1}
for word in word_set:
if word not in word_to_index:
word_to_index[word] = len(word_to_index)
indexed_texts = [[word_to_index.get(word, word_to_index['<UNK>']) for word in text] for text in tokenized_texts]이미지에 패딩을 둘렀던 것처럼 텍스트도 패딩을 입혀야 한다.
그것을 위한 사전 작업이다.
max_len = max(len(text) for text in indexed_texts)
padded_texts = np.zeros((len(indexed_texts), max_len), dtype=np.int64)
for i, text in enumerate(indexed_texts):
padded_texts[i, :len(text)] = text최대 길이를 재고 빈 공간만큼 패딩을 입힌다.
inputs = torch.tensor(padded_texts)
targets = torch.tensor(labels, dtype=torch.float32).view(-1, 1)
dataset = TensorDataset(inputs, targets)
dataloader = DataLoader(dataset, batch_size=2)데이터셋 준비.
class SentimentClassifier(nn.Module):
def __init__(self, vocab_size, emb_dim, out_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, emb_dim, padding_idx = 0)
self.fc = nn.Linear(emb_dim, out_dim)
# self.sigmoid = nn.Sigmoid()
def forward(self, text):
# 임베딩 레이어 통과 (쉐입: 배치, 스퀀스 길이)
embedded = self.embedding(text)
# 임베딩 통과한 텍스트를 넣어줌 (쉐입: 배치, 스퀀스 길이, 임베딩 차원)
pooled = torch.mean(embedded, dim=1)
# (쉐입: 배치, 임베딩 차원)
output = self.fc(pooled)
# (쉐입: 배치, 아웃풋 차원)
return output
EMBEDING_DIM = 10 # 단어를 10차원 벡터로 표현
OUTPUT_DIM = 1 # 이진 분류이므로 출력 차원은 1
model = SentimentClassifier(len(word_to_index), EMBEDING_DIM, OUTPUT_DIM)임베딩 공간 구현을 위한 클래스를 만든다.
개념 자체는 오토인코더랑 큰 차이 없어보인다.
criterion = nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
epochs = 500
for epoch in range(epochs):
epoch_loss = 0
for text_batch, labels_batch in dataloader:
optimizer.zero_grad()
predictions = model(text_batch).squeeze(1)
loss = criterion(predictions, labels_batch.squeeze(1))
loss.backward()
optimizer.step()
epoch_loss += loss.item()
if (epoch+1) % 100 == 0:
print(f"Epoch {epoch+1}/{epochs}, Loss: {epoch_loss/len(dataloader)}")구현한 임베딩 클래스로 벡터화하고 학습을 돌린다.
학습 코드도 일반적인 딥러닝 모델 학습과 별 차이 없다.
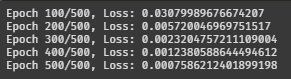
로스가 쭉쭉 내려간다.
def predict_sentiment(text):
tokenized = text.lower().split()
indexed = [word_to_index.get(word, word_to_index["<UNK>"]) for word in tokenized] # [ 9, 15, 7, 2]
if len(indexed) < 7:
indexed += [word_to_index["<PAD>"]] * (max_len - len(indexed)) # [ 9, 15, 7, 2, 0, 0, 0]
input_tensor = torch.LongTensor(indexed).unsqueeze(0)
prediction = model(input_tensor)
prediction = torch.sigmoid(prediction)
if prediction.item() > 0.5:
output = "긍정"
else:
output = "부정"
return output
predict_sentiment("this film is great")학습한 모델로 예측을 할 함수다.
텍스트가 들어오면 대소문자를 맞추고 토큰화를 거쳐 패딩을 입혀 모델에 넣는다.
시그모이드로 감싸서 0.5 이상(50%) 이면 긍정으로, 아니면 부정으로 본다.
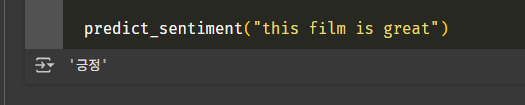
긍! 정!
2. Seq2Seq
Seq2Seq 모델로 영/프 번역 진행
이해하지 못했기에 코드만 저장
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import random
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import seaborn as sns
import math
import time
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
SOS_token = 0
EOS_token = 1
MAX_LENGTH = 10
class Lang:
def __init__(self, name):
self.name = name
self.word2index = {}
self.index2word = {0: "SOS", 1: "EOS"} # <UNK>, <PAD> 없음
self.n_words = 2 # SOS, EOS만 포함해서 2개부터 시작
def add_sentence(self, sentence):
for word in sentence.split(' '): # 띄어쓰기 기준으로 나눔
if word not in self.word2index:
self.word2index[word] = self.n_words
self.index2word[self.n_words] = word
self.n_words += 1
raw_data = [
("i am a student .", "je suis un etudiant ."),
("he is a boy .", "il est un garcon ."),
("she is a girl .", "elle est une fille ."),
("we are students .", "nous sommes des etudiants ."),
("they are boys .", "ils sont des garcons ."),
("i love this cat .", "j adore ce chat .")
]
input_lang = Lang('eng')
output_lang = Lang('fra')
for pair in raw_data:
input_lang.add_sentence(pair[0])
output_lang.add_sentence(pair[1])
# 문장 => tokenize => encode => tensor
def tensor_from_sentence(lang, sentence):
indexes = [lang.word2index[word] for word in sentence.split(' ')]
indexes.append(EOS_token)
return torch.tensor(indexes, dtype=torch.long, device=device).view(-1,1)
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
def forward(self, input_):
embedded = self.embedding(input_)
output, hidden = self.gru(embedded)
return output, hidden
class DecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size):
super().__init__()
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
self.out = nn.Linear(hidden_size, output_size)
def forward(self, decoder_input, decoder_hidden):
embedded = self.embedding(decoder_input)
output, hidden = self.gru(embedded, decoder_hidden)
output = F.log_softmax(self.out(output.squeeze(1)), dim=1)
return output, hidden
def train_basic(input_tensor, target_tensor, encoder, decoder, optimizers, criterion):
encoder_optimizer, decoder_optimizer = optimizers
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
_, encoder_hidden = encoder(input_tensor)
decoder_input = torch.tensor([[SOS_token]], device=device)
decoder_hidden = encoder_hidden
loss = 0
target_length = target_tensor.size(1)
for di in range(target_length):
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
loss += criterion(decoder_output, target_tensor[:, di])
decoder_input = target_tensor[:, di].unsqueeze(1)
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
return loss.item() / target_length
def evaluate_basic(input_sentence, encoder, decoder):
with torch.no_grad():
input_tensor = tensor_from_sentence(input_lang, input_sentence).transpose(0, 1)
_, encoder_hidden = encoder(input_tensor)
decoder_input = torch.tensor([[SOS_token]], device=device)
decoder_hidden = encoder_hidden
decoded_words = []
for di in range(MAX_LENGTH):
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
topv, topi = decoder_output.data.topk(1)
if topi.item() == EOS_token:
decoded_words.append('<EOS>')
break
else:
decoded_words.append(output_lang.index2word[topi.item()])
decoder_input = topi.squeeze().detach().view(1, -1)
return decoded_words
hidden_size = 128
basic_encoder = EncoderRNN(input_lang.n_words, hidden_size).to(device)
basic_decoder = DecoderRNN(hidden_size, output_lang.n_words).to(device)
encoder_optimizer = optim.Adam(basic_encoder.parameters(), lr=0.001)
decoder_optimizer = optim.Adam(basic_decoder.parameters(), lr=0.001)
optimizers = (encoder_optimizer, decoder_optimizer)
criterion = nn.NLLLoss()
n_iters = 2000
for iteration in range(1, n_iters + 1):
pair = random.choice(raw_data)
input_tensor = tensor_from_sentence(input_lang, pair[0]).transpose(0, 1)
target_tensor = tensor_from_sentence(output_lang, pair[1]).transpose(0, 1)
loss = train_basic(input_tensor, target_tensor, basic_encoder, basic_decoder, optimizers, criterion)
if iteration % 400 == 0:
print(f"Iteration: {iteration} / {n_iters}, Loss : {loss}")
for pair in raw_data:
print(pair[0], pair[1])
output_words = evaluate_basic(pair[0], basic_encoder, basic_decoder)
output_sentence = ' '.join(output_words)
print(" >> ", output_sentence)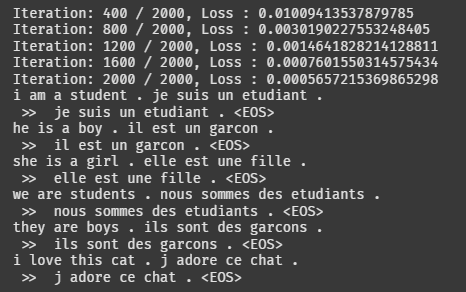
3. BahdanauAttention
어텐션의 초기 모델?? 바다나우 어텐션 구현.
이해하지 못했기에 코드만 저장 ㅠㅠ
''' BahdanauAttention '''
import torch
import torch.nn as nn
import torch.nn.functional as F
class BahdanauAttention(nn.Module):
def __init__(self, hidden_size):
super().__init__()
self.W = nn.Linear(hidden_size, hidden_size, bias=False)
self.U = nn.Linear(hidden_size, hidden_size, bias=False)
self.V = nn.Linear(hidden_size, 1, bias=False)
def forward(self, decoder_hidden, encoder_outputs):
s_proj = self.W(decoder_hidden.permute(1, 0, 2))
h_proj = self.U(encoder_outputs)
scores = self.V(torch.tanh(s_proj + h_proj))
attn_weights = F.softmax(scores, dim=1)
context = torch.bmm(attn_weights, encoder_outputs) # batch matrix multiplication
return context, attn_weights.squeeze(2)
class BahdanauAttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size):
super().__init__()
self.embedding = nn.Embedding(output_size, hidden_size)
self.attention = BahdanauAttention(hidden_size)
self.gru = nn.GRU(hidden_size*2, hidden_size, batch_first=True)
self.out = nn.Linear(hidden_size, output_size)
def forward(self, decoder_input, decoder_hidden, encoder_outputs):
embedded = self.embedding(decoder_input)
context, attn_weights = self.attention(decoder_hidden, encoder_outputs)
rnn_input = torch.cat((embedded, context), dim=2)
output, hidden = self.gru(rnn_input, decoder_hidden)
output = F.log_softmax(self.out(output.squeeze(1)), dim=1)
return output, hidden, attn_weights
def train_bahdanau(input_tensor, target_tensor, encoder, decoder, optimizers, criterion):
encoder_optimizer, decoder_optimizer = optimizers
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
encoder_outputs, encoder_hidden = encoder(input_tensor)
decoder_input = torch.tensor([[SOS_token]], device=device)
decoder_hidden = encoder_hidden
loss = 0
target_length = target_tensor.size(0)
for di in range(target_length):
decoder_output, decoder_hidden, _ = decoder(decoder_input, decoder_hidden, encoder_outputs)
loss += criterion(decoder_output, target_tensor[di])
decoder_input = target_tensor[di].unsqueeze(0)
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
return loss.item() / target_length
def evaluate_bahdanau(input_sentence, encoder, decoder):
with torch.no_grad():
input_tensor = tensor_from_sentence(input_lang, input_sentence).transpose(0, 1)
encoder_outputs, encoder_hidden = encoder(input_tensor)
decoder_input = torch.tensor([[SOS_token]], device=device)
decoder_hidden = encoder_hidden
decoded_words = []
decoder_attentions = []
for di in range(MAX_LENGTH):
decoder_output, decoder_hidden, attn_weights = decoder(decoder_input, decoder_hidden, encoder_outputs)
decoder_attentions.append(attn_weights.squeeze(0).cpu().numpy())
topv, topi = decoder_output.data.topk(1)
if topi.item() == EOS_token:
decoded_words.append('<EOS>')
break
else:
decoded_words.append(output_lang.index2word[topi.item()])
decoder_input = topi.squeeze().detach().view(1, -1)
return decoded_words, decoder_attentions
hidden_size = 128
bahdanau_encoder = EncoderRNN(input_lang.n_words, hidden_size).to(device)
bahdanau_decoder = BahdanauAttnDecoderRNN(hidden_size, output_lang.n_words).to(device)
encoder_optimizer = optim.Adam(bahdanau_encoder.parameters(), lr=0.001)
decoder_optimizer = optim.Adam(bahdanau_decoder.parameters(), lr=0.001)
optimizers = (encoder_optimizer, decoder_optimizer)
criterion = nn.NLLLoss()
n_iters = 2000
for iteration in range(1, n_iters + 1):
pair = random.choice(raw_data)
input_tensor = tensor_from_sentence(input_lang, pair[0]).transpose(0, 1)
target_tensor = tensor_from_sentence(output_lang, pair[1]).transpose(0, 1)
loss = train_bahdanau(input_tensor, target_tensor, bahdanau_encoder, bahdanau_decoder, optimizers, criterion)
if iteration % 400 == 0:
print(f"Iteration: {iteration} / {n_iters}, Loss : {loss}")
4. 연습
오늘 이해한 게 정말 하나도 없다.
이대로 자면 양심에 찔리기 때문에 자연어 처리 기초부터 연습을 했다.
(1) 전처리
# 데이터 로드
df = pd.read_csv('imdb.tsv', delimiter = "\\t")
# 대소문자 통합
df['review'] = df['review'].str.lower()
# 토큰화
df['sent_tokens'] = df['review'].apply(sent_tokenize)
# 품사 태깅
df['pos_tagged_tokens'] = df['sent_tokens'].apply(pos_tagger)
# 표제어 추출
df['lemmatized_tokens'] = df['pos_tagged_tokens'].apply(words_lemmatizer)
# 추가 전처리(빈도, 길이, 불용어 처리)
stopwords_set = set(stopwords.words('english'))
df['cleaned_tokens'] = df['lemmatized_tokens'].apply(lambda x: clean_by_freq(x, 1))
df['cleaned_tokens'] = df['cleaned_tokens'].apply(lambda x: clean_by_len(x, 2))
df['cleaned_tokens'] = df['cleaned_tokens'].apply(lambda x: clean_by_stopwords(x, stopwords_set))
# 1차 확인
df[['cleaned_tokens']]
# 전처리 끝난 토큰 통합
def combine(sentence):
return ' '.join(sentence)
df['combined_corpus'] = df['cleaned_tokens'].apply(combine)
# 2차 확인
df[['combined_corpus']]
(2) 감성지수 계산
def swn_polarity(pos_tagged_words):
senti_score = 0
for word, tag in pos_tagged_words:
# PennTreeBank 기준 품사를 WordNet 기준 품사로 변경
wn_tag = penn_to_wn(tag)
if wn_tag not in (wn.NOUN, wn.ADJ, wn.ADV, wn.VERB):
continue
# Synset 확인, 어휘 사전에 없을 경우에는 스킵
if not wn.synsets(word, wn_tag):
continue
else:
synsets = wn.synsets(word, wn_tag)
# SentiSynset 확인
synset = synsets[0]
swn_synset = swn.senti_synset(synset.name())
# 감성 지수 계산
word_senti_score = (swn_synset.pos_score() - swn_synset.neg_score())
senti_score += word_senti_score
return senti_score(3) 한국어 교정
pip install py-hanspell
from hanspell import spell_checker
text = "아버지가방에들어가신다나는오늘코딩을했다"
hanspell_sent = spell_checker.check(text)
print(hanspell_sent.checked)


AI Engineer