정신없이 자연어 첫 미션을 끝냈다.
학습시간 09:00~03:00(당일18H/누적1218H)
◆ 학습내용
어제 4~6번에 이어 7번부터 시작!
7. 모델 생성
3개 모델을 각각 구현해야 한다. 근데 뭔가 한방에 할 수 있는 방법이 없을까 생각하다가, 클래스에 다 넣어서 호출하면 좋을 것 같다는 아이디어가 떠올랐다.
class Classifier(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers, bidirectional, dropout, pad_idx, model_name=None):
super().__init__()
self.model_name = model_name.lower()
self.bidirectional = bidirectional
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)
self.dropout = nn.Dropout(dropout)3개 모델을 담기 위한 클래스를 만들었다. 하파로는 총 단어 개수, 임베딩 차원, 은닉 차원, 출력 차원, 레이어 수, 양방향 여부(모델에 따라 다름), 드롭아웃 비율, 패딩, 모델 종류 이렇게 넣었다.
if self.model_name == 'rnn':
self.rnn = nn.RNN(embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=bidirectional, dropout=dropout, batch_first=True)
elif self.model_name == 'lstm':
self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=bidirectional, dropout=dropout, batch_first=True)
elif self.model_name == 'gru':
self.rnn = nn.GRU(embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=bidirectional, dropout=dropout, batch_first=True)
self.fc = nn.Linear(hidden_dim * 2 if bidirectional else hidden_dim, output_dim)입력에 따라서 모델을 분기할 조건문이다.
마지막에 은닉층을 2배로 한다. 양방향 연산을 통해 효율을 높이기 위함이다.
def forward(self, text):
embedded = self.dropout(self.embedding(text))
output, hidden = self.rnn(embedded)
if self.model_name == 'lstm':
hidden = hidden[0]
if self.bidirectional:
hidden = self.dropout(torch.cat((hidden[-2], hidden[-1]), dim=1))
else:
hidden = self.dropout(hidden[-1])
return self.fc(hidden)순전파 함수를 만들어 준다.
간단하게 3개 모델 구현 끝!
8. 모델 학습
def train_model(model_name, emb_name, emb_matrix, train_loader, vocab_size, word_to_index, learning_rate, epochs):
pad_idx = word_to_index['<PAD>']크게 보면 일반적인 훈련 함수랑 별 차이가 없는데, 몇가지 설정해줘야 할 게 있다.
일단 함수형태로 호출해서 사용할 것이기 때문에 파라미터를 쭉 넣어준다.
# 모델 인스턴스 생성
model = Classifier(
vocab_size=vocab_size,
embedding_dim=100,
hidden_dim=128,
output_dim=len(set(labels)),
n_layers=2,
bidirectional=True,
dropout=0.5,
pad_idx=pad_idx,
model_name=model_name
).to(device)
# 사전 훈련된 임베딩 가중치 적용
model.embedding.weight.data.copy_(emb_matrix)
model.embedding.weight.data[pad_idx] = torch.zeros(100)
model.embedding.weight.requires_grad = False3개 모델 중 내가 지정한 모델을 받아줘야 하기 때문에 내부에 모델을 생성하는 코드를 넣는다.
드롭아웃 0.5로 학습이 잘 안 되면 수치를 조정해야할 것 같다.
그리고 어제 만든 3개 임베딩 모델에서 가중치를 가져와 적용시킨다.
# 옵티마이저와 손실함수 정의
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
criterion = nn.CrossEntropyLoss().to(device)이제 본격적인 학습 루프 도입부다.
print(f"--- Start training [{model_name}] with [{emb_name}] ---")
model.train()
for epoch in range(epochs):
total_loss = 0
total_correct = 0
total_epoch = 0어떤 모델끼리 묶여서 학습하는지 알 수 있도록 프린트문을 넣었다.
for text, label in tqdm(train_loader):
text, label = text.to(device), label.squeeze().to(device)
predictions = model(text)
loss = criterion(predictions, label)
_, predicted_labels = torch.max(predictions, 1)
total_correct += (predicted_labels == label).sum().item()
total_epoch += label.size(0)
optimizer.zero_grad()
loss.backward()
optimizer.step()이후 코드는 일반적인 학습 루프와 동일하다.
9. 모델 훈련
# 하이퍼파라미터
LEARNING_RATE = 0.001
EPOCHS = 20
# 훈련된 모델 저장
trained_models = {}9개 조합을 컨트롤하기 위해서 하파를 새로 만들었다.
에폭은 일단 20만 해볼까..? 20에폭만 해도 조합이 9개라 180에폭을 돌려야 한다.
""" Vanilla RNN """
trained_models['RNN_Word2Vec'] = train_model(
model_name='RNN',
emb_name='Word2Vec',
emb_matrix=word2vec_embedding_matrix,
train_loader=train_loader,
vocab_size=vocab_size,
word_to_index=word_to_index,
learning_rate=LEARNING_RATE,
epochs=EPOCHS
)지금까지 만들었던 시계열 모델, 임베딩 모델에서 뽑아낸 가중치, 단어 사전, 매핑된 인덱스를 쭉 넣어준다.
일단 이건 Vanilla RNN이랑 Word2Vec을 조합한 거고,
trained_models['RNN_FastText'] = train_model(
model_name='RNN',
emb_name='FastText',
emb_matrix=fasttext_embedding_matrix,
train_loader=train_loader,
vocab_size=vocab_size,
word_to_index=word_to_index,
learning_rate=LEARNING_RATE,
epochs=EPOCHS
)이건 Vanilla RNN이랑 FastText를 조합한 거다.
trained_models['GRU_GloVe'] = train_model(
model_name='GRU',
emb_name='GloVe',
emb_matrix=glove_embedding_matrix,
train_loader=train_loader,
vocab_size=vocab_size,
word_to_index=word_to_index,
learning_rate=LEARNING_RATE,
epochs=EPOCHS
)코드를 쭉 복붙해서 GRU + GloVe 조합까지 총 9개를 만들었다.

학습 시작!! 텍스트 데이터라 그런지 1에폭에 시간이 얼마 걸리지 않네









훈련셋 최종 에폭 기준
RNN_Word2Vec 로스 2.26, 정확도 25%
RNN_FastText 로스 2.16, 정확도 27%
RNN_GloVe 로스 2.62, 정확도 14%
LSTM_Word2Vec 로스 1.00, 정확도 68%
LSTM_FastText 로스 1.04, 정확도 67%
LSTM_GloVe 로스 1.17, 정확도 62%
GRU_Word2Vec 로스 0.90, 정확도 71%
GRU_FastText 로스 0.90, 정확도 71%
GRU_GloVe 로스 0.97, 정확도 68%
정확도 기준으로 수치만 보면
시계열 모델 중에서는 Vanilla RNN이 가장 안 좋다.
임베딩 모델 중에서는 GloVe가 가장 안 좋다.
흠.. GRU 모델 성능이 LSTM 모델보다 소폭 안 좋다고 들었는데 오히려 좋게 나온다. 이상하네.
일단 테스트셋으로도 평가를 해보자.
10. 모델 평가
def evaluate_model(model, test_loader):
print(f"--- Evaluating model ---")
# 모델을 평가 모드로 설정
model.eval()
...
학습 루프랑 비슷하게 쭉 만들어준다. 아래 내용은 생략
# sklearn.metrics를 사용해 성능 지표 계산
accuracy = accuracy_score(all_labels, all_preds)
precision = precision_score(all_labels, all_preds, average='weighted', zero_division=0)
recall = recall_score(all_labels, all_preds, average='weighted', zero_division=0)
f1 = f1_score(all_labels, all_preds, average='weighted', zero_division=0)
return accuracy, precision, recall, f1마지막엔 분류모델 지표를 불러와서 연산 후 평가한다.
results_list = []
for model_key, model in trained_models.items():
print(f"\n===== Evaluating [{model_key}] =====")
# 평가 함수 호출
accuracy, precision, recall, f1 = evaluate_model(model, test_loader)
# 결과 저장
model_name, emb_name = model_key.split('_')
results_list.append({
'Model': model_name,
'Embedding': emb_name,
'Accuracy': accuracy,
'Precision': precision,
'Recall': recall,
'F1-score': f1
})9개 조합에 대한 평가를 해야한다.
따라서 방금 만든 함수를 각각 딕셔너리 형태로 리스트에 저장해서 한방에 불러온다.
results_df = pd.DataFrame(results_list)
results_df = results_df.sort_values(by='Accuracy', ascending=False).reset_index(drop=True)
print("\n\n▶▶▶ 최종 모델 성능 평가표 ◀◀◀")
print(results_df)클래스 불균형이 있으면 F1-score로 정렬할 텐데, 균형이 잘 잡힌 듯해서 정확도 기준으로 1순위 부터 정렬한다.
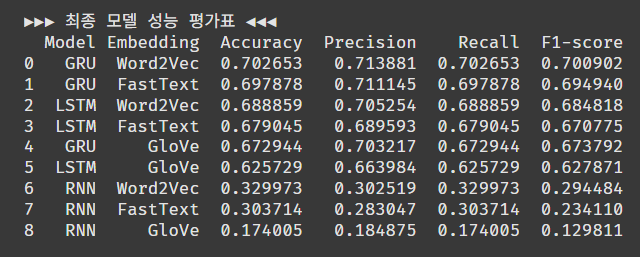
1위는 GRU+Word2Vec 조합이다.
정확도 70%면 만족스러운 성능은 아니네.
에폭이 부족했나? 하파 값이 잘못됐나?
조금 수정해서 모델을 개선해 보자.
11. 모델 개선
지금까지 진행하면서 몇 가지 눈에 걸렸던 하파값들이 있었다. 이것만 수정해도 결과가 유의미하게 변하지 않을까 유추해 본다.
""" 임베딩 모델 """
def set_embedding_models():
# Word2Vec 모델 정의
word2vec_model = Word2Vec(
sentences=processed_documents,
vector_size=200, # 100 -> 200
window=10, # 5 -> 10
min_count=5,
workers=4,
sg=1,
epochs=20 # 10 -> 20
)
# FastText 모델 정의
fasttext_model = FastText(
sentences=processed_documents,
vector_size=200,
window=10,
min_count=5,
workers=4,
sg=1,
epochs=20
)
# GloVe 모델 정의
download_url = 'http://nlp.stanford.edu/data/glove.6B.zip'
glove_dir = 'news-topic-classifier/glove'
zip_path = os.path.join(glove_dir, 'glove.6B.zip')
glove_txt = os.path.join(glove_dir, 'glove.6B.200d.txt')
word2vec_txt = os.path.join(glove_dir, 'glove.6B.200d.word2vec.txt')
os.makedirs(glove_dir, exist_ok=True)일단 임베딩 모델 하파를 변경했다.
벡터 사이즈, 컨텍스트 윈도우, 에폭을 2배로 늘렸다. GloVe도 100d 모델에서 200d 모델로 변경했다.
""" 임베딩 행렬 생성 함수 """ # emb dim 100 -> 200
def create_embedding_matrix(embedding_model, word_to_index, embedding_dim=200):
embedding_matrix = np.zeros((len(word_to_index), embedding_dim))임베딩 매트릭스 생성시 넣는 차원 수를 100에서 200으로 늘렸다.
# 150 -> 400
train_dataset = NewsDataset(X_train, y_train, word_to_index, max_len=400)
test_dataset = NewsDataset(X_test, y_test, word_to_index, max_len=400)
# 64 -> 32
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)최대 토큰을 늘리고 배치를 줄였다.
def train_model(model_name, emb_name, emb_matrix, train_loader, vocab_size, word_to_index, learning_rate, epochs):
pad_idx = word_to_index['<PAD>']
# 모델 인스턴스 생성
model = Classifier(
vocab_size=vocab_size,
embedding_dim=200, # 100 -> 200
hidden_dim=256, # 128 -> 256
output_dim=len(set(labels)),
n_layers=2,
bidirectional=True,
dropout=0.3, # 0.5 -> 0.3
pad_idx=pad_idx,
model_name=model_name
).to(device)
# 사전 훈련된 임베딩 가중치 적용
model.embedding.weight.data.copy_(emb_matrix)
model.embedding.weight.data[pad_idx] = torch.zeros(200) # 100 -> 200
model.embedding.weight.requires_grad = False
학습 루프에서 생성하는 모델의 하파값을 일부 수정했다.
zeros도 100에서 200으로 늘렸다.
""" 파이프라인 실행 """
# 하이퍼파라미터
LEARNING_RATE = 0.0001 # 0.001 -> 0.0001
EPOCHS = 20
# 훈련된 모델 저장
trained_models = {}학습률을 10배 낮췄다. 에폭은 일단 유지!
trained_models['RNN_Word2Vec'] = train_model(
model_name='RNN',
emb_name='Word2Vec',
emb_matrix=word2vec_embedding_matrix,
train_loader=train_loader,
vocab_size=vocab_size,
word_to_index=word_to_index,
learning_rate=LEARNING_RATE,
epochs=EPOCHS
)
...
...다시 9개 조합을 돌려보자!!
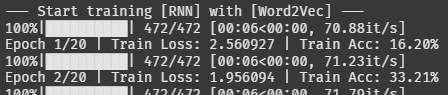
RNN_Word2Vec 조합의 2에폭 정확도가 33%다. 아깐 20에폭 돌려서 25% 였는데 시작부터 느낌이 좋다.
테스트셋 평가
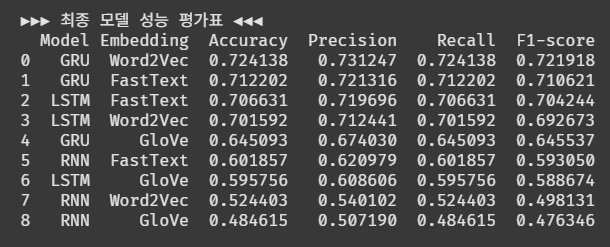
이번에도 1위는 GRU+Word2Vec 조합이다.
하파값을 조정했음에도 불구하고 정확도는 2% 정도만 상승한 것 같다.
그래도 Vanilla RNN + GloVe는 17%에서 48%로 유의미한 상승이 생겼다.
늘릴 수 있는 건 조금 씩 다 늘려봤는데 정확도가 70% 수준에 머무른다라...
그렇다면 이건 모델의 한계이거나 데이터의 문제 둘 중 하나일 것이다.
나중에 기회가 되면 최신 모델로 분류를 해봐야겠다.
알고 보니 미션 2개를 이어서 하는 거였다. 어쩐지 시간을 길게 주나 했더니,, 역시는 역시 역시군
