미션 2개 + 해커톤 기획은 지옥이다...
학습시간 09:00~04:00(당일19H/누적1237H)
◆ 학습내용
한영 AI 번역기 모델 구현하기!
- 한국어를 영어로 번역하는 Seq2Seq(기본 모델, Attention 적용 모델) 구현
- JSON 파일(train_set.json, valid_set.json) 형식
- 데이터셋 각 항목은 한국어 문장("ko")과 영어 번역문("mt")으로 구성
- 적절한 토크나이저를 선택하여 한국어, 영어 문장을 토큰화
- 필요한 경우 SOS, EOS, PAD, UNK 등의 특수 토큰을 정의
- 한국어와 영어 각각의 어휘 사전 구성
- Seq2Seq 모델: GRU 기반의 Encoder-Decoder 모델을 구현하고, Teacher Forcing 기법을 적용해 학습
- Attention 모델: Attention(Bahdanau 혹은 Luong)을 적용한 디코더를 구현
- 무작위 문장 쌍에 대해 모델의 번역 결과를 출력
- 다양한 평가 지표(예: BLEU 점수) 도입
1. 계획
벌써 어텐션 모델이라니... 아마 이번엔 아키텍처를 구현하는 게 핵심이겠지?
일단 데이터셋을 제공해 주니 다운로드 받는데 큰 걱정은 안 해도 될 것 같다.
문제는 JSON 파일을 어떻게 전처리하느냐다. 탐지모델은 모델에 적합한 포맷으로 파싱을 했는데, 이번에도 그럴 필요가 있는지 찾아봐야겠다.
토큰화는 하던대로 똑같이 하면 될 것 같은데, 임베딩 모델은 구현할 필요 없나? 모델에 따라서 임베딩 모델을 구현해야 하는 여부가 달라지는 건가? 이것도 찾아봐야겠다.
마지막으로 BLEU 점수라는 것으로 평가를 해보라고 하는데,, 이것도 처음 본다.
이번 미션도 순조롭지 않을 것 같은 느낌이 든다 ㅠㅠ
2. EDA
import sys
if 'google.colab' in sys.modules:
from google.colab import drive; drive.mount('/content/drive')
import drive.MyDrive.develop.config_my_path as cc
cc.dir('machine-translator')일단 기본 환결설정을 해준다.
dir() 함수에 뭔가 기능을 여러 개 넣고 싶은데 아직 뭘 추가해야할지 모르겠다.
# 시스템 & 유틸
import os
import json
import random
import numpy as np
from tqdm import tqdm
import matplotlib.font_manager as fm
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 전처리
!pip install kiwipiepy
from kiwipiepy import Kiwi
import spacy
from collections import Counter
# BLEU
import nltk
nltk.download('punkt')
from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction
# PyTorch
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
# 디바이스
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")기본적인 라이브러리를 불러왔다.
토큰화에는 국문 kiwi, 영문 spacy를 사용할 예정이다.
BLEU 평가지표는 nltk안에 내장되어 있다고 한다...!
def load_json_data(path):
with open(path, 'r', encoding='utf-8') as f:
data = json.load(f)
return data['data']
train_path = 'train_set.json'
valid_path = 'valid_set.json'
train_data = load_json_data(train_path)
valid_data = load_json_data(valid_path)
print(f"Train datas: {len(train_data)}")
print(f"Valid datas: {len(valid_data)}")
print("----------------")
print("KO:", train_data[0]['ko'])
print("MT:", train_data[0]['mt'])
print("----------------")
train_data[0]JSON에 뭐가 들었는지 확인해 보자!
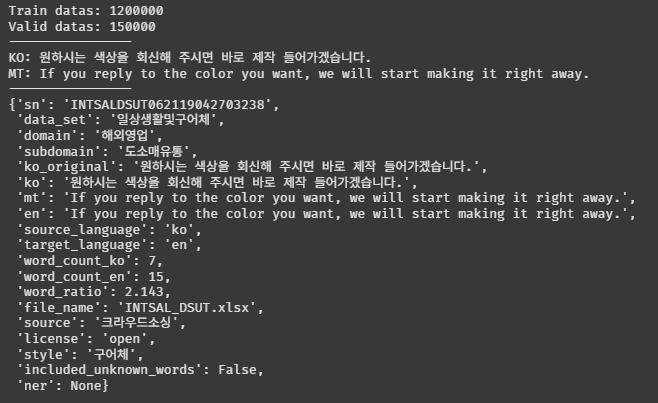
Train 12만 개, Valid 1만 5천 개다. 8:2 비율로 나누어져 있는 것 같다.
JSON 내부에는 여러 키쌍값이 있다. ko, mt의 상관관계를 학습시키는 것 같다.
조금 더 살펴보자!
# 문장 길이 측정
def get_sentence_lengths(data):
ko_lens = [len(item['ko']) for item in data]
en_lens = [len(item['mt']) for item in data]
return ko_lens, en_lens
ko_lengths_train, en_lengths = get_sentence_lengths(train_data)
print(f"KO Avg Length: {np.mean(ko_lengths_train):.0f}")
print(f"EN Avg Length: {np.mean(en_lengths):.0f}")
print(f"KO Max Length: {max(ko_lengths_train)}")
print(f"EN Max Length: {max(en_lengths)}")
print("----------------")
ko_lengths_valid, en_lengths = get_sentence_lengths(valid_data)
print(f"KO Avg Length: {np.mean(ko_lengths_valid):.0f}")
print(f"EN Avg Length: {np.mean(en_lengths):.0f}")
print(f"KO Max Length: {max(ko_lengths_valid)}")
print(f"EN Max Length: {max(en_lengths)}")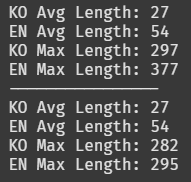
len() 함수로 train, valid 셋의 문장 길이를 확인했다.
영어 최대 377자면 엄청 긴 문장도 없다는 뜻이다.
평균 27~54자면 이 데이터셋은 짧은 문장들로 대부분 구성되어 있는 것 같다.
df = pd.concat([train_df, valid_df], ignore_index=True)
sns.set(style="whitegrid")
# domain 분포
plt.figure(figsize=(10, 4))
sns.countplot(data=df, x='domain', hue='split', order=df['domain'].value_counts().index)
plt.title('Domain Distribution by Split')
plt.xticks(fontproperties=fontprop)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()어떤 도메인의 언어를 주로 학습하는지 확인해 보자.
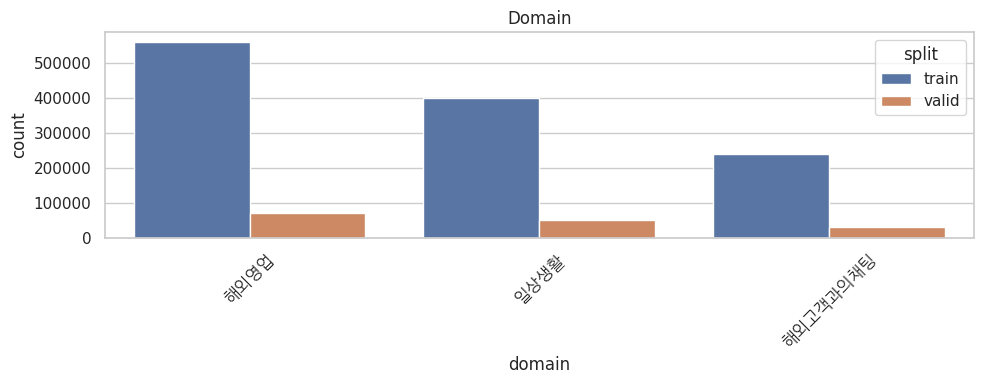
비즈니스와 일상생활이 대부분이다. 그렇다는 건, 법률지식 같은 전문 용어를 인풋으로 넣으면 성능이 젬병이 될 가능성이 높다는 뜻이다.
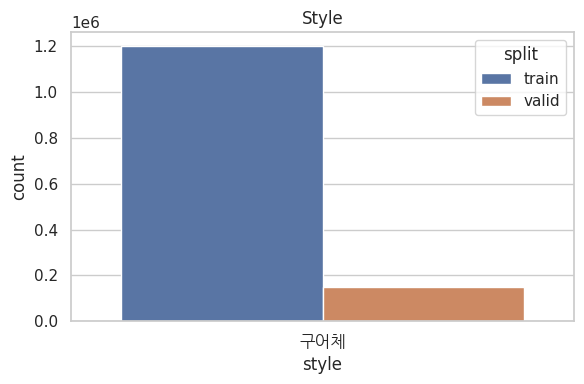
문체는 구어체로만으로 이루어져 있다. 문어체나 개조식 형태의 인풋에는 성능이 잘 안 나올 것 같다.
3. 전처리
SPECIAL_TOKENS = {
"<pad>": 0,
"<sos>": 1,
"<eos>": 2,
"<unk>": 3
}특수토큰을 먼저 설정했다. 지금까지 4개만 배웠는데 다른 게 뭐가 더 있는지 나중에 찾아봐야겠다.
class Tokenizer:
def __init__(self):
self.kiwi = Kiwi()
self.en = spacy.load("en_core_web_sm")
def tokenize_ko(self, text):
return [t.form for t in self.kiwi.tokenize(text)]
def tokenize_en(self, text):
return [t.text.lower() for t in self.en(text)]간단한 토크나이저 함수를 만들었다. kiwi랑 spacy "en_core_web_sm" 버전을 가져왔다.
def build_vocab(sentences, tokenize_fn, min_freq=2):
counter = Counter()
for sent in sentences:
counter.update(tokenize_fn(sent))
vocab = {token: idx for idx, (token, freq) in enumerate(counter.items(), start=4) if freq >= min_freq}
vocab = {**SPECIAL_TOKENS, **vocab}
return vocab단어사전 함수를 만들었다. 임베딩 미션 때 했던 것처럼 Counter()를 사용해서 토큰의 빈도를 계산한다.
출현 빈도가 2 이하인 건 버리고, 인덱스 0~3은 스폐셜 토큰으로 해야하니 4부터 등록한다.
vocab = {**SPECIAL_TOKENS, **vocab} 이렇게 쓰면 고정 등록할 수 있다는데,, 아직 이 와일드카드처럼 생긴 녀석의 사용법을 잘 모르겠다.
sentences = ["안녕하세요", "안녕", "반가워요"]
tokenize_fn = lambda x: list(x) # 예시: 문자 단위
→ vocab = {'<pad>':0, '<sos>':1, '<eos>':2, '<unk>':3, '안':4, '녕':5, '하':6, ...}위 함수를 사용하면 이런 식의 결과가 나온다고 한다!
def encode(tokens, vocab, add_sos_eos=True):
ids = [vocab.get(t, SPECIAL_TOKENS["<unk>"]) for t in tokens]
if add_sos_eos:
return [SPECIAL_TOKENS["<sos>"]] + ids + [SPECIAL_TOKENS["<eos>"]]
return ids이제 간단한 인코드 함수를 만들어 준다.
이게 살짝 이해하기 어려운데, build_vocab 함수랑 한 세트로 보면 될 것 같다.
build_vocab에서 단어사전을 만들고, encode에서 그 단어사전을 사용해 문장을 숫자로 변환한다.
시작 문장에는 sos토큰을, 마지막 문장에는 eos 토큰을 넣는다.
class IndexedDataset(Dataset):
def __init__(self, token_pairs):
self.data = token_pairs
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return (
torch.tensor(self.data[idx]['ko']),
torch.tensor(self.data[idx]['mt'])
)토큰화된 데이터를 텐서로 변환하는 클래스를 만들었다.
한영을 튜플로 묶어서 리턴한다.
def collate_fn(batch):
ko_batch, en_batch = zip(*batch)
ko_pad = torch.nn.utils.rnn.pad_sequence(ko_batch, batch_first=True, padding_value=SPECIAL_TOKENS["<pad>"])
en_pad = torch.nn.utils.rnn.pad_sequence(en_batch, batch_first=True, padding_value=SPECIAL_TOKENS["<pad>"])
return ko_pad, en_pad다음은 패딩을 추가해 주는 함수다.
이게 코드적이고 아직 잘 이해가 안 간다. 저 rnn.pad_sequence라는 모듈을 뜯어보기 전까진 계속 이해를 못할 것 같긴 한데,,, 시간이 없으니 일단 패스.. ㅠㅠ
def get_tokenized_loader(json_path, cache_path, batch_size):
if os.path.exists(cache_path):
tokenized_data, ko_vocab, en_vocab = torch.load(cache_path)
else:
with open(json_path, encoding='utf-8') as f:
data = json.load(f)['data']
tokenizer = Tokenizer()
ko_vocab = build_vocab([d['ko'] for d in data], tokenizer.tokenize_ko)
en_vocab = build_vocab([d['mt'] for d in data], tokenizer.tokenize_en)
tokenized_data = []
for d in data:
ko_ids = encode(tokenizer.tokenize_ko(d['ko']), ko_vocab)
en_ids = encode(tokenizer.tokenize_en(d['mt']), en_vocab)
tokenized_data.append({'ko': ko_ids, 'mt': en_ids})
torch.save((tokenized_data, ko_vocab, en_vocab), cache_path)
print("tokenized file saved")
dataset = IndexedDataset(tokenized_data)
loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
return loader, ko_vocab, en_vocab
train_loader, ko_vocab, en_vocab = get_tokenized_loader(
json_path='train_set.json',
cache_path='tokenized_train.pt',
batch_size=64
)이건 굳이 필요 없을 것 같긴 한데,, 토큰화에 시간이 너무 오래 걸려서 방법이 없을까 고민하다 생각해낸 방법이다.
JSON 파일을 불러와서 아까 만든 Tokenizer 클래스를 적용한다.
build_vocab() 함수로 사전화 하고 encode() 함수로 문장 단위 토큰화를 해서 tokenized_data 리스트에 넣는다.
이걸 다운로드 해뒀다가 나중에 불러오면 전처리 끝!
