역대급으로 어려웠던 미션... 내가 뭘 했는지도 모르겠다
학습시간 12:00~00:00(당일12H/누적1279H)
◆ 학습내용
어제(6~7번)에 이어 오늘 8번 부터 시작!
8. 모델 학습 2차
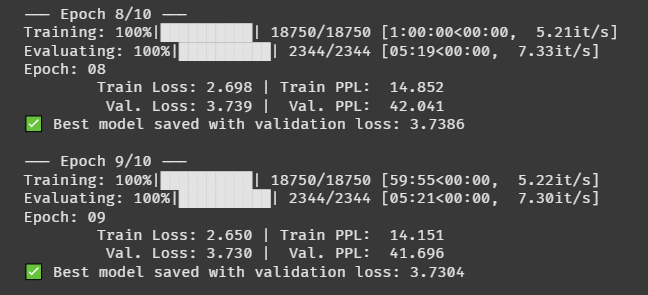
어제 틀어놓고 잤는데 베이직 모델조차 학습을 끝내지 못했다.
이대로면 이 미션을 끝내지 못할 것 같다는 생각이 들어서 데이터를 줄여서 처음부터 다시 해보기로 했다.
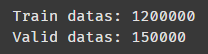
다시 보니까 train set이 12만 개인 줄 알았는데 120만 개더라 ㅋ 어쩐지 오래 걸린다 했다 ㅋㅋㅋㅋ
SPECIAL_TOKENS = {"<pad>": 0, "<sos>": 1, "<eos>": 2, "<unk>": 3}
TRAIN_JSON = "train_set.json"
VALID_JSON = "valid_set.json"
TRAIN_CACHE = "tokenized_train.pt"
VALID_CACHE = "tokenized_valid.pt"
SMOKE_RATIO = 0.05
MIN_FREQ = 2
BATCH_SIZE = 64SMOKE_RATIO 라는 것을 추가했다. 전처리 진행할 데이터 비율을 다루는 변수다.
def process_split(json_path, cache_path, tokenizer, ratio, ko_vocab=None, en_vocab=None, build_vocab_flag=False):
if os.path.exists(cache_path):
print(f"[SKIP] '{cache_path}' already exists.")
return torch.load(cache_path)
data = json.load(open(json_path, "r", encoding="utf-8"))["data"]
if 0 < ratio < 1:
random.seed(42)
data = random.sample(data, int(len(data) * ratio))
ko_sents = [d["ko"] for d in data]
en_sents = [d["mt"] for d in data]새로 만든 변수에 맞추어 전처리 함수도 손봤다.
학습 데이터 120만 개의 5%면 6만 개다. 제대로 만들어 졌을까!?

6만 개만 토크나이즈 됐다.
데이터 100% 사용할 때는 이 부분에서만 2시간 넘게 걸렸는데,, 이럴 줄 알았으면 미리 나눠서 쓰는 건데 ㅠㅠ 안 그래도 부족한 시간을 날려버렸다.

데이터 수가 줄어드니 모델이 파라미터 수도 줄어들었다. 자연어 처리 모델은 데이터에 따라 파라미터 수가 변하는 것 같다!!
# torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
기존에 있던 clip 관련 코드는 다 제거했다. 에폭을 많이 돌릴 게 아니라서 제한을 두는 게 딱히 의미가 없을 것 같다.
epochs = 5
# clip = 1.0
# Basic 모델 훈련
train_model(model_basic, train_loader, valid_loader, opt_basic, criterion_basic, epochs, device)잘 돌아가나 5에폭만 돌려보자!
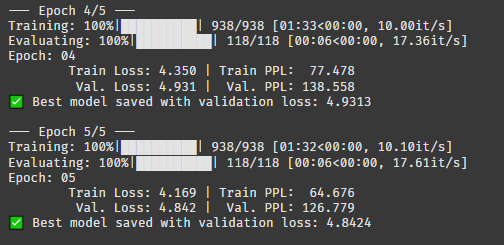
베이직 모델 학습이 끝났다. 데이터가 적어서 그런지 1에폭이 2분 정도 걸린다.
로스가 계속 줄어드는 걸 보면 한 20에폭까지 돌려도 될 것 같지만,, 시간이 없으니 그냥 이대로 끝내야지.. ㅠㅠ
perplexity 지수가 생각보다 엄청 높다. 이건 당혹지수? 같은 건데, 모델이 어떤 단어를 최종 결정해야할지 헷갈려하는 빈도라고 보면 된다.
몇이 적당한 수준인지는 모르겠지만 어쨌든 valid set 126이면 엄청 높은 수치라는 건 알 것 같다.
# Attention 모델 훈련
train_model(model_attn, train_loader, valid_loader, opt_attn, criterion_attn, epochs, device)다음은 어텐션 모델! 과연 어텐션 하나 들어간 게 유의미한 차이를 보여줄까??
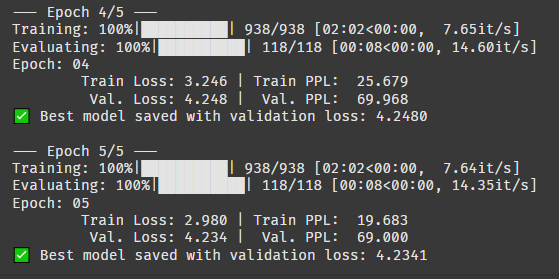
오!! 로스와 PPL이 엄청나게 줄었다!! 5에폭만 돌렸는데도 엄청난 차이가 있다.
valid set 성능이 아직 안 좋지만, 이건 학습한 데이터가 적으니 감안할 수밖에 없겠지...
9. 모델 평가
이번에 평가할 지표는 BLEU다. 일단 이게 뭔지부터 살펴보자.

BLEU Score(Bilingual Evaluation Understudy)란, 텍스트 번역 성능을 확인할 때 자주 쓰이는 지표다. 1에 가까울수록 성능이 좋다.
Rouge Score가 Recall 기반의 평가지표인 반면, BLEU Score는 Precision 기반의 지표다.
흠,,, Precision 기반이라는 건 이해했는데 나머진 아무 것도 모르겠다 ㅋ
def translate_sentence(sentence_str, model, tokenizer, ko_vocab, en_vocab, device, max_len=100):
def evaluate_and_show_samples(model, data_loader, device, num_samples=3):
일단 관련 함수 2개를 만들었다. 함수 내용이 뭔지는 모르겠다.... 이건 부트캠프 끝나고 다시 봐야할듯
models_to_evaluate = [
(model_basic, 'best-model-Seq2Seq.pth'),
(model_attn, 'best-model-AttnSeq2Seq.pth')
]
for model, model_path in models_to_evaluate:
model.load_state_dict(torch.load(model_path, map_location=device))
evaluate_and_show_samples(model, valid_loader, device, num_samples=1)모델 학습 후 나온 pth 파일을 로드해서 추론에 사용한다.

오잉?? 원문이 토큰화 되어서 들어가는 것 같은데,, 이게 맞나!? 뭔가 이상하다 ㅋㅋㅋㅋㅋㅋ
그리고 BLEU 점수도 엄청 높다. 성능이 거의 망했다는 뜻이겠지...
my_sentence = ("오늘도 행복한 하루 보내세요. 감사합니다.")
print(f"\nMy Korean Sentence: {my_sentence}")
print("-" * 60)
for model, model_path in models_to_evaluate:
model.eval()
translated_tokens = translate_sentence(my_sentence, model, tokenizer, ko_vocab, en_vocab, device)
translated_sentence = " ".join(translated_tokens)
print(f"[{model.__class__.__name__} Translation]: {translated_sentence}")내가 입력한 한국어를 잘 번역하는지 테스트 하는 코드다.

안녕하세요 감사합니다 정도는 번역할 수 있는 성능이다.
다른 건 어떨까?

즐거운 하루 보내세요가 have a day day day day로 나온다 ㅋㅋㅋㅋ

살짝 사무적인 내용을 넣어봤다. 일단 숫자는 인식하지 못하는 것 같다.
흠,,, 그래도 모델이 만들어지긴 했는데 완전 망한 것 같다.
수업 진도가 너무 빨라서 다시 수정할 시간은 없는데,,, 아무래도 고이 모셔 두었다가 겨울에 다시 꺼내봐야겠다.
완벽하진 않지만 완료는 했다...!
