이거 난이도가 조금 이상한데,,, 첫 프로젝트보다 이게 더 어려운 것 같다.
학습시간 13:00~01:00(당일12H/누적1267H)
◆ 학습내용
어제 4~5번에 이어 6번 부터 시작!
6. 모델 객체 생성
어제 모델 2개를 만들었는데, 시간이 늦어서 객체 생성을 못했다. 후딱 만들고 학습을 하자!
INPUT_DIM = len(ko_vocab)
OUTPUT_DIM = len(en_vocab)일단 가장 중요한 단어사전의 총 길이를 변수로 설정한다.
한국어로 들어와 영어로 나가기 때문에 인풋이 ko_vacab이다.
ENC_EMB_DIM = 256 # 인코더 임베딩 차원
DEC_EMB_DIM = 256 # 디코더 임베딩 차원
HID_DIM = 512 # 기본 모델 히든 차원
ENC_HID_DIM = 512 # 어텐션 모델 인코더 히든 차원
DEC_HID_DIM = 512 # 어텐션 모델 디코더 히든 차원
N_LAYERS = 2 # 기본 모델 레이어 수
DROPOUT = 0.5사실 임베딩 차원을 각각 뭘로 해줘야 하는지 잘 모르겠다.
보통은 인코더 디코더 임베딩을 저정도로 설정한다고 하는데,,, 근거는 찾지 못했다 ㅋ..
특별한 점은, 기본 모델엔 히든 차원만 있고, 어텐션 모델엔 히든 차원이 인코더 디코더 나누어져 있다는 것이다.
basic_encoder = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM, N_LAYERS, DROPOUT)
basic_decoder = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, N_LAYERS, DROPOUT)
model_basic = Seq2Seq(basic_encoder, basic_decoder, device).to(device)기본 모델 인코더 디코더를 초기화하고 model_basic으로 지정해 준다.
attn_encoder = AttnEncoder(INPUT_DIM, ENC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, DROPOUT)
attention = BahdanauAttention(ENC_HID_DIM, DEC_HID_DIM)
attn_decoder = AttnDecoder(OUTPUT_DIM, DEC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, DROPOUT, attention)
model_attn = AttnSeq2Seq(attn_encoder, attn_decoder, device).to(device)어텐션 모델도 똑같이 한다.
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print("\n--- Parameter Counts ---")
print(f"The Basic Seq2Seq model has {count_parameters(model_basic):,} trainable parameters.")
print(f"The Attention Seq2Seq model has {count_parameters(model_attn):,} trainable parameters.")파라미터 수 확인을 위한 함수를 하나 만들었다.
원래 summary 라이브러리를 사용했는데, 파라미터만 볼 거면 이렇게 하는 게 출력이 한 줄만 나와서 좋은 것 같다.

기본이 4500만 파라미터다. 어텐션이 들어가면 2배 가량 뛴다.
7. 모델 학습
opt_basic = optim.Adam(model_basic.parameters(), lr=0.0005)
criterion_basic = nn.CrossEntropyLoss(ignore_index=SPECIAL_TOKENS['<pad>'])
opt_attn = optim.Adam(model_attn.parameters(), lr=0.0005)
criterion_attn = nn.CrossEntropyLoss(ignore_index=SPECIAL_TOKENS['<pad>'])드디어 학습 루프다...
일단 옵티마이저와 손실함수를 각 모델을 위해 2개 만들었다. 평소와 조금 다른 점은 손실함수에 pad 토큰이 들어간다는 것이다. 역전파 시에 loss값에 pad 토큰을 반영하지 않기 위함이다.
def train_model(model, train_loader, valid_loader, optimizer, criterion, epochs, device, clip=1.0):
model_name = model.__class__.__name__
best_valid_loss = float('inf')
print(f"\n========== Starting Training & Evaluation for: {model_name} ==========")드디어 학습 함수다!
model.__class__.__name__ 는 처음 사용해 보는데, 저장할 모델이 2개여서 자동으로 분기를 나누어주기 위함이다.
for epoch in range(epochs):
model.train()
total_train_loss = 0
print(f"\n--- Epoch {epoch+1}/{epochs} ---")에폭 돌리는 루프다! 여기까진 똑같다.
for i, (src, trg) in enumerate(tqdm(train_loader, desc="Training")):
src, trg = src.to(device).T, trg.to(device).T
optimizer.zero_grad()
output = model(src, trg, teacher_forcing_ratio=0.5)
output_dim = output.shape[-1]
output_reshaped = output[1:].reshape(-1, output_dim)
trg_reshaped = trg[1:].reshape(-1)이번엔 순전파 부분이다. 평소와 조금 다른 점은 batch가 튜플 형식으로 i, (scr, trg) 이렇게 들어간다는 점이다. 그리고 전치행렬로 변경한다. 그리고 또 쉐입을 변경해 준다.
쉐입이 계속 바뀌니 머릿속에서 그려지지가 않는다..ㅠㅠ
loss = criterion(output_reshaped, trg_reshaped)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
total_train_loss += loss.item()다음을 역전파 부분이다. 다행이 크게 다른 건 없다. clip이라는 게 있는데, 이게 시계열 모델 특성상 기울기 폭발할 확률이 높아서 특정값 이상 step하지 못하게 막아주는 역할이라고 한다. 이런 게 있었다니 신기하다...!
if avg_valid_loss < best_valid_loss:
best_valid_loss = avg_valid_loss
torch.save(model.state_dict(), f'best-model-{model_name}.pth')베스트 모델이 나올 때마다 저장하는 조건식을 걸었다.
# 하이퍼파라미터
epochs = 10
clip = 1.0
# Basic 모델 훈련
train_model(model_basic, train_loader, valid_loader, opt_basic, criterion_basic, epochs, device, clip=clip)
# Attention 모델 훈련
train_model(model_attn, train_loader, valid_loader, opt_attn, criterion_attn, epochs, device, clip=clip)에폭은 10 정도만 돌려볼까..!!
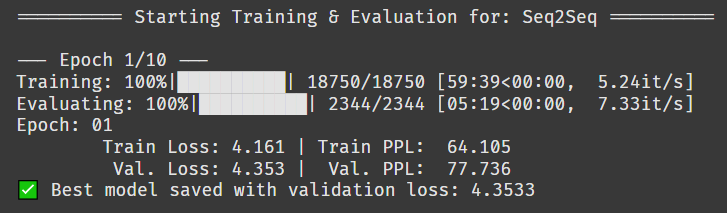
헉 ㅡㅡ... 1에폭에 1시간이 걸린다.
어텐션 모델까지 돌린다고 생각하면 20시간은 넘게 걸릴 것 같은데,,, 어쩜 좋지
자고 일어나도 학습이 안 끝날 것 같다.
일단 오늘은 여기까지 하고 정 안 되겠으면 데이터를 줄여서 처음부터 다시 하든지 해야겠다.
