어...? 진도 속도가...???
학습시간 09:00~03:00(당일18H/누적1297H)
◆ 학습내용

1. 논문 톺아보기
(1) BERT의 차별점
Introduction (Section 1)
Q. BERT가 기존의 Transformer 기반 언어 모델(GPT, ELMo 등)과 구별되는 가장 큰 차별점은 무엇인가?
- 가장 큰 차별점은 '진정한 양방향성(Deeply Bidirectional)'을 구현했다는 점.
- GPT: 왼쪽에서 오른쪽으로만 정보를 처리하는 단방향(unidirectional) 모델. (다음에 올 단어 예측)
- ELMo: 양방향 정보를 사용하긴 하지만, 왼쪽→오른쪽 LSTM과 오른쪽→왼쪽 LSTM을 각각 따로 학습한 뒤 결과를 단순히 이어 붙이는 방식(Shallow Bidirectional)이었음.
- BERT: 마스크드 언어 모델(MLM)을 사용해서 문장의 특정 단어를 가리고, 처음부터 문장 전체(왼쪽과 오른쪽 모두)의 문맥을 동시에 고려하여 가려진 단어를 예측. 덕분에 훨씬 깊이 있는 문맥 이해 가능.
(2) MLM
Section 3.1 (“Masked LM”)
Q. BERT의 MLM(Masked Language Model) 목표 함수는 어떻게 정의되며, 왜 전체 입력 토큰의 15%만 마스킹하는가?
- 목표 함수: 입력 토큰 중 일부를
[MASK]토큰으로 바꾼 뒤, 주변 단어들의 전체 문맥을 이용해 원래 단어가 무엇이었는지 예측하도록 학습. - 15%만 마스킹하는 이유:
- 너무 적게 마스킹하면 학습 비용(시간, 자원)이 너무 많이 소요됨.
- 너무 많이 마스킹하면 예측에 필요한 문맥 정보가 부족해져 학습이 어려워짐.
- 논문 저자들이 실험을 통해 15%가 성능과 학습 효율 사이의 가장 적절한 '스위트 스폿'이라는 것을 경험적으로 찾아냄.
- 마스킹된 15%를 8:1:1로 처리:
- 80%: 진짜
[MASK]토큰으로 변경. (예: I love you -> I[MASK]you) - 10%: 다른 임의의 단어로 변경. (예: I love you -> I apple you)
- 10%: 원래 단어 그대로 유지. (예: I love you -> I love you)
- 이유: 파인튜닝 단계에서는
[MASK]토큰이 없기 때문에, 사전학습과 파인튜닝 단계의 불일치를 줄이고 모델이 모든 토큰의 표현에 주의를 기울이게 하기 위함.
- 80%: 진짜
(3) NSP
Section 3.1 (“Next Sentence Prediction”)
Q. NSP 과제를 추가한 의도와, 이 과제가 downstream 태스크에 어떤 도움을 주는지 설명하라.
- 의도: MLM이 단어 수준의 문맥을 이해하는 데 집중한다면, NSP는 문장과 문장 사이의 관계를 모델이 이해하도록 만들기 위해 추가. (두 문장 A, B가 주어졌을 때, B가 A의 바로 다음 문장이 맞는지(IsNext) 아닌지(NotNext)를 맞추는 이진 분류 문제)
- 도움 되는 점: Q&A(질의응답), NLI(자연어 추론)처럼 두 텍스트 사이의 관계를 파악하는 것이 중요한 다운스트림 태스크에서 성능을 높이는 데 직접적인 도움을 줌. 모델이 글의 전체적인 흐름이나 논리 구조를 파악하는 능력을 갖게 됨.
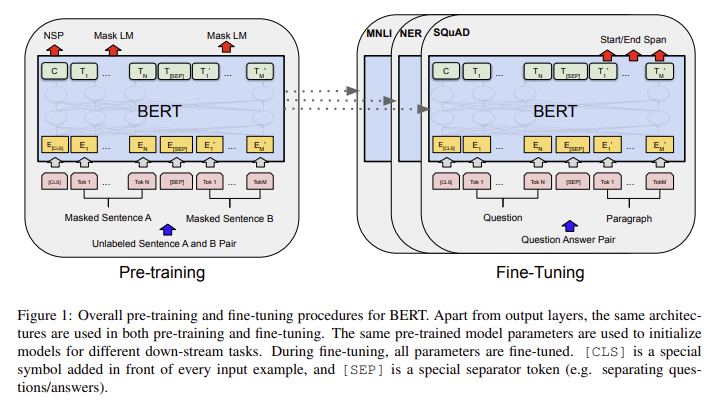
(4) 사전학습 & 파인튜닝
Section 3.2 (“Pre-training Procedure”) / Section 3.3 (“Fine-tuning Procedure”)
Q. BERT에서 “사전학습(pre-training)”과 “파인튜닝(fine-tuning)” 단계는 각각 어떤 데이터·목표로 수행되며, 파인튜닝 시 가장 큰 이점은 무엇인가?
사전학습 (Pre-training):
- 데이터: BooksCorpus, 위키피디아 같은 대규모의 레이블 없는 텍스트 데이터(unlabeled data)를 사용.
- 목표: MLM과 NSP 과제를 풀면서, 언어 자체에 대한 깊은 이해, 즉 범용적인 언어 표현 능력을 키우는 단계.
파인튜닝 (Fine-tuning):
- 데이터: 특정 문제에 대한 소량의 레이블 있는 데이터(labeled data)를 사용. (예: 감성 분석 데이터)
- 목표: 이미 똑똑해진 BERT 모델 위에 간단한 분류 레이어를 추가하여, 특정 태스크에 맞게 가중치를 미세 조정.
가장 큰 이점:
- 적은 데이터와 비용으로 매우 높은 성능의 모델을 만들 수 있다는 것. 밑바닥부터 학습하는 대신, 이미 언어 천재가 된 BERT를 살짝만 가르치면 되므로 훨씬 효율적이고 강력함.
(5) 임베딩 세 요소
Section 3.3 (“Input/Output Representations”)
Q. BERT 입력 토큰 임베딩은 세 요소(토큰, 세그먼트, 위치)로 구성된다. 각 요소의 역할과, 이들을 더하는 방식이 왜 중요한지 설명하라.
각 요소의 역할:
| 임베딩 종류 | 역할 |
|---|---|
| 토큰 임베딩 | 각 단어(토큰)의 고유한 의미를 나타냄. |
| 세그먼트 임베딩 | 각 토큰이 첫 번째 문장(A)에 속하는지 두 번째 문장(B)에 속하는지 구분. |
| 위치 임베딩 | 각 토큰이 문장 내에서 몇 번째 위치에 있는지 순서 정보를 부여. |
더하는 방식이 중요한 이유:
- 세 정보를 하나의 벡터로 합쳐 모델에 전달함으로써, 모델이 각 단어의 의미, 소속 문장, 순서 정보를 동시에 고려하여 복잡한 언어 구조를 훨씬 효율적이고 통합적으로 이해하게 함.
(6) Base & Large 차이점
Section 4.1 (“Model Architecture”) Table 1
Q. BERT-Base와 BERT-Large의 구조적 차이(레이어 수, 은닉 크기, self-attention 헤드 수 등)는 무엇이며, 이 차이가 성능에 어떻게 기여하는가?
- BERT-Base와 Large의 구조적 차이는 모델의 '크기'와 '복잡도'.
| 구조 | BERT-Base | BERT-Large |
|---|---|---|
| Transformer 레이어 (L) | 12개 | 24개 |
| 은닉 크기 (H) | 768 | 1024 |
| Self-Attention 헤드 수 (A) | 12개 | 16개 |
| 총 파라미터 수 | 1.1억 개 | 3.4억 개 |
- 성능 기여: 모델이 클수록 더 복잡하고 미묘한 언어적 패턴을 학습할 수 있는 용량(capacity)이 커짐. 따라서 BERT-Large는 BERT-Base보다 거의 모든 다운스트림 태스크에서 더 높은 성능을 보여줌. 즉, 모델의 크기가 표현력과 직결됨.
(7) 사전학습 데이터
Section 3.1 (“Pre-training Data”)
Q. BERT가 사전학습에 사용한 코퍼스는 무엇이며(규모·출처), 왜 두 가지 코퍼스를 혼합해서 사용했는가?
- 사용 코퍼스:
- BooksCorpus (800M 단어): 다양한 장르의 소설책 데이터.
- English Wikipedia (2,500M 단어): 위키피디아 텍스트 데이터.
- 혼합 이유: 두 코퍼스의 특징이 서로를 보완해주기 때문.
- 위키피디아: 정형화되고 사실적인 정보 학습에 유리.
- BooksCorpus: 대화나 서사처럼 장문의 연속적인 문맥과 다양한 문체 학습에 유리.
- 결론: 사실적 지식과 자연스러운 대화 흐름을 모두 학습하여 더 범용적인 언어 이해 능력을 갖추게 하려는 의도.
(8) 벤치마크 결과
Section 5 (“Experiments & Results”) Table 2-4
Q8. BERT가 GLUE, SQuAD, SWAG 등의 벤치마크에서 기존 최고 기록을 크게 경신할 수 있었던 주요 요인은 무엇인가?
- 진정한 양방향 사전학습 (MLM): 문장 전체의 앞뒤 문맥을 동시에 활용하여 단어와 문장을 깊이 있게 이해하는 새로운 방식을 도입. 이는 문맥에 따른 단어의 의미 변화를 파악하는 데 매우 효과적이었음.
- 통합된 파인튜닝 프레임워크: 대부분의 태스크를 별도 구조 변경 없이, 사전학습된 BERT 위에 간단한 출력 레이어만 추가하는 방식으로 해결. BERT의 풍부한 언어 표현을 특정 태스크에 쉽게 적용할 수 있었음.
(9) 한계와 후속 연구
Section 7 (“Conclusion”) 내 Limitations 문단
Q. 논문에서 언급된 한계점 두 가지를 쓰고, 각 한계에 대응하기 위해 이후 연구들이 어떻게 접근했는지 예를 들어 설명하라.
한계점 1: 사전학습과 파인튜닝의 불일치 ([MASK] 토큰 문제)
- 내용: 사전학습 때는
[MASK]토큰을 사용하지만, 파인튜닝 단계에서는 등장하지 않아 두 단계 사이에 괴리가 생긴다는 문제. - 후속 연구: XLNet은 순열(Permutation) 기반 언어 모델링을 제안하여,
[MASK]토큰 없이 양방향 문맥을 학습.
한계점 2: 독립적인 예측 가정
- 내용: MLM은 마스킹된 단어들을 예측할 때, 다른 마스킹된 단어들과의 관계를 고려하지 않고 각각 독립적으로 예측한다는 한계.
- 후속 연구: SpanBERT는 개별 토큰 대신 연속된 단어 덩어리(span)를 마스킹하고 예측하도록 학습 목표를 바꿔, 덩어리 내부의 관계까지 학습하도록 개선.
(10) 응용·확장 사례
Section 6 (“Related Work”)
Q. BERT의 사전학습 방식을 영상·멀티모달·코드 언어 모델 등 타 분야에 확장한 사례 하나를 선택하여, 어떻게 적용했는지 요약하라.
VideoBERT (영상 분야 적용 사례)
- 핵심 아이디어: 텍스트에서 단어를 마스킹하듯, 영상에서 시각적 토큰(visual token)의 일부를 마스킹하고 이를 예측하도록 BERT의 MLM 방식을 확장.
- 적용 방식:
- 토큰화: 영상을 짧은 클립으로 나눠 '시각적 토큰'을 생성.
- 데이터셋 구성: 영상 토큰과 해당 영상의 설명 텍스트를 하나의 시퀀스로 구성.
- 사전학습: 시퀀스의 토큰(시각 또는 텍스트) 15%를
[MASK]로 가리고, 주변 문맥을 이용해 원래 토큰을 예측하도록 학습.
- 결과: 텍스트만 보고 미래의 영상 장면을 생성하거나, 영상의 다음 행동을 예측하는 등 텍스트와 영상 사이의 깊은 관계를 이해하는 능력을 보여줌.
2. 코드 구현
(1) Activation Layer
""" Activation Layer """
class PositionWiseFeedForward(nn.Module):
def __init__(self, hidden_size, ff_size):
super().__init__()
self.fc1 = nn.Linear(hidden_size, ff_size)
self.fc2 = nn.Linear(ff_size, hidden_size)
self.gelu = nn.GELU()
def forward(self, x):
return self.fc2(self.gelu(self.fc1(x)))PositionWiseFeedForward 클래스는 표현력을 향상시키는 역할을 한다.
어텐션 메커니즘을 통해 생성된 문맥 정보를 입력받고, 비선형 변환을 포함한 추가적인 계산을 수행한다.
주로 두 개의 선형 레이어 사이에 GELU 활성화 함수를 배치한 형태를 가진다.
첫 번째 레이어는 입력 차원을 확장하고, 두 번째 레이어는 다시 원래 차원으로 축소한다.
결과적으로 더 복잡하고 추상적인 특징을 학습할 수 있는 능력을 갖추게 된다.
(2) Add & Norm Layer
""" Add & Norm Layer """
class LayerNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-12):
super().__init__()
self.gamma = nn.Parameter(torch.ones(hidden_size))
self.beta = nn.Parameter(torch.zeros(hidden_size))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
output = self.gamma * (x - mean) / (std + self.eps) + self.beta
return output정규화 레이어다. gradient vanishing이나 exploding 문제를 완화한다.
핵심 연산은 평균과 표준편차를 계산하는 것이다.
gamma(ones)와 beta(zeros)를 이용해 스케일링과 이동을 적용할 수 있다.
(3) SDP Attention
""" SDP Attention """
def scaled_dot_product_attention(q, k, v, mask=None):
d_k = q.size(-1)
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn_weights = torch.softmax(scores, dim=-1)
output = torch.matmul(attn_weights, v)
return output어텐션 메커니즘의 가장 기본 연산이다.
Query, Key, Value를 입력을 받아, Query와 Key의 유사도를 계산하고, 이 유사도를 가중치로 삼아 Value의 정보를 조절하는 방식으로 작동한다.
유사도 점수는 Key 벡터의 차원 수 제곱근으로 나누어 스케일링하는데, 값이 과도하게 커지는 것을 방지하기 위함이다.
마스크(mask)를 적용하는 이유는 패딩된 토큰처럼 불필요한 부분에 대해서는 어텐션이 계산되지 않도록 하기 위함이다.
(4) MH Attention
""" MH Attention """
class MultiHeadAttention(nn.Module):
def __init__(self, hidden_size, num_heads):
super().__init__()
self.d_head = hidden_size // num_heads
self.num_heads = num_heads
self.w_q = nn.Linear(hidden_size, hidden_size)
self.w_k = nn.Linear(hidden_size, hidden_size)
self.w_v = nn.Linear(hidden_size, hidden_size)
self.w_concat = nn.Linear(hidden_size, hidden_size)
def forward(self, q, k, v, mask=None):
batch_size = q.size(0)
Q, K, V = self.w_q(q), self.w_k(k), self.w_v(v)
Q = Q.view(batch_size, -1, self.num_heads, self.d_head).transpose(1, 2)
K = K.view(batch_size, -1, self.num_heads, self.d_head).transpose(1, 2)
V = V.view(batch_size, -1, self.num_heads, self.d_head).transpose(1, 2)
attn_output = scaled_dot_product_attention(Q, K, V, mask)
attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.d_head)
output = self.w_concat(attn_output)
return output여러 개의 어텐션을 병렬적으로 실행한다. 다양한 관점에서 문맥을 파악하기 위함이다.
입력된 벡터는 여러 개의 헤드(Head)로 나누어 어텐션 점수가 계산된다.
(5) Encoder Layer
""" Encoder Layer """
class EncoderLayer(nn.Module):
def __init__(self, hidden_size, num_heads, ff_size, dropout_prob):
super().__init__()
self.attention = MultiHeadAttention(hidden_size, num_heads)
self.norm1 = LayerNorm(hidden_size)
self.dropout1 = nn.Dropout(p=dropout_prob)
self.ffn = PositionWiseFeedForward(hidden_size, ff_size)
self.norm2 = LayerNorm(hidden_size)
self.dropout2 = nn.Dropout(p=dropout_prob)
def forward(self, x, mask):
_x = x
x = self.attention(q=x, k=x, v=x, mask=mask)
x = self.norm1(self.dropout1(x) + _x)
_x = x
x = self.ffn(x)
x = self.norm2(self.dropout2(x) + _x)
return xBERT 모델을 구성하는 핵심 레이어다.
MultiHeadAttention과 PositionWiseFeedForward로 구성되며, 이 레이어가 겹겹이 쌓여 BERT의 몸체를 이룬다.
특징은 잔차 연결(Residual Connection)과 레이어 정규화(Layer Normalization) 과정을 거친다는 것이다.
Add & Norm 구조 덕분에 깊은 네트워크에서도 그래디언트가 원활하게 흐를 수 있다.
(6) Positional Encoding
""" Positional Encoding """
class PositionalEncoding(nn.Module):
def __init__(self, hidden_size, max_len=512):
super().__init__()
pe = torch.zeros(max_len, hidden_size)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, hidden_size, 2).float() * (-math.log(10000.0) / hidden_size))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
return x + self.pe[:, :x.size(1), :]단어 순서 정보를 모델에 주입하는 역할을 한다. 순서 개념이 없는 트랜스포머 아키텍처의 한계를 보완하기 위함이다.
각 토큰의 위치에 대한 고유한 벡터 값을 생성하여 단어의 임베딩에 더해준다.
sin, cos 함수를 이용하여 짝수와 홀수의 위치 벡터를 수학적으로 생성한다.
긴 길이의 시퀀스에 대해서도 위치 정보를 일반화하여 적용할 수 있는 장점이 있다.
(7) BERT Model
""" BERT Model """
class BERTModel(nn.Module):
def __init__(self, vocab_size, max_len, hidden_size, num_layers, num_heads, ff_size, dropout_prob):
super().__init__()
self.hidden_size = hidden_size
self.token_embedding = nn.Embedding(vocab_size, hidden_size)
self.positional_encoding = PositionalEncoding(hidden_size, max_len)
self.segment_embedding = nn.Embedding(2, hidden_size)
self.norm = LayerNorm(hidden_size)
self.dropout = nn.Dropout(p=dropout_prob)
self.encoder_layers = nn.ModuleList(
[EncoderLayer(hidden_size, num_heads, ff_size, dropout_prob) for _ in range(num_layers)]
)
def forward(self, x, segment_ids):
mask = (x > 0).unsqueeze(1).repeat(1, x.size(1), 1).unsqueeze(1)
embedding = self.token_embedding(x) + self.segment_embedding(segment_ids)
embedding = self.positional_encoding(embedding)
x = self.dropout(self.norm(embedding))
for layer in self.encoder_layers:
x = layer(x, mask)
return xBERT의 몸톰이다.
단어 토큰 시퀀스가 입력되면, 토큰, 세그먼트, 위치 임베딩을 결합하여 초기 벡터 표현을 생성하고, 이 벡터를 여러 층의 인코더 레이어에 통과시킨다.
(8) MLM & NSP Head
""" MLM & NSP Head """
class BERTForPretraining(nn.Module):
def __init__(self, vocab_size, max_len, hidden_size, num_layers, num_heads, ff_size, dropout_prob):
super().__init__()
self.bert = BERTModel(vocab_size, max_len, hidden_size, num_layers, num_heads, ff_size, dropout_prob)
self.mlm_head = nn.Linear(hidden_size, vocab_size)
self.nsp_head = nn.Linear(hidden_size, 2)
def forward(self, x, segment_ids):
bert_output = self.bert(x, segment_ids)
mlm_prediction = self.mlm_head(bert_output)
cls_output = bert_output[:, 0, :]
nsp_prediction = self.nsp_head(cls_output)
return mlm_prediction, nsp_prediction앞서 구현한 BERTModel 몸통 위에 사전학습을 위한 Head를 추가한 구조다.
Masked Language Model(MLM)과 Next Sentence Prediction(NSP)을 위한 레이어가 있다.
MLM 헤드는 BERT의 최종 출력 벡터를 받아 각 위치의 토큰이 어휘사전의 어떤 단어인지를 예측한다.
NSP 헤드는 [CLS] 토큰의 출력을 받아 두 문장이 이어지는 관계인지를 분류한다.
이 두 레이어가 있어야 BERT는 범용적인 언어 능력을 얻을 수 있다.
(9) 모델 생성
""" 모델 생성 """
config = {
'vocab_size' : 30522,
'max_len' : 512,
'hidden_size' : 768,
'num_layers' : 12,
'num_heads' : 12,
'ff_size' : 768 * 4,
'dropout_prob' : 0.1
}
model = BERTForPretraining(**config)헤드 클래스(BERTForPretraining)를 인스턴스화 한다.
config는 임의로 넣었는데, 주어진 테스크에 맞게 변경하면 된다.
