과연 나는 이 벽을 넘어갈 수 있을 것인가...
학습시간 09:00~03:00(당일18H/누적1315H)
◆ 학습내용
| 구분 | GPT-1 (2018) | GPT-2 (2019) | GPT-3 (2020) |
|---|---|---|---|
| 핵심 컨셉 | 생성적 사전학습(Generative Pre-training)으로 범용 언어 표현 학습 후 파인튜닝(Fine-tuning) | 제로샷(Zero-shot) 다중 과제 학습. 별도 파인튜닝 없이 다양한 작업 수행 가능 | 인컨텍스트 학습(In-context Learning). 퓨샷(Few-shot) 방식으로 예시 몇 개만 주면 바로 학습 |
| 파라미터 수 | 1.17억 개 | 15억 개 | 1750억 개 |
| 학습 데이터 | BookCorpus (약 8억 단어) | WebText (40GB) | Common Crawl 등 포함 (570GB) |
| 주요 특징 | 트랜스포머의 '디코더' 구조만 사용. 특정 과제에 맞게 모델 구조를 수정하고 재학습 필요 | 모델 크기를 키워 성능 극대화. 파인튜닝 없이 프롬프트만으로 과제 수행 시도 | 거대한 모델과 데이터로 문맥 내 학습 능력 비약적 향상. API 형태로 제공 시작 |
| 의의 | NLP에서 생성적 사전학습의 가능성을 보여줌 | 거대 언어 모델(LLM)의 시대 개막 | LLM의 상업적 성공과 대중화 기여 |
GPT 1

Improving Language Understanding by Generative Pre-Training
(생성적 사전학습을 통한 언어 이해 능력 향상)
문제: GPT-1 논문의 핵심적인 두 단계 학습 프레임워크는 무엇인가요?
정답: Generative pre-training and Discriminative fine-tuning
해설: GPT-1은 두 단계 학습 프레임워크 기반임. 첫째, 레이블 없는 방대한 텍스트로 언어 모델을 학습하는 '생성적 사전 훈련'을 진행함. 둘째, 사전 훈련된 모델을 특정 과제에 맞춰 조정하는 '판별적 미세 조정'을 수행함. 이 구조는 범용 언어 능력을 먼저 기르고 각 전문 분야에 적용하는 효율적인 방식임.
문제: GPT-1 모델이 사전 훈련에 사용한 주요 데이터셋은 무엇인가요?
정답: BooksCorpus
해설: GPT-1은 'BooksCorpus' 데이터셋을 사용하여 사전 훈련됨. 이 데이터셋은 7,000권 이상의 미출판 도서로 구성되어 있음. 다양한 장르의 책을 통해 긴 문맥의 의존성과 풍부한 언어 패턴을 학습함. 이는 긴 호흡의 서사 구조 학습에 유리하여 위키피디아와는 다른 장점을 가짐.
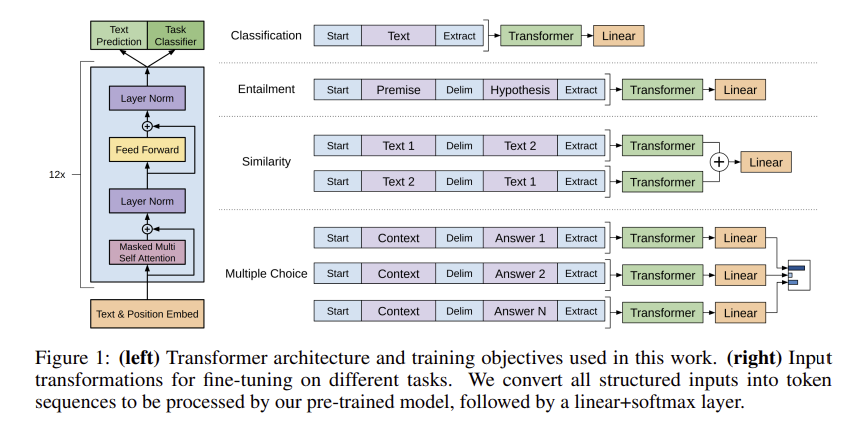
문제: GPT-1의 모델 아키텍처는 트랜스포머(Transformer)의 어떤 부분을 기반으로 하나요?
정답: Decoder block only
해설: GPT-1은 트랜스포머의 전체 구조가 아닌 '디코더 블록'만을 사용함. 이는 다음 단어를 예측하는 생성 모델에 더 적합하기 때문임. 12개의 디코더 레이어를 쌓고 '마스크드 셀프 어텐션'을 활용함. 이 디코더-온리 구조는 후속 GPT 시리즈의 기본 골격이 되었음.
문제: 사전 훈련 단계에서 GPT-1이 최적화한 목적 함수(Objective Function)는 무엇인가요?
정답: Standard language modeling likelihood
해설: GPT-1은 '표준 언어 모델링 우도(likelihood)'를 최대화하는 것을 목표로 학습함. 즉, 이전 단어들이 주어졌을 때 다음 단어가 나타날 확률을 가장 높이는 방향으로 훈련됨. 이는 BERT의 마스크드 언어 모델(MLM)과는 다른 전통적 방식임. 이 방식을 통해 문장을 순차적으로 생성하는 능력을 효과적으로 학습함.
문제: 미세 조정(Fine-tuning) 단계에서, 서로 다른 다운스트림 태스크를 처리하기 위해 GPT-1은 어떤 방식을 사용했나요?
정답: Task-specific input transformations
해설: GPT-1은 다양한 과제 해결을 위해 '태스크별 입력 변환' 방식을 사용함. 이는 모델 구조 변경을 최소화하며 여러 문제에 유연하게 대응하기 위함임. 각 태스크에 맞게 시작/종료 토큰, 구분자 토큰 등을 활용하여 입력 데이터의 형식을 바꿈. 이를 통해 단일 아키텍처로 여러 과제에 적용 가능성을 높였음.
문제: 자연어 추론(NLI) 태스크를 위해 GPT-1은 전제(premise)와 가설(hypothesis) 문장을 어떻게 입력으로 구성했나요?
정답: Concatenated the premise and hypothesis by inserting a delimiter token
해설: 자연어 추론 과제를 위해 전제와 가설 두 문장을 하나로 합쳐 입력으로 구성함. 두 문장 사이에 특별한 '구분자(delimiter) 토큰'을 삽입하여 연결함. 이를 통해 모델은 두 문장의 관계를 하나의 시퀀스로 파악하고 추론을 수행함. 이 방식은 문장 쌍을 다루는 여러 다른 태스크에도 동일하게 적용됨.
문제: 미세 조정 단계에서, 사전 훈련의 언어 모델링 목적 함수를 보조적으로 사용했을 때 어떤 효과가 있었나요?
정답: It improved the model's generalization performance and accelerated convergence.
해설: 미세 조정 시, 언어 모델링 목적 함수를 보조적으로 함께 사용함. 이는 지도 학습 모델의 '일반화 성능'을 향상시키는 효과를 가져옴. 또한 모델이 더 빨리 최적의 해에 도달하도록 '수렴 속도를 가속화'함. 결과적으로 더 안정적이고 강건한 모델을 만드는 데 기여함.
문제: GPT-1이 사용한 트랜스포머 아키텍처의 파라미터(레이어 수, 임베딩 차원, 헤드 수)는 무엇이었나요?
정답: 12 layers, 768-dimensional embeddings, 12 attention heads
해설: GPT-1은 12개의 디코더 '레이어(layer)'로 구성되었음. 단어를 표현하는 임베딩 벡터의 차원은 '768차원'이었음. 한 번에 여러 관점에서 정보를 처리하는 어텐션 '헤드(head)'는 '12개'를 사용함. 이 파라미터 구성은 당시 기준으로 매우 큰 모델에 해당함.
문제: 논문에서 GPT-1의 접근법이 기존의 다른 준지도 학습 방법들과 달랐던 핵심적인 차이점은 무엇인가요?
정답: It minimized task-specific architectural changes and directly fine-tuned the pre-trained model.
해설: 기존 방식은 주로 사전 훈련된 '단어 임베딩'만을 활용함. 반면 GPT-1은 단어 임베딩뿐만 아니라, 사전 훈련된 '모델 전체'를 직접 미세 조정함. 이로 인해 각 태스크에 맞는 별도의 모델 구조 변경을 '최소화'할 수 있었음. 이는 단일 통합 아키텍처로 다양한 문제에 접근하는 새로운 패러다임을 제시함.
문제: GPT-1의 토크나이저는 어떤 방식을 사용했나요?
정답: Byte-Pair Encoding (BPE)
해설: GPT-1은 텍스트를 처리 단위인 토큰으로 나누기 위해 'BPE' 방식을 사용함. BPE는 자주 함께 등장하는 문자 쌍을 하나의 단위로 병합해 어휘를 구축함. 이를 통해 사전에 등록되지 않은 단어(OOV) 문제에 효과적으로 대응할 수 있음. GPT-1은 40,000개의 병합 규칙을 가진 BPE 어휘 사전을 사용했음.
문제: 논문에서 '제로샷(zero-shot) 동작' 분석을 통해 저자들이 보이고자 한 것은 무엇이었나요?
정답: That the model had already acquired useful linguistic knowledge during pre-training.
해설: '제로샷' 평가는 미세 조정을 전혀 하지 않은 상태에서 모델의 성능을 측정하는 것임. 이를 통해 GPT-1이 '사전 훈련 과정만으로도 유용한 언어 지식을 습득했음'을 보임. 비록 성능이 높지는 않았지만, 무작위 추측보다 나은 결과를 보여주며 사전 훈련의 효과를 입증함. 이는 모델이 특정 과제에 대한 잠재력을 내재하고 있음을 시사함.
문제: GPT-1은 위치 정보를 모델에 어떻게 제공했나요?
정답: Learned position embeddings
해설: 트랜스포머는 단어의 순서를 인식하지 못해 별도의 위치 정보가 필요함. GPT-1은 고정된 값을 사용하는 대신, '학습 가능한 위치 임베딩'을 사용함. 이는 모델이 훈련 데이터로부터 최적의 위치 표현 방식을 스스로 학습하게 함. 기존 트랜스포머의 사인/코사인 함수 방식보다 더 유연한 접근법임.
문제: 미세 조정 시, 입력 시퀀스의 맨 마지막 토큰에 해당하는 트랜스포머 블록의 출력을 어디에 입력으로 사용했나요?
정답: An additional linear layer and softmax to predict the task's labels
해설: 미세 조정 시, 시퀀스의 마지막 토큰에서 나온 최종 출력 벡터를 활용함. 이 벡터를 과제 예측을 위해 새로 추가된 '선형(linear) 레이어'의 입력으로 사용함. 그 후 '소프트맥스(softmax) 함수'를 거쳐 최종 레이블을 예측함. 이 방식은 전체 시퀀스의 정보를 압축하여 분류 문제에 효과적으로 적용하는 전략임.
문제: GPT-1 논문이 발표될 당시, 자연어 처리에 널리 사용되던 사전 훈련된 표현(representation)은 주로 어떤 수준의 정보에 초점을 맞추고 있었나요?
정답: Word-level
해설: GPT-1 이전에는 주로 '단어 수준(word-level)'의 정보를 사전 훈련하는 것이 일반적이었음. Word2Vec, GloVe와 같이 각 단어에 대한 고정된 벡터 표현(임베딩)을 학습함. 이 단어 임베딩을 각 태스크 모델의 입력 피처로 사용하는 방식이었음. 문맥에 따라 단어의 의미가 변하는 것을 제대로 반영하기 어려운 한계가 있었음.
GPT 2

Language Models are Unsupervised Multitask Learners
(언어 모델은 비지도 다중 과제 학습자)

# GPT-2의 '제로샷 생성' 예시 코드
from transformers import pipeline
# 1. 텍스트 생성 파이프라인 로드
generator = pipeline('text-generation', model='gpt2')
# 2. 시작 프롬프트(문맥)만 제공
prompt = "In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains."
# 3. 모델이 알아서 뒷이야기를 생성 (별도 학습 없음 = Zero-shot)
results = generator(prompt, max_length=100, num_return_sequences=1)
print("--- GPT-2 생성 결과 ---")
print(results[0]['generated_text'])
문제: GPT-2 논문의 핵심 주장(thesis)은 무엇인가요?
정답: Language models can perform tasks without explicit supervision if they are large enough.
해설: GPT-2의 핵심 주장은 충분히 큰 언어 모델은 별도의 명시적 지도 학습 없이도 여러 과제를 수행할 수 있다는 것임. 이는 방대한 웹페이지 데이터셋으로 훈련 시, 모델이 자연스럽게 다양한 태스크를 학습함을 보여줌. 즉, 파인튜닝 없이 제로샷(zero-shot)으로 멀티태스크 학습이 가능함을 시사하며 모델의 크기(capacity)와 데이터 다양성이 핵심 요소로 작용함.
문제: GPT-2의 사전 훈련을 위해 OpenAI가 직접 제작한 데이터셋의 이름은 무엇인가요?
정답: WebText
해설: GPT-2 사전 훈련을 위해 OpenAI가 직접 제작한 데이터셋의 이름은 'WebText'임. 이 데이터셋은 소셜 뉴스 사이트 레딧(Reddit)에서 최소 3 '카르마'를 받은 게시물의 외부 링크를 수집하여 구축됨. 높은 품질의 텍스트 확보를 목적으로 설계되었으며, 약 40GB 규모의 방대한 양을 통해 모델이 다양하고 실제적인 언어 패턴을 학습하게 함.
문제: GPT-2는 특정 과제를 수행하기 위해 어떤 방식을 사용했나요?
정답: Task conditioning via prompts
해설: GPT-2는 특정 과제를 수행하기 위해 '프롬프트(prompt)를 통한 과제 조건화' 방식을 사용함. 이는 별도의 파인튜닝 없이, 특정 형식의 텍스트를 모델에 입력으로 제공하여 원하는 작업을 유도하는 것임. 예를 들어, 번역을 시키려면 "영어 문장 = 프랑스어 문장" 같은 예시를 프롬프트로 제공함. 이를 통해 단일 모델이 다양한 태스크를 제로샷으로 처리하게 됨.
문제: GPT-1과 비교했을 때, GPT-2 아키텍처의 사소한 수정 사항이 아닌 것은 무엇인가요?
정답: The model was changed from a decoder-only to an encoder-decoder architecture.
해설: GPT-1과 비교 시, GPT-2는 아키텍처의 근본적 변경 없이 사소한 수정만 이루어짐. 레이어 정규화 위치를 옮기고, 최종 셀프 어텐션 블록 뒤에 추가적인 레이어 정규화를 더했으며 어휘 크기도 확장됨. 하지만 디코더-온리 아키텍처는 그대로 유지되었으며, 인코더-디코더 구조로 변경하는 것과 같은 근본적인 변화는 없었음.
문제: GPT-2 논문에서 모델의 제로샷(zero-shot) 태스크 전이 성공에 가장 중요하다고 강조한 요소는 무엇인가요?
정답: The capacity of the language model
해설: GPT-2 논문에서 제로샷 태스크 전이 성공에 가장 중요하다고 강조한 요소는 '언어 모델의 용량(capacity)'임. 여기서 용량은 모델의 크기, 즉 파라미터 수를 의미하며 모델이 클수록 더 많은 지식과 패턴을 저장하고 일반화할 수 있음. 따라서 별도의 훈련 없이도 다양한 태스크를 수행하는 능력이 향상되며, 모델의 크기가 성능에 직결된다는 점을 시사함.
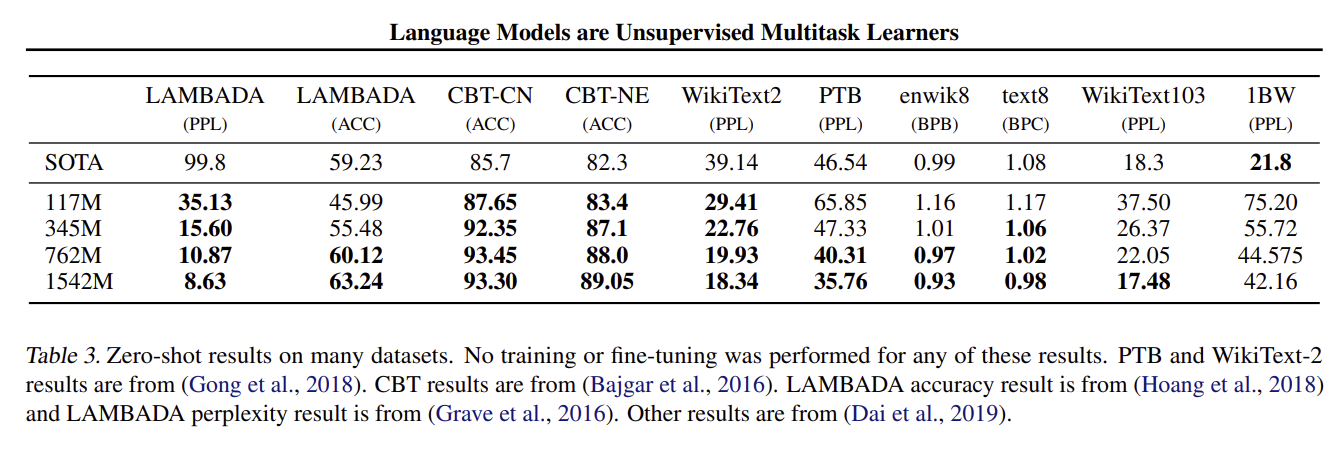
문제: GPT-2 모델의 가장 큰 버전은 몇 개의 파라미터를 가지고 있었나요?
정답: 1.5 Billion
해설: GPT-2 모델 중 가장 큰 버전은 15억(1.5 Billion)개의 파라미터를 가지고 있음. OpenAI는 117M, 345M, 774M, 1.5B 등 네 가지 크기의 모델을 공개했으며, 이 중 가장 큰 모델은 당시 기준으로 매우 큰 규모였음. 이 거대한 모델은 제로샷 환경에서 SOTA(state-of-the-art) 성능을 달성하는 데 핵심적인 역할을 수행함.
문제: WebText 데이터셋을 만들 때, 저자들이 데이터 품질을 위해 의도적으로 제외한 데이터 소스는 무엇인가요?
정답: Wikipedia pages
해설: WebText 데이터셋을 만들 때, 저자들은 데이터 품질과 공정한 평가를 위해 '위키피디아(Wikipedia) 페이지'를 의도적으로 제외함. 많은 기존 NLP 데이터셋이 위키피디아를 포함하고 있어, 평가 데이터셋과의 중복을 피하고 모델의 순수한 일반화 능력을 측정하려는 목적임. 이를 통해 WebText 데이터셋의 독창성과 데이터 품질을 높이고자 했음.
문제: 논문에서 번역 작업을 제로샷으로 수행하기 위해 모델에 어떤 형식의 프롬프트를 제공했나요?
정답: english sentence = french sentence
해설: 논문에서 번역 작업을 제로샷으로 수행하기 위해, 모델에 '영어 문장 = 프랑스어 문장' 형식의 예시를 프롬프트로 제공함. 이와 같은 예시를 몇 개 보여줌으로써 모델이 번역이라는 과업을 인지하고 수행하도록 유도함. 이는 명시적인 지시 없이 문맥을 통해 과제를 학습하는 GPT-2의 멀티태스크 능력을 보여주는 대표적인 사례임.
문제: GPT-2의 저자들이 가장 큰 모델의 공개를 처음에는 보류했던 주된 이유는 무엇인가요?
정답: Concerns about malicious use of the technology
해설: OpenAI가 처음 가장 큰 GPT-2 모델의 공개를 보류했던 주된 이유는 '기술의 악의적 사용에 대한 우려' 때문이었음. 가짜 뉴스 생성, 스팸, 피싱 등 사회에 해를 끼칠 수 있는 잠재적 위험성을 고려한 결정이었음. 이 결정은 AI 기술의 윤리적 책임과 안전한 배포에 대한 중요한 논의를 촉발시키는 계기가 되었음.
문제: GPT-2가 제로샷 환경에서 SOTA(state-of-the-art)를 달성했다고 보고된 태스크가 아닌 것은 무엇인가요?
정답: Question Answering (SQuAD-2)
해설: GPT-2는 여러 태스크에서 제로샷으로 SOTA를 달성했지만, 질의응답(Question Answering) 태스크인 'SQuAD 2.0'에서는 좋은 성능을 보이지 못했음. 논문에 따르면 GPT-2는 해당 태스크에서 약 5%의 정확도를 기록했는데, 이는 무작위 추측보다 약간 나은 수준에 불과했음. 이는 답이 없는 경우를 판단하는 능력이 부족했음을 보여줌.
문제: GPT-2의 문맥 창(context window) 크기는 몇 개의 토큰이었나요?
정답: 1024
해설: GPT-2의 문맥 창(context window) 크기는 '1024개 토큰'이었음. 이는 한 번에 모델이 고려할 수 있는 텍스트의 길이를 의미하며, GPT-1의 512개 토큰에서 두 배로 증가한 것임. 더 긴 문맥을 이해할 수 있게 되면서, 모델은 장기 의존성(long-range dependencies)을 더 잘 파악하고 복잡한 글을 이해하고 생성하는 능력이 향상되었음.
문제: 논문에서 "언어 모델은 비지도 멀티태스크 학습자"라고 말하는 것의 의미는 무엇인가요?
정답: The model learns to perform multiple tasks by simply predicting the next word on a large, varied dataset.
해설: '언어 모델은 비지도 멀티태스크 학습자'라는 말은 모델이 다음 단어를 예측하는 단순한 목표를 통해 여러 과제를 배운다는 의미임. 즉, 방대하고 다양한 데이터셋으로 훈련하면, 모델은 더 나은 예측을 위해 텍스트에 내재된 번역, 요약, 질의응답 등의 패턴을 스스로 학습함. 별도의 태스크 레이블 없이도 다재다능해진다는 개념임.
문제: GPT-2의 훈련 과정에서 초기화(initialization) 방식은 어떻게 수정되었나요?
정답: A modified initialization scaling weights by 1/√N was used, where N is the number of residual layers.
해설: GPT-2는 훈련 과정에서 초기화 방식을 수정하여, 잔차 레이어(residual layer)의 가중치를 초기화할 때 '1/√N'이라는 값을 곱하여 스케일을 조정함. 여기서 N은 잔차 레이어의 총 개수를 의미하며, 각 잔차 블록이 누적될 때 신호가 크게 변하는 것을 방지함. 이는 깊은 모델의 훈련 안정성을 높이는 데 기여함.
문제: GPT-2가 텍스트를 생성할 때, 어떤 현상을 제어하기 위해 Top-K 샘플링 같은 기법이 사용되었나요?
정답: The model getting stuck in repetitive loops
해설: GPT-2가 텍스트를 생성할 때 'Top-K' 샘플링 같은 기법을 사용하는 주된 이유는 모델이 의미 없는 '반복 루프'에 갇히는 현상을 제어하기 위함임. 언어 모델은 때때로 확률이 낮은 단어들을 선택하며 비논리적이거나 반복적인 텍스트를 생성할 수 있음. Top-K 샘플링은 확률이 가장 높은 K개의 단어 중에서만 다음 단어를 선택하여, 더 자연스러운 문장을 생성하도록 도움.
문제: 논문에 따르면, GPT-2는 WebText 데이터셋에 대해 과소적합(underfitting)되었나요, 아니면 과적합(overfitting)되었나요?
정답: It still underfit the dataset.
해설: 논문에 따르면, 가장 큰 GPT-2 모델조차도 WebText 데이터셋에 대해 '과소적합(underfitting)' 상태였음. 이는 모델이 훈련 데이터를 완전히 학습하지 못했으며, 모델의 용량을 더 키우거나 더 오래 훈련하면 성능이 더 향상될 여지가 있음을 의미함. 여러 태스크에서 SOTA를 달성했음에도, 훈련 데이터에 대해서는 아직 학습할 내용이 남아있다는 점이 인상적임.
GPT 3
Language Models are Few-Shot Learners
(언어 모델은 퓨샷 학습자)
# GPT-3의 '퓨샷 학습' 컨셉을 보여주는 예시 (OpenAI API 스타일)
# 상황: 영어 문장을 프랑스어로 번역하고 싶음
# 별도의 번역 모델을 학습시키는 대신, 프롬프트에 예시를 몇 개 넣어줌
prompt = """
Translate English to French:
sea otter => loutre de mer
peppermint => menthe poivrée
cheese =>
"""
# 위 프롬프트(입력)를 GPT-3 모델에 전달하면...
# 모델은 앞선 예시(sea otter, peppermint)의 패턴을 '문맥 안에서' 학습하여
# 'cheese'에 대한 프랑스어 번역 'fromage'를 출력함.
# 이처럼 별도 파인튜닝 없이, 예시 몇 개만으로 새로운 문제를 푸는 것이
# GPT-3의 핵심인 'In-context Few-shot Learning'.
문제: GPT-3 논문의 핵심적인 기여 또는 주장은 무엇인가요?
정답: That scaling up language models greatly improves task-agnostic, few-shot performance.
해설: GPT-3 논문의 핵심 주장은 언어 모델의 규모를 키우는 것이 과제에 구애받지 않는 '퓨샷(few-shot)' 성능을 크게 향상시킨다는 것임. 이는 모델의 크기가 커질수록 별도의 파인튜닝 없이, 단 몇 개의 예시만으로 새로운 과제를 학습하고 수행하는 능력이 비약적으로 발전함을 의미함. 때로는 기존의 파인튜닝 기반 SOTA 모델과 경쟁할 만한 수준에 도달하기도 함.
문제: GPT-3에서 소개된, 모델의 가중치를 업데이트하지 않고 태스크를 학습하는 능력은 무엇이라고 불리나요?
정답: In-context learning
해설: GPT-3에서 소개된, 모델의 가중치를 업데이트하지 않고 과제를 학습하는 능력은 '인컨텍스트 러닝(In-context learning)'이라고 불림. 이는 모델이 추론 시점에 프롬프트의 문맥으로 주어진 예시나 설명을 통해 일시적으로 과제를 파악하고 수행하는 능력임. 기존의 그래디언트 업데이트 기반 학습과 달리, 별도의 훈련 과정 없이 즉각적으로 새로운 태스크에 적응함.
문제: GPT-3의 가장 큰 모델은 몇 개의 파라미터를 가지고 있나요?
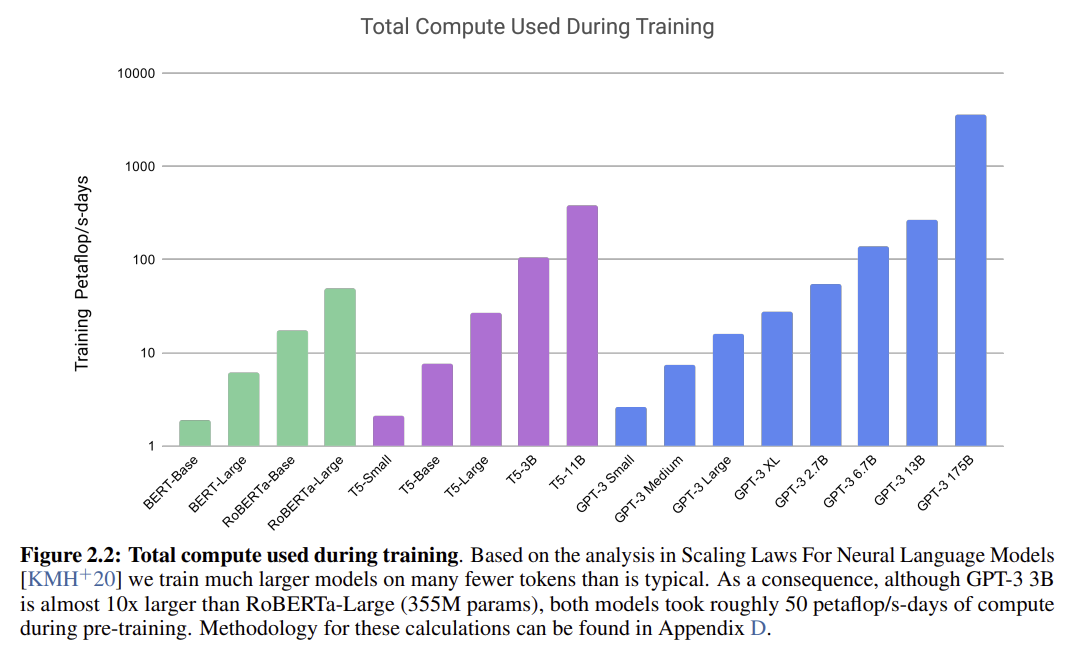
정답: 175 Billion
해설: GPT-3의 가장 큰 모델은 1,750억(175 Billion)개의 파라미터를 가지고 있음. 이는 이전의 어떤 비-희소(non-sparse) 언어 모델보다 10배 이상 큰 규모임. 이 엄청난 크기는 GPT-3가 퓨샷 학습에서 뛰어난 성능을 보이는 핵심적인 이유 중 하나로 꼽힘. 모델의 용량(capacity)이 클수록 더 많은 지식과 패턴을 학습하고 일반화할 수 있기 때문임.
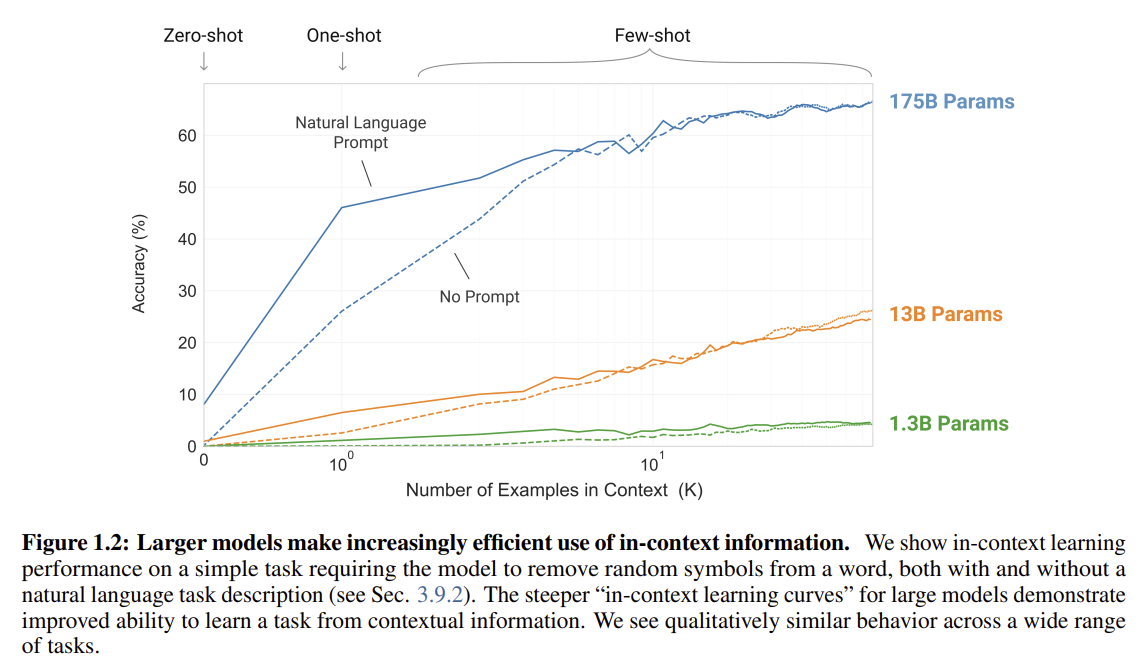
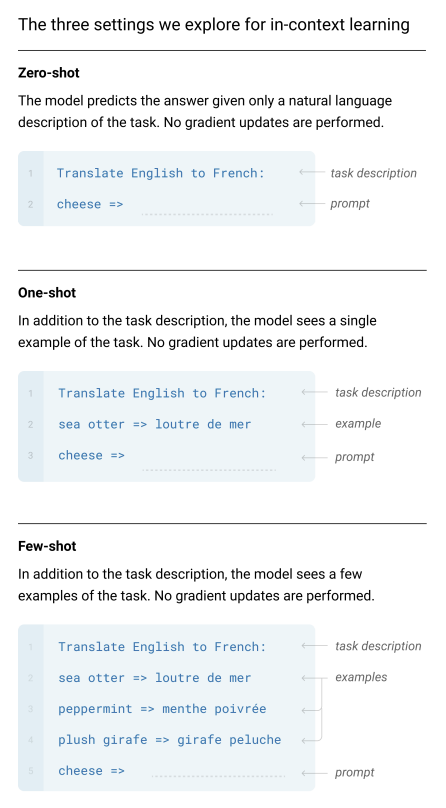
문제: "Few-shot", "One-shot", "Zero-shot" 학습의 차이점은 무엇인가요?
정답: The number of examples provided in the context window.
해설: '퓨샷', '원샷', '제로샷' 학습의 차이점은 추론 시점에 모델의 컨텍스트 창(프롬프트)에 제공되는 예시(demonstration)의 개수임. 제로샷은 아무런 예시 없이 과제 설명만으로 문제를 풀게 하는 방식임. 원샷은 단 하나의 예시를 제공하며, 퓨샷은 몇 개(일반적으로 10~100개)의 예시를 제공하여 모델이 과제를 더 잘 이해하도록 도움.
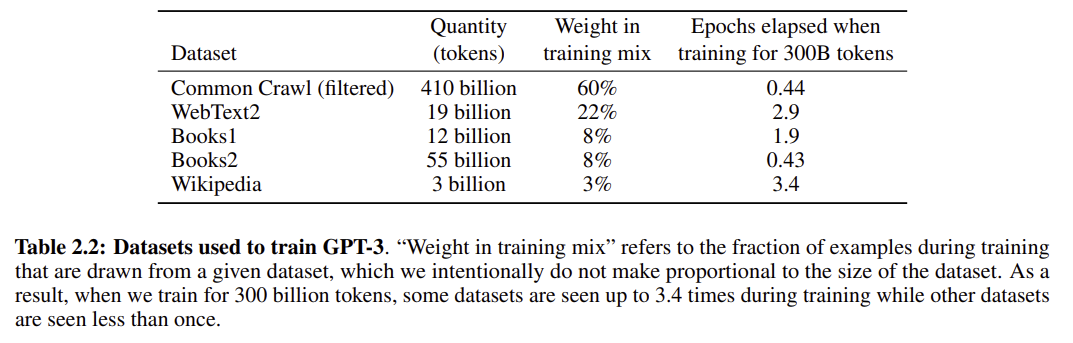
문제: GPT-3의 훈련 데이터셋에서 가장 큰 비중을 차지한 것은 무엇인가요?
정답: A filtered version of Common Crawl
해설: GPT-3 훈련 데이터셋에서 가장 큰 비중(60%)을 차지한 것은 필터링된 '커먼 크롤(Common Crawl)' 데이터임. 커먼 크롤은 웹 전체에서 수집한 방대한 텍스트 데이터이지만 품질이 고르지 않은 단점이 있어, OpenAI는 고품질 문서 선별 모델을 개발하여 데이터셋을 정제한 후 훈련에 사용함. 이 외에도 WebText2, Books, Wikipedia 등이 데이터에 포함됨.
문제: GPT-3 아키텍처는 GPT-2와 비교하여 근본적으로 어떻게 다른가요?
정답: It uses the same architecture as GPT-2 but is scaled up significantly.
해설: GPT-3의 아키텍처는 GPT-2와 근본적으로 동일하며, 이를 매우 큰 규모로 확장(scale-up)한 것임. 논문에서 일부 희소(sparse) 어텐션 패턴 사용을 언급했지만 이는 실험적 부분이며 핵심 구조는 동일함. 즉, 새로운 아키텍처 도입보다는 기존의 검증된 디코더-온리 트랜스포머 구조를 파라미터, 데이터셋, 모델 크기 면에서 극적으로 키운 것임.
문제: 논문에서 GPT-3가 어려움을 겪었다고 언급한 태스크 유형이 아닌 것은 무엇인가요?
정답: Generating news articles that are hard to distinguish from human-written ones.
해설: 논문에 따르면 GPT-3는 인간이 쓴 기사와 구별하기 어려운 '뉴스 기사 생성'에 탁월한 능력을 보였음. 반면, 자연어 추론(NLI) 태스크나 일부 상식 추론, 독해력 문제에서는 어려움을 겪는다고 언급됨. 이는 GPT-3가 유창하고 일관성 있는 텍스트 생성 능력은 뛰어나지만, 복잡한 논리적 추론이나 깊은 의미 이해가 필요한 과제에서는 여전히 한계를 보임을 시사함.
문제: GPT-3의 훈련 데이터셋 품질을 높이기 위해 Common Crawl 데이터에 어떤 처리를 했나요?
정답: They developed a model to filter for higher quality content.
해설: GPT-3의 훈련 데이터 품질을 높이기 위해, 방대한 양의 커먼 크롤(Common Crawl) 데이터에 특별한 필터링 처리를 했음. 이를 위해 고품질 문서를 참조 데이터셋으로 사용하여, 문서의 품질을 분류하는 모델을 먼저 훈련시킴. 그 후, 이 분류 모델을 이용해 전체 커먼 크롤 데이터에서 품질이 높은 것으로 예측되는 문서들만 샘플링하여 훈련에 사용함.
문제: GPT-3가 보여준 '즉석 추론' 또는 '빠른 적응' 능력의 예시로 논문에서 언급된 것은 무엇인가요?
정답: Performing 3-digit arithmetic.
해설: 논문에서 GPT-3가 보여준 '즉석 추론' 또는 '빠른 적응' 능력의 예시로 '세 자리 숫자 산술 연산 수행'이 언급됨. 이는 모델이 퓨샷 또는 원샷 프롬프트로 주어진 몇 개의 예시만 보고도 덧셈, 뺄셈과 같은 규칙을 즉석에서 학습하고 적용하는 능력을 보여줌. 이 외에도 단어의 철자 바꾸기, 문장에서 새로운 단어 사용하기 등도 예시로 제시됨.
문제: GPT-3의 훈련 데이터셋에는 왜 중복 제거(de-duplication) 과정이 포함되었나요?
정답: To prevent contamination of the held-out validation sets and ensure fair evaluation.
해설: GPT-3의 훈련 데이터셋에 중복 제거 과정이 포함된 주된 이유는 '공정한 평가를 보장하기 위함'임. 만약 훈련 데이터에 평가(test) 데이터가 포함되어 있다면, 모델은 문제를 푸는 것이 아니라 정답을 외워서 맞히게 됨. 이러한 '데이터 오염(contamination)'을 방지하기 위해, 모든 벤치마크의 평가 세트와 겹치는 부분을 훈련 데이터에서 제거하는 작업을 수행함.
문제: GPT-3 모델 제품군에서 가장 큰 모델(175B)의 API 이름은 무엇이었나요?
정답: Davinci
해설: GPT-3 모델 제품군 중 가장 큰 175B 파라미터 모델의 초기 API 이름은 '다빈치(Davinci)'였음. OpenAI는 GPT-3 모델들을 크기와 성능에 따라 여러 등급으로 나누어 API를 제공했음. 다빈치는 가장 강력한 성능을 제공하는 최상위 모델이었으며, 그 아래로 큐리(Curie), 배비지(Babbage), 에이다(Ada) 등이 있었음.
퀴문제: GPT-3의 문맥 창(context window) 크기는 몇 개의 토큰이었나요?
정답: 2048
해설: GPT-3의 모든 모델은 '2048 토큰'의 문맥 창(context window) 크기를 사용함. 이는 GPT-2의 1024 토큰보다 두 배 확장된 크기로, 모델이 한 번에 더 긴 텍스트를 보고 이해할 수 있게 해줌. 더 넓은 문맥 창은 모델이 글의 전체적인 흐름과 장기적인 의존성을 파악하는 데 도움을 주어, 더 일관성 있고 맥락에 맞는 텍스트를 생성하는 데 중요한 역할을 함.
문제: 논문에서는 GPT-3의 어떤 한계점을 명시적으로 언급했나요?
정답: Its performance on text synthesis can degrade over long passages, repeating itself.
해설: 논문에서 명시적으로 언급한 GPT-3의 한계점 중 하나는 긴 글을 생성할 때 성능이 저하될 수 있다는 것임. 구체적으로, 긴 구절에 걸쳐 내용의 일관성이 깨지거나, 특정 문구나 문장을 계속해서 '반복하는 루프'에 빠지는 현상이 나타날 수 있음. 이는 모델이 텍스트를 순차적으로 생성하면서 앞선 내용을 점차 잊어버리기 때문에 발생하는 문제로 추정됨.
문제: GPT-3가 파인튜닝(fine-tuning) 없이도 다양한 작업을 수행할 수 있다는 발견이 시사하는 바는 무엇인가요?
정답: That a single, large-scale model can be a general-purpose NLP solution.
해설: GPT-3가 파인튜닝 없이도 다양한 작업을 수행할 수 있다는 발견은 '단일 대규모 모델이 범용 NLP 솔루션이 될 수 있음'을 시사함. 이는 특정 과제마다 별도의 모델을 만들고 파인튜닝해야 했던 기존 패러다임에서 벗어날 가능성을 보여줌. 즉, 매우 큰 모델 하나를 만들어두면, 사용자가 원하는 다양한 태스크를 즉석에서 처리할 수 있는 강력한 언어 처리 시스템의 개발 방향을 제시함.
문제: 논문에 따르면, GPT-3의 훈련에 사용된 최적화(optimizer) 알고리즘은 무엇이었나요?
정답: Adam
해설: 논문에 따르면, GPT-3 훈련에 사용된 최적화(optimizer) 알고리즘은 '아담(Adam)'임. 아담은 딥러닝에서 널리 사용되는 최적화 기법으로, 각 파라미터마다 다른 학습률을 적용하여 효율적이고 안정적인 학습을 가능하게 함. 논문에서는 구체적으로 β1 = 0.9, β2 = 0.95, ε = 10−8의 하이퍼파라미터 설정을 사용했다고 명시함.
