개인적으로 평가지표가 제일 어렵다. 수학을 모르니 어쩔 수 없는 일인 듯하다. 갈 길이 멀다.
학습시간 09:00~03:00(당일18H/누적1369H)
◆ 학습내용
어제에 이어 6번 부터 시작!
6. 평가지표 종류
어제 학습이 끝나고 드디어 평가를 할 차례다.
평가는 총 2단계로, 지표와 육안으로 평가할 예정이다.
이번에 ROUGE?라는 평가 지표를 이용하라고 하는데,, 지난 번 미션도 그렇고, 지표에 대한 이해도가 없으니 뭐가 뭔지 모르겠다. 일단 지표 공부를 좀 해야겠다.
(1) ROUGE
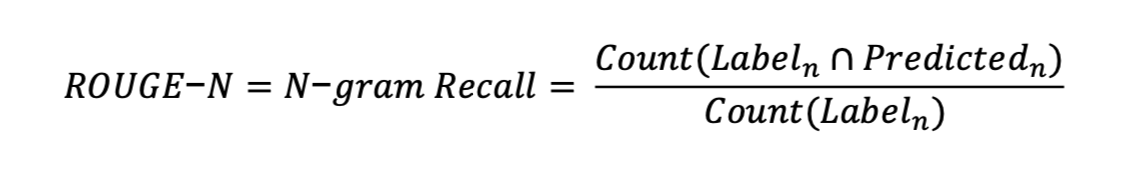
Recall-Oriented Understudy for Gisting Evaluation. 자연어 처리 모델 중 주로 텍스트 요약의 성능을 확인할 때 자주 쓰이는 지표다.
Recall(재현율) 기반으로, 정답 요약문에 있는 단어(n-gram)가 모델이 생성한 요약문에 얼마나 포함되었는지 측정한다.
하위 지표로는 ROUGE 1, 2, L 이 있다.
정답의 핵심 내용이 빠짐없이 포함되었는지 확인하는 데 강점이 있다.
(2) BLEU

Bilingual Evaluation Understudy. ROUGE가 Recall(재현율) 기반의 평가지표이라면, BLEU는 Precision(정밀도) 기반의 지표다.
원래 기계 번역(Machine Translation) 성능 평가를 위해 만들어졌다.
모델이 만들어낸 표현이 정답과 얼마나 유사한지, 문법적으로 자연스러운지 확인하는 데 좋다.
(3) METEOR
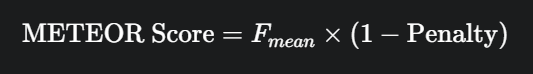
Metric for Evaluation of Translation with Explicit ORdering. Precision과 Recall의 조화 평균을 사용한다.
단순히 단어가 같은지만 보는 게 아니라, 동의어, 형태소(어근)까지 고려해서 평가한다. ('run'과 'running'을 같게 봄)
BLEU나 ROUGE보다 인간의 평가와 상관관계가 더 높다고 알려져 있다.
형태나 동의어까지 고려하는 똑똑한 지표라서, 좀 더 유연하고 의미 중심으로 평가하고 싶을 때 좋다.
(4) BERTScore
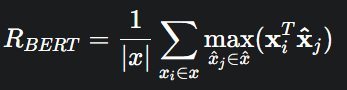
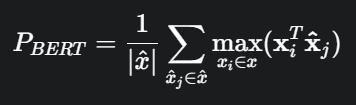
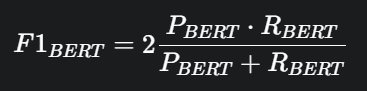
최신 트렌드! BERT 같은 언어 모델을 활용해서 문장의 문맥적 의미(Contextual Meaning)를 직접 비교하는 방식이다.
단어 임베딩 벡터 간의 코사인 유사도를 계산하여 의미적 유사도를 측정한다.
"학생이 공부한다"와 "학자가 연구한다"처럼 단어는 다르지만 의미가 유사한 문장을 잘 잡아낸다.
인간의 판단과 가장 유사한 결과를 보이지만, 계산 비용이 높은 게 흠이다.
7. 모델 평가
BERTScore는 너무 복잡해서 못하겠고,,, ROUGE, BLEU, METEOR 이 3개를 비교해 보면 좋을 것 같다.
def evaluate_model(model, tokenizer, df, device, num_samples=1):
rouge_metric = evaluate.load('rouge')
bleu_metric = evaluate.load('bleu')
meteor_metric = evaluate.load('meteor')
sample_df = df.head(num_samples)
all_predictions = []
all_references = []평가용 함수를 만들었다. 원본, 정답 샘플, 모델 생성 샘플 이렇게 출력 후에 평가지표 점수를 나타내면 좋을 것 같다!
for index, row in sample_df.iterrows():
text = row['text']
reference_summary = row['abstractive']
inputs = tokenizer(text, return_tensors="pt", max_length=1024, truncation=True).to(device)
summary_ids = model.generate(
inputs.input_ids, num_beams=4, max_length=128, early_stopping=True
)
generated_summary = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
all_predictions.append(generated_summary)
all_references.append(reference_summary)valid set 샘플을 돌면서 요약본을 생성해 주고,
# 샘플 텍스트 비교
print("\n──────────────────────────────")
print(f"[ Sample # {index+1}. ]")
print(f"[원문 일부]: {text[:200]}...")
print(f"[정답 요약]: {reference_summary}")
print(f"[생성 요약]: {generated_summary}")
# 샘플 점수
individual_rouge = rouge_metric.compute(predictions=[generated_summary], references=[reference_summary])
individual_bleu = bleu_metric.compute(predictions=[generated_summary], references=[[reference_summary]])
individual_meteor = meteor_metric.compute(predictions=[generated_summary], references=[reference_summary])
print(f"{'ROUGE-L'.ljust(9)}: {individual_rouge['rougeL'] * 100:<10.2f}")
print(f"{'BLEU'.ljust(9)}: {individual_bleu['bleu'] * 100:<10.2f}")
print(f"{'METEOR'.ljust(9)}: {individual_meteor['meteor'] * 100:<10.2f}")육안으로 비교할 수 있도록 샘플을 나열하고 3개 지표를 출력한다.
print("\n──────────────────────────────")
print("[ Total Score ]")
print(f"{'ROUGE-1'.ljust(9)}: {final_rouge['rouge1'] * 100:<10.2f}")
print(f"{'ROUGE-2'.ljust(9)}: {final_rouge['rouge2'] * 100:<10.2f}")
print(f"{'ROUGE-L'.ljust(9)}: {final_rouge['rougeL'] * 100:<10.2f}")
print(f"{'BLEU'.ljust(9)}: {final_bleu['bleu'] * 100:<10.2f}")
print(f"{'METEOR'.ljust(9)}: {final_meteor['meteor'] * 100:<10.2f}")마지막으로 진행한 모든 샘플의 스코어 총합을 출력한다.
loaded_model = AutoModelForSeq2SeqLM.from_pretrained("kobart_best_model").to(device)
loaded_tokenizer = AutoTokenizer.from_pretrained("kobart_best_model")
evaluate_model(
model=loaded_model,
tokenizer=loaded_tokenizer,
df=valid_df,
device=device,
num_samples=3
)저장해주었던 모델이랑 토크나이저를 로드 후에 함수를 실행한다.

넘 길어서 텍스트가 짤리네
1번 샘플은 아래와 같다.
[원문 일부]: [1] 취소소송은 처분 등이 있음을 안 날부터 90일 이내에 제기하여야 하고, 처분 등이 있은 날부터 1년을 경과하면 제기하지 못하며( 행정소송법 제20조 제1항, 제2항), 청구취지를 변경하여 구 소가 취하되고 새로운 소가 제기된 것으로 변경되었을 때에 새로운 소에 대한 제소기간의 준수 등은 원칙적으로 소의 변경이 있은 때를 기준으로 하여야 한다....
[정답 요약]: 취소소송은 처분 등이 있다는 것을 안 때로부터 90일 이내에 제기하여야 하고, 행정처분에서의 허가에 붙은 기한이 부당하게 짧은 경우에는 이를 허가조건 존속기간으로 보아서 그 기한의 도래로 조건 개정을 고려한다고 해석할 수 있기에, 사도개설허가의 준공검사를 받지 못한 것은 사도개설허가 자체의 존속기간으로 볼 수 없다는 까닭으로 이것이 실효되는 것은 아니다.
[생성 요약]: 취소소송은 처분 등이 있음을 안 날부터 90일 이내에 제기하여야 하고, 처분 등이 있은 날부터 1년을 경과하면 제기하지 못하며, 구 소가 취하되고 새로운 소가 제기된 것으로 변경되었을 때에 새로운 소에 대한 제소기간의 준수 등은 원칙적으로 소의 변경이 있은 때를 기준으로 해야 한다.
흠 법률용어를 모르니 이게 잘 요약된 것인지 모르겠다 ㅋ
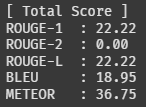
3개 샘플에 대한 토탈 스코어다.
ROUGE2는 왜 0점이지,,
이게 만점이 100점이라고 하던데, 그럼 아주 형편 없는 수준이라는 뜻이다.
그래도 METEOR에서는 36점이 나왔다. 에폭을 조금 더 돌리면 점수가 좋아지려나??
마침 주말이니 시간을 내서 10에폭 정도 돌린 다음 다시 평가해 봐야겠다.
