허깅페이스는 신이 내린 선물입니다.
학습시간 09:00~03:00(당일18H/누적1351H)
◆ 학습내용
어제 1~2번에 이어 3번 부터 시작!
3. transformers 라이브러리
이번 미션은 왠지 내가 직접 무언가를 구현해 보라는 느낌보다는 허깅페이스와 친해지라는 느낌이다. 그래서 조금 더 공부하고 시작해 보자.
허깅페이스 핵심 내용 30선!
| 용어 | 설명 | 호출 예시 |
|---|---|---|
| BERT | 양방향 인코더 구조의 대표 모델 | AutoModel.from_pretrained('bert-base-cased') |
| GPT | 디코더 구조의 대표 모델 | AutoModelForCausalLM.from_pretrained('gpt2') |
| T5 | 인코더-디코더 구조의 텍스트-투-텍스트 모델 | AutoModelForSeq2SeqLM.from_pretrained('t5-small') |
| BART | 손상된 텍스트 복원 방식으로 학습하는 모델 | AutoModelForSeq2SeqLM.from_pretrained('facebook/bart-base') |
| RoBERTa | BERT의 학습을 최적화하여 성능을 높인 모델 | AutoModel.from_pretrained('roberta-base') |
| DistilBERT | BERT를 증류하여 만든 경량화 모델 | AutoModel.from_pretrained('distilbert-base-uncased') |
| ELECTRA | 효율적인 사전 학습 방식의 판별자 모델 | AutoModel.from_pretrained('google/electra-small-discriminator') |
| XLM-RoBERTa | 100개 이상의 언어를 지원하는 다국어 모델 | AutoModel.from_pretrained('xlm-roberta-base') |
| PEGASUS | 추상적 문장 요약에 특화된 모델 | AutoModelForSeq2SeqLM.from_pretrained('google/pegasus-xsum') |
| ViT | 이미지를 위한 트랜스포머 아키텍처 | AutoModel.from_pretrained('google/vit-base-patch16-224') |
| Wav2Vec2 | 음성 인식을 위한 트랜스포머 모델 | AutoModel.from_pretrained('facebook/wav2vec2-base-960h') |
| CLIP | 텍스트와 이미지를 연결하는 멀티모달 모델 | AutoModel.from_pretrained('openai/clip-vit-base-patch32') |
| pipeline | 가장 간단하게 모델 추론을 수행하는 API | pipeline('sentiment-analysis', model='distilbert-base-uncased') |
| AutoModel | 모델 이름을 기반으로 아키텍처를 자동 추론 | from transformers import AutoModel |
| AutoTokenizer | 모델에 맞는 토크나이저를 자동으로 로드 | AutoTokenizer.from_pretrained('bert-base-cased') |
| Tokenizer | 텍스트를 모델이 이해하는 숫자 ID로 변환 | tokenizer.encode("안녕하세요") |
| Configuration | 모델의 구조(레이어 수 등)를 정의하는 설계도 | AutoConfig.from_pretrained('bert-base-cased') |
| Trainer | 모델의 파인튜닝 과정을 자동화하는 클래스 | Trainer(model=model, args=args, train_dataset=ds) |
| TrainingArguments | Trainer의 학습 옵션을 상세하게 설정 | TrainingArguments(output_dir='./results', per_device_train_batch_size=8) |
| Model Card | 모델의 정보를 담고 있는 문서 | # 허깅페이스 허브의 모델 페이지에서 'Model card' 탭 확인 |
| datasets | 허브의 데이터셋을 로드하고 처리하는 라이브러리 | from datasets import load_dataset; ds = load_dataset('squad') |
| evaluate | 모델 성능 평가 지표를 로드하는 라이브러리 | import evaluate; accuracy = evaluate.load('accuracy') |
| accelerate | 코드 변경을 최소화하며 분산 학습을 지원 | from accelerate import Accelerator; accelerator = Accelerator() |
| Hugging Face Hub | 모델/데이터셋을 공유하는 중앙 저장소 | from huggingface_hub import HfApi; api = HfApi() |
| Spaces | 모델의 인터랙티브 데모를 호스팅하는 서비스 | # Gradio/Streamlit 코드를 작성하여 허브의 'Spaces'에 업로드 |
| Gradio | 인터랙티브 머신러닝 데모 UI를 만드는 라이브러리 | import gradio as gr; gr.Interface(fn=greet, ...).launch() |
| Safetensors | 안전하고 빠른 모델 가중치 저장 파일 형식 | model.save_pretrained('./dir', safe_serialization=True) |
| Text Classification | 문장의 클래스를 분류하는 작업 | pipeline('text-classification') |
| Named Entity Recognition | 텍스트에서 인명, 지명 등 개체명을 식별 | pipeline('ner') |
| Fine-Tuning | 사전 학습된 모델을 특정 작업에 맞게 미세조정 | trainer = Trainer(...); trainer.train() |
딱 봐도 신기해 보이는 기능이 잔뜩 있다.
근데 이렇게 다 준비되어 있으면 인공지능 개발자가 왜 필요하지...?
4. 전처리
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from datasets import Dataset
# 모델 & 토크나이저 로드
tokenizer = AutoTokenizer.from_pretrained("gogamza/kobart-summarization")
model = AutoModelForSeq2SeqLM.from_pretrained("gogamza/kobart-summarization")
# 데이터셋 준비
train_dataset = Dataset.from_pandas(train_df)
valid_dataset = Dataset.from_pandas(valid_df)일단 오토토크나이저, 오토모델을 불러온다. 역시 이름에 오토가 붙으면 참 믿음직스럽단말이지.
그리고 tokenizer, model로 초기화를 해줬다.
사용한 모델은 gogamza/kobart-summarization 이다. 이번에 bart 모델을 해보려고 하는데, 이게 bart전용 요약 모델이라고 한다.
이름도 참 제멋대로 해놨는데 종류도 많으니 어디서 찾아야할지도 모르겠다...
train_json, train_df = load_json("data/train_original_law.json")
valid_json, valid_df = load_json("data/valid_original_law.json")그리고 마지막으로 EDA할 때 만들었던 함수를 조금 변경해서 train, valid의 데이터프레임을 생성한다.
아무래도 transformer 라이브러리는 df를 기준으로 전처리를 하는 것 같다.
def preprocess(documents):
# 원문 토큰화
model_inputs = tokenizer(
text=documents["text"],
max_length=1024,
truncation=True,
padding="max_length"
)
# 요약문 토큰화
labels = tokenizer(
text_target=documents["abstractive"],
max_length=128,
truncation=True,
padding="max_length"
)
model_inputs["labels"] = labels["input_ids"]
return model_inputs다음은 토큰화 하는 함수다. 이 함수 하나로 토큰화가 끝난다니,,, 난 지금까지 뭘 배운거지???
어쨌든, JSON 파일 내부에 있었던 text 노드와 abstractive 노드를 학습시켜야 한다. 역시 이 둘의 상관관계를 구하는 게 정답인가 보군.
length는 토큰의 수다. 1024토큰은 128토큰으로 약 9배 요약하는 셈이다.
# 데이터셋 생성
tokenized_train_dataset = train_dataset.map(
preprocess,
batched=True,
remove_columns=train_dataset.column_names
)
tokenized_valid_dataset = valid_dataset.map(
preprocess,
batched=True,
remove_columns=valid_dataset.column_names
)
# 확인
print(tokenized_train_dataset[0])Dataset 이라는 짱짱 라이브러리를 사용해서 데이터프레임과 토크나이저 함수를 묶어준다.

27000개 데이터를 전처리하는데 13초 걸렸다. 이정도면 120만 개도 금방 하겠는데...? 난 지금까지 뭘 배운 거지....?
{'input_ids': [14145, 19252, 15497, 24645, 26670, ..., 3, 3, 3, 3, 3, 3], 'attention_mask': [1, 1, 1, 1, ..., 0, 0, 0, 0, 0, 0, ..., 0, 0, 0], 'labels': [14145, 19252, 1700, 14053, 9879, 14330, 14183, 14573, 10667, 9714, 17195, ..., 3, 3, 3, 3, 3, 3, 3, ..., 3]}
0번 인덱스를 열어보니 이런 결과물이 나왔다. input_ids, attention_mask, labels으로 이루어진 데이터셋이다.
이걸 바로 모델에 넣으면 되는 건가?? 데이터로더는 안 만드는 건가??
허깅페이스를 사용하니까 그동안 내가 해온 절차가 너무 간소화되니 넘 당황스럽다.
5. 모델 학습
벌써 학습이라니...
from transformers import Trainer, TrainingArguments
import torch
def train_model(model, tokenizer, train_dataset, eval_dataset, model_output_path):
training_args = TrainingArguments(
output_dir=model_output_path,
num_train_epochs=2,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
warmup_steps=500,
weight_decay=0.01,
logging_dir=f"{model_output_path}/logs",
logging_steps=1000,
evaluation_strategy="steps",
eval_steps=1000,
save_strategy="steps",
save_steps=500,
load_best_model_at_end=True,
save_total_limit=2,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
)
trainer.train()
trainer.save_model(model_output_path)이것도 transformers 라이브러리에서 모듈 2개를 불러와서 함수 형태로 만들었다.
살짝 욜로 모델 돌리는 것과 비슷한 느낌이다.
train_model(
model=model,
tokenizer=tokenizer,
train_dataset=tokenized_train_dataset,
eval_dataset=tokenized_valid_dataset,
model_output_path="./kobart_best_model"
)가중치 저장할 경로를 셋팅 후 함수를 실행해준다.

에러가 떴다. evaluation_strategy 라는 아규먼트는 없다고 한다.
!pip install --upgrade transformers
transformers 버전이 낮은 건가 싶어서 재설치 했다.

똑같은 에러가 뜬다. 뭐가 문제지..?
evaluation_strategy="steps", 이 부분이 문제인 것 같은데,,,
주석처리하고 다시 실행해보자!
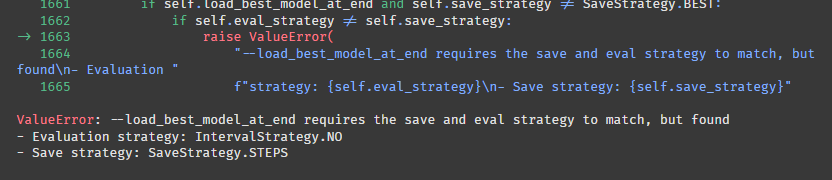
또 에러가 떴다.
- Evaluation strategy: IntervalStrategy.NO
- Save strategy: SaveStrategy.STEPS
이 두 strategy가 match해야 하는데 달라서 생긴 문제라고 한다.
평가와 저장이라,,, 내가 뭘 잘못 설정했나?
training_args = TrainingArguments(
output_dir=model_output_path,
num_train_epochs=2,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
warmup_steps=500,
weight_decay=0.01,
logging_dir=f"{model_output_path}/logs",
logging_steps=1000,
#evaluation_strategy="steps",
eval_steps=1000,
save_strategy="steps",
save_steps=1000,
load_best_model_at_end=True,
save_total_limit=2,
)eval step과 save step을 1000으로 동일하게 변경했다.

똑같은 에러가 뜬다.
eval_strategy="steps",
eval_steps=1000,
save_strategy="steps",
save_steps=1000,evaluation_strategy -> eval_strategy로 변경했다.

어! 이번엔 에러가 아니라 API를 입력하라고 뜬다. 허깅페이스도 API를 연동해서 써야하는 건가?
잠시 찾아보니 wandb 홈페이지에 연결해서 내 학습 정보를 저장할 수 있는 것 같다.
저장할 필요가 없을 시 report_to="none" 코드 한 줄만 추가하면 해결된다고!!

드디어... 된다!!!! 2에폭 설정했는데 30분 정도 걸리는 것 같다. 그럼 4에폭에 1시간 40에폭에 10시간,,,,,,,
일단 2에폭으로 평가까지 해보고 나중에 생각하자.
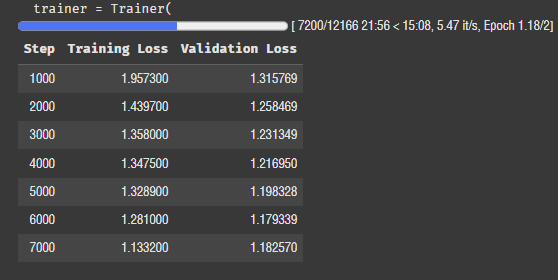
로스가 점점 낮아진다. tqdm보다 저 그래프 막대기가 훨씬 보기 좋은 것 같다. 데이터프레임으로 결과가 출력되는 것도 참 좋네. 어떻게 설정하는 거지..? 메모해뒀다가 나중에 꼭 찾아봐야지!!
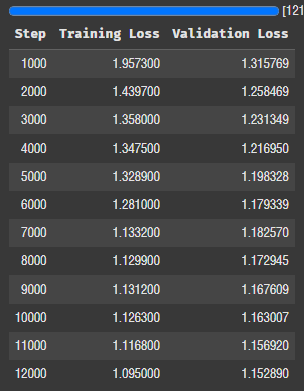
2에폭 학습이 끝났다. 흐름을 보니 더 돌리면 로스가 1 이하로 떨어질 것 같긴 하다.
There were missing keys in the checkpoint model loaded: ['model.encoder.embed_tokens.weight', 'model.decoder.embed_tokens.weight', 'lm_head.weight'].
뭐 이런 에러가 떴는데,,, 무시해도 되는 거겠지..?
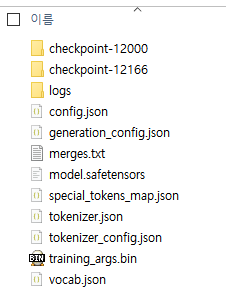
폴더를 확인해 보니 다양한 파일이 들어가 있다.
model.safetensors 이게 용량이 제일 큰 걸 보니 가중치 본체인 것 같다.
내일은 이걸로 평가해봐야지!!
