텍스트 데이터는 머신런닝 때 배운 데이터프레임 지식을 이용할 수 있어서 좋다. 역시 다 쓸모가 있구만!
학습시간 09:00~03:00(당일18H/누적1444H)
◆ 학습내용
감성 분석 AI 구현하기!
내용
- 패션, 화장품, 가전, IT기기, 생활 5가지 분야에 대한 쇼핑몰과 SNS 리뷰
- 쇼핑몰 리뷰 데이터 감성 분석
- Full Fine-Tuning & PEFT 활용 후 차이점 확인
데이터
- JSON 파일 하나에 여러 개의 리뷰가 포함
- RawText: 리뷰 텍스트
- GeneralPolarity: 긍부정 라벨(부정=-1, 중립=0, 긍정=1)
가이드
- 감성 분석 모델을 학습시키기 위한 형식으로 적절하게 변환
- 전체 데이터를 학습 데이터와 테스트 데이터로 분할
- transformers 라이브러리로 Full Fine-Tuning
- peft 라이브러리로 PEFT
- Full Fine-Tuning과 PEFT 방식 비교 분석 및 제출
1. 데이터 준비

이번 미션에 사용할 데이터다. 폴더명에서 느껴지듯 부정적인 리뷰인지 긍정적인 리뷰인지 분류하는 작업이다.
쇼핑몰 폴더에는 생활 카테고리가 없다.
대신 쇼핑몰 폴더에는 하위 폴더가 하나씩 더 있다. JSON 파일이 위치한 디렉토리의 깊이가 달라서, 먼저 이를 하나의 폴더나 파일로 다 모아줄 필요가 있을 것 같다.
일단 JSON 파일 내부 모습을 봐야할 것 같다.
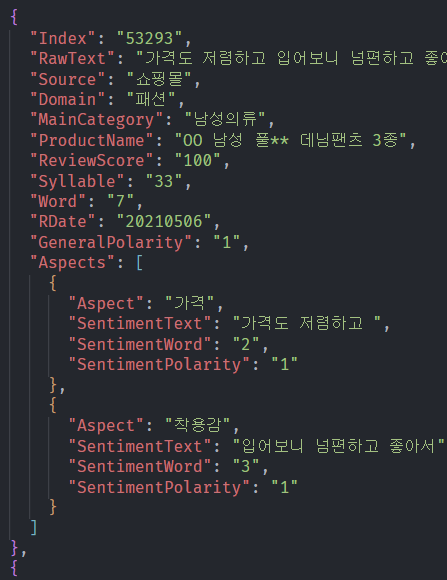
다행이도 SNS, 쇼핑몰 폴더에 있는 JSON 파일의 구조 자체는 큰 차이가 없는 듯 보인다. 쇼핑몰에는 ReviewScore와 RDate라는 항목이 추가로 있는데, 어차피 감성만 분석하면 되니까 필요 없을 것 같다.
핵심 키값은 RawText, GeneralPolarity로 보인다. EDA를 위해서 Source, Domain, MainCategory, Syllable 까지 취합하면 될 것 같다.
def load_json(load_dir, save_dir):
if not os.path.exists(save_dir):
os.makedirs(save_dir)
target_columns = {
'RawText' : 'text',
'Source' : 'source',
'Domain' : 'domain',
'MainCategory' : 'category',
'GeneralPolarity' : 'label',
'Syllable' : 'length'
}파일을 취합하기 위한 함수를 만들었다. 저렇게 6개 컬럼 제외하곤 다 버릴 예정이다.
편의상 일부를 내가 이해하기 쉬운 단어로 바꾸고 전부 소문자로 통일했다.
all_reviews = []
for dir in load_dir:
json_files = glob(os.path.join(dir, '**', '*.json'), recursive=True)
for file_path in tqdm(json_files, desc=f"Loading '{dir}'"):
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
for review in data:
d = {new: review.get(old) for old, new in target_columns.items() if old in review}
all_reviews.append(d)
df = pd.DataFrame(all_reviews)
return df모든 파일을 돌면서 JSON 파일을 all_reviews 리스트에 저장한다음 데이터프레임으로 변환했다.
df = load_json(['./data/SNS/', './data/쇼핑몰/'], './data')
df.head()확인해 보자!
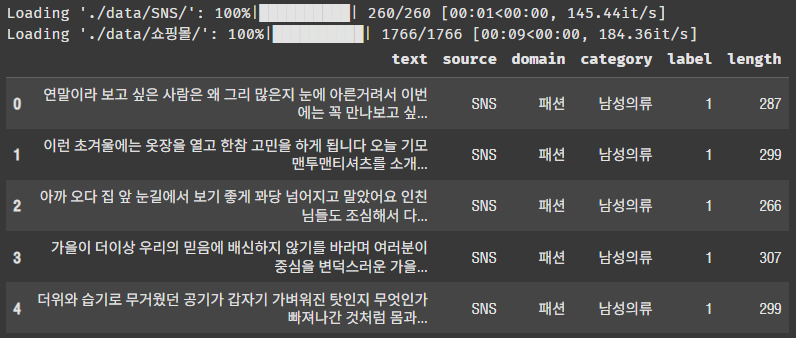
컬럼 6개가 잘 나온다.
df.to_csv(os.path.join(save_dir, 'unified_reviews.csv'), index=False, encoding='utf-8-sig')10초면 처리가 끝나긴 하지만 파일 저장하는 연습을 해야하기 때문에 csv 파일로 변환 후 저장했다.
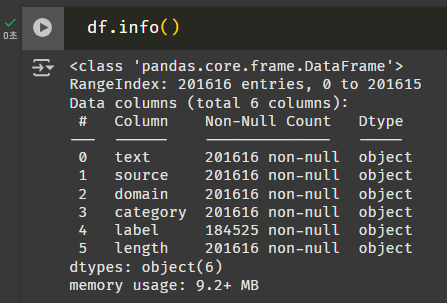
머신러닝 이후로 처음 써보는 info() 함수. 로우가 20만 개 정도 된다.
데이터가 많은 건지 적은 건지 잘 모르겠지만, 감성 분류 테스크에서 이정도의 데이터로 얼만큼의 성능이 나오는지는 확인할 수 있을 것 같다.
label, length는 int형태로 바꿔야할 것 같다. 근데 label 수량이 조금 이상한데? 결측치인가?
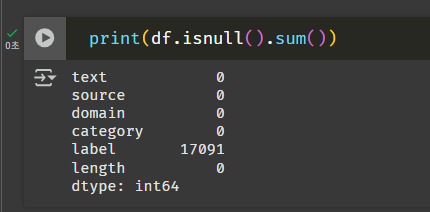
헐 이럴수가... 확인 안 했으면 큰일날 뻔했다.
df_isnull = df[df.isnull().any(axis=1)]
df_isnull.head()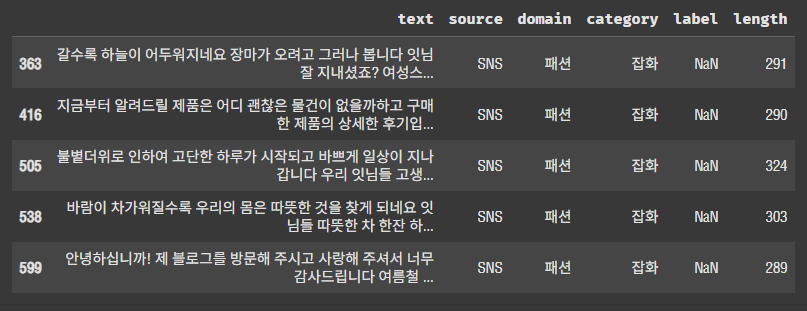
조금 더 확인해 보니 정말 label 컬럼이 비어있다. 이건 드롭해주는 게 맞는 것 같다.
df.dropna(inplace=True)
df['label'] = pd.to_numeric(df['label']).apply(lambda x: int(x) + 1)
df['length'] = pd.to_numeric(df['length'])
df.to_csv(os.path.join(save_dir, 'reviews.csv'), index=False, encoding='utf-8-sig')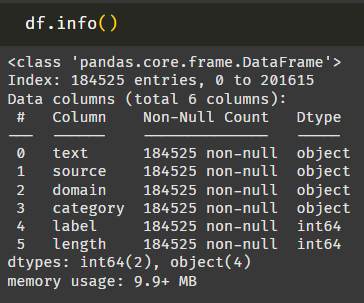
결측치를 드롭하고 label, length 컬럼을 숫자형태로 변경했다.
label 컬럼 값은 -1~1 인데, 음수값은 모델 학습에 영향이 있다고 하여 0~2로 변경했다.
데이터 준비 끝!
2. EDA
앞선 선장한 6개 컬럼에 대한 EDA를 진행해 보자!
일단 학습 성능에 영향을 미치는 건 텍스트 수와 텍스트 길이일 것 같다. 이 둘을 메인으로 잡고 해야겠다.
""" 리뷰 수 분석 """
fig, axes = plt.subplots(2, 2, figsize=(20, 16))
fig.suptitle('리뷰 수 분석', fontsize=22)
# Source별 리뷰 수
sns.countplot(ax=axes[0, 0], x='source', data=df, palette='Set2')
axes[0, 0].set_title('Source별 리뷰 수')
axes[0, 0].set_xlabel('출처')
axes[0, 0].set_ylabel('리뷰 수')
# Domain별 리뷰 수
sns.countplot(ax=axes[0, 1], x='domain', data=df, palette='Set2')
axes[0, 1].set_title('Domain별 리뷰 수')
axes[0, 1].set_xlabel('분야')
axes[0, 1].set_ylabel('')
# Label별 리뷰 수
sns.countplot(ax=axes[1, 0], x='label', data=df, palette='Set2')
axes[1, 0].set_title('Label별 리뷰 수')
axes[1, 0].set_xlabel('라벨')
axes[1, 0].set_ylabel('리뷰 수')
axes[1, 0].set_xticks(ticks=[0, 1, 2])
axes[1, 0].set_xticklabels(['부정', '중립', '긍정'])
# Category별 리뷰 수
top_20_categories = df['category'].value_counts().head(20).index
sns.countplot(ax=axes[1, 1], x='category', data=df, order=top_20_categories, palette='Set2')
axes[1, 1].set_title('category별 리뷰 수')
axes[1, 1].set_xlabel('카테고리')
axes[1, 1].set_ylabel('')
axes[1, 1].tick_params(axis='x', rotation=90)
Source, Domain, Label, Category별로 리뷰수가 각각 몇 개나 있는 지 확인해보자.
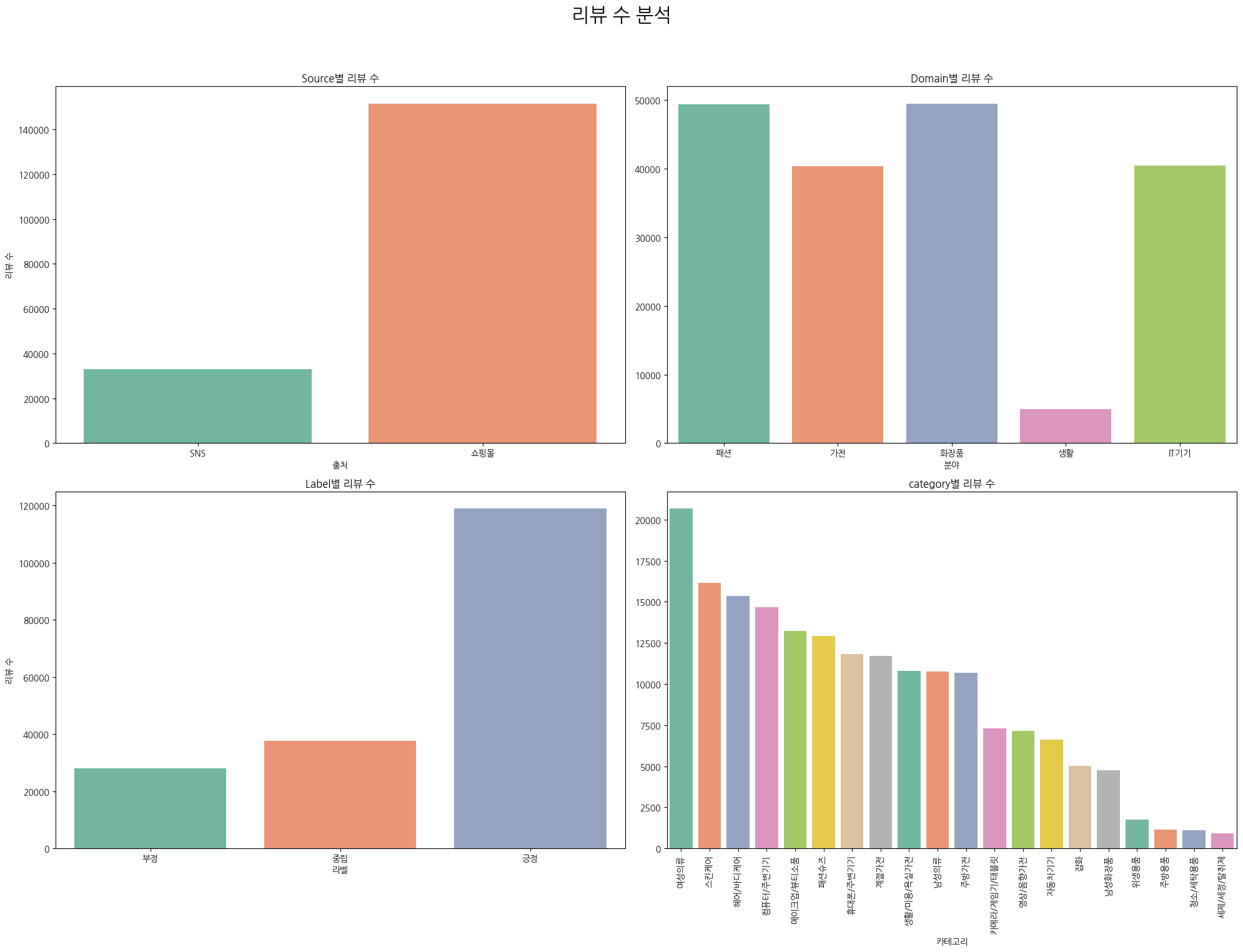
Source: 의외로 SNS 리뷰보다 쇼핑몰 리뷰가 훨씬 많다. 나는 쇼핑몰에서 리뷰해본 적이 한번도 없는데,,, 이상하다. 내가 비정상인듯 ㅋ
Domain: 5가지 도메인이 있다. 생활 관련 리뷰 수가 엄청 적다. 어쩌면 이 데이터로 학습을 시켰을 때 생활 쪽 리뷰는 잘 분류하지 못할 수도 있을 것 같다.
Label: 긍정적인 리뷰가 대부분이다. 뭐 당연한 건가??? 부정, 중립, 긍정의 비율이 비슷하다면 오히려 상품으로써의 가치가 없다는 뜻이겠지.
Category: 여성의류, 스킨바디케어, 뷰티 쪽 리뷰가 많다. 위생, 주방, 세탁 용품은 리뷰가 적다. 아마도 상품 특성상 리뷰까지 해야할 이유를 느끼지 못한 것이 아닐까...
""" 감성 비율 """
domain_label_ratio = df.groupby('domain')['label'].value_counts(normalize=True).mul(100).rename('percent').reset_index()
fig, ax = plt.subplots(figsize=(15, 6))
sns.barplot(ax=ax, x='domain', y='percent', hue='label', data=domain_label_ratio, palette='Set2')
ax.set_title('감성 비율')
ax.set_xlabel('분야')
ax.set_ylabel('비율 (%)')
ax.legend(handles=ax.get_legend_handles_labels()[0], title='라벨', labels=['부정', '중립', '긍정'])
plt.tight_layout()
plt.show()이번엔 도메인 별로 부정적인 리뷰 비율의 차이가 있는지 확인해 보자.
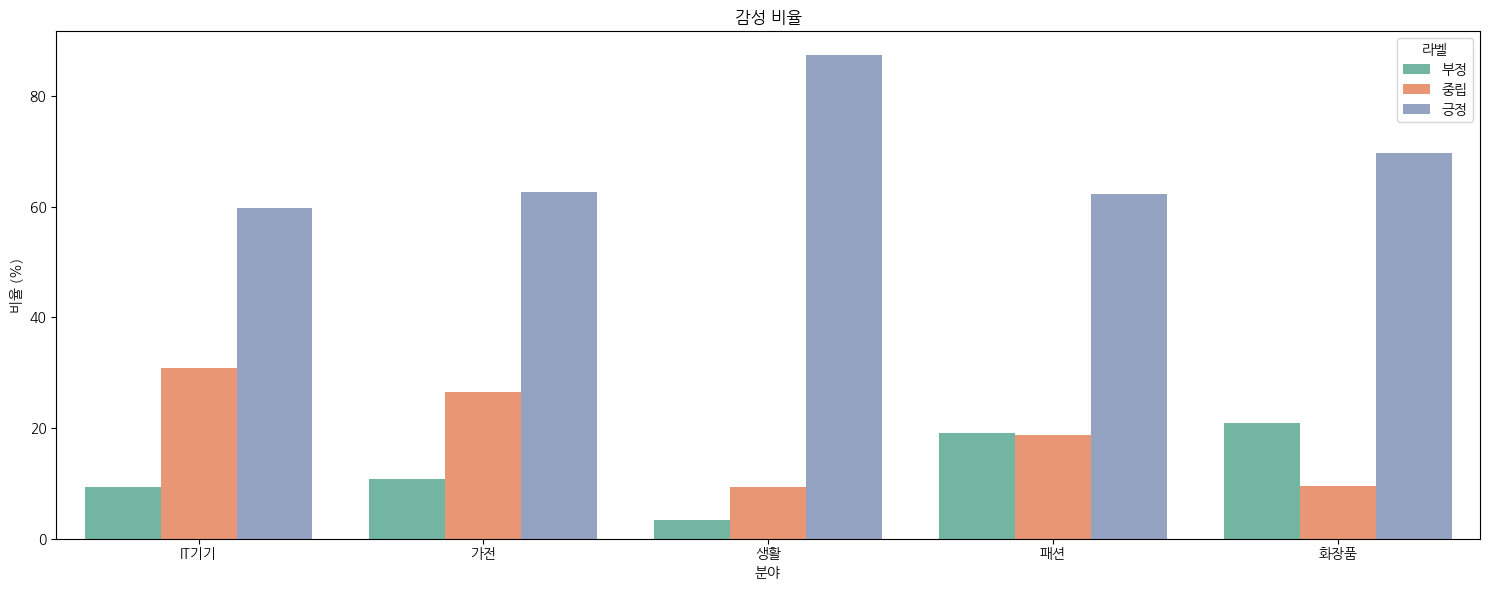
얼핏보면 다 비슷해 보이지만, 화장품과 패션 쪽에서는 부정적인 비율이 중립보다 많다. 그렇다는 건 마음에 안 드는 제품이 꽤나 있었다는 뜻이다.
생활 관련 상품은 유독 부정 리뷰가 없다. 생필품은 보통 저렴해서 악플 달 이유를 못 느끼는 건가..? 생활 분야의 부정적인 리뷰는 데이터가 별로 없어서 성능이 안 좋을 수도 있을 것 같다.
""" 리뷰 길이 분포 """
max_len = df['length'].max()
step = 50
bin_edges = np.arange(0, max_len + step, step)
bins = pd.cut(df['length'], bins=bin_edges, right=False)
binned_counts = bins.value_counts().sort_index()
fig, ax = plt.subplots(figsize=(15, 6))
sns.barplot(ax=ax, x=binned_counts.index.astype(str), y=binned_counts.values, palette='Set2')
ax.set_title('리뷰 길이 분포')
ax.set_xlabel('리뷰 길이 구간')
ax.set_ylabel('빈도수')
ax.tick_params(axis='x', rotation=90)
plt.tight_layout()
plt.show()어느 정도 구간의 길이에 데이터가 몰려있는지 확인해 보자.
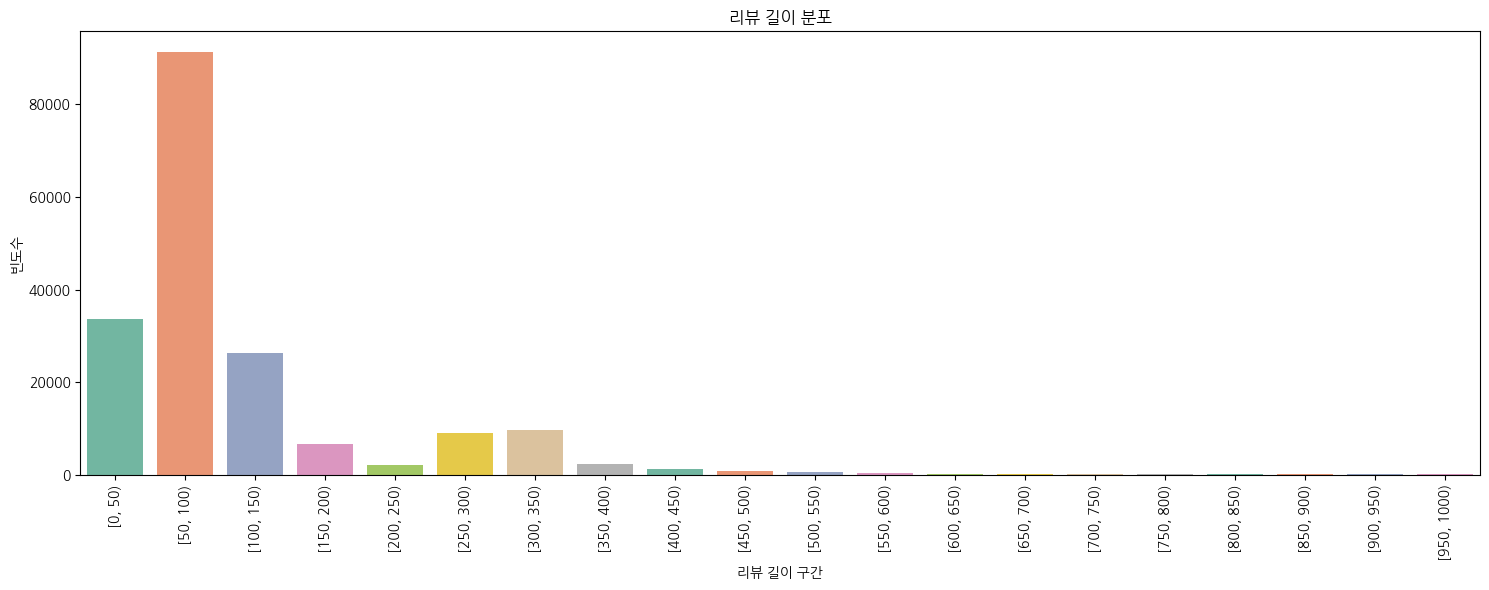
150자 이하에 90% 정도 몰려있는 느낌이다. 500자 넘어간 것도 약간 있는데,,, 이건 왠지 홍보를 위해 리뷰작업을 한 것 같다. 누가 리뷰를 500자씩 쓰냐구요
""" 리뷰 길이 분석 """
fig, axes = plt.subplots(2, 2, figsize=(20, 16))
fig.suptitle('리뷰 길이 분석', fontsize=22)
# Source별 평균 길이
sns.barplot(ax=axes[0, 0], x='source', y='length', data=df, palette='Set2')
axes[0, 0].set_title('Source별 평균 리뷰 길이')
axes[0, 0].set_xlabel('출처')
axes[0, 0].set_ylabel('평균 리뷰 길이')
# Domain별 평균 길이
sns.barplot(ax=axes[0, 1], x='domain', y='length', data=df, palette='Set2')
axes[0, 1].set_title('Domain별 평균 리뷰 길이')
axes[0, 1].set_xlabel('분야')
axes[0, 1].set_ylabel('')
# Label별 평균 길이
sns.barplot(ax=axes[1, 0], x='label', y='length', data=df, palette='Set2')
axes[1, 0].set_title('Label별 평균 리뷰 길이')
axes[1, 0].set_xlabel('라벨')
axes[1, 0].set_ylabel('평균 리뷰 길이')
axes[1, 0].set_xticklabels(['부정', '중립', '긍정'])
# Category별 평균 길이
top_20_categories = df['category'].value_counts().head(20).index
top_20_df = df[df['category'].isin(top_20_categories)]
sorted_order = top_20_df.groupby('category')['length'].mean().sort_values(ascending=False).index
sns.barplot(ax=axes[1, 1], x='category', y='length', data=top_20_df, order=sorted_order, palette='Set2')
axes[1, 1].set_title('category별 평균 리뷰 길이 (정렬)')
axes[1, 1].set_xlabel('카테고리')
axes[1, 1].set_ylabel('')
axes[1, 1].tick_params(axis='x', rotation=90)다음은 Source, Domain, Label, Category별로 리뷰 길이가 어느 정도 되는지 확인해보자.
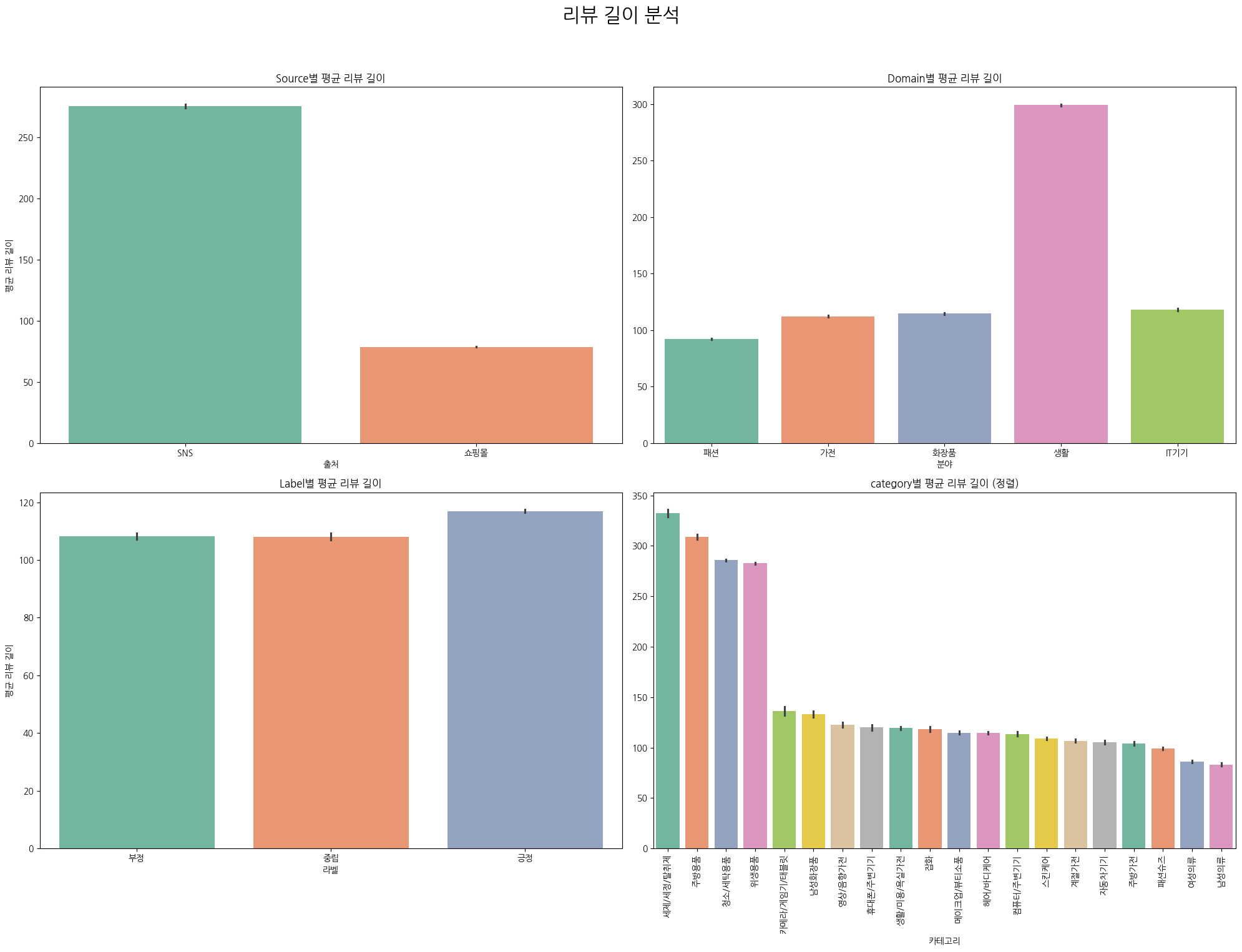
Source: SNS 리뷰 길이가 훨씬 길다. 희안하네. 리뷰 수는 쇼핑몰이 더 많았는데,,,
Domain: 생활 관련 리뷰가 유독 길다. 리뷰 수는 거의 없지만 길이가 기니까 어쩌면 학습하는 데 큰 문제가 없을 수도 있겠다.
Label: 부정, 중립, 긍정 모두 리뷰 길이는 비슷하다. 부정적인 리뷰는 길이가 길 줄 알았는데 의외다. 보통 마음에 안 드는 상품을 리뷰하면 이것저것 트집을 잡아야 해서 길어지지 않나?
Category: 위생, 주방, 세탁 용품의 리뷰 길이가 유독 길다. 이것도 리뷰 수와 정반대의 결과다. 일부러 이런 데이터를 준 것인지, 아니면 통상적으로 이 카테고리의 리뷰 길이가 긴 것인지 이제 조금 헷갈리기 시작한다.
일단 이정도면 보고 싶었던 내용은 다 확인한 것 같다. 내일부터는 본격적으로 모델을 만들어 봐야지!
