허깅페이스를 이용할 땐 어떤 모델이 어떤 상황에 적합한지 구분하는 안목이 필요해 보인다.
학습시간 09:00~02:00(당일17H/누적1461H)
◆ 학습내용
리뷰 감성 분석 AI 구현하기!
어제에 이어 3번부터 시작!
3. 모델 생성
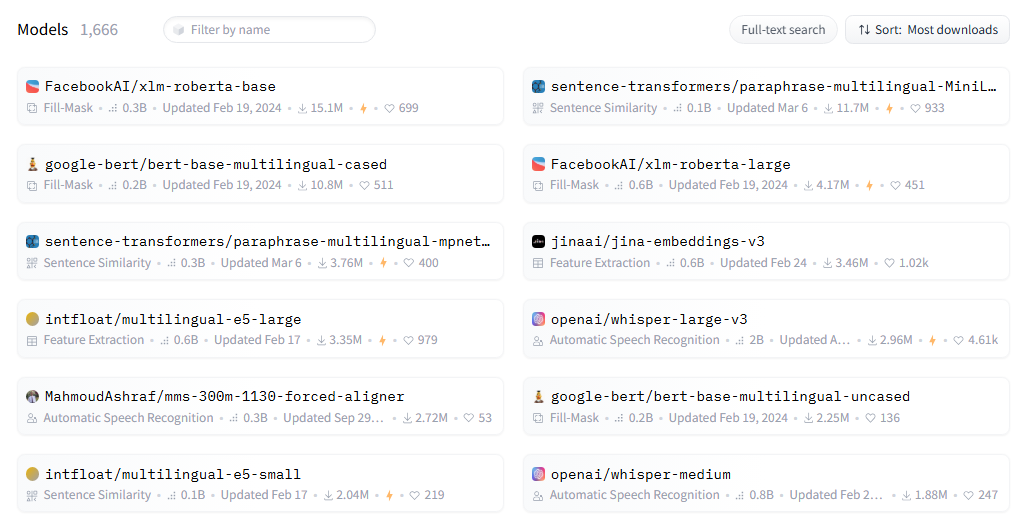
모델을 쇼핑하기 위해 허깅페이스에 들어왔다.
한국어를 지원하는 모델은 1666개다.
감성 분류 전용으로 이미 튜닝이 끝난 모델도 있다. 하지만 그걸 사용하면 미션을 진행하는 의미가 없으니 베이스 모델을 찾아봐야겠다.
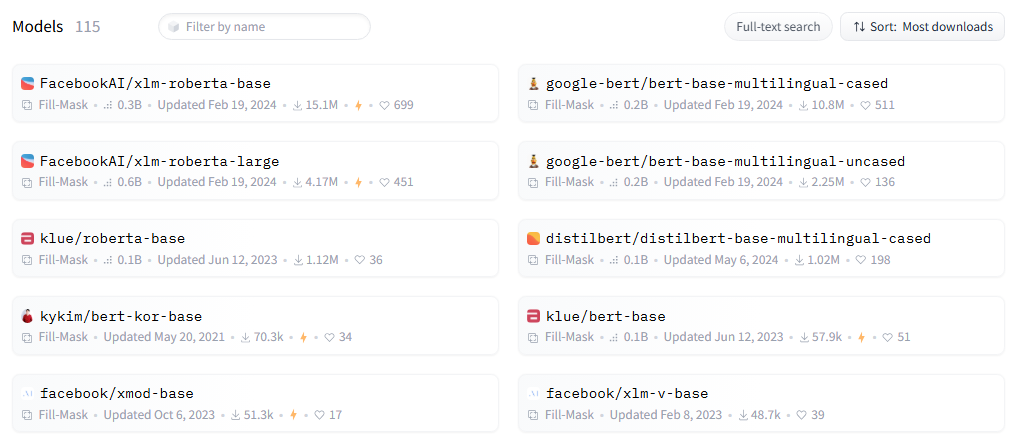
내 테스크에 맞게 파인튜닝할 수 있는 텍스트 베이스 모델은 100개가 조금 넘는다. facebook과 google의 모델이 다운로드 & 좋아요 기준으로 상위권이다. klue에서 나온 모델이 한국어 전용 모델이라고 한다.
이번엔 다운로드 수가 제일 많은 'FacebookAI/xlm-roberta-base' 모델로 해봐야겠다. facebook 모델의 성능도 궁금하고, 다국어 모델을 한국어로 파인튜닝하면 성능이 어느 정도 나오는지도 궁금하다.
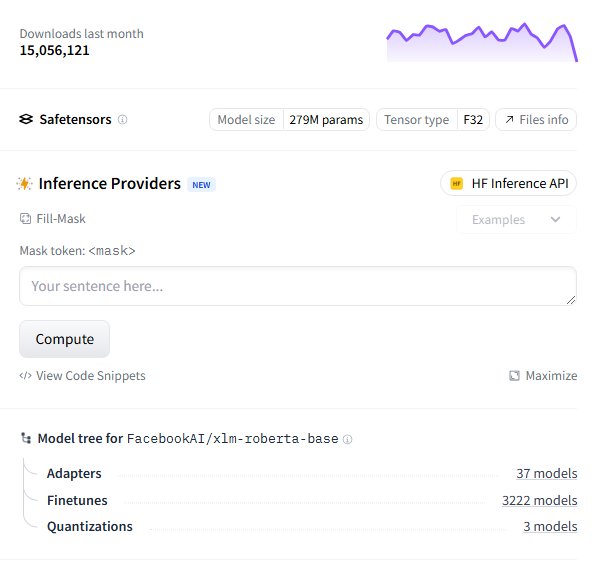

다운로드 수가 무려 1500만.... 파라미터 수는 2.79억 개다. 파인튜닝할 때 시간이 많이 걸릴 듯한 느낌이다.
파일 크기는 1GB 정도다. 일단 해보고 판단하자!
model_name = "FacebookAI/xlm-roberta-base"
save_dir = "./model/"
if not os.path.exists(save_dir):
os.makedirs(save_dir)
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.save_pretrained(save_dir)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=3)
model.save_pretrained(save_dir)
내 폴더에서 로드 후 진행하기 위해 앞서 선택한 모델을 model/ 폴더에 다운로드했다.
4. 데이터셋 생성
train_df, test_df = train_test_split(df, test_size=0.2, random_state=42, stratify=df['label'])
train_dataset = Dataset.from_pandas(train_df)
test_dataset = Dataset.from_pandas(test_df)어제 만들었던 데이터프레임을 8:2 비율로 train & test 스플릿 했다.
아무리 생각해도 Dataset 모듈은 완전 사기다.
model_path = "./model" # FacebookAI/xlm-roberta-base
model = AutoModelForSequenceClassification.from_pretrained(model_path, num_labels=3)
tokenizer = AutoTokenizer.from_pretrained(model_path)아까 다운받았던 FacebookAI/xlm-roberta-base 모델이 있는 폴더를 경로로 지정해서 model & tokenizer 변수로 초기화했다. 라벨은 부정, 중립, 긍정이라서 3개로 했다.
def tokenize(examples):
tokenized = tokenizer(
examples['text'],
padding='max_length',
truncation=True,
max_length=128
)
return tokenized완전완전 사기인 Autotokenizer로 간단하게 토큰화를 해주고,
tokenized_train_dataset = train_dataset.map(tokenize, batched=True)
tokenized_test_dataset = test_dataset.map(tokenize, batched=True)
tokenized_train_dataset.set_format("torch")
tokenized_test_dataset.set_format("torch")train set과 data set을 텐서 형태로 만들어 주었다.

이렇게 쉽게 전처리가 끝나다니,,,
5. 모델 학습
FFT, PEFT를 비교해 보자!
""" 학습 중 출력할 지표 설정 """
def compute_metrics(p):
preds = np.argmax(p.predictions, axis=1)
labels = p.label_ids
accuracy = accuracy_score(labels, preds)
f1 = f1_score(labels, preds, average='weighted')
return {"accuracy": accuracy, "f1": f1}
학습 시 넣을 보조 함수를 하나 만들었다.
로그가 출력될 때 보통 로스만 나오는데, 허깅페이스 모듈을 사용할 때는 매트릭 함수를 사전 정의 후 넣으면 다른 지표를 함께 볼 수 있는 것 같다.
""" 모델 학습 함수 """
def train_model(model, args):
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_train_dataset,
eval_dataset=tokenized_test_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
return trainer후,, Trainer 모듈은 완전완전완전 사기다.
""" Full Fine Tunning """
model_fft = AutoModelForSequenceClassification.from_pretrained(model_path, num_labels=3, torch_dtype=torch.bfloat16).to(device)먼저 FFT 모델 학습을 먼저 해보자.
AutoModelForSequenceClassification 모듈을 사용하여 모델이 저장된 경로를 넣고 초기화해준다.
최근 강의에서 bfloat16을 배웠기 때문에 바로 써먹어준다 ㅎㅎㅎ
training_args_fft = TrainingArguments(
output_dir='./results/fft',
num_train_epochs=1,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
weight_decay=0.01,
eval_strategy="steps",
save_strategy="steps",
metric_for_best_model="accuracy",
report_to="none"
)argument를 정의해 준다. 아까 만든 train_model 함수에 넣을 하이퍼파라미터를 모아놓은 코드다. YOLO 모델 돌리는 것과 느낌이 비슷하다.
배치는 32로 했다. 배치를 높일수록 메모리 점유율이 높아지는 대신 최적화될 가능성도 높아진다고 멘토님에게 들었다. 일단 이렇게 돌려보고 확 높여서 비교해 봐야겠다.
train_fft = train_model(model_fft, training_args_fft).train()
일단 가볍게 1에폭만 돌려보자.
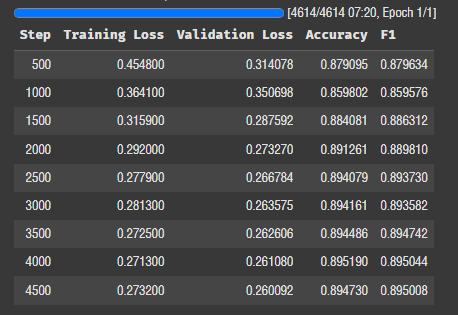
1에폭에 7분 정도 걸린다. 2500 스텝부터는 로스가 잘 안 떨어진다.
lora_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
r=4,
lora_alpha=4,
lora_dropout=0.1,
)
model_lora = AutoModelForSequenceClassification.from_pretrained(model_path, num_labels=3, torch_dtype=torch.bfloat16).to(device)
model_lora = get_peft_model(model_lora, lora_config)
다음은 PEFT 학습이다. LoRA는 모델 초기화 전에 rank와 alpha 값을 정의해야 한다.
일단 값은 4로 했다. 논문에서 보았던 낮은 수치 중 가장 효율이 좋았던 수치이기 때문이다.
이것도 일단 한번 돌려보고 더 높여서 비교해 봐야겠다.
model_lora.print_trainable_parameters()
peft 라이브러리에는 파라미터 수를 확인할 수 있는 함수가 있다. facebook 모델 2.78억 개 중에서 74만 개만 튜닝하면 된다고 한다.
이걸로 비슷한 성능을 낼 수 있다고?? 대박이다.
training_args_lora = TrainingArguments(
output_dir='./results/lora',
num_train_epochs=1,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
weight_decay=0.01,
eval_strategy="steps",
save_strategy="steps",
metric_for_best_model="accuracy",
load_best_model_at_end=True,
report_to="none",
)똑같이 arg를 설정해 줬다. 어라 근데 이거 output 경로 제외하고 아까랑 똑같은데 그냥 함수로 만들까?
""" 학습 인자 설정 함수 """
def set_train_args(output_dir):
args = TrainingArguments(
output_dir=output_dir,
num_train_epochs=1,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
weight_decay=0.01,
eval_strategy="steps",
save_strategy="steps",
metric_for_best_model="accuracy",
report_to="none"
)
return args후딱 함수로 바꿨다.
args_lora = set_train_args(output_dir='./results/lora')
train_lora = train_model(model_lora, args_lora).train()학습 돌려보자!
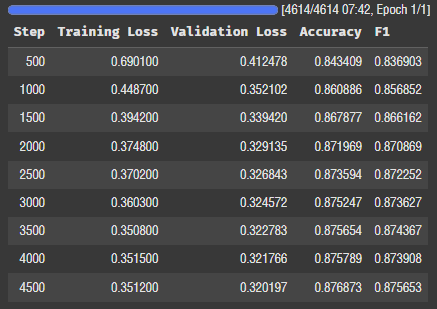
오잉 생각보다 학습시간 차이가 없다. 오히려 20초 정도 더 걸렸다. 왜지..?
로스는 0.27에서 0.35로, 정확도는 0.89에서 0.87로 미세하게 성능이 안 좋아졌다.
0.26%의 파라미터만 튜닝했는데 이정도의 성능이면 대단하다고 보는 게 맞는 거겠지..?
근데 학습 시간이 별 차이 없다는 게 이해가 안 된다.
num_train_epochs=3,
per_device_train_batch_size=1024,
per_device_eval_batch_size=1024,배치를 1024로 해보자. 과연 돌아갈까?

메모리가 터져버렸다 ㅋㅋㅋㅋ
768MB가 필요한데 580MB만 남아서 터졌다고 한다. A100을 쓰는데 부족할 정도면 역시 무리였던 것 같다.
그래도 이정도면 512까진 가능하겠는데?
num_train_epochs=3,
per_device_train_batch_size=512,
per_device_eval_batch_size=512,512로 재도전..
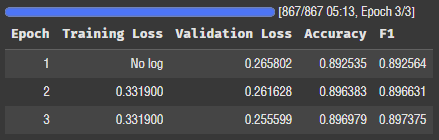
FFT 로스가 전보다 올라갔다... 정확도는 0.002 정도 오른듯
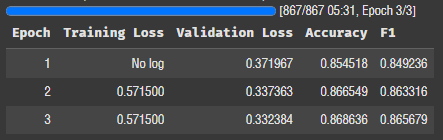
LoRA 로스도 올라갔다 ㅠ 정확도는 0.002 정도 떨어졌다.
lora_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
r=16,
lora_alpha=64,
lora_dropout=0.1,
)rank, alpha 값에 따라서 로스와 정확도가 달라질까?
rank 4 -> 16
alpha 4 -> 64
이렇게 한번 돌려보자.
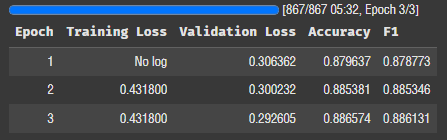
오! 성능이 좋아졌다. 값을 조금만 더 올려볼까?
lora_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
r=64,
lora_alpha=128,
lora_dropout=0.1,
)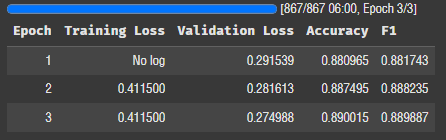
오! 정확도가 0.89다. 이정도면 PEFT와 성능차이가 거의 없다.
rank 값이 문제였군!

모델 총 파라미터의 1% 만 튜닝해서 비슷한 성능을 낸다는 게 참 놀랍다.
num_train_epochs=10,
per_device_train_batch_size=512,
per_device_eval_batch_size=512,FFT, LoRA 각각 10에폭씩 돌려서 비교해 보자.
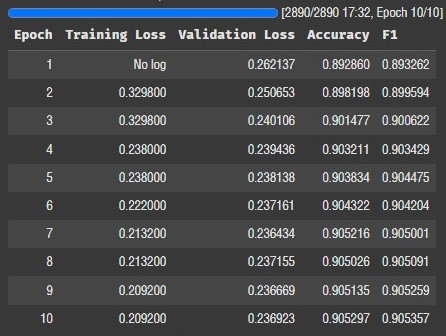
FFT 정확도가 0.9까지 상승했다. 변동폭을 보니 여기서 에폭을 더 돌린다고 유의미한 변화가 있을 것 같진 않다.
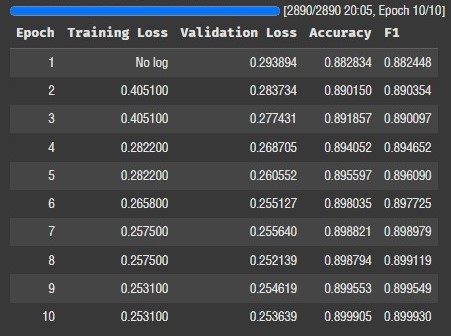
LoRA의 정확도도 0.8999 까지 올라갔다. 이정도면 사실 수치상 성능은 동일하다고 보는 게 맞는 것 같다.
일단 오늘은 여기까지! 비교분석이 기대된다!
