허깅페이스+랭체인 조합이 더 발전하면 AI 엔지니어의 밥줄이 끊길지도 모르겠다는 생각이 들었다...
학습시간 09:00~03:00(당일18H/누적1551H)
◆ 학습내용
어제에 이어 4번 부터 시작!
4. Generation
어제 벡터 DB에서 코사인 유사도 기반으로 문서를 뽑아오는 것까지 했다.
Indexing - Retrieval 단계까지 했으므로 Generation을 할 차례다.
템플릿이랑 체인을 만드는 단계인 것 같은데,,, 뭘 해야할지 몰르겠다. 하면서 터득해 보자!
!pip install langchain-huggingface -q
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
from langchain.prompts import PromptTemplate
from langchain_huggingface import HuggingFacePipeline필요한 라이브러리를 임포트했다. 랭체인은 없어서 설치했다.
tokenizer = AutoTokenizer.from_pretrained(llm_model_dir)
model = AutoModelForCausalLM.from_pretrained(llm_model_dir, torch_dtype=torch.bfloat16, device_map="auto")기본적으로 필요한 토크나이저와 모델 객체를 만들었다.
이번에도 bfloat16으로 해보자!
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
temperature=0.1,
return_full_text=False
)
llm = HuggingFacePipeline(pipeline=pipe)다음은 허깅페이스 transformers 모듈의 pipeline과 랭체인 pipeline을 이용해 llm 객체를 만들었다.
살짝 이해가 안 가는 건,, 하이퍼파라미터는 trainsformer 라이브러리로 만들고 llm 객체는 langchain_huggingface 라이브러리로 만든다는 거다.
왜 굳이 귀찮게 나누어 놓았을까..?
template = """
[System]:
- 반드시 한국어로 답변하세요.
- 당신은 세무 전문 AI입니다.
- 제공된 [Context] 정보를 바탕으로 사용자의 질문에 답변하세요.
- [Context] 정보로 답변이 어렵다면 모르겠다고 답변하세요.
- 거짓으로 답변을 꾸며내지 마세요.
- 최대한 자세하게 답변하세요.
[Context]:
{context}
[Question]:
{question}
[Answer]:
"""
prompt = PromptTemplate.from_template(template)다음은 시스템 프롬프트를 만들었다.
어떤 프롬프트를 전달할지 고민하다가 그냥 최대한 RAG답게 행동하도록 했다.
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)지금까지 만든 코드를 체인으로 쭉 연결했다.
PDF 문서의 문맥, 시스템 프롬프트, LLM 모델을 순차적으로 타고 마지막으로 StrOutputParser를 통해 결과값이 출력된다.
랭체인 문법이 생소해서 이해가 어렵긴 한데,, 그냥 파라미터를 콤마가 아닌 수직선? 으로 연결한다고 보면 될 것 같다.
근데 | 이거 뭐라고 부르는 거지??
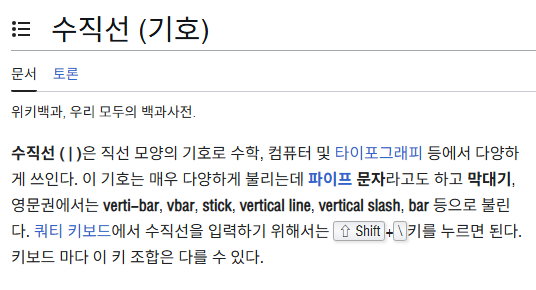
아 뭐야 진짜 수직선이라 부르네 ㅋㅋㅋㅋㅋㅋㅋ
query = "2024년 연말정산을 해야하는데, 작년과 변경된 점이 있나요?"
print(f"\n[질문]\n{query}")
answer = rag_chain.invoke(query)
print(f"\n[답변]\n{answer}")답변을 제대로 하나 한번 테스트해보자!

네, 2024년 귀속부터는 소득기준 초과 부양가족에 대한 자료 조회 및 다운로드를 제한하여 납세자의 실수를 최소화하고 정확한 연말정산을 지원하기 위해 「간소화 서비스」를 전면 개편하였습니다. 이로 인해 연말정산 간소화 서비스가 이전과 다르게 운영될 예정입니다.
오 뭔가 두루뭉술하지만 2024년의 답변을 해주긴 한다.
근데 이번 미션은 이게 끝인가...? 허깅페이스+랭체인 하니까 뭐 할게 없다. 전처리, 모델 설계, 학습을 다 안 하면 난 이제 뭘 해야하지...?
from fastapi import FastAPI그동안 틈틈히 공부한 FastAPI를 테스트할 순간인 것 같다.
app = FastAPI()
class QueryRequest(BaseModel):
query: str
@app.post("/get_answer")
async def get_answer(request: QueryRequest):
answer = rag_chain.invoke(request.query)
return {"answer": answer}FastAPI를 app이라는 객체로 만든다음 간단한 백엔드 서버를 구축했다. /get_answer 입력이 들어오면 이 api통해 방금 만든 chain에 query를 보내서 모델과 소통한다!
API_URL = "http://127.0.0.1:8000"
if prompt := st.chat_input("궁금한 내용을 입력해 주세요"):
# 사용자 메시지 기록 및 출력
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
...
response = requests.post(f"{API_URL}/get_answer", json={"query": prompt})
...
백엔드에 연결할 간단한 웹을 만들고 실행!

나름 그럴듯한 채팅창이 만들어졌다.
답변도 잘할까?
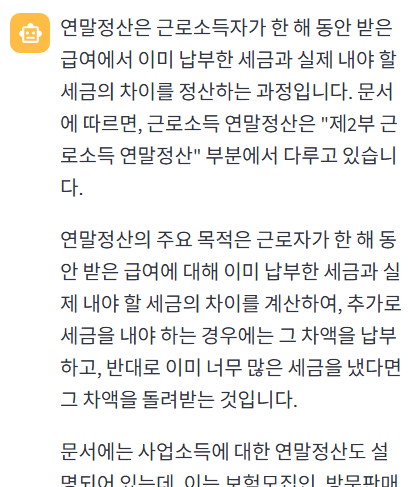
왠지 문서에 너무 의존하는 듯한 느낌으로 말을 하지만, 그래도 답변은 잘한다.
llm이 문서에 고집하는 건 아마도 내가 넣은 시스템 프롬프트 때문인 것 같다.
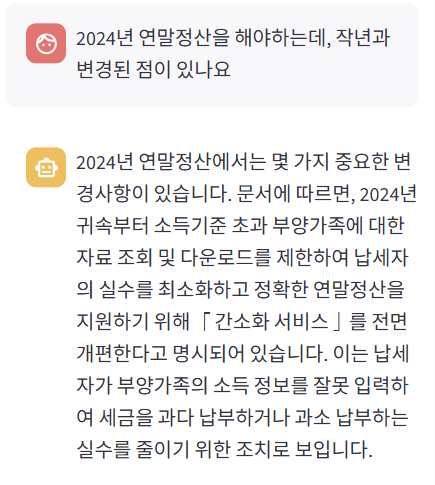
아까 개발환경에서 입력했던 질문을 똑같이 입력해 보았다.
간소화 서비스 전면 개편이라는 내용이 동일한 걸 보니 api로 호출해도 적절한 청크를 잘 찾는 것 같다.
근데 답변당 평균 10초 정도 걸리는데, 청크가 엄청 많으면 더 오래걸릴 것 같기도 하다.
일단 이번 미션은 여기서 종료...
