내가 제대로 하고 있는 건지 잘 모르겠다...
학습시간 09:00~03:00(당일18H/누적1533H)
◆ 학습내용
연말정산 도와주는 AI 챗봇 구현하기!
목표
- LangChain을 이용해 RAG 시스템을 구현
- 사용자의 질문이 들어왔을 때, 연관된 문서 청크를 찾아 답변을 생성
- Hybrid searching, multi-query retrieval, contextual compression, reranking 등 실험
- Temperature, penalty 등 텍스트 생성과 관련된 다양한 옵션 설정
데이터
- 국세청에서 발간한 2024년 연말정산 신고 안내 문서 사용
- Hugging Face의 적절한 한국어 LLM 사용
1. 모델 선정
다시 돌아온 모델 쇼핑의 시간이다.
RAG를 구현하기 위해서는 embedding & llm 이렇게 2개의 모델이 필요하다.
먼저 embedding model 모델 쇼핑해 보자!
필터를 먼저 셋팅했다. text-embeddings-inference가 아마도 임베딩 모델이겠지...?
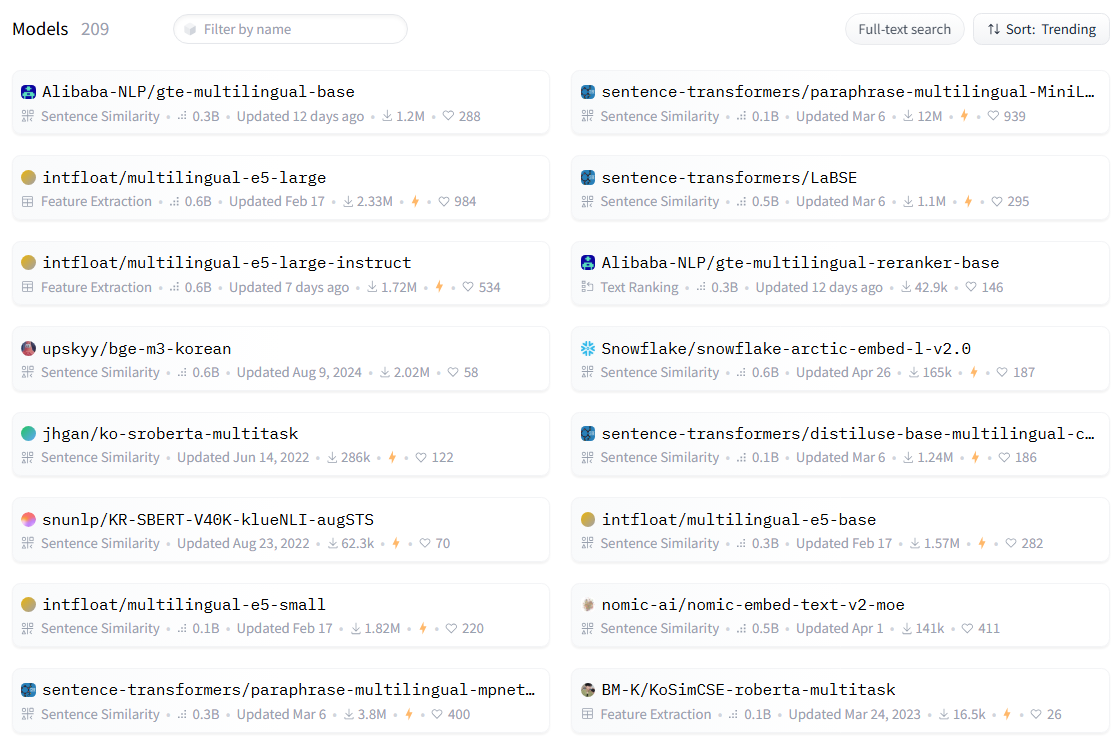
한국어 가능 여부까지 필터를 걸었더니 209개의 모델이 나왔다. 현재 trending인 모델을 훑어보니 upskyy/bge-m3-korean 라는 모델이 눈에 들어온다.
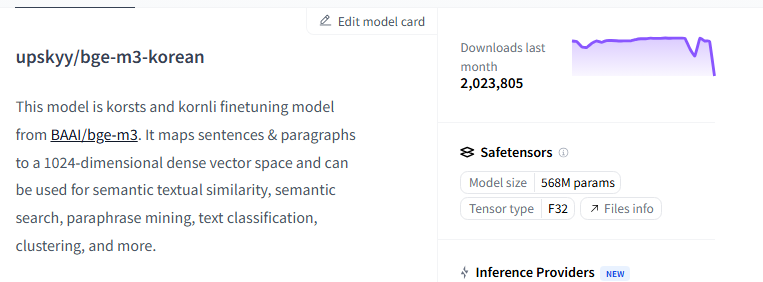
BAAI/bge-m3 모델을 파인튜닝해서 만들었다고 한다. 다운로드 수가 2백만이니 나쁘지 않은 것 같다.
근데 이렇게 까지 큰 임베딩 모델은 필요없는데,,, 조금 더 작은 모델 없나?
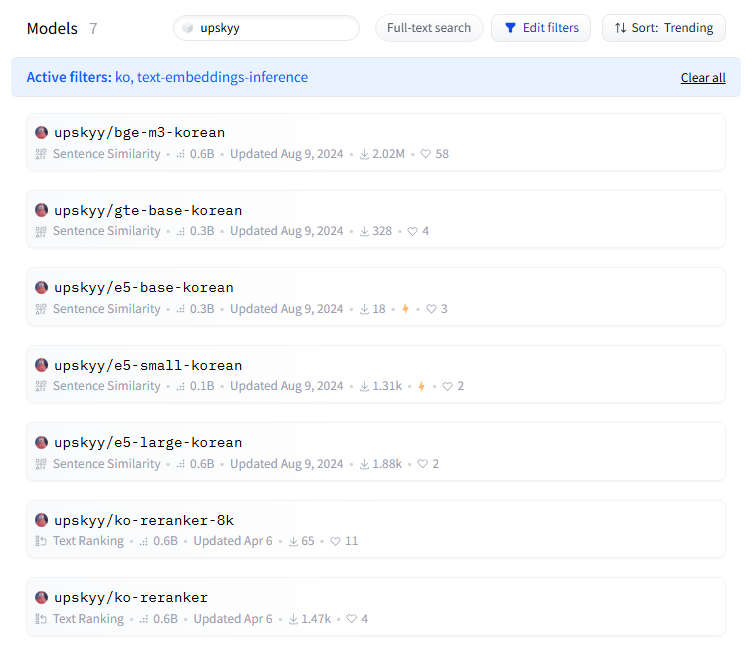
upskyy로 검색했더니 이 사람이 올린 모델이 쭉 나온다. 오 small 버전이 보인다!
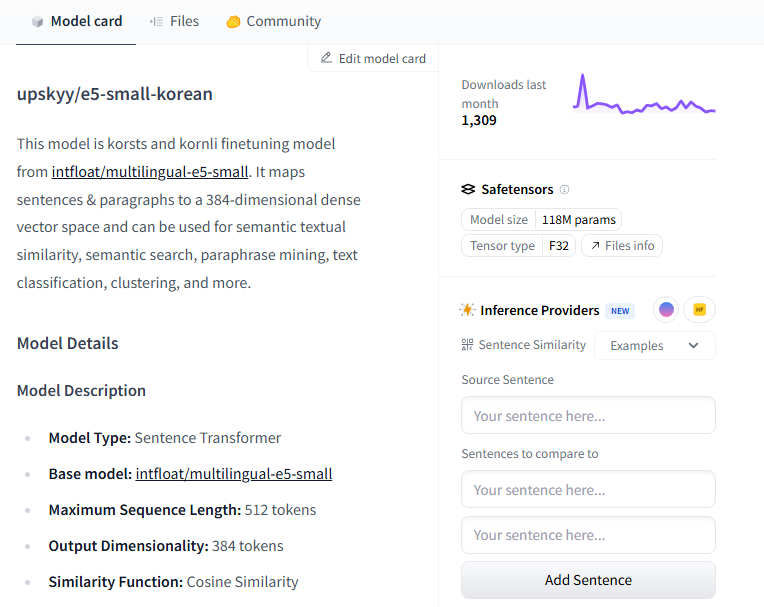
ntfloat/multilingual-e5-small 모델을 파인튜닝해서 만들었다고 한다. 다운로드 수가 낮긴 한데,,, 그래도 같은 사람이 만들었으니까 한번 믿고 써볼까..?
text-generation-inference, Text Generation, korea 필터를 거니까 약 2000개의 모델이 나왔다.
최근 skt에서 만들었다던 에이닷 모델도 보인다.
근데 파라미터가 다 무슨 100억~700억 개 이러네 ㅋㅋㅋㅋ 이렇게 큰 모델은 필요 없는데,,,
파라미터 30억 개 이하 필터를 추가했다.
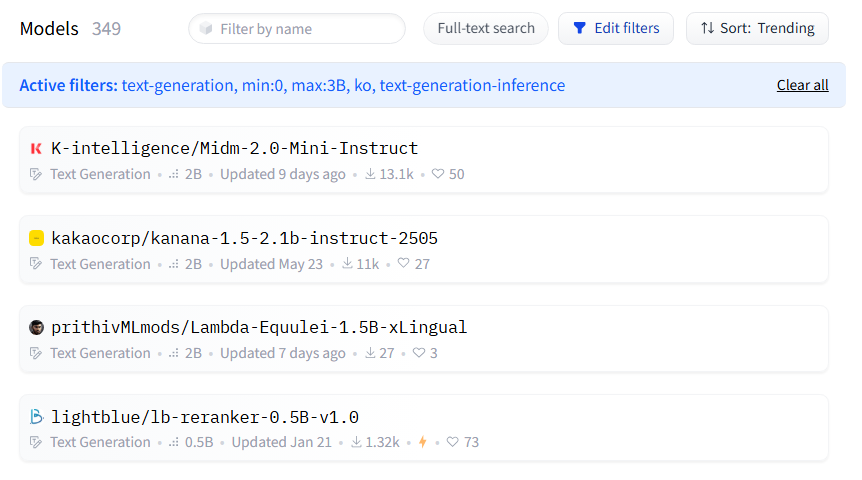
약 350개의 모델이 나왔다. 최근 공개된 KT 믿음 2.0 모델과 카카오에서 만든 카나나가 1, 2위를 다투고 있다.
개인적으로 KT를 더 좋아해서 믿음 모델로 해봐야겠다.
def download_model(model_id, save_path):
os.makedirs(save_path, exist_ok=True)
snapshot_download(repo_id=model_id, local_dir=save_path)
download_model("upskyy/e5-small-korean", "./model/embedding/")
download_model("K-intelligence/Midm-2.0-Mini-Instruct", "./model/llm/")클라우드에 바로 다운로드하기 위해 함수를 만들었다.

embedding model 다운로드 완료!

llm model도 다운로드 완료!
후,, 모델 쇼핑만 몇 시간을 했는지 모르겠다 ㅠ 모델 보는 안목이 없으니까 은근 시간을 많이 잡아먹는다...
2. 데이터 확인

이번 미션에 사용할 데이터다.

헉 캠프 측에서 임의로 만든 데이터인 줄 알았는데 진짜 국세청 자료인 것 같다.

약 400페이지가 넘는 분량이다.
데이터 용량은 20MB쯤인데, 이렇게 많은 자료가 들어갈 수 있나? PDF의 특징이 원래 이런 건가??

간단히 훑어보니, 2024년 부터 달라진 점이 꽤 많이 적혀 있다. 이런 부분을 잘 대답할 줄 알아야 좋은 RAG 모델이라 할 수 있게지??
3. Indexing & Retrieval
RAG는 3단계로 이루어진다고 들었다.
- Indexing
- Load -> Split -> Embed -> Store
- Retrieval
- Query Embed -> Similarity Search -> Return Chunks
- Generation
- Prompt -> Generate
해보지 않아서 이게 맞는 흐름인지 모르겠다. 해보면 알겠지 뭐 ㅋ...
loader = PyPDFLoader(data_dir)
document = loader.load()일단 PDF 파일을 로드하기 위한 객체를 만들었다.
Dataloader 같은 느낌인가? PDF파일이 아닐 때는 어떻게 하면 좋을지 알아두면 좋을 것 같다.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_documents(document)PDF 파일을 청크 단위로 나눴다. 총 400페이지니까 1000자 정도로 나누면 되지 않을까...? 흐름을 유지하기 위해 200자 오버랩을 줬다.
print(f"Total Chunks: {len(chunks)}") 
총 637개의 청크. 800을 곱하면 PDF 파일 내 텍스트 수는 약 50만 자 정도 된다는 뜻이다.
emb_model = HuggingFaceEmbeddings(model_name=emb_model_dir, model_kwargs={'device': device})다음은 아까 다운로드 받은 임베딩 모델과 허깅페이스 모듈을 사용해서 임베딩했다.
vector_db = FAISS.from_documents(documents=chunks, embedding=emb_model)다음은 FAISS 모듈을 이용해 백터공간에 DB화 했다. 이게 시간이 몇 분 정도 걸리는데 저장할 수 있는 방법은 없나?
vector_db.save_local("./data/faiss_index")
vector_db = FAISS.load_local("./data/faiss_index", emb_model)이렇게 저장했다가 다시 로드하면 되는 듯하다.

엥? 에러가 떴다.
대충 읽어보니 pickle 파일은 악성 코드를 포함할 수 있어서 allow_dangerous_deserialization 을 True 로 주는 코드를 포함해야 로드할 수 있다는 것 같다.
vector_db = FAISS.load_local("./data/faiss_index", emb_model, allow_dangerous_deserialization=True)오케이 이것도 했고,
retriever = vector_db.as_retriever()방금 로드한 벡터 DB로 retrieval 할 수 있도록 객체로 만들어 줬다.
def test_vector_db(query, k):
retrieved_docs = vector_db.similarity_search(query, k)
print(f"\n사용자 질문: {query}")
print("\n검색된 문서:")
for i, doc in enumerate(retrieved_docs):
print(f" [{i+1}] {doc.page_content}")
print("\n",("*"*100))잘 나오나 테스트하기 위한 함수를 만들었다. 이걸 실행하면 내가 입력한 것과 코사인 유사도가 가장 높은 k개의 chunk가 출력된다.
test_vector_db(query="소득신고", k=2)
소득신고 라는 텍스트와 코사인 유사도가 높은 2개의 chunk가 나왔다.
흠 제대로 하고 있는 건가...? 근데 이건 EDA를 어떻게 해야하지??
일단 오늘은 여기까지 해보자.. ㅠㅠ
