[250818월1860H] 모델 최적화(Distillation, Pruning, Quantization), 모델 변환(ONNX, Tensor RT) 이론
비전공자 부트캠프 생존기
목록 보기
132/169
무슨 말인지 하나도 모르겠다 ㅠㅠ...
학습시간 09:00~01:00(당일16H/1860H)
◆ 학습내용
1. 모델 최적화 기법
- 학습된 딥러닝 모델의 효율성을 극대화하는 과정
- 주요 목표: 추론 속도 향상, 메모리 사용량 감소, 모델 크기 축소, 전력 소모량 절감
- 정확도 손실을 최소화하면서 위 목표들을 달성하는 것이 핵심
(1) 지식 증류 (Knowledge Distillation)
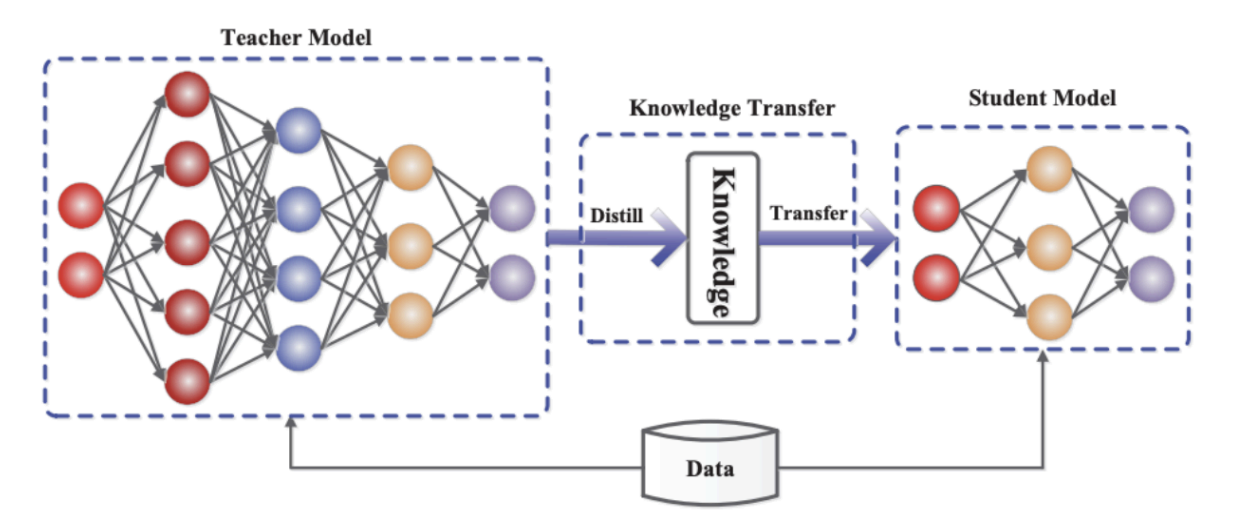
A. 개념
- 크고 복잡한 Teacher 모델의 일반화된 지식을 작고 효율적인 Student 모델로 이전하는 학습 기법
B. 핵심 원리: Soft Label
- Hard Label: 정답 클래스만 1이고 나머지는 0인 원-핫 벡터 (e.g.,
[0, 1, 0]) - Soft Label: Teacher 모델의 출력 확률 분포 자체를 사용 (e.g.,
[0.1, 0.8, 0.1]), 정답이 아닌 클래스와의 관계(e.g., '고양이'가 '개'와 '자동차'보다 유사하다는 정보)까지 학습 가능 - Temperature Scaling: Softmax 함수에 T(온도) 매개변수를 적용하여 확률 분포를 부드럽게 만들어 지식 이전 효과를 높임
C. 프로세스
- 사전 학습된 Teacher 모델 준비
- Teacher 모델의 Soft Label을 정답으로 사용하여 Student 모델 학습
- Student 모델의 원래 Hard Label Loss와 Soft Label Loss를 결합하여 최종 Loss 계산 및 최적화
(2) 가지치기 (Pruning)
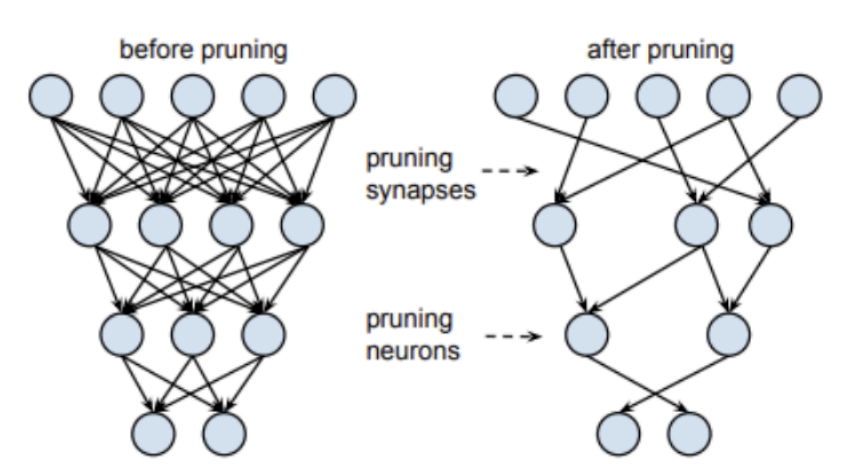
A. 개념
- 모델의 파라미터 중 중요도가 낮은 부분을 식별하고 제거하여 네트워크를 희소(sparse)하게 만드는 기법
B. Pruning 기준 (Criteria)
- Magnitude-based: 가중치의 절대값(L1/L2 norm)이 작은 것을 중요도가 낮다고 판단하여 제거 (가장 일반적인 방법)
- Gradient-based: 학습 중 가중치의 그래디언트 변화량을 기반으로 중요도 판단
C. 종류 및 특징
| 구분 | Unstructured Pruning | Structured Pruning |
|---|---|---|
| 제거 단위 | 개별 가중치 | 필터, 채널 등 구조 단위 |
| 장점 | 압축률이 높고 유연함 | 일반 하드웨어에서 속도 향상 |
| 단점 | 특수 라이브러리/하드웨어 필요 가능성 | 압축률이 상대적으로 낮을 수 있음 |
D. 관련 개념: 복권 가설 (Lottery Ticket Hypothesis)
- 거대한 초기 네트워크에는 잘 훈련시키면 원래 네트워크만큼의 성능을 내는 작은 부분 네트워크(Winning Ticket)가 존재한다는 가설
- Pruning은 이 '당첨된 복권'을 찾는 과정으로 해석될 수 있음
(3) 양자화 (Quantization)
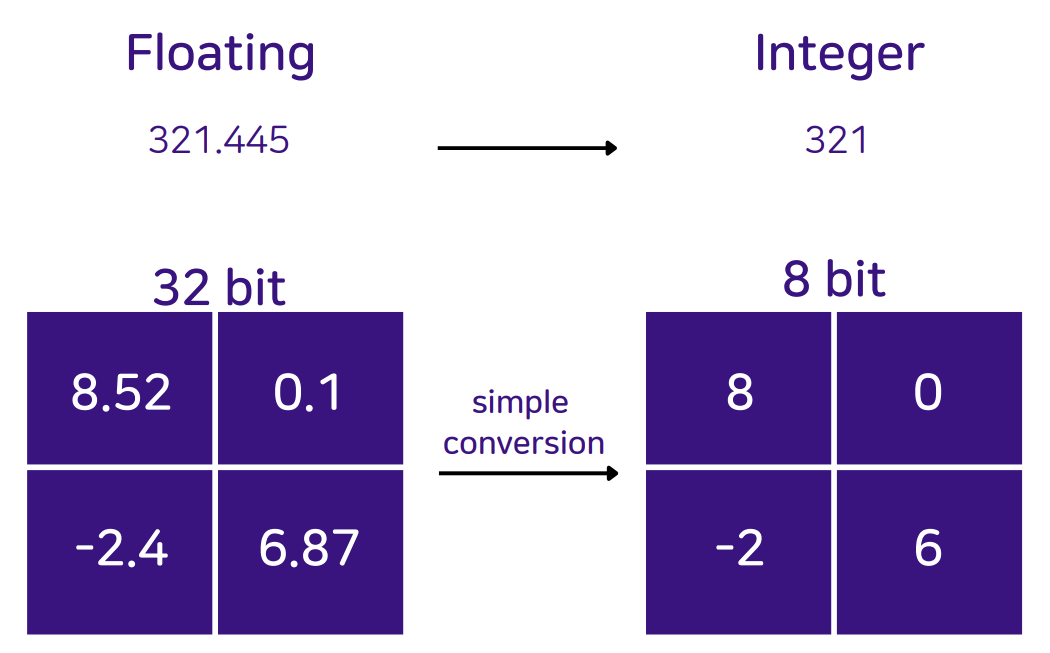
A. 개념
- 메모리와 연산량 절감을 위해 모델의 가중치와 활성화 함수 값을 32비트 부동소수점(FP32)에서 저정밀도 정수(INT8, INT4 등)로 데이터 타입을 변환하는 기술
- 이유: 대부분의 하드웨어(CPU, NPU)에서 정수 연산이 부동소수점 연산보다 훨씬 빠르고 전력 효율적이기 때문
B. 양자화 종류
- PTQ (Post-Training Quantization): 학습이 완료된 모델에 적용, 간편하지만 정확도 하락 가능성 있음
- Dynamic Quantization: 가중치는 미리 양자화, 활성화 값은 추론 시 동적으로 변환. 적용이 가장 간편
- Static Quantization: 가중치와 활성화 값 모두 미리 양자화. 대표 데이터(Calibration set)를 통해 활성화 값의 통계(최소/최대값)를 미리 계산. 추론 속도가 더 빠름
- QAT (Quantization-Aware Training): 학습 과정에서 양자화로 인한 오차를 미리 시뮬레이션하며 훈련. PTQ보다 정확도가 높지만, 학습 과정이 복잡하고 오래 걸림
C. PyTorch 데이터 타입과 양자화
- 양자화는
torch.float32로 표현되는 파라미터를torch.int8과 같은 저정밀도 타입으로 변환하는 핵심 과정
| 데이터 타입 | 설명 | 범위 (예시) |
|---|---|---|
torch.float32 | 32비트 부동소수점 (기본) | -3.4e38 ~ 3.4e38 |
torch.float16 | 16비트 부동소수점 | -65504 ~ 65504 |
torch.int8 | 8비트 부호 있는 정수 | -128 ~ 127 |
torch.uint8 | 8비트 부호 없는 정수 | 0 ~ 255 |
2. 모델 변환 및 배포
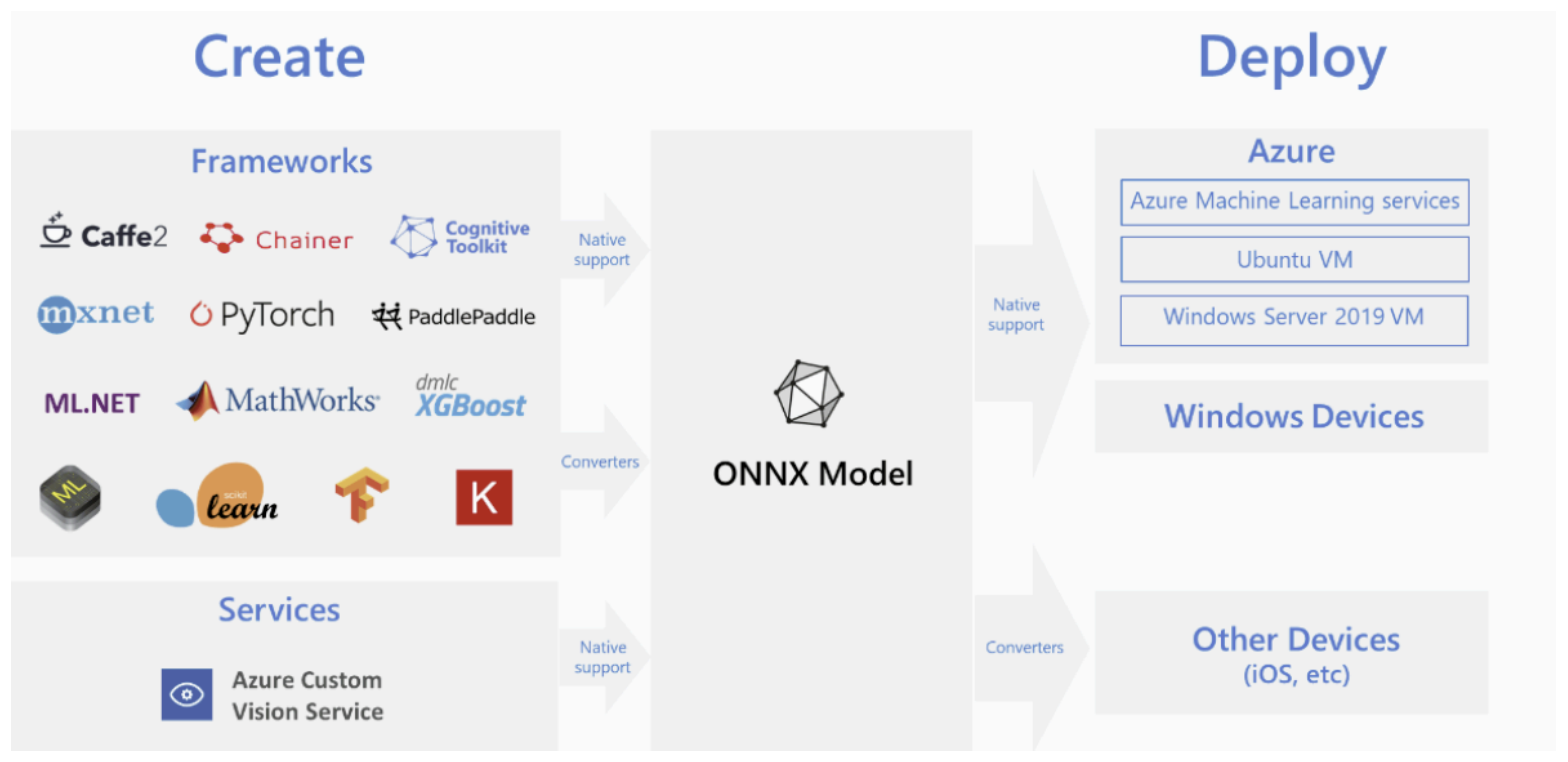
(1) 개요
A. 목적
- 학습 환경(e.g., Python, PyTorch)에서 개발된 모델을 실제 서비스가 이루어지는 배포 환경(e.g., 서버, 모바일, 웹)으로 이전하는 과정
- 이 과정에서 추론 성능 최적화 및 타겟 하드웨어와의 호환성 확보가 중요
(2) 변환 워크플로우
A. 일반적인 과정
- 1단계: 학습 프레임워크(PyTorch 등)에서 모델 학습 및 최적화(Pruning, Quantization) 완료
- 2단계: ONNX와 같은 중간 표현(Intermediate Representation, IR) 포맷으로 모델 변환
- 3단계: 타겟 환경에 맞는 추론 엔진(TensorRT, TFLite 등)을 사용하여 ONNX 모델을 한번 더 변환 및 최적화
- 4단계: 최종 변환된 모델을 애플리케이션에 탑재하여 배포
(3) 주요 변환 프레임워크
A. 종류 및 특징
| 프레임워크 | 주요 용도 | 개발사 | 특징 |
|---|---|---|---|
| ONNX | 프레임워크 간 모델 교환 | Microsoft, Meta 등 | 다양한 프레임워크 지원, 중간 다리 역할 |
| TFLite | 모바일/임베디드 기기 | 경량화, Android/iOS 및 엣지 디바이스 | |
| TensorRT | NVIDIA GPU 추론 가속 | NVIDIA | 저지연, 고성능 추론에 최적화 |
| CoreML | Apple 기기 | Apple | iOS, macOS 등 애플 생태계에 통합 |
3. 이진법과 데이터 표현
(1) 컴퓨터와 이진법
A. 기본 개념
- 컴퓨터는 모든 정보를 0과 1의 조합인 이진법(binary)으로 처리하고 저장
- 0과 1은 전기의 ON/OFF 상태에 직접 대응되어 물리적으로 구현하기 용이하기 때문
B. 비트(Bit)와 바이트(Byte)
- 비트(Bit): 정보의 최소 단위, 0 또는 1 하나의 값을 저장할 수 있는 공간
- 바이트(Byte): 8개의 비트를 묶은 단위, 1 바이트는 가지의 정보를 표현 가능
(2) 정수 표현 방식
A. 부호 없는 정수 (Unsigned Integer)
- 0과 양의 정수만을 표현하는 방식
- n개의 비트는 0부터 까지의 범위를 가짐
- 예시 (8비트): 십진수 13 → 이진수
00001101
B. 부호 있는 정수 (Signed Integer)
- 양수, 음수, 0을 모두 표현하는 방식
- 최상위 비트(MSB, Most Significant Bit)를 부호 비트로 사용 (0: 양수, 1: 음수)
- 2의 보수(Two's Complement) 표현법이 컴퓨터 구조의 표준으로 사용됨
- 음수를 만드는 법: 원래 수의 모든 비트를 반전(1은 0으로, 0은 1로)시킨 뒤 1을 더함
- 예시 (8비트): -13 표현하기
- 13의 이진수:
00001101
- 13의 이진수:
- 비트 반전 (1의 보수):
11110010
- 비트 반전 (1의 보수):
- 1 더하기 (2의 보수):
11110011
- 1 더하기 (2의 보수):
- 2의 보수 방식을 사용하면 덧셈 연산만으로 뺄셈을 구현할 수 있어 하드웨어적으로 매우 효율적
(3) 실수 표현 방식
A. 부동소수점 (Floating-Point)
- 실수를 컴퓨터에서 근사하여 표현하는 표준 방식 (IEEE 754)
- 하나의 실수를
부호(Sign),지수(Exponent),가수(Mantissa)세 부분으로 나누어 저장- 부호(Sign): 1비트, 양수(0) 또는 음수(1)를 결정
- 지수(Exponent): 수의 크기(소수점의 위치)를 나타내는 부분
- 가수(Mantissa/Fraction): 수의 정밀도(실제 숫자)를 나타내는 부분
- 예시:
float32는 부호 1비트, 지수 8비트, 가수 23비트로 구성됨
(4) 딥러닝 모델과의 연관성
A. 데이터 타입과 정밀도
- 딥러닝 모델의 가중치는 기본적으로
float32(32비트 부동소수점)로 저장됨 - 양자화(Quantization)는 이 32비트짜리 실수를
int8(8비트 정수) 등 더 적은 비트를 사용하는 데이터 타입으로 변환하는 과정 - 사용하는 비트 수가 줄어들면 모델의 크기가 작아지고, 하드웨어에 따라 정수 연산이 더 빨라 추론 속도가 향상됨
| 데이터 타입 | 총 비트 수 | 표현 방식 | 주요 범위 | 딥러닝에서의 용도 |
|---|---|---|---|---|
uint8 | 8 | 부호 없는 정수 | 0 ~ 255 | 이미지 픽셀 값, 양자화 |
int8 | 8 | 2의 보수 정수 | -128 ~ 127 | 양자화된 가중치/활성화 |
float16 | 16 | 부동소수점 | 약 -6.5e4 ~ 6.5e4 | 혼합 정밀도 학습, 모델 경량화 |
float32 | 32 | 부동소수점 | 약 -3.4e38 ~ 3.4e38 | 일반적인 모델 가중치 (기본) |
4. 최적화 실습 예제: Pruning
(1) CNN 모델 정의 및 학습
A. MNIST 분류 모델
- Pruning을 적용하기 위한 기본 모델을 생성하고 간단히 학습
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 1. CNN 모델 만들기
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, stride=1, padding=1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(in_features=64 * 7 * 7, out_features=10)
def forward(self, x):
x = self.pool1(self.relu1(self.conv1(x)))
x = self.pool2(self.relu2(self.conv2(x)))
x = x.view(-1, 64 * 7 * 7)
x = self.fc1(x)
return x
# 2. MNIST 데이터셋 학습
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
model = SimpleCNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
def train(model, train_loader, optimizer, criterion):
model.train()
for data, target in train_loader:
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train(model, train_loader, optimizer, criterion)
print("MNIST 데이터셋 학습 완료!")
(2) 가중치 Pruning 적용
A. torch.nn.utils.prune 사용법
module: Pruning을 적용할 레이어 지정 (e.g.,model.conv1)name: 해당 레이어에서 Pruning할 파라미터 이름 지정 (보통'weight')amount: 제거할 파라미터의 비율 (e.g.,0.3은 30%를 의미)l1_unstructured함수는 L1-norm 기준의 비정형 Pruning을 수행
B. 영구적 제거
- Pruning을 적용하면 실제 가중치는 그대로 있고,
weight_mask가 생성되어 연산에서 제외시키는 방식 prune.remove를 호출해야 마스크가 실제 가중치에 적용되어 0으로 바뀌고, 마스크 버퍼가 사라져 모델 구조가 영구적으로 변경됨
import torch.nn.utils.prune as prune
module = model.conv1
prune.l1_unstructured(module, name="weight", amount=0.3)
print("프루닝 마스크 적용 후 버퍼:", list(module.named_buffers()))
prune.remove(module, 'weight')
print("Pruning 완료! 마스크 제거 후 버퍼:", list(module.named_buffers()))
(3) 전체 최적화 파이프라인
A. 일반적인 순서
- 1단계: 기본 모델 학습
- 2단계: 모델 Pruning 적용
- 3단계: Pruning으로 인한 성능 저하를 복구하기 위해 Fine-tuning (추가 학습)
- 4단계: Fine-tuning된 모델에 Quantization 적용 (PTQ 또는 QAT)
- 5단계: 최종 최적화된 모델을 ONNX 등으로 변환하여 배포

AI Engineer