신기한 가중치의 세계
학습시간 09:00~02:00(당일17H/누적1877H)
◆ 학습내용
모델 배포 실습
-
아래의 3가지 타입의 모델로 변환하여 저장
.pth (PyTorch 기본 저장 형식).pth (양자화 된 버전).onnx (ONNX 형식)
-
ONNX 파일을 기반으로 하여 추론 코드를 작성
-
모델에 적절한 평가 데이터셋을 사용해 동작 검증
1. 데이터 & 모델 준비
오랜만에 하는 미션이다. 이번에는 ONNX 파일과 친해지고 양자화된 가중치를 만들어 보는 것이 핵심인 것 같다.
마음 같아선 막 배운 도커를 적용해서 해보고 싶지만,,, 다음 프로젝트 때 연습할 시간이 있을 것 같으니 그때 하자.
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.quantization
import torch.onnx
from tqdm.notebook import tqdm일단 필요한 라이브러리를 로드한다. 핵심은 torch.quantization, torch.onnx인 것으로 보인다.
tqdm의 새로운 사용법을 찾았는데 이것도 이번에 적용해 봐야겠다.
""" 데이터 로더 함수 """
def get_dataloader(batch_size):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.MNIST(root='./data', train=True, download=False, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=False, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
return train_loader, test_loader데이터로더를 리턴하는 함수를 만들었다. 원래 함수로 만들지는 않았는데, 이렇게 하니까 뭔가 가독성도 좋고... 유지보수에 좋아 보이는 게 암튼 내 스타일이다.
원래 미션에서는 그동안 만들었던 모델 중 하나를 가져오라고 했는데, 뭐가 괜찮나 찾아보기 귀찮아서 그냥 MNIST로 처음부터 다시 만들기로 결정했다.
train_loader, test_loader = get_dataloader(batch_size=64)배치는 64 정도로 하면 되겠지?
""" 모델 클래스 """
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
)
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
)
self.fc = nn.Linear(32*7*7, 10)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = x.view(-1, 32*7*7)
x = self.fc(x)
return x
model = SimpleCNN()오랜만에 만드는 CNN 모델이다.
간단하게 conv 레이어와 fc 레이어로 구성했다.
2. 모델 학습
""" 학습 & 평가 함수 """
def train_model(model, train_loader, test_loader, criterion, optimizer, epochs):
total_steps = len(train_loader) * epochs
with tqdm(total=total_steps, desc="Progress") as progress_bar:
for epoch in range(epochs):
# Train
model.train()
total_loss = 0.0
for images, labels in train_loader:
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
progress_bar.update(1)
progress_bar.set_postfix(epoch=f'{epoch+1}/{epochs}', loss=f'{loss.item():.4f}')
avg_loss = total_loss / len(train_loader)
# Evaluate
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
progress_bar.write(f'[{epoch+1}/{epochs}] Train Loss: {avg_loss:.4f} | Test Acc: {accuracy:.2f} %')
return model학습과 평가를 진행할 함수다. 늘 하던 것과 똑같은데, tqdm으로 progress bar를 만들었다는 게 조금 다르다. update, set_postfix를 사용하면 진행상황을 멋지게 볼 수 있다고 한다!! 빨리 보고 싶구만!
train = train_model(
model=model,
train_loader=train_loader,
test_loader=test_loader,
criterion=nn.CrossEntropyLoss(),
optimizer=optim.Adam(model.parameters(), lr=0.001),
epochs=3
)3에폭만 돌려보자. 과연 어떻게 나올 것인가!?

오 진행상황을 알려주는 bar가 평소와 다른 모습이다. 멋진데?
postfix는 꼭 필요한 게 아니면 굳이 안 해도 될 것 같다.

3에폭만 돌렸는데도 정확도가 98.81%가 나온다. 좋다 좋아.
3. 가중치 저장
""" 모델 저장 함수 """
def save_model(model, file_name):
model.eval()
# pt 저장
torch.save(model.state_dict(), f'{file_name}.pt')
print(f'{file_name}.pt Save Complete')
# pth 저장
model_to_quantize = SimpleCNN()
model_to_quantize.load_state_dict(model.state_dict())
model_to_quantize.eval()
quantized_model = torch.quantization.quantize_dynamic(
model_to_quantize,
{nn.Linear, nn.Conv2d},
dtype=torch.qint8
)
torch.save(quantized_model.state_dict(), f'{file_name}.pth')
print(f'{file_name}.pth Save Complete')
# ONNX 저장
dummy_input = torch.randn(1, 1, 28, 28) # B, C, H, W
onnx_path = f'{file_name}.onnx'
torch.onnx.export(
model,
dummy_input,
onnx_path,
verbose=False,
input_names=['input'],
output_names=['output']
)
print(f'{file_name}.onnx Save Complete')
모델 가중치를 3개 타입으로 저장하는 함수다.
1번은 pth로 저장하라고 했는데 그냥 pt로 했다.
2번 pth 양자화는 qint8이 국룰이라 해서 이걸로 했다.
3번 ONNX는 더미인풋으로 배치, 채널, 이미지 사이즈를 넣어줘야 한다.
save_model(train, 'model')저장해 보자!
저장 완료!
file_list = ['model.pt', 'model.pth', 'model.onnx']
for file_name in file_list:
size_in_bytes = os.path.getsize(file_name)
size_in_mb = size_in_bytes / (1024 * 1024)
print(f'{file_name}: {size_in_mb:.2f} MB')용량을 비교해 보자. 양자화된 pth 파일의 용량이 가장 낮아야 정상인데,,!
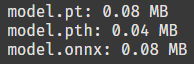
오! 확실히 양자화된 pth 파일이 다른 파일보다 용량이 2배나 낮다. 좋군!!
