처음으로 나만의 알고리즘 같은 것을 만들었다. 간단해도 고려할 게 많다. 무언가를 자동화 한다는 건 참 매력적이지만 그만큼 미리 계획을 짜둘 게 많은 것 같다.
학습시간 09:00~03:00(당일18H/누적2096H)
◆ 학습내용
영화 리뷰 AI 분석 웹앱 구현하기!
어제에 이어 6번 부터 시작!
6. AI 모델 개선
어제 리뷰 수정하는 기능까지 구현을 했다.
근데 큰 문제가 생겼다. 평점 기능이 제대로 작동하지 않는다.
일단 어느 상황에서 문제가 생기는지 테스트 해보자.
- 부정 리뷰 테스트

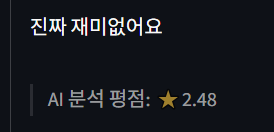

부정적인 리뷰만 보면 큰 문제처럼 보이진 않는다.
마지막 리뷰는 더 강한 부정 느낌으로 적었는데 의도한 대로 평점이 떨어진 것 같다...?
그럼 잘 작동하는 건가??
- 긍정 리뷰 테스트

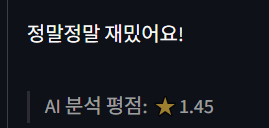
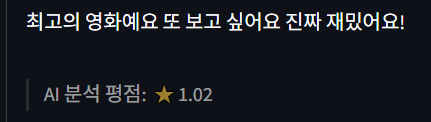
긍적적인 리뷰는 처참하다. 긍정에 가까워질 수록 평점이 낮아지는 이상한 현상이 보인다.
뭐가 문제지?
긍정에 가까울 수록 모델 아웃풋 수치가 0에 가까워지는 구조인가??
고민할 게 아니라 모델을 먼저 테스트하는 게 맞는 순서인 것 같다.
모델 아웃풋이 어떤 형식으로 나오는지 확인해 보자.
from transformers import pipeline
sentiment_pipeline = pipeline(
"sentiment-analysis",
model="tabularisai/multilingual-sentiment-analysis",
)
test_sentences = [
# 긍정 리뷰
"진짜 최고의 영화예요. 꼭 보세요 두 번 보세요!",
"정말 정말 재밌어요!",
"재밌어요!",
# 부정 리뷰
"정말 최악의 영화. 돈이 너무 아까워요.",
"너무 지루해서 보다가 잠들었어요.",
"재미없어요",
# 애매한 리뷰
"그냥 그럭저럭 볼만했어요.",
"기대했던 것과는 조금 다르네요.",
]
for sentence in test_sentences:
result = sentiment_pipeline(sentence)
print(f"문장: {sentence}")
print(f"예측: {result}")
print("\n")tabularisai/multilingual-sentiment-analysis 모델을 테스트 하기 위해 test.py 파일을 새로 만들었다.
만약 여기서 감성 분석을 제대로 하지 못한다면 모델 성능에 문제가 있다는 뜻일 것이다.
근데 허깅페이스 다운로드 1위 모델인데 과연 성능이 부족할까..? 일단 테스트를 해봐야 알겠지.
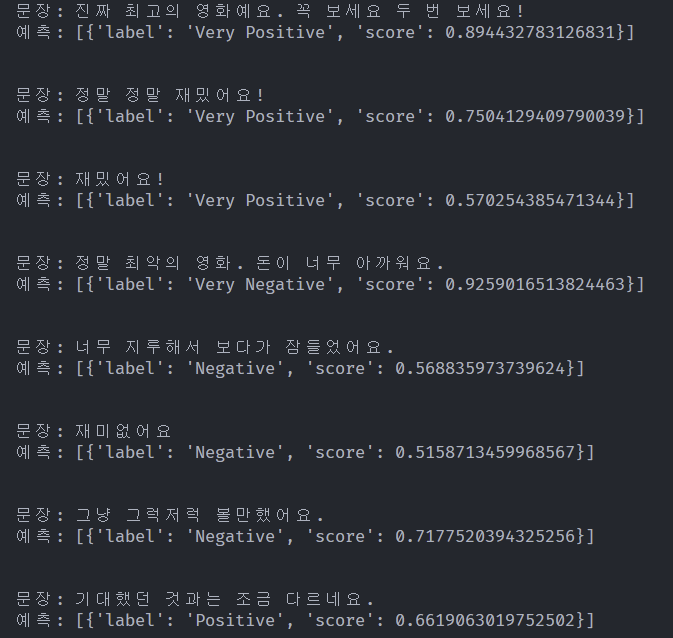
테스트 결과가 나왔다.
가만 보니까 스코어 점수가 곧 긍부정을 나타내지 않는다. 가장 높은 수치인 0.925는 Very Negative라는 라벨을 가지고 있다.
그렇다는 건 아웃풋 숫자는 라벨에 대한 확신도를 나타내는 것이기에, 높을 수록 긍정이 아니라 그냥 해당 라벨을 잘 감지했다는 뜻이 된다.
그럼 평점이 이상하게 나오는 것도 이해가 된다. 라벨을 먼저 확인하고 그다음 스코어를 반영해야 하는데, 나는 그냥 스코어만 가져다 썼으니 라벨 간의 수치 파악에 문제가 됐을 수밖에 없다.
라벨은 총 몇 개가 있지??

허깅페이스에 들어가 보니 해당 모델은 총 5개의 라벨이 있다고 한다.
흠, 그렇다면 라벨에 대한 결과치를 각각 계산해서 0~10점으로 환산되도록 코드를 짜면 될 것 같다.
어떻게 하면 좋을까?
생각해 보자!
나에겐 라벨이 5개 있고 각 라벨마다의 확신도가 있다.
라벨로 점수를 1차적으로 분류하면 어떨까?
Very Positive = 10
Positive = 7.5
Neutral = 5
Negative = 2.5
Very Negative = 0
이렇게 하면 라벨 만으로도 충분히 긍부정 분류 및 점수 측정이 가능할 것이다.
하지만 이렇게 하면 세세한 점수 표현이 어렵겠지. 게다가 확신도를 이용하지 못하게 되니 이건 반쪽짜리 분류에 불과하다.
어떻게 해야 확신도를 라벨에 추가할 수 있을까?
흠,,,,,,,,,,,,
Very Positive = 8 + (확신도 X 2)
Positive = 6 + (확신도 X 2)
Neutral = 4 + (확신도 X 2)
Negative = 2 + (확신도 X 2)
Very Negative = 0 + (확신도 X 2)
이렇게 하면 어떨까?
확신도는 0~1 사이 값으로만 존재하기에, 곱하기 2를 해주면 0~2 범위를 가지는 수치가 된다.
그렇다는 건 기준점만 라벨로 5등분 해주면 평점 0~10을 구현할 수 있다는 뜻이다. 물론 10점 만점을 줄 확률이 낮다는 게 흠이긴 하지만,, 이정도면 괜찮지 않을까?
앗 근데 생각해 보니까 문제가 있다. 모델이 라벨을 잘못 분류하면 어쩌지?
계산을 해보자.
- "최악의 영화"가 Negative 0.8 이라면 평점은 3.6이 된다.
- "최악 최악 최악의 영화" Very Negative 0.8 이라면 평점은 1.6이 된다.
- 그러나, "최악의 영화"가 라벨링이 Very Negative 0.7로 분류된다면 평점은 1.4가 된다.
결국, 모델이 라벨링을 잘못하면 부정적인 리뷰에 가까울 수록 0~4점 구간에서 더 높은 평점을 가지게 된다.
Very Positive = 8 + (확신도 X 2)
Positive = 6 + (확신도 X 2)
Neutral = 4 + (확신도 X 2)
Negative = 4 - (확신도 X 2)
Very Negative = 2 - (확신도 X 2)
그럼 이렇게 하면 어떨까? 0~4점 Negative 구간은 확신도를 더하는 게 아니라 빼주는 거다.
- "최악의 영화"가 Negative 0.8 이라면 평점은 2.4가 된다.
- "최악 최악 최악의 영화" Very Negative 0.8 이라면 평점은 0.4이 된다.
- "최악의 영화"가 라벨링이 Very Negative 0.7로 분류된다면 평점은 0.6이 된다.
됐다! 이제 꽤 그럴듯한 로직이 됐다!! 이렇게 코드를 짜서 적용해보자!!
@app.post("/movies/{movie_id}/reviews/", response_model=Review)
def create_review_for_movie(movie_id: int, review: ReviewCreate, session: Session = Depends(get_session)):
movie = session.get(Movie, movie_id)
if not movie:
raise HTTPException(status_code=404, detail="Movie not found")
result = sentiment_pipeline(review.review_text)[0]
label = result['label']
confidence = result['score']
if label == 'Very Positive':
final_score_10 = 8 + (2 * confidence)
elif label == 'Positive':
final_score_10 = 6 + (2 * confidence)
elif label == 'Neutral':
final_score_10 = 4 + (2 * confidence)
elif label == 'Negative':
final_score_10 = 4 - (2 * confidence)
else: # Very Negative
final_score_10 = 2 - (2 * confidence)
final_score_10 = max(0, min(10, final_score_10))
sentiment_score = final_score_10
db_review = Review.model_validate(review, update={"movie_id": movie_id, "sentiment_score": sentiment_score})
session.add(db_review)
session.commit()
session.refresh(db_review)
return db_review리뷰를 작성했을 때 평점을 구하는 API를 다시 만들었다.
리뷰를 수정하면 평점을 다시 구하는 API도 이거랑 비슷하게 만들었다.
@app.get("/movies/{movie_id}/rating")
def get_movie_rating(movie_id: int, session: Session = Depends(get_session)):
reviews = session.exec(select(Review).where(Review.movie_id == movie_id)).all()
if not reviews:
return {"average_rating": 0.0}
total_score = sum(review.sentiment_score for review in reviews)
average_rating = total_score / len(reviews)
return {"average_rating": average_rating}이번엔 평균 평점을 구하는 API다.
모든 리뷰의 평점을 더하고 총 개수로 나눈 값을 리턴한다.
with st.container(border=True):
st.markdown(f"**작성자: {review['author']}**")
st.write(review['review_text'])
rating = review['sentiment_score']
st.markdown(f"> AI 분석 평점: ⭐{rating:.2f}")프론트엔드에 평점 나오는 코드도 살짝 손봤다.
평점을 잘 예측하는지 테스트 해보자!
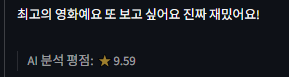
오!! 잘 나오는 것 같은데?? 몇 개만 더 해보자.
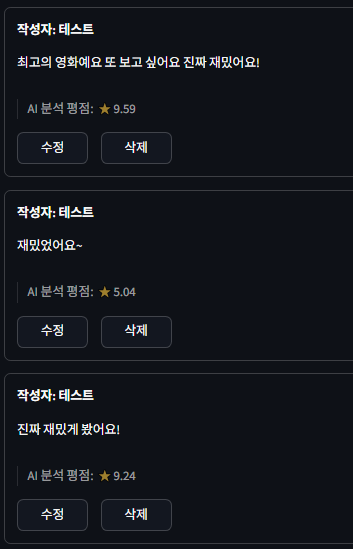
적극적으로 긍정적일수록 10점에 가까워진다.
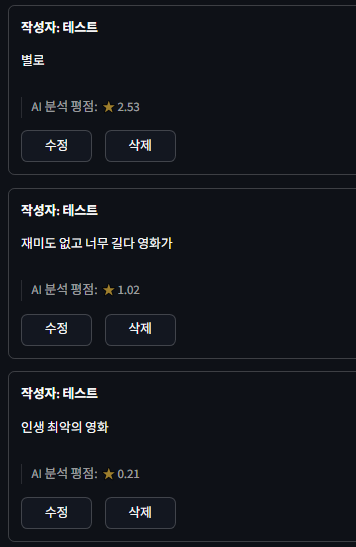
부정적인 리뷰일수록 0점에 가깝다.
이정도면 모델을 이용한 리뷰 점수 평가 알고리즘도 잘 만들어진 것 같다.
이번에는 모델을 양자화해서 다시 로드해 보자.
물론 성능은 소폭 감소하겠지만,,, 양자화 경험을 쌓기 위해!
model_id = "tabularisai/multilingual-sentiment-analysis"
onnx_path = "onnx_model"
# 모델 & 토크나이저 다운로드
model = ORTModelForSequenceClassification.from_pretrained(model_id, export=True)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 양자화 설정
qconfig = AutoQuantizationConfig.avx512_vnni(is_static=False, per_channel=False)
# 퀀타이저 생성
quantizer = ORTQuantizer.from_pretrained(model, "text-classification")
# 모델 양자화 및 저장
quantizer.quantize(save_dir=onnx_path, quantization_config=qconfig)
# 토크나이저 저장
tokenizer.save_pretrained(onnx_path)quantizer.py 파일을 새로 하나 만들었다.
onnxruntime과 transformers 패키지를 이용해서 모델을 다운로드 후 ONNX 파일로 변환한다.
CPU에서 양자화 후 모델을 돌릴 땐 avx512_vnni를 사용하면 좋다고 한다.
여기서 avx는 Advanced Vector Extensions 이고, vnni는 Vector Neural Network Instructions 이다.
모델이 FP32타입인데, 이렇게 하면 FP32를 계산 시에 qint8타입으로 변환해서 계산 후 다시 FP32로 변환해 준다고 한다.
python quantizer.py실행!
OnnxExporterWarning: Symbolic function 'aten::scaled_dot_product_attention' already registered for opset 14. Replacing the existing function with new function. This is unexpected.
경고 메시지가 2개 떴다. 일단 변환 규칙이 중복으로 발견되어서 새로운 펑션으로 대체했다고 한다. 흠...
TracerWarning: torch.tensor results are registered as constants in the trace. You can safely ignore this warning if you use this function to create tensors out of constant variables that would be the same every time you call this function. In any other case, this might cause the trace to be incorrect.
모델 내부에서 고정된 값을 사용해서 텐서를 만든다고 한다. 무시해도 되는 경고라고 한다. 과연 정말 무시해도 되는 경고인 걸까...
어쨌든 코드를 실행시키고 나니 onnx_model 폴더에 ONNX 파일과 토크나이저가 생겼다.
모델 용량이 130MB다. 원본이랑 얼마나 차이가 날까?
원본 용량은 541MB다. 대충 계산해도 양자화 후 무려 4배 이상 감소한 셈이다.
성능만 크게 감소하지 않았으면 좋겠는데!!
백엔드에 심기 전에 성능 테스트를 먼저 해보자.
test_sentences = [
# 긍정 리뷰
"진짜 최고의 영화예요. 꼭 보세요 두 번 보세요!",
"정말 정말 재밌어요!",
"재밌어요!",
# 부정 리뷰
"정말 최악의 영화. 돈이 너무 아까워요.",
"너무 지루해서 보다가 잠들었어요.",
"재미없어요",
# 애매한 리뷰
"그냥 그럭저럭 볼만했어요.",
"기대했던 것과는 조금 다르네요.",
]
# 원본 모델
original_pipeline = pipeline(
"sentiment-analysis",
model="tabularisai/multilingual-sentiment-analysis",
)
# 양자 모델
onnx_model_path = "./onnx_model/"
model = ORTModelForSequenceClassification.from_pretrained(onnx_model_path)
tokenizer = AutoTokenizer.from_pretrained(onnx_model_path)
onnx_pipeline = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
# 응답 비교
for sentence in test_sentences:
result_original = original_pipeline(sentence)[0]
result_onnx = onnx_pipeline(sentence)[0]
print(f"문장: {sentence}")
print(f"원본 예측: {result_original}")
print(f"양자 예측: {result_onnx}")
print("-" * 20)
아까 만들었던 test.py에 코드를 일부 추가했다.
이걸로 동일 인풋에 대해 원본&양자화 모델 각각의 아웃풋 라벨과 확신도를 비교할 수 있을 거다.
python test.py실행!
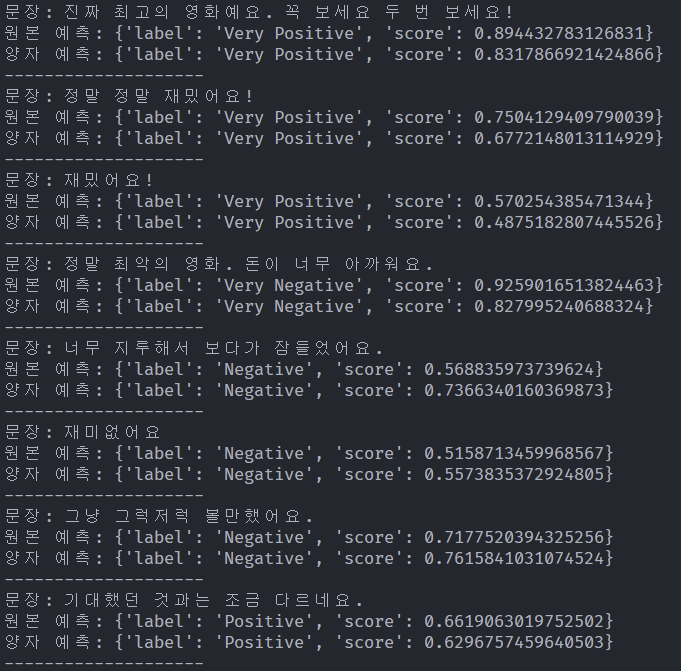
결과가 나왔다.
두 모델의 라벨 결과가 정확히 일치한다. 확신도는 조금씩 감소한 것처럼 느껴지는데, 또 어떤 라벨은 더 높게 나오기도 한다. 큰 차이는 없는 듯하다.
이대로 백엔드에 추가해 보자.
# 감성 분석 파이프라인
# tabularisai/multilingual-sentiment-analysis
onnx_model_path = "./onnx_model/"
model = ORTModelForSequenceClassification.from_pretrained(onnx_model_path)
tokenizer = AutoTokenizer.from_pretrained(onnx_model_path)
sentiment_pipeline = pipeline(
"sentiment-analysis",
model=model,
tokenizer=tokenizer,
)onnx_model 폴더 내에 있는 모델과 토크나이저를 로드하도록 코드를 변경했다.
서버를 다시 켜서 확인해 보자!
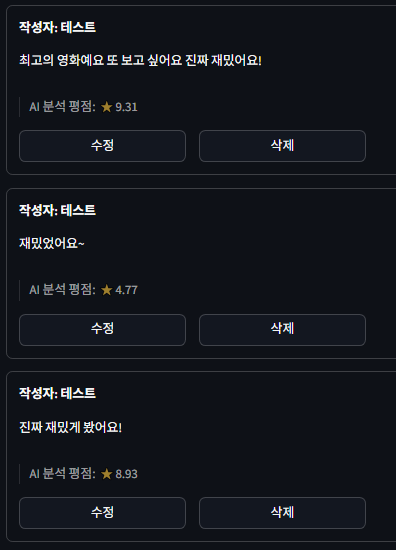
들어가서 수정을 한번씩 눌러줬더니 평점이 현재 모델이 계산한 값으로 변경되었다.
원본과 비교를 해보자.
리뷰: 최고의 영화예요 또 보고 싶어요 진짜 재밌어요!
원본: 9.59
양자: 9.31리뷰: 재밌었어요~
원본: 5.04
양자: 4.77리뷰: 진짜 재밌게 봤어요!
원본: 9.24
양자: 8.93
긍정적인 리뷰에서는 전반적으로 점수가 소폭 하락했다. 이건 확신도가 감소했기 때문일 것이다.
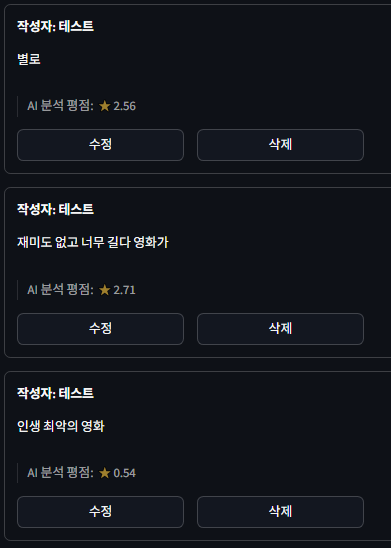
부정적인 리뷰도 수정을 한번씩 눌러서 평점을 새로고침 했다.
원본과 비교를 해보자.
리뷰: 별로
원본: 2.53
양자: 2.56리뷰: 재미도 없고 너무 길다 영화가
원본: 1.02
양자: 2.71리뷰: 인생 최악의 영화
원본: 0.21
양자: 0.54
부정적인 리뷰 쪽에서는 전반적으로 평점이 올랐다. 이 또한 확신도가 감소했기 때문일 것이다. 4점 이하부터는 확신도를 마이너스 해주는 알고리즘이라서 그렇다.
두 번째 리뷰는 점수가 1.7점 가량 올랐는데, 이건 아예 라벨을 다른 것으로 예측한 것 같다.
그래도 큰 맥락에서 보면 양자화 모델 또한 원본 모델 못지 않게 긍정과 부정을 잘 분류하는 것 같다.
영화를 하나씩 다 들어가서 리뷰 작업을 했다.
평점이 다 달려있으니까 이제 좀 사이트처럼 보이네..!
아직 미흡한 점이 많지만,,, 시간이 없어서 여기서 마무리 해야할 것 같다.
그래도 다 만들고 나니까 뿌듯하다. 큰 서비스는 이거보다 천 배는 힘들겠지?
마지막 미션도 어찌어찌 완료다.. ㅠㅠ
