
RNN 사용한 삼성전자 주가 분석
RNN 선택 이유
이유는 없다. 본 코드는 학교 실습 시간에 제공 받은 것인데, 평소 주식에 대한 관심의 연장선으로 금융 공학에 대한 흥미가 생겨 공부 해보기로 했다.
코드 시작
import torch
import torch.nn as nn
import pandas as pd
samsung = pd.read_csv('해당주소 ㅎㅎ')파이썬을 기본으로 pytorch를 이용한 RNN을 사용할 것이며, samsung 전자의 데이터는 krx에서 가져왔다. 기본적으로 csv 다운로드를 하면 ['Date', 'Open', 'High', 'Low', 'Close', 'Adj Close', 'Volume']를 column으로 갖는 파일이다.
#DataNormalization Scaler
from sklearn.preprocessing import MinMaxScaler, StandardScaler
scaler = MinMaxScaler()
samsung[['Open','High', 'Low', 'Close', 'Volume']]=scaler.fit_transform(samsung[['Open','High', 'Low', 'Close', 'Volume']])
samsung.head() 삼성전자의 주가는 2018-01-02부터 2024-01-11까지 1468개의 시계열 데이터를 활용했다. 중간에 incomplete datapoint들은 mean값으로 채우거나 하지 않고 과감하게 삭제했다.
import numpy as np
import torch.optim as optim
import matplotlib.pyplot as plt
#Activate Gpu computing
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(f'{device} is available') 사실 아직 gpu 연결 안했다 하하
X = samsung[['Open','High', 'Low', 'Volume']].values
y= samsung['Close'].values X는 행렬이기 때문에 대문자로 표현했다(그렇게 하라고 하더라)
def seq_data(x, y, sequence_length):
x_seq =[]
y_seq =[]
for i in range(len(x)-sequence_length):
x_seq.append(x[i: i+sequence_length])
y_seq.append(y[i+sequence_length])
x_seq =np.array(x_seq)
y_seq = np.array(y_seq)
return torch.FloatTensor(x_seq).to(device), torch.FloatTensor(y_seq).to(device).view([-1,1])시퀀스 만드는 것을 정의한 것, return은 torch로
split = 500
sequence_length = 5
x_seq, y_seq = seq_data(X, y, sequence_length)
x_train_seq =x_seq[:split]
y_train_seq = y_seq[:split]
x_test_seq = x_seq[split:]
y_test_seq = y_seq[split:]
print(x_train_seq.size(), y_train_seq.size())
print(x_test_seq.size(), y_test_seq.size()) test는 500개로 진행하고 print된 결과는 다음과 같을 것이다. => torch.Size([500, 5, 4]) torch.Size([500, 1]), torch.Size([965, 5, 4]) torch.Size([965, 1])
왜 500+965=1465로 1468개가 아니지?
일단 위에 나온 수는 데이터의 수가 아니라 sequence의 수이다.
그리고 5개씩 끊기 때문에 => ...[1462, 1463, 1464, 1465, 1466], [1463, 1464, 1465, 1467, 1468]처럼 마무리 된다.
train=torch.utils.data.TensorDataset(x_train_seq, y_train_seq)
test = torch.utils.data.TensorDataset(x_test_seq, y_test_seq)
batch_size=20
train_loader = torch.utils.data.DataLoader(dataset=train, batch_size=batch_size, shuffle=False)
test_loader = torch.utils.data.DataLoader(dataset=test, batch_size=batch_size, shuffle=False)
input_size=x_seq.size(2)
num_layers =2
hidden_size=8timeseries 데이터이기 때문에 shuffle = False이고 x_seq.size(2) = 4이다(volume, open, high, low).
VanillaRNN 코드
class VanillaRNN(nn.Module):
def __init__(self, input_size, hidden_size, sequence_length, num_layers, device):
super(VanillaRNN, self).__init__()
self.device = device
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Sequential(
nn.Linear(hidden_size * sequence_length, 1),
nn.Sigmoid()
)
def forward(self, x):#input이 들어왔을때 output설정해주는
h0 = torch.zeros(self.num_layers, x.size()[0], self.hidden_size).to(self.device)
out, _ = self.rnn(x, h0)
out= out.reshape(out.shape[0], -1)
out= self.fc(out)
return out
model = RNN(input_size = input_size,
hidden_size=hidden_size,
sequence_length=sequence_length,
num_layers=num_layers,
device=device).to(device)input을 flattened sequence of feature vectors)로 바꾸고, processes it through a linear layer to reduce it to a single value, apply a Sigmoid function to squash this value between 0 and 1. 그리고 forward 함수는 output을 설정해주는 과정이다.
criterion = nn.MSELoss()
lr = 1e-3
num_epochs = 500
optimizer = optim.Adam(model.parameters(), lr = lr)
loss_graph = []
n=len(train_loader)
for epoch in range(num_epochs):
running_loss = 0.0
for data in train_loader:
seq, target = data
out = model(seq)
loss=criterion(out, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
loss_graph.append(running_loss/n)
if epoch % 50 ==0: #50번마다 확인
print('[epoch: %d] loss: %.4f'%(epoch, running_loss/n))우리는 Adam을 이용해서, loss를 줄이기 위해 뉴럴네트워크의 attributes들을 업데이트 해주겠다. 실제값과 비교하여 얼마나 잘 학습하고 있는지 그래프를 그려주는 코드가 밑에서 이어진다.귀찮으니까 그래프 생략<
def plotting(train_loader, test_loader, actual):
with torch.no_grad():
train_pred =[]
test_pred = []
for data in train_loader:
seq, target = data
out = model(seq)
train_pred += out.cpu().numpy().tolist()
for data in test_loader:
seq, target = data
out = model(seq)
test_pred += out.cpu().numpy().tolist()
total = train_pred + test_pred
plt.figure(figsize=(10,6))
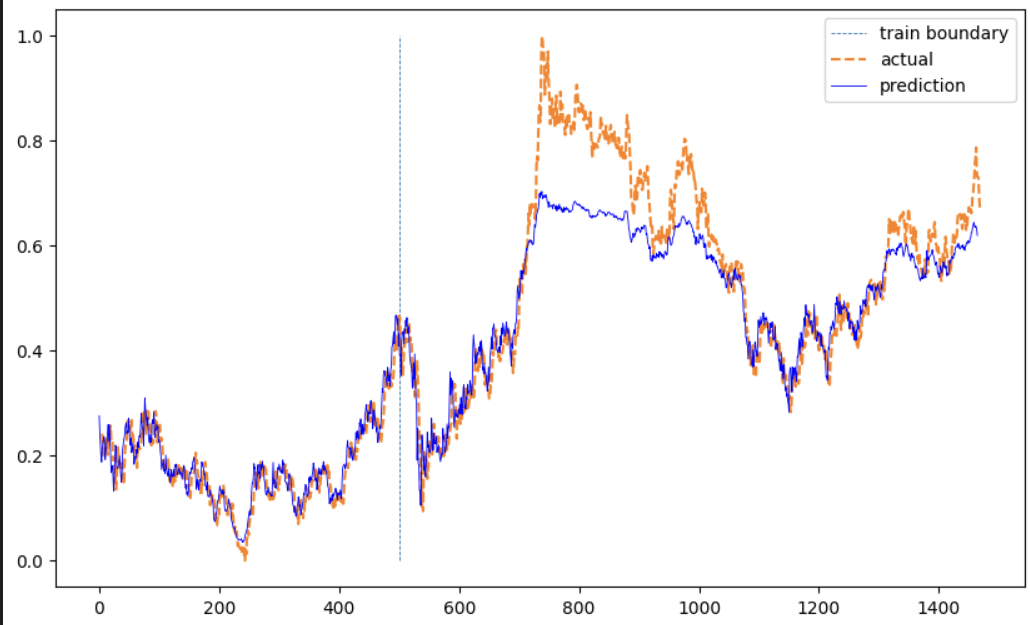
plt.plot(np.ones(100)*len(train_pred), np.linspace(0,1,100), '--', linewidth=0.6)
#train 과 test 비교위해 500기준으로 선으로 나눠줘서 구분한 것
plt.plot(actual, '--')
plt.plot(total, 'b', linewidth =0.6)
plt.legend(['train boundary', 'actual', 'prediction'])
plt.show()
plotting(train_loader, test_loader, samsung['Close'][sequence_length:])matplotlib로 실제와 prediction을 비교하는 그래프를 그려보았고 결과는 다음과 같다.
결론
이때까지는 딥러닝으로 패턴 분석하는 것 자체가 신기하기만 했다. 그러나 과연 이게 "prediction"이라는 이름이 알맞는가? ㅎㅎ 일단 RNN보다는 뛰어나다고 알려져 있는 LSTM을 다음에 써보겠다.
본 내용은 누군가에게 정보를 제공하고자 작성한 글이 아니다(실력이 안됨) 본인이 공부하면서 깨달은? 내용들의 기록 용도임을 밝힌다.
무한한 피드백과 태클을 걸어도 된다. 양분으로 감사하게 받아 먹겠다.
