
🙆♀️ AWS S3란?
Simple Storage Service : 인터넷용 스토리지 서비스
-
Amazon S3는 언제든지 어디서나 원하는 양의 데이터를 저장하고 검색하는 데 사용할 수 있는 간편한 웹 서비스 인터페이스를 제공한다. 이 서비스를 사용하면 클라우드 네이티브 스토리지를 사용하는 애플리케이션을 손쉽게 구축할 수 있다.
-
Amazon S3는 확장성이 뛰어나고 사용한 만큼만 비용을 지불하므로 작은 규모에서 시작해 성능 또는 안정성 저하 없이 원하는 대로 애플리케이션을 확장할 수 있다.
-
파일에 인증을 붙여서 무단으로 엑세스 하지 못하도록 할 수 있다.
-
최소 1바이트에서 최대 5TB의 데이터를 저장하고 서비스 할 수 있다.
-
많은 사용자가 접속을 해도 이를 감당하기 위해서 시스템적인 작업을 하지 않아도 된다.
=> Amazon S3를 사용하는 개발자는 데이터 저장 방법을 고민하기보다는 혁신에 집중할 수 있다.
🔸 AWS S3 스토리지 클래스
(1) Amazon S3 Standard - 무제한 저장 가능한 스토리지
자주 액세스하는 데이터를 위한 스토리지 클래스로 내구성, 99.9% 가용성 및 성능이 뛰어난 객체 스토리지 서비스를 제공한다.
(2) Amazon S3 Standard - IA(Infrequent Access)
액세스 빈도가 낮지만 필요할 때 빠르게 액세스 해야하는 데이터를 위한 스토리지 클래스이다. S3 Standard와 같은 내구성 및 성능과 99.9% 가용성을 지원하면서 가격은 기존 S3 대비 58% 저렴하여 최근 백업 서비스에 많이 사용된다.
(3) Amazon S3 One Zone - IA(Infrequent Access)
액세스 빈도가 낮지만 필요할 때 빠르게 액세스 해야하는 데이터를 위한 스토리지 클래스이다. 최소 3개의 가용 영역(AZ)에 데이터를 저장하는 다른 S3 스토리지 클래스와 달리, 단일 AZ에 데이터를 저장함으로써 S3 Standard-IA 대비 20% 저렴한 비용을 제공한다.
(4) Amazon Glacier - 데이터 백업용 스토리지
데이터 보관을 위한 안전하고 안정적, 비용이 매우 저렴한 스토리지 서비스로 S3와 같은 내구성과 성능 및 가용성을 보유하고 있으며, S3 표준 대비 최고 77%까지 저렴하다. 데이터 아카이빙 및 장기간 데이터 보관 및 오래된 로그 데이터에 대한 저장 용도로 적당한 서비스이다. 또한 S3의 수명주기 기능을 통한 객체 자동 마이그레이션을 제공한다.
=> 데이터 보관에 대해 프리티어를 제공하지 않음 (월별 10GB의 Amazon Glacier 데이터 검색 무료 제공)
🔸 AWS S3 관련 용어
객체(Object)
Amazon S3에 저장되는 기본 개체이다.
객체는 객체 데이터와 메타데이터로 구성된다.
메타데이터는 객체를 설명하는 이름-값 페어의 집합이다. 여기에는 마지막으로 수정한 날짜와 같은 몇 가지 기본 메타데이터 및 Content-Type 같은 표준 HTTP 메타데이터가 포함된다. 객체를 저장할 때 사용자 지정 메타데이터를 지정할 수도 있다.
객체는 키(이름) 및 버전 ID를 통해 버킷 내에서 고유하게 식별된다. (버킷에서 S3 버전 관리가 활성화된 경우)

버킷(Bucket)
S3에서 생성할 수 있는 최상위 디렉토리의 개념이다.
Amazon S3에 저장된 객체에 대한 컨테이너이다.
버킷에 저장할 수 있는 객체 수에는 제한이 없다. (용량 무제한)
계정 별로 100개까지 생성 가능하다.
버킷 단위로 지역(region)을 지정할 수 있고, 버킷에 포함된 모든 객체에 대해서 일괄적으로 인증과 접속 제한을 걸 수 있다.
- Amazon S3 리소스에 대한 액세스를 관리하는 데 사용할 수 있는 버킷 정책, 액세스 제어 목록(ACL), S3 액세스 포인트와 같은 제어 옵션을 제공합니다.
- 사용량 보고를 위한 집계 단위로 사용됩니다.
키 (Key)
객체 키(또는 키 이름)는 버킷 내 객체에 대한 고유한 식별자이다.
버킷 내 모든 객체는 정확히 하나의 키를 갖는다.
버킷, 객체 키 및 선택적으로 버전 ID(버킷에 대해 S3 버전 관리가 활성화된 경우)의 조합은 각 객체를 고유하게 식별한다.
S3 버전 관리
S3 버전 관리를 사용하면 동일 버킷 내에 여러 개의 객체 변형을 보유할 수 있다.
S3 버전 관리를 사용하여 버킷에 저장된 모든 버전의 모든 객체를 보존, 검색 및 복원할 수 있다. 또한 의도치 않은 사용자 작업 및 애플리케이션 장애로부터 쉽게 복구할 수 있다.
버전 ID
버킷에 S3 버전 관리를 활성화하면 Amazon S3에서 버킷에 추가되는 각 객체에 고유한 버전 ID를 생성한다.
이러한(또는 다른) 객체를 CopyObject 및 PutObject와 같은 기타 작업으로 수정하는 경우 새 객체가 고유한 버전 ID를 가진다.
Regions (지역)
AWS 리전은 AWS가 짧은 지연 시간, 높은 처리량 및 중복성이 높은 네트워킹으로 연결되었으며 물리적으로 분리 및 격리된 다수의 가용 영역(AZ) 을 제공하는 지리적 위치이다.
Amazon S3에서 사용자가 만드는 버킷을 저장할 지리적 AWS 리전 을 선택할 수 있다.
AWS 리전 에 저장된 객체는 사용자가 명시적으로 객체를 다른 리전으로 전송하거나 복제하지 않는 한 해당 리전을 벗어나지 않는다. 예를 들어, 유럽(아일랜드) 리전에 저장된 객체는 유럽 밖으로 이동하지 않는다.
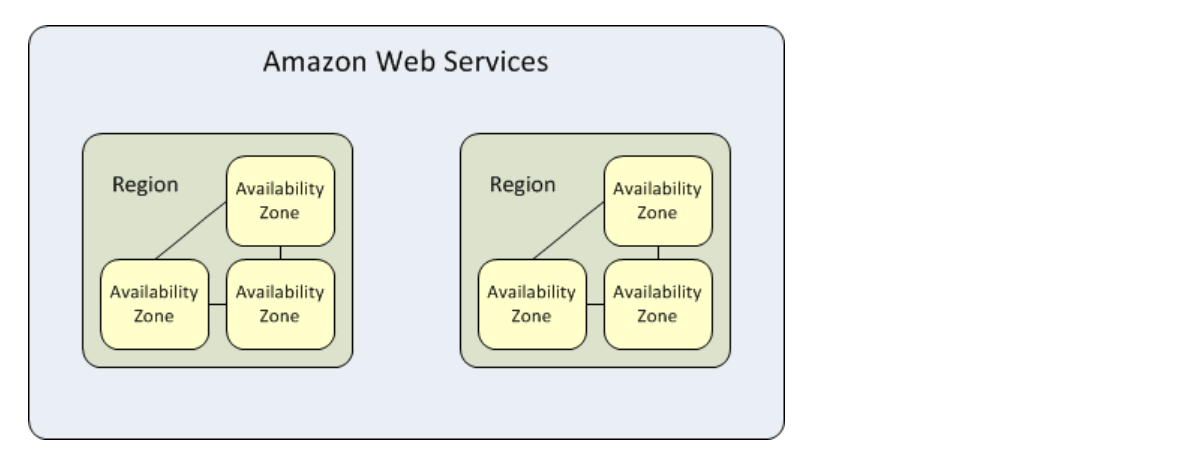
가용영역 (AZ)
AWS 가용 영역은 AWS 리전 내에 물리적으로 격리된 위치를 말한다.
S3는 각 AWS 리전 내에 최소 3개의 AZ를 운영하며, 각 AZ는 화재, 홍수 등과 같은 지역 이벤트로부터 보호할 수 있도록 지리적으로 분리된다.
Amazon S3 Standard, S3 Standard-Infrequent Access 및 S3 Glacier 스토리지 클래스는 하나의 AZ가 모두 손실되어도 데이터를 보호할 수 있도록 최소 3개의 AZ에 걸쳐 데이터를 복제한다. 이는 공개적으로 사용할 수 있는 AZ가 3개 미만인 리전에도 동일하게 적용된다. 이러한 스토리지 클래스에 저장된 객체는 해당 AWS 리전 내 모든 AZ에서 액세스할 수 있다.
RSS
Reduced Redundancy Storage의 약자로 일반 S3 객체에 비해서 데이터가 손실될 확률이 높은 형태의 저장 방식이다.
대신 가력이 저렴하기 때문에 복원이 가능한 데이터, 예를 들어 썸네일 이미지와 같은 것을 저장하는데 적합하다.
🔸 AWS S3 작동방식
정리하면!
Amazon S3는 데이터를 버킷 내의 객체로 저장하는 객체 스토리지 서비스이다.
버킷은 객체에 대한 컨테이너인 것이다.
Amazon S3에 데이터를 저장하려면 먼저 버킷을 생성하고 버킷 이름 및 AWS 리전을 지정해야 한다. 그런 다음 Amazon S3에서 객체로 해당 버킷에 데이터를 업로드한다. 각 객체에는 키(또는 키 이름)가 있으며, 이는 버킷 내 객체에 대한 고유한 식별자이다.
S3 버전 관리를 사용하여 동일한 버킷에 여러 버전의 객체를 보관하고, 실수로 삭제되거나 덮어쓰기된 객체를 복원할 수 있다.
버킷과 버킷의 객체는 프라이빗이며 액세스 권한을 명시적으로 부여한 경우에만 액세스할 수 있다. 버킷 정책, AWS Identity and Access Management(IAM) 정책, 액세스 제어 목록(ACL), S3 액세스 포인트를 사용하여 액세스를 관리할 수 있다.
🔸 AWS S3 실습
(1) 버킷 생성하기
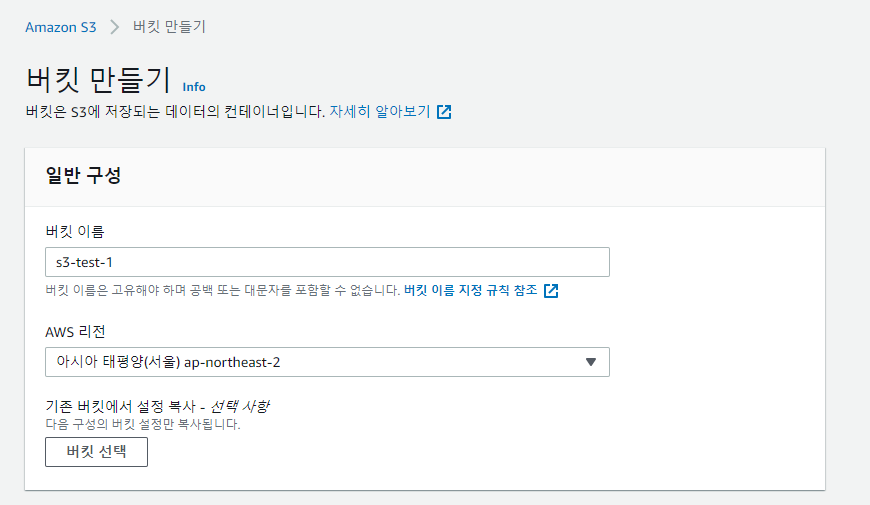
-
버킷 이름은 다른 서버와 겹치지 않는 고유한 이름이 되어야 한다. 버킷 이름은 Global Unique로, 전세계에 어디에도 중복된 이름이 존재할 수 없다.
-
리전(Region)은 일반적으로 S3을 사용하는 사용자와 가까운 위치가 되도록 설정한다.
(2) 파일 업로드
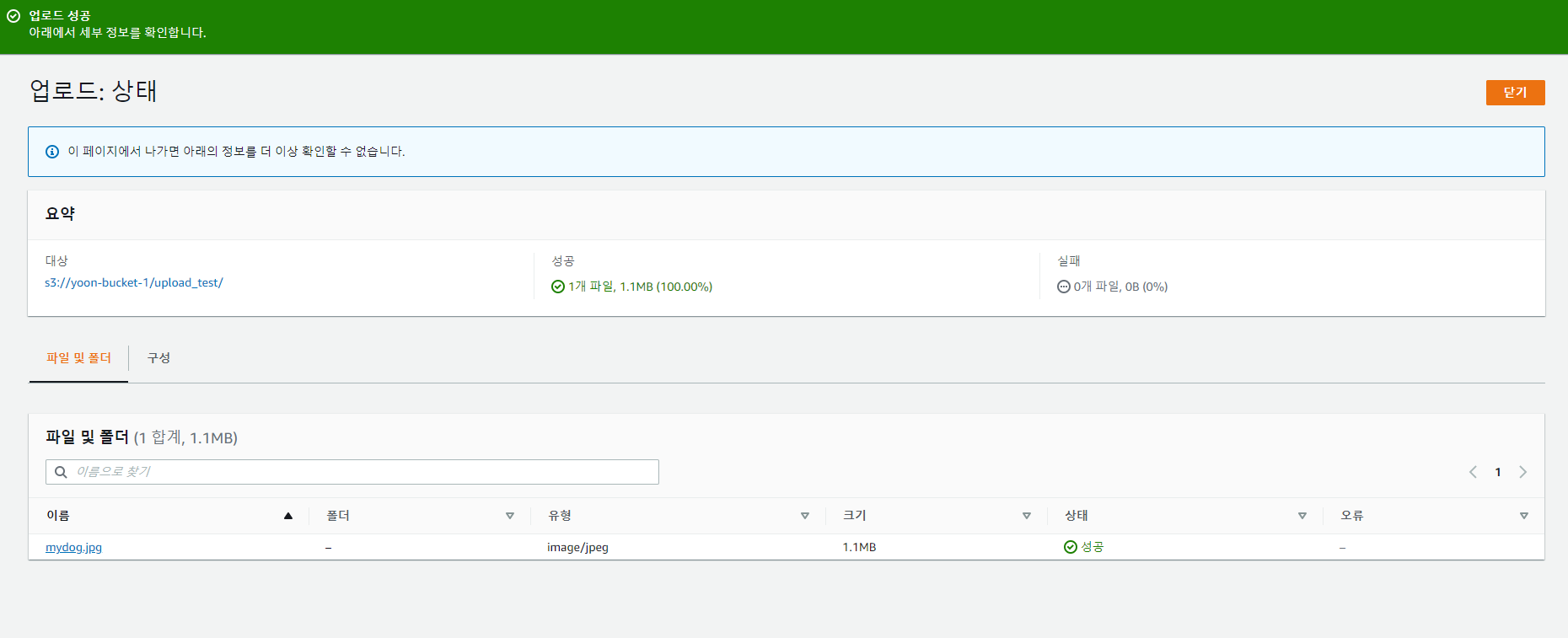
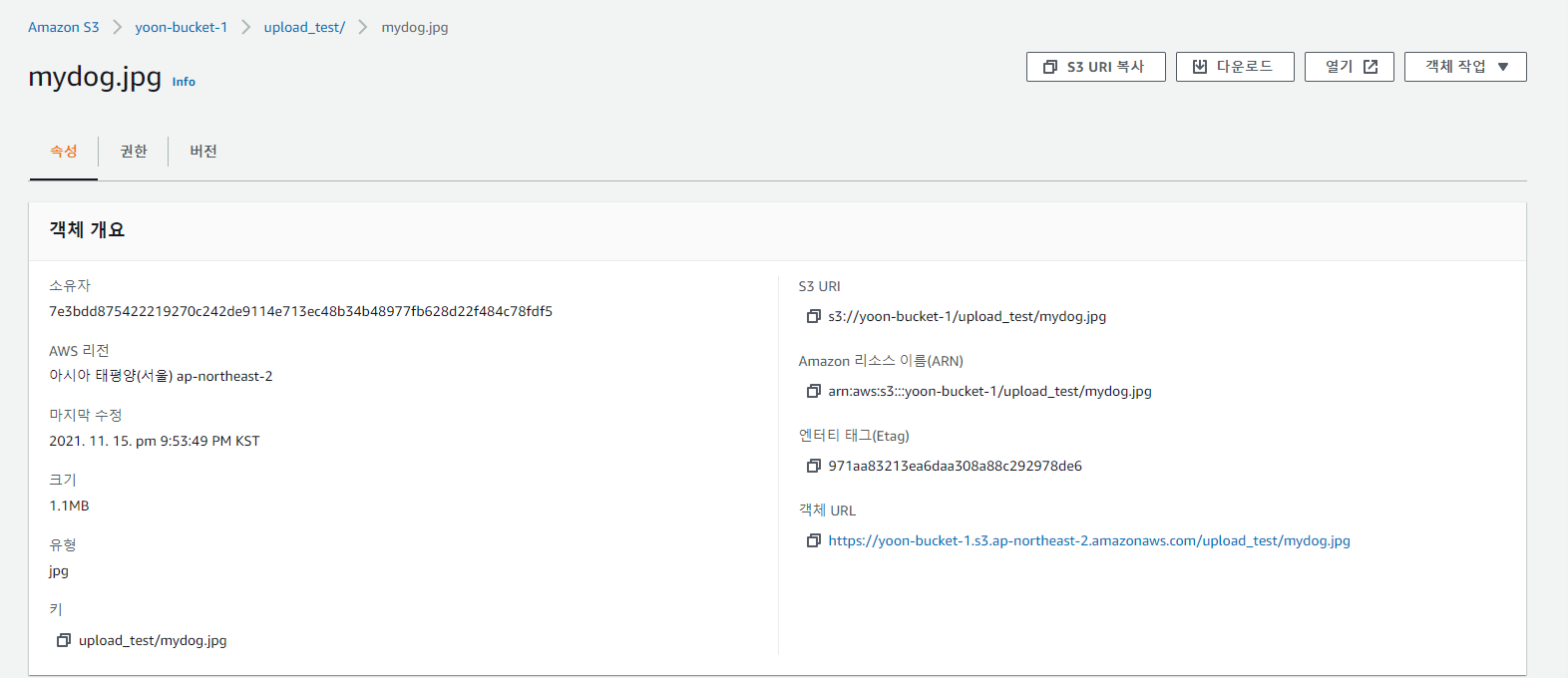
생성된 객체 URL에 접근하면 된다.
파일의 웹 URL은 기본적으로 두 가지 형태를 가진다.
https://bucket-name.s3.Region.amazonaws.com/keynamehttps://s3.Region.amazonaws.com/bucket-name/keyname
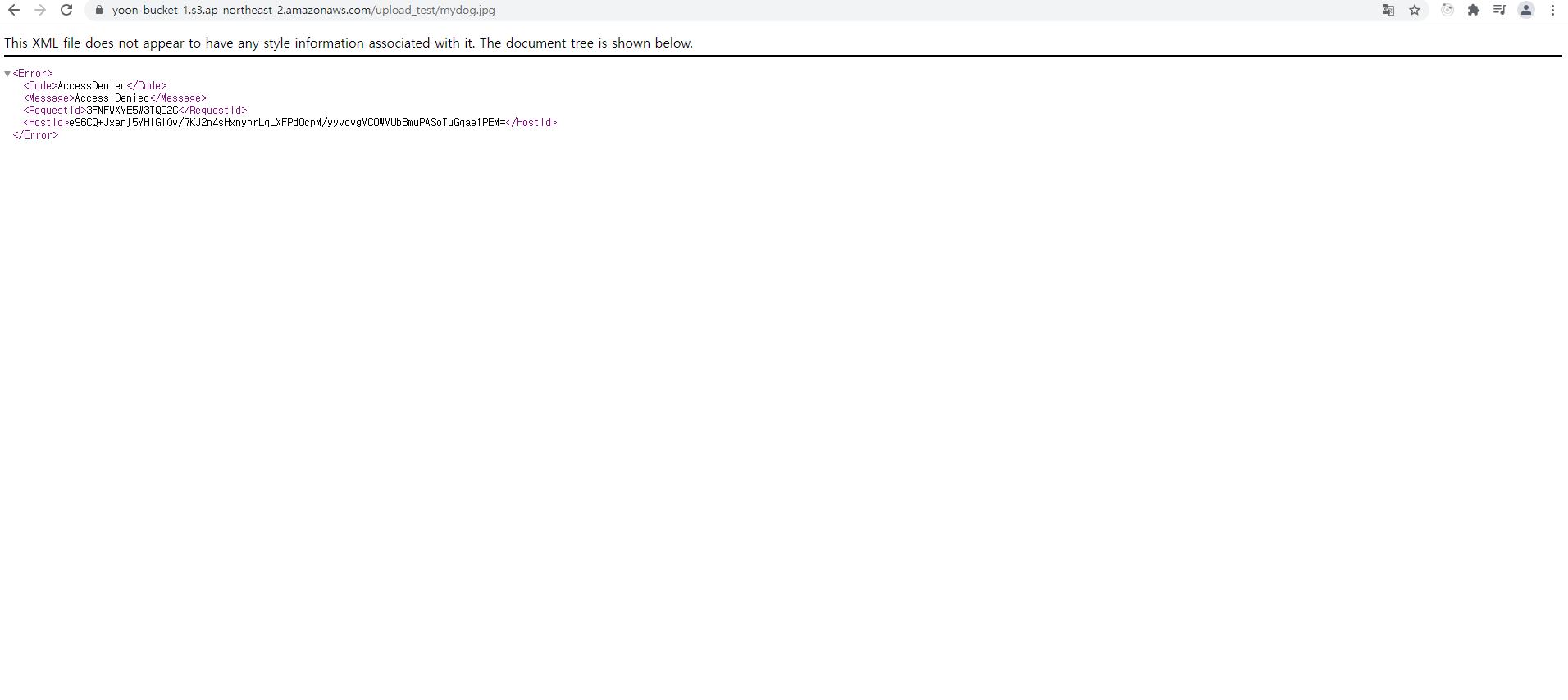
=> 처음에는 이렇게 접근권한이 없으므로 에러가 표시된다.
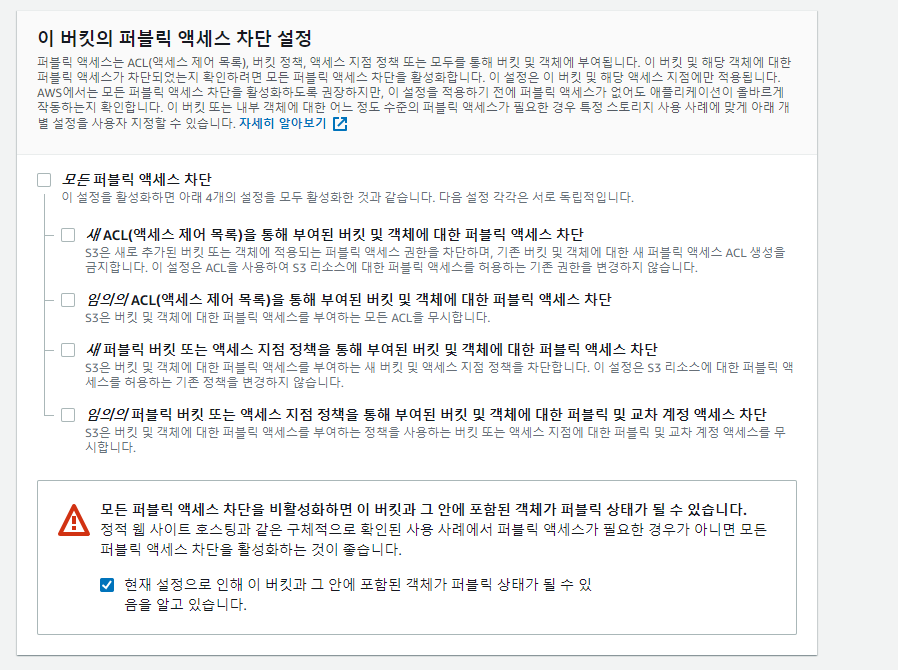
(3) 접근 권한 변경하기
다른 사람들이 어디서든 도메인을 통해서 들어오게 하려면 "퍼블릭 설정" 으로 변경하면 된다.
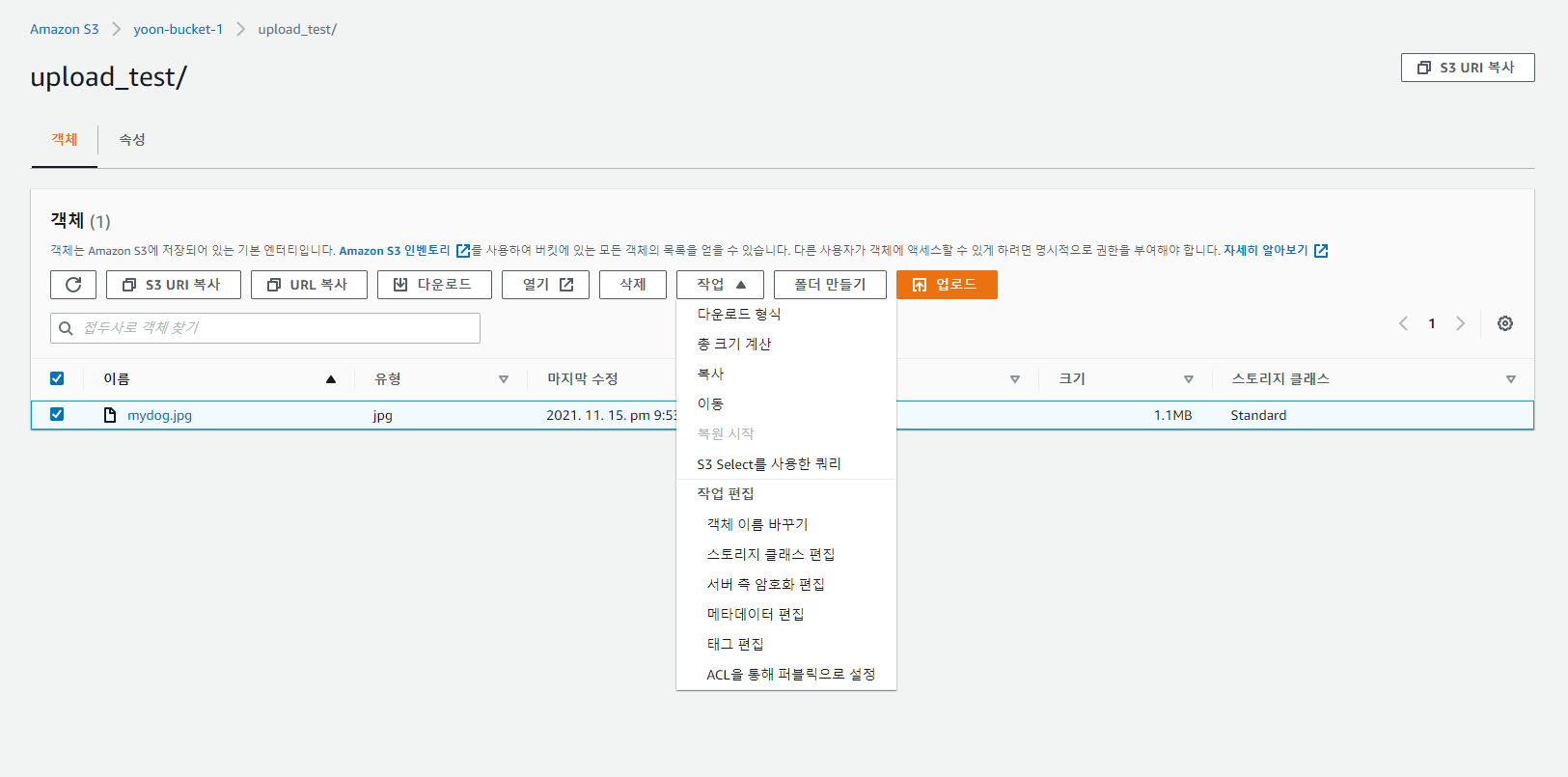
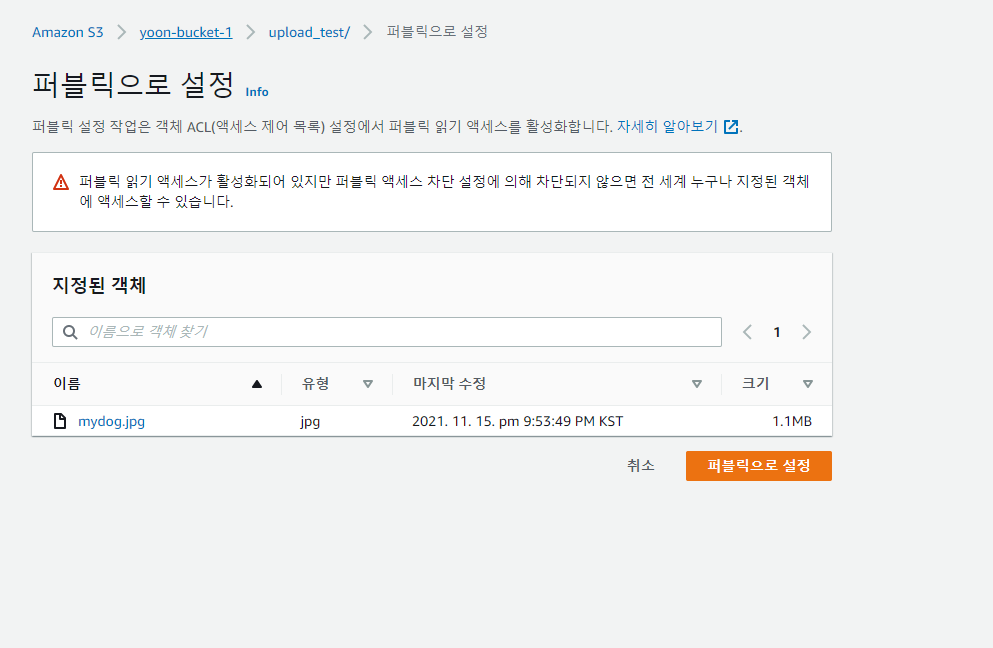

해당 파일이 잘 나오는 것을 확인할 수 있다.
(4) 버킷 정책
다만 이렇게 일일이 파일 하나하나를 퍼블릭으로 설정하는 것은 귀찮은 작업이 될 수도 있다. 특정한 범위의 파일에 대해서 전부 한꺼번에 퍼블릭으로 설정하는 방법도 있다. [버킷 정책 편집]을 클릭하여 버킷 내에 모든 파일들이 퍼블릭(Public)에서 접근이 가능하도록 설정해보자. 여기에 들어가는 내용은 [정책 생성기]를 통해 생성할 수 있다.
-
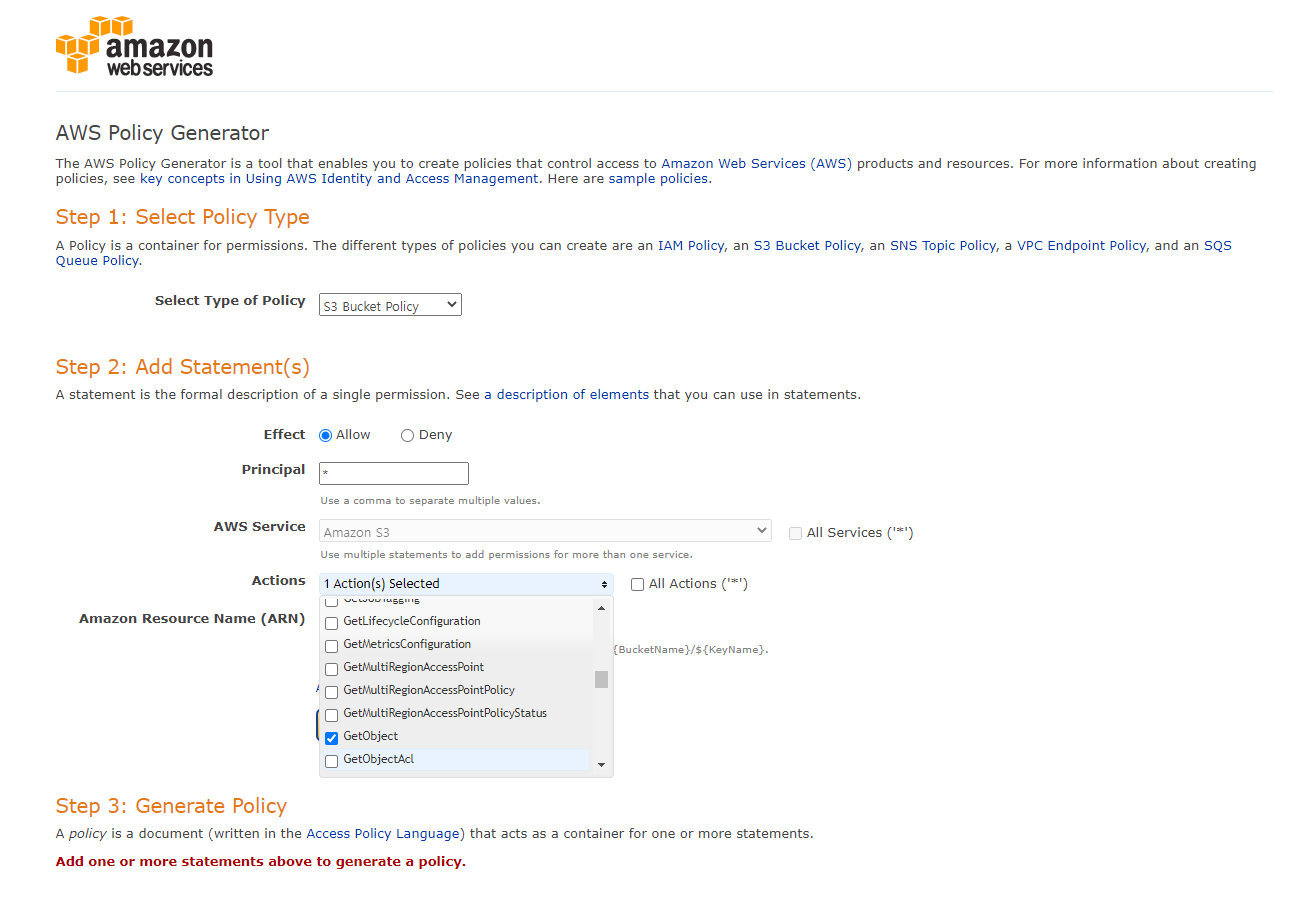
Principal에는 *을 넣는다. AWS Service에는 [Amazon S3]를 넣고, 이후에 Actions에는 [GetObject]를 선택한다.
=> 해당 URL을 알고 있는 모든 주체(Principal)가 객체에 접근할 수 있는 것을 의미한다. 또한 객체(Object) 즉, 파일을 다운로드 할 수 있도록 설정하겠다는 의미이다. -
Resource에는 자신의 AWS S3 고유 경로를 넣은 뒤에 접근할 수 있는 파일의 URL을 설정한다. 파일의 URL로 *라고 넣어주게 되면 해당 버킷 내의 모든 객체에 접근할 수 있도록 하겠다는 의미이다.
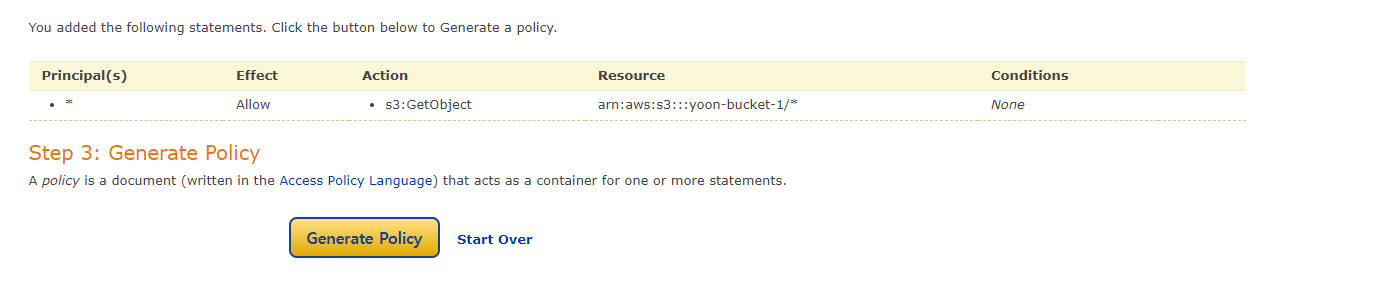
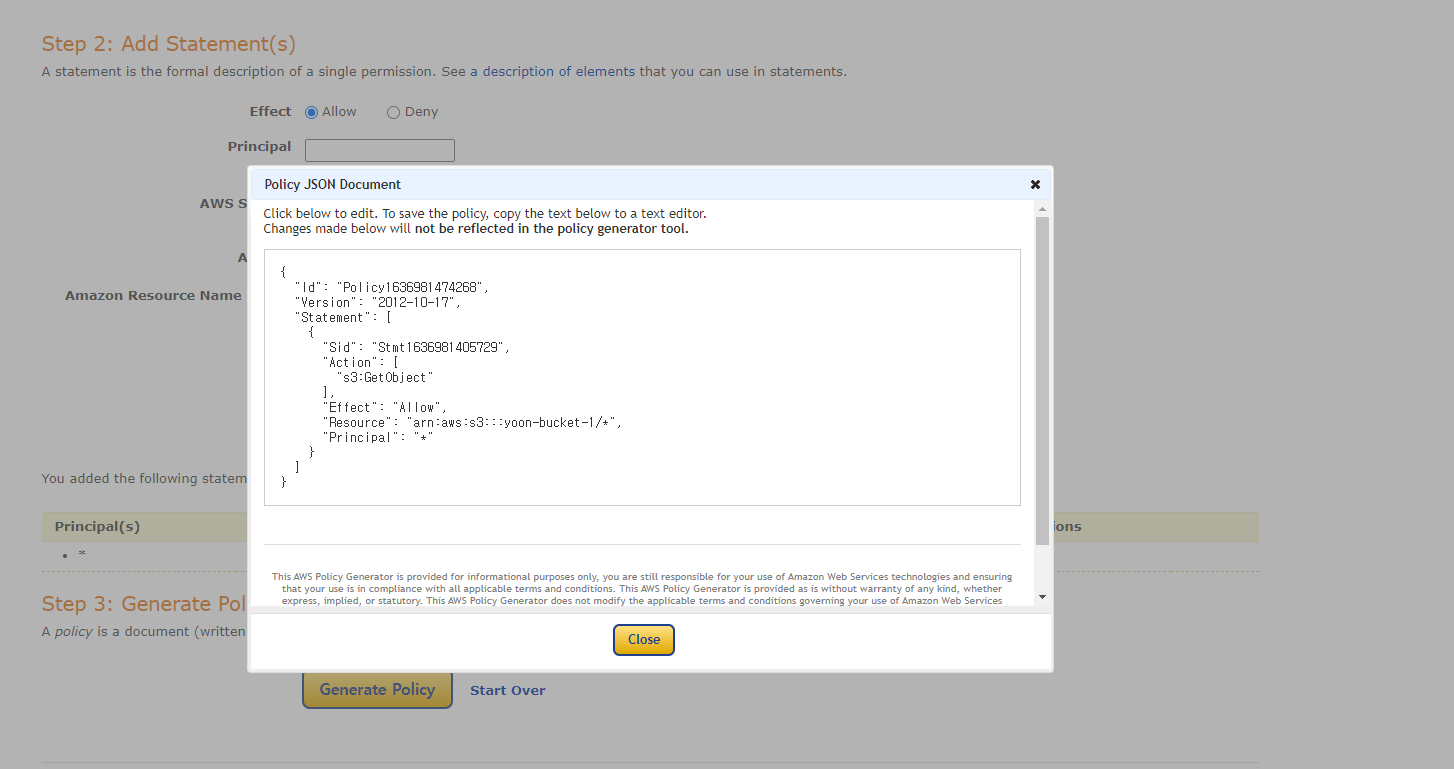
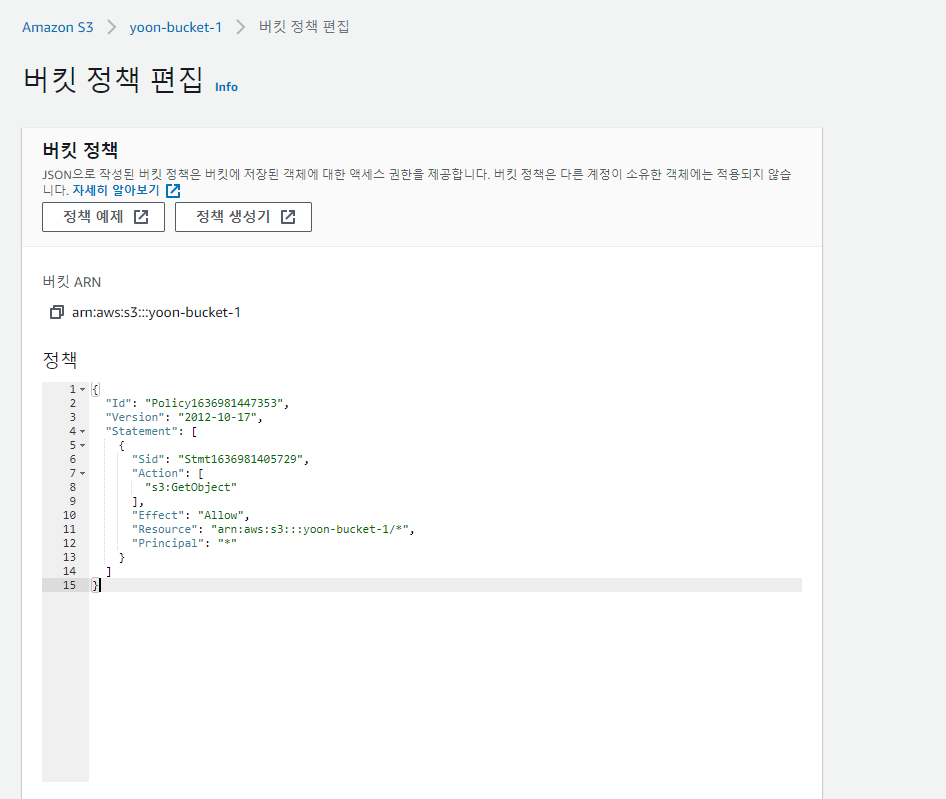
Generate Policy 버튼을 눌러서 생성된 정책 내용을 복사하여 아까 빈 [버킷 정책]란에 붙여넣기한다.
=> 이제 모든 파일에 누구든지 접근하여 다운로드 받을 수 있도록 설정되었다.
(5) IAM 설정하기
IAM : Identity and Access Management로, AWS 리소스들에 대한 접근을 제어할 수 있는 서비스로 권한을 부여 혹은 제한하여 리소스 보관의 안정성을 높일 수 있다.
IAM > 사용자 탭 > 사용자 추가 버튼
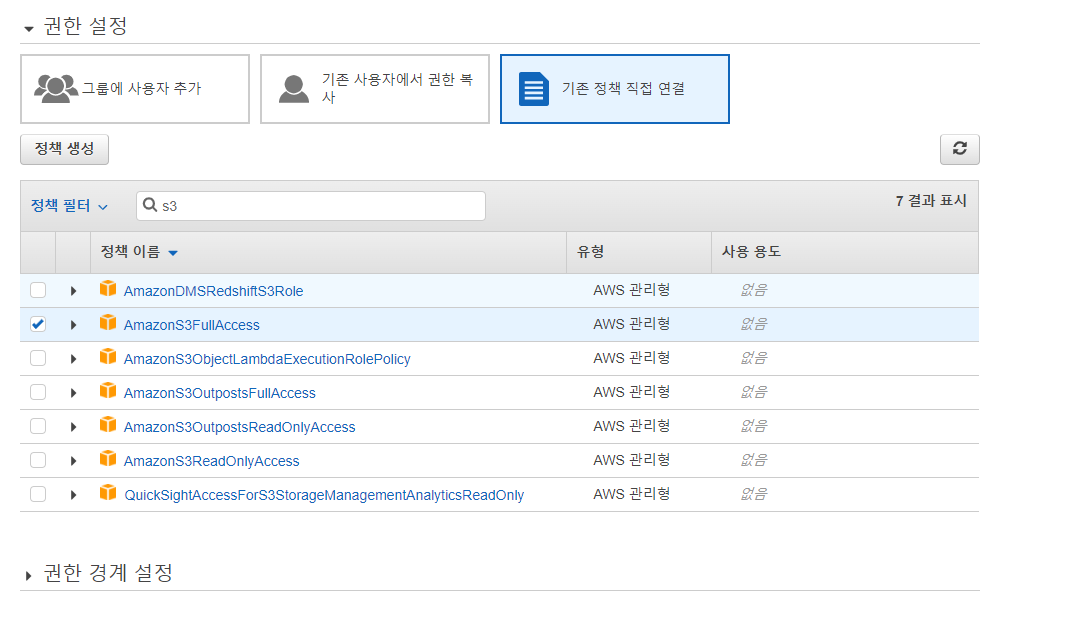
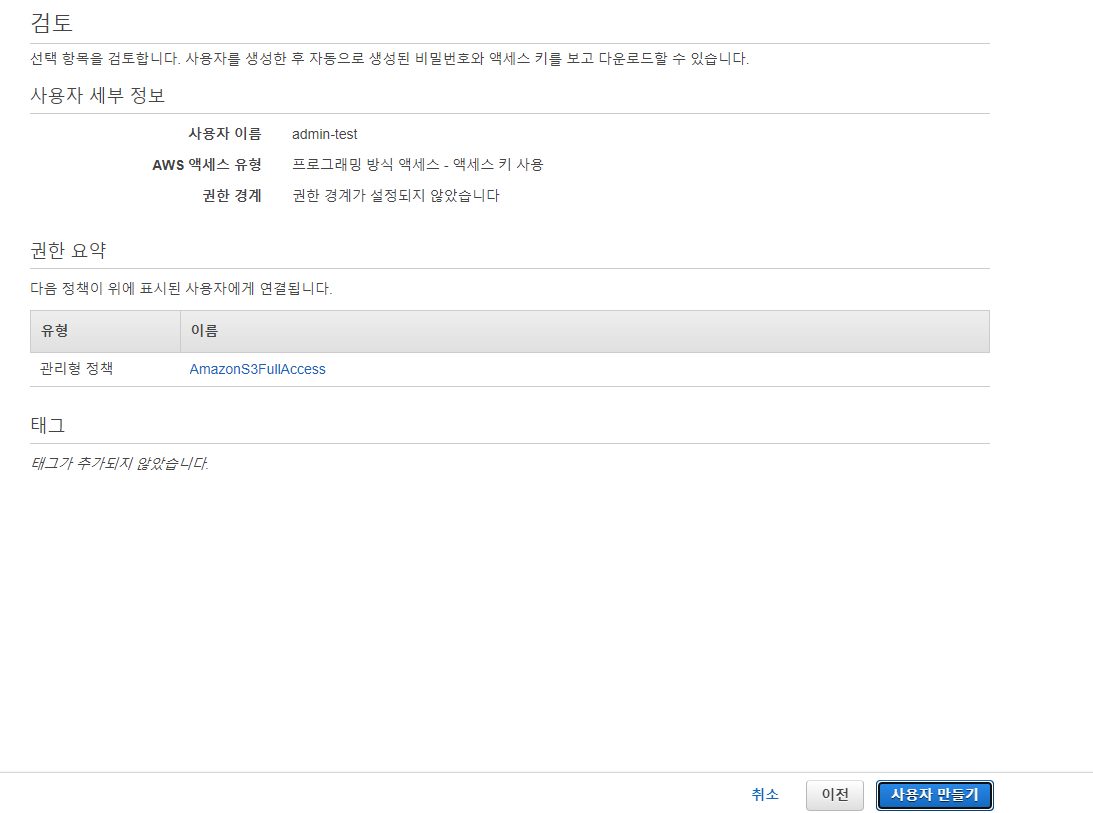
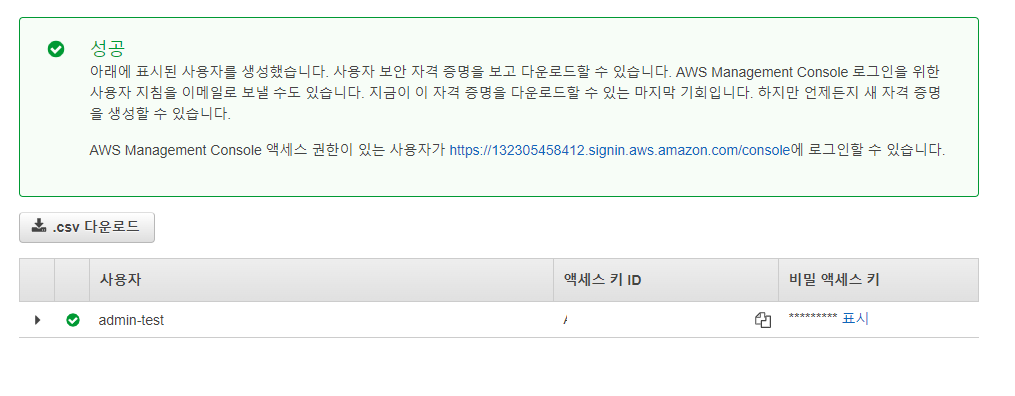
=> 엑세스 키 ID와 비밀 엑세스 키가 생성되었다! 이후 웹 등을 연동할 때 엑세스 키 ID와 비밀 엑세스 키가 사용되니 따로 기록해둬야한다.
[References]
https://ndb796.tistory.com/264
https://datalibrary.tistory.com/185

By the way, I found a good article about this topic, maybe it will be interesting https://ftp-mac.com/uploading-large-files-to-aws-s3/. In my opinion, there is a lot of information there.