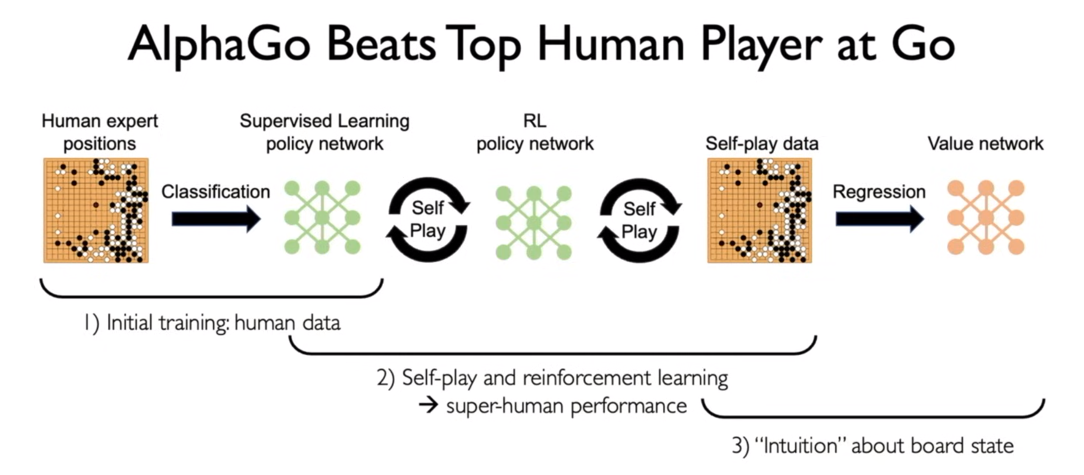
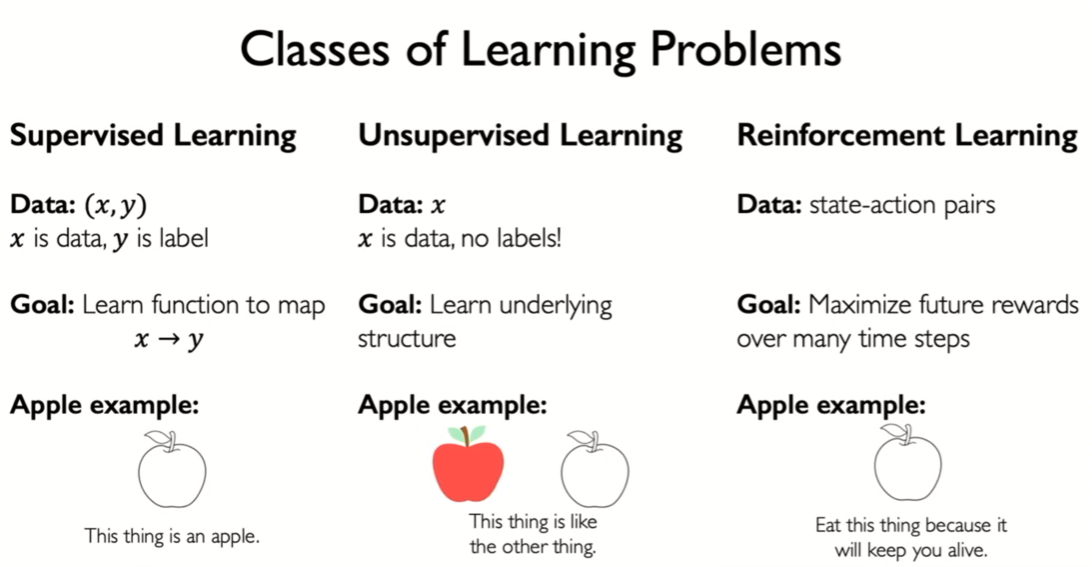
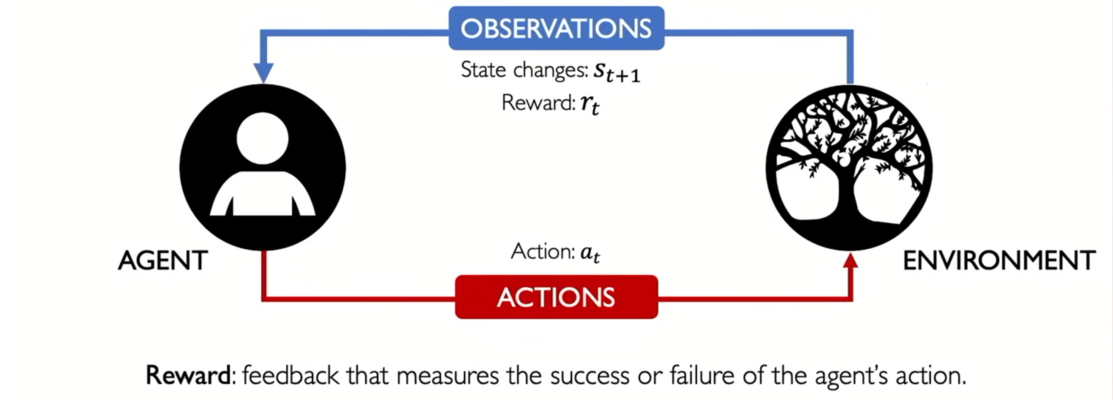
MIT 6.S191: Reinforcement Learning


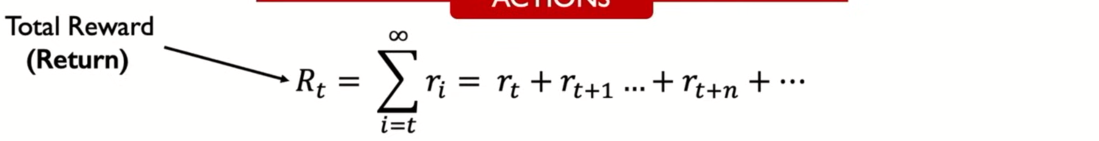
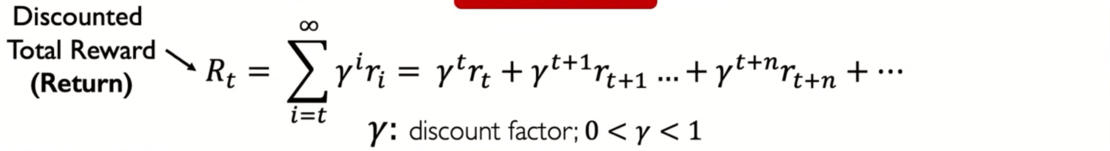




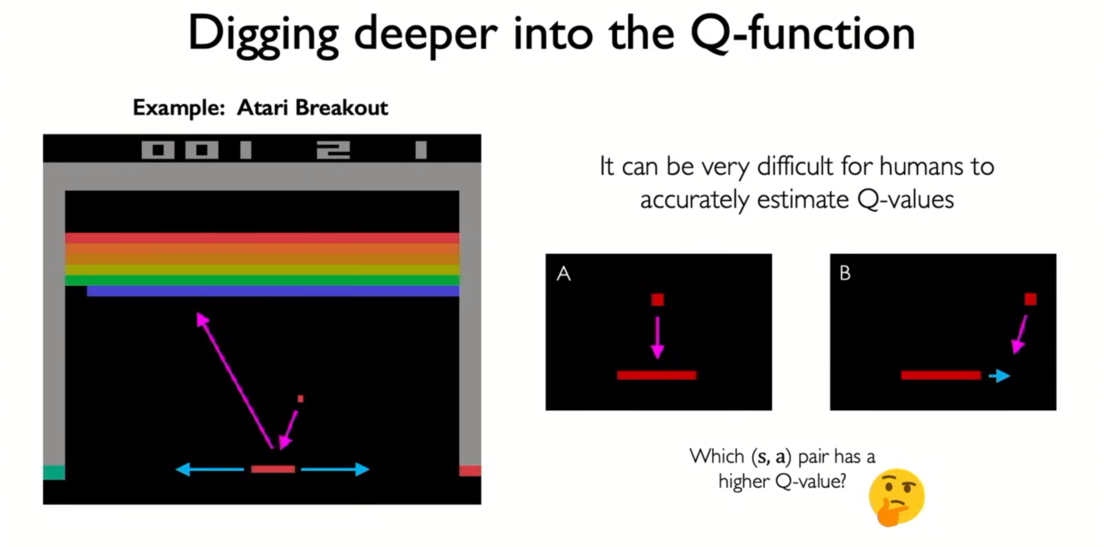
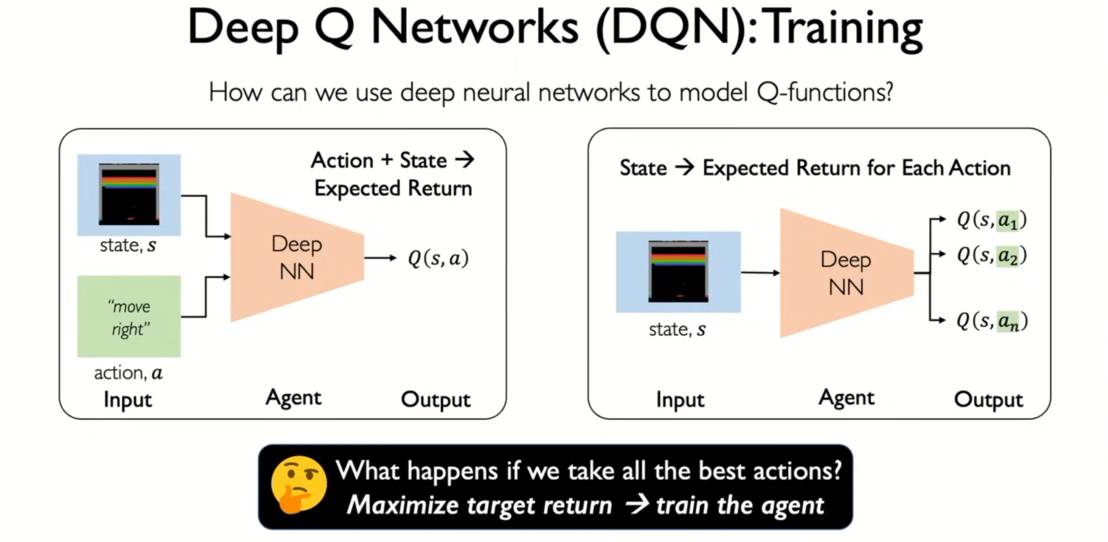
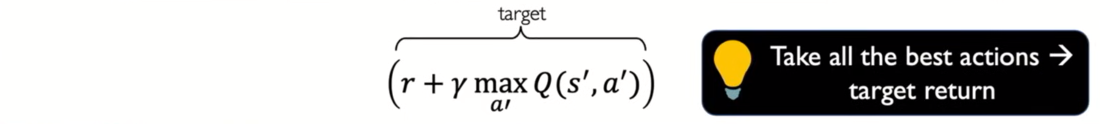
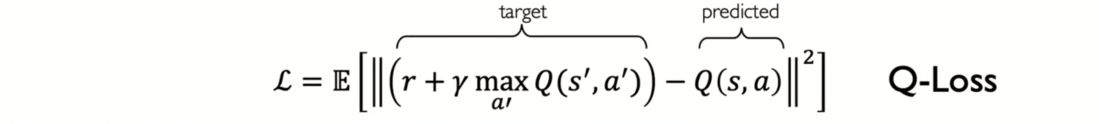
- left : feed s,a pair
- right : only states as input and output Q value each of possible actions
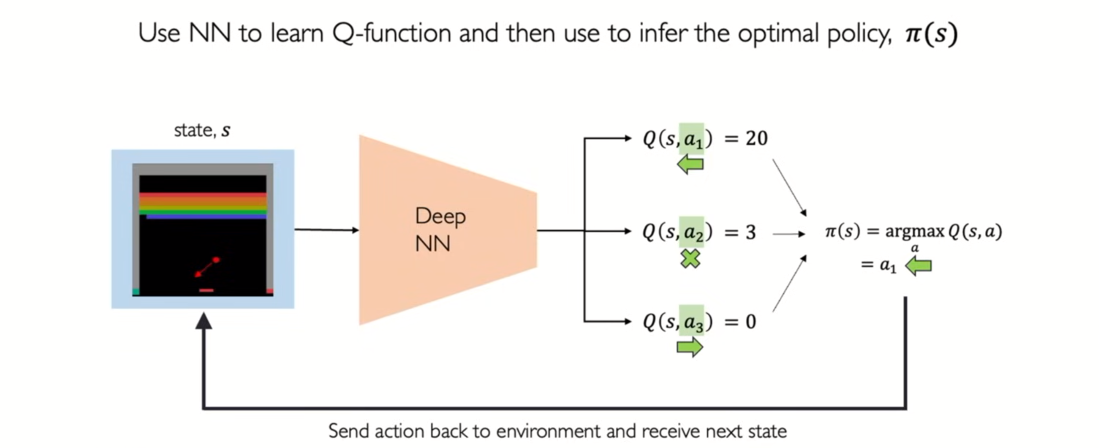
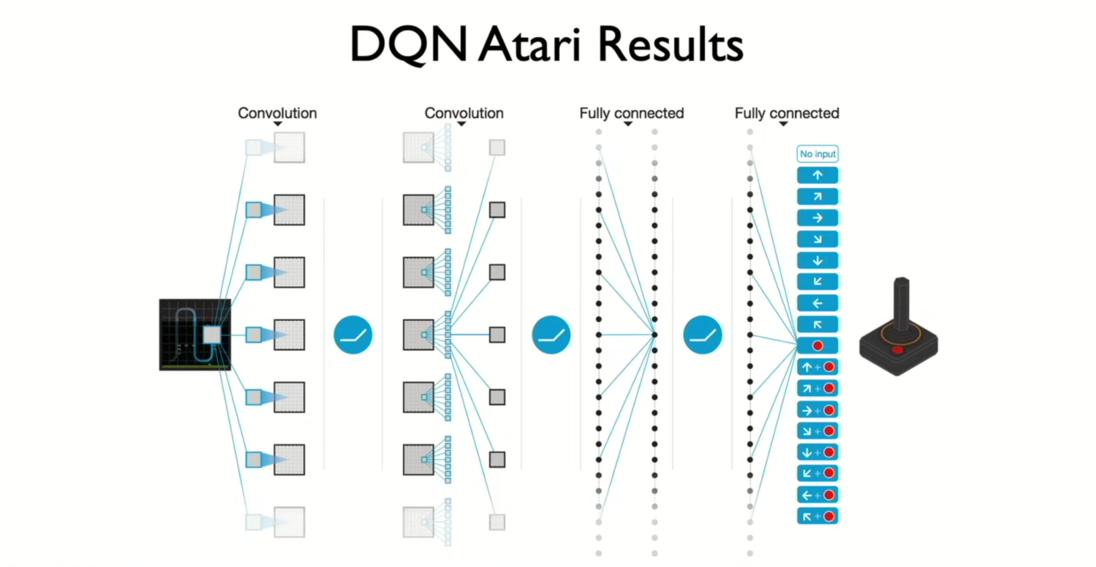
- very many actions
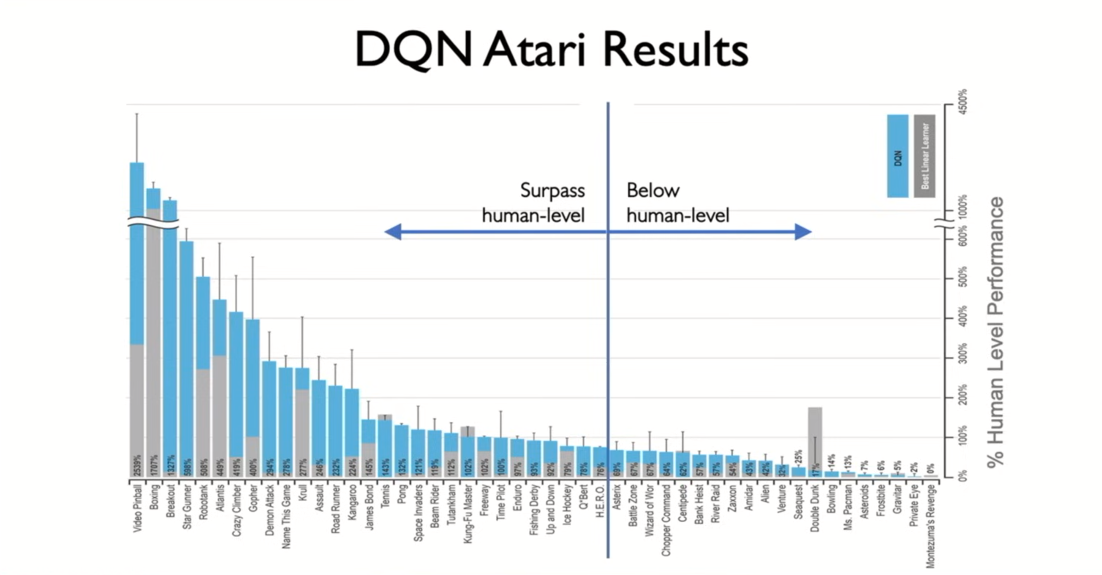
- DQN surpasses human performance for over 50% of atari games


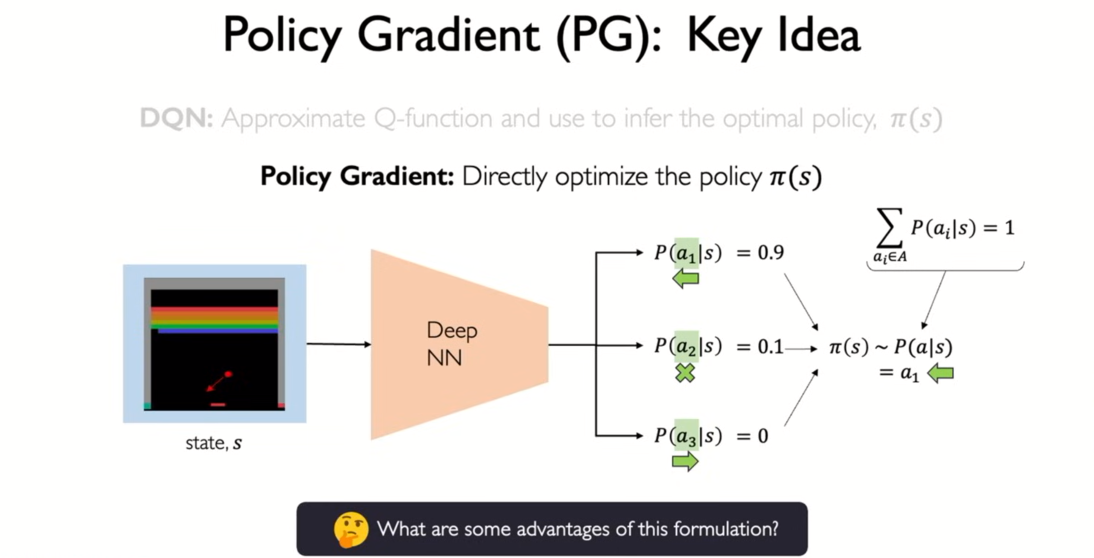
-
instead of outputting Q values, directly optimize policy function
-
the likelihood we take specific action given s
-
not take the maximum, now we're going to do sample from this probability distribution
-
the sampling these actions is now going to be stochastic, not picking what the network think is best action.
going to have some more exploration of the environment. constantly sample
- Q-learning vs policy learning
- Q learning side, you roll out whole game until the end so you have expectation
- policy learning there is no expectation except from the point of view that you have. this now distribution over the different actions that you can take and that gives you an expectation as well

- finite set of possible actions
- action space is discrete
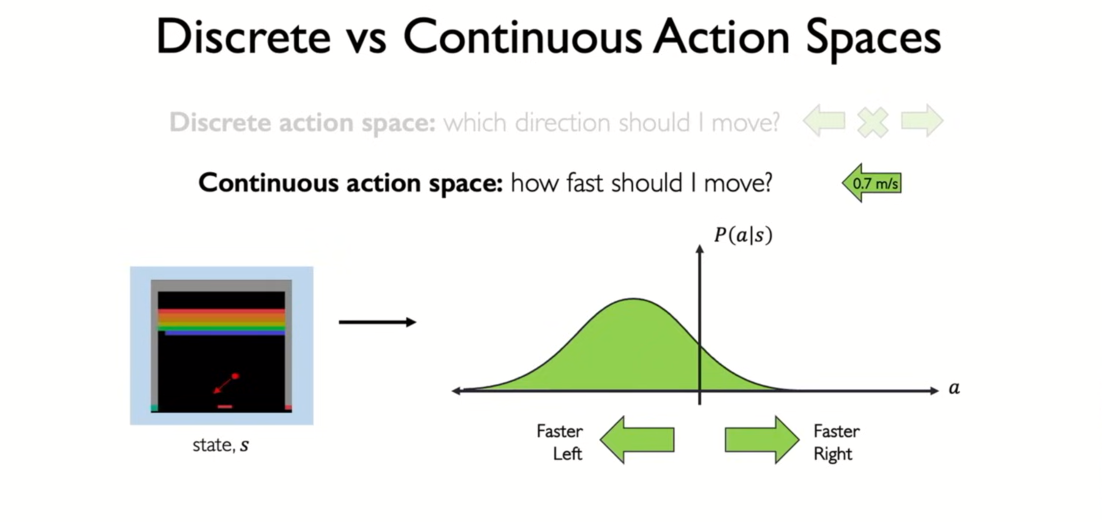
- instead of discrete
continuous
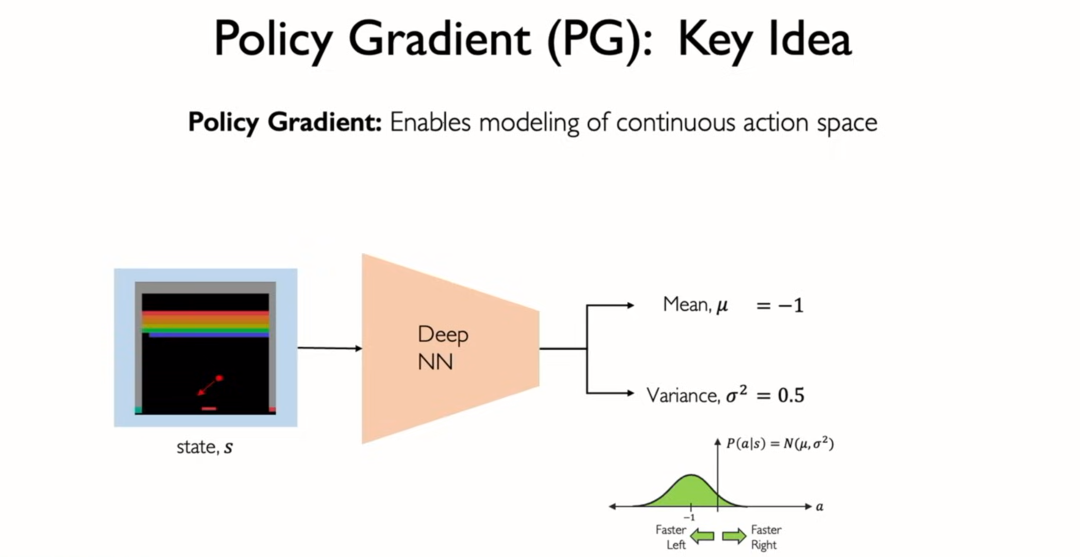
- they learned how latent spaces could be predicted by a neural network
- they learned not every possible gaussian's PDF but parameters
which is and that define those gaussians
- they learned not every possible gaussian's PDF but parameters
- do something similar
- instead of outputting the probability for every possible actions which is infinite in continuous action space
- learn and that define the probability distribution
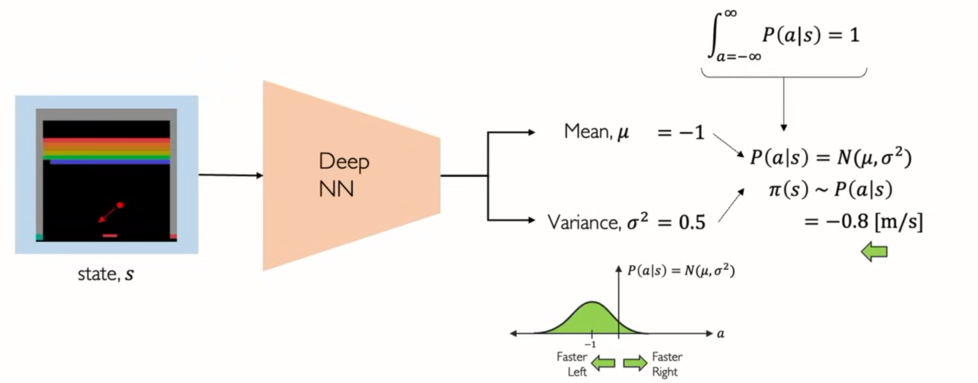
- we can sample from that distribution
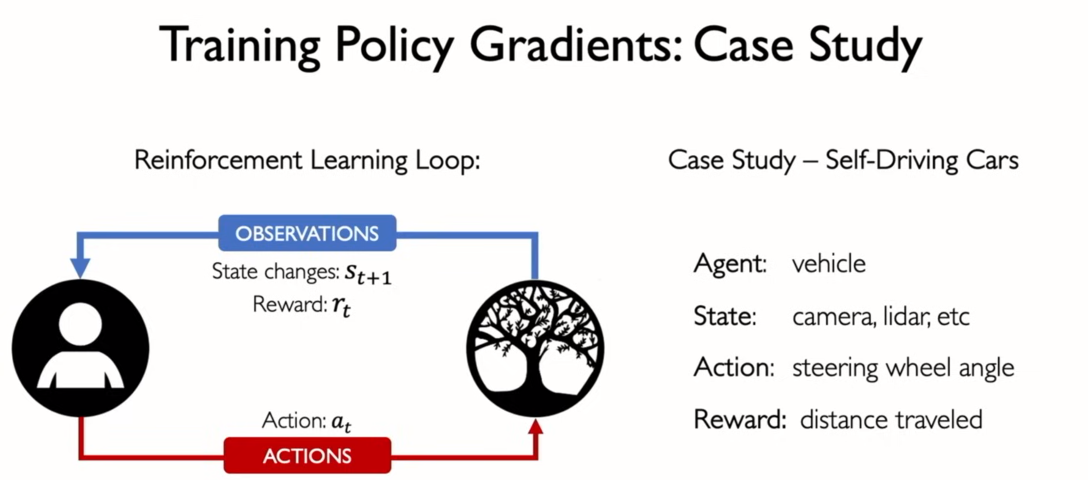

- selecting an action that was chosen for this particular state and multiply it by the total discounted reward