Natural Language Processing - Week 2
Sentiment Analysis with Naïve Bayes
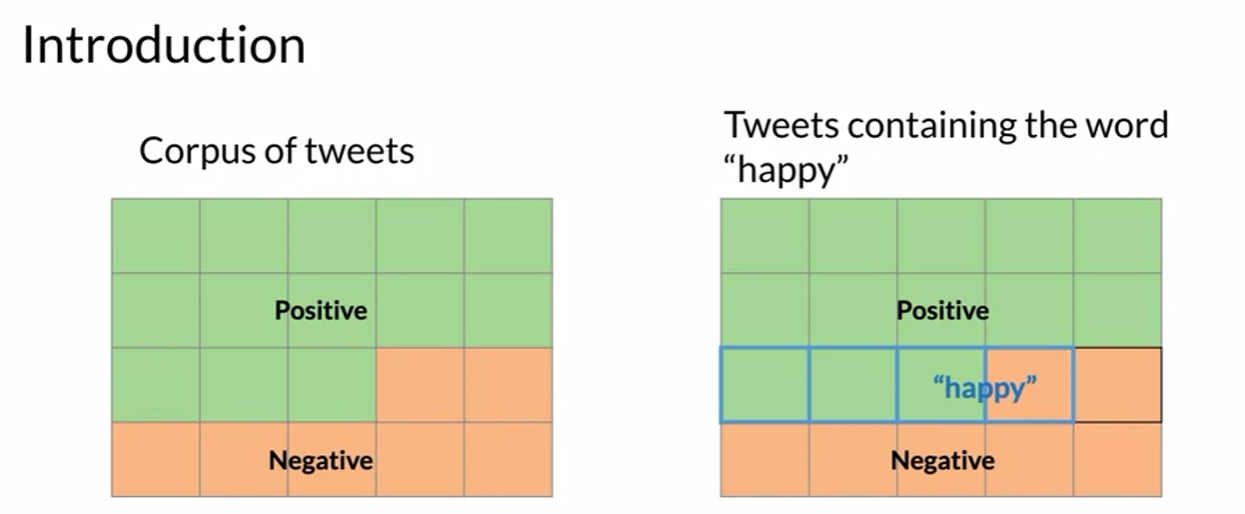
Lecture: Naive Bayes
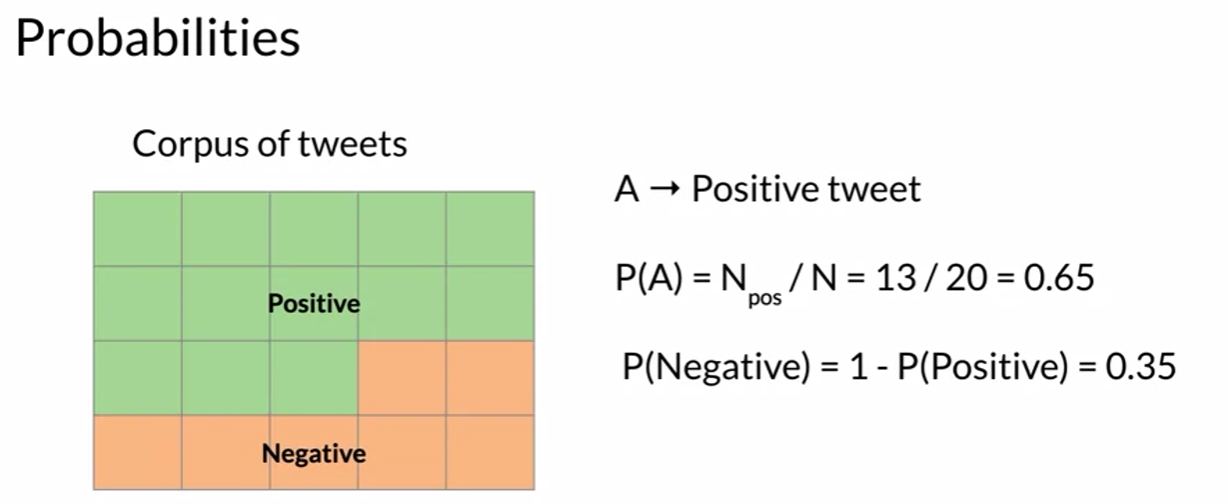
Probability and Bayes’ Rule

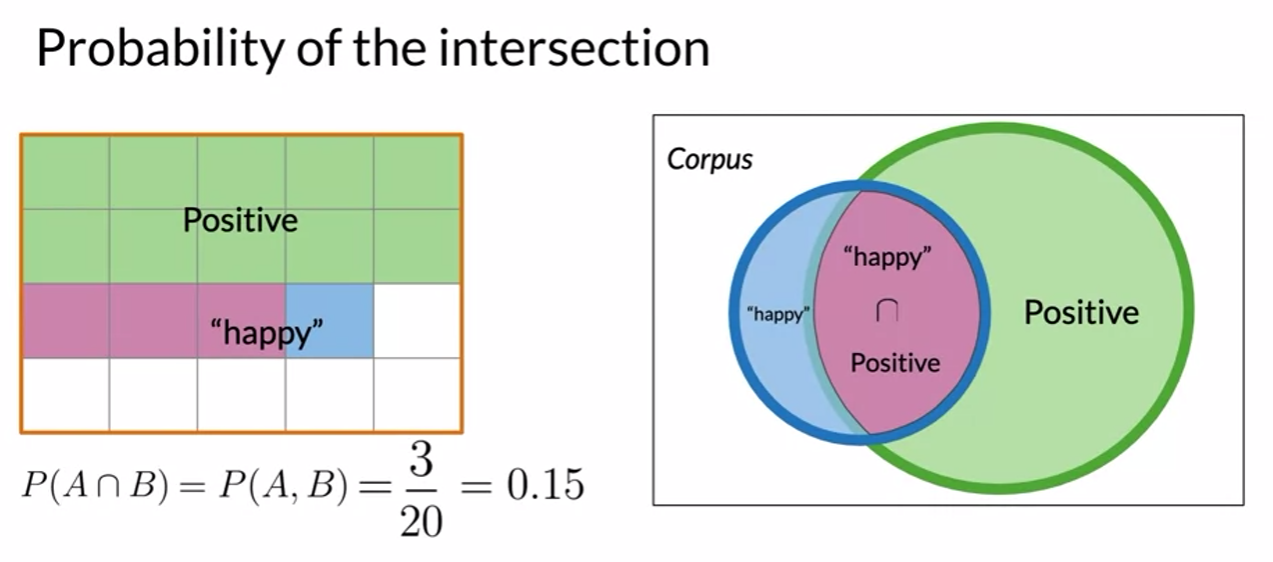
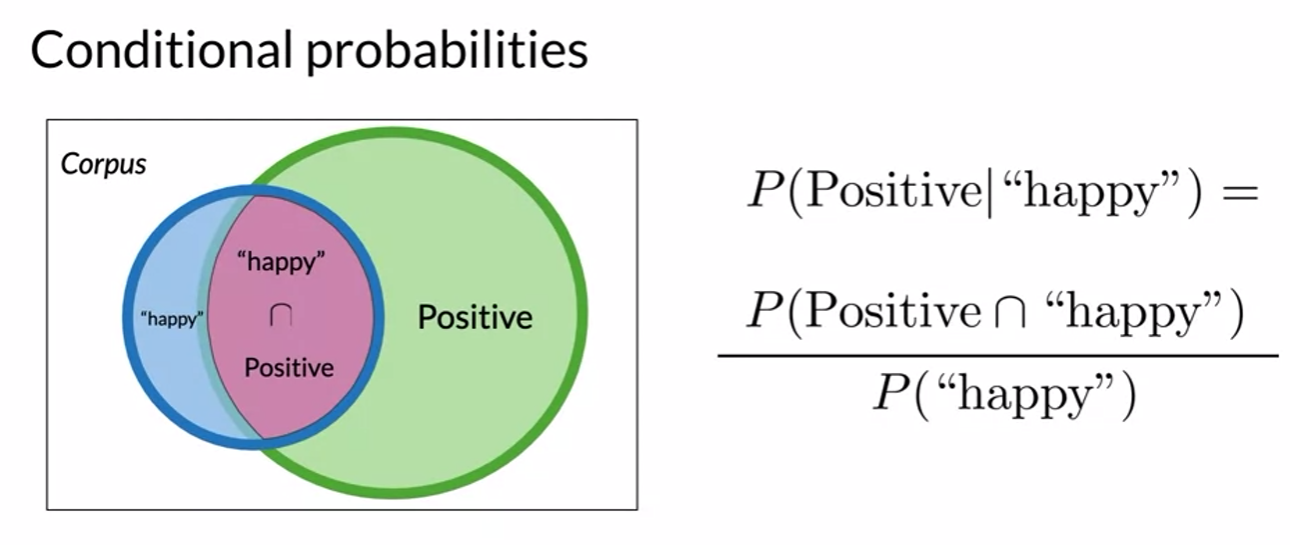
- probability of intersection
Bayes’ Rule
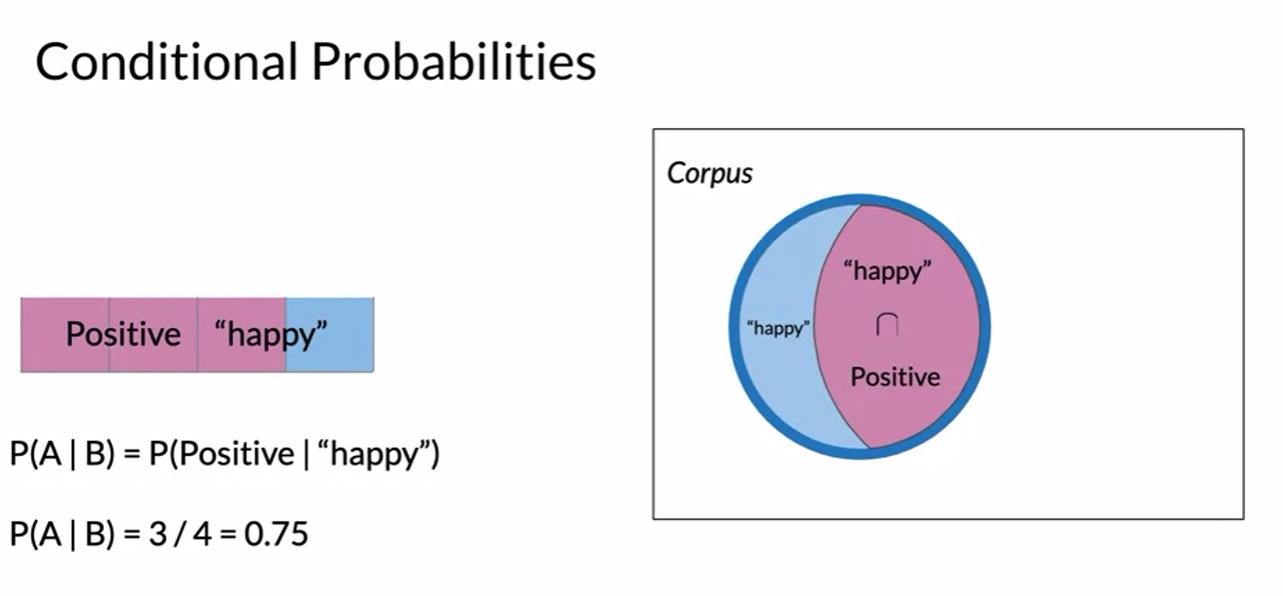
- happy중에 positive
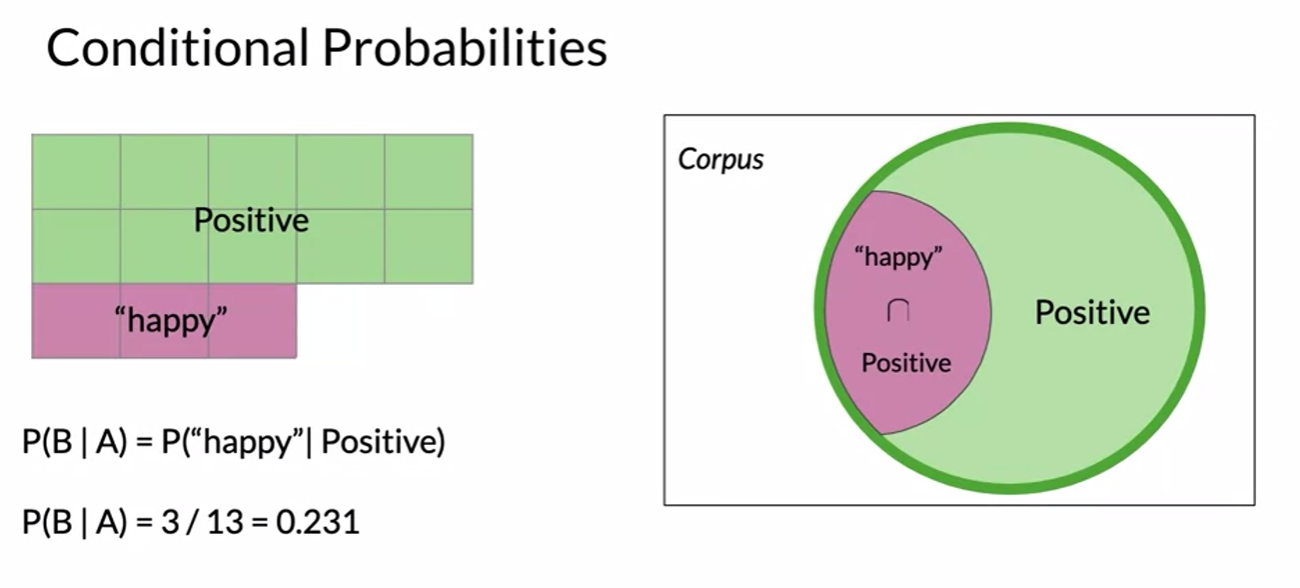
- positive중에 happy
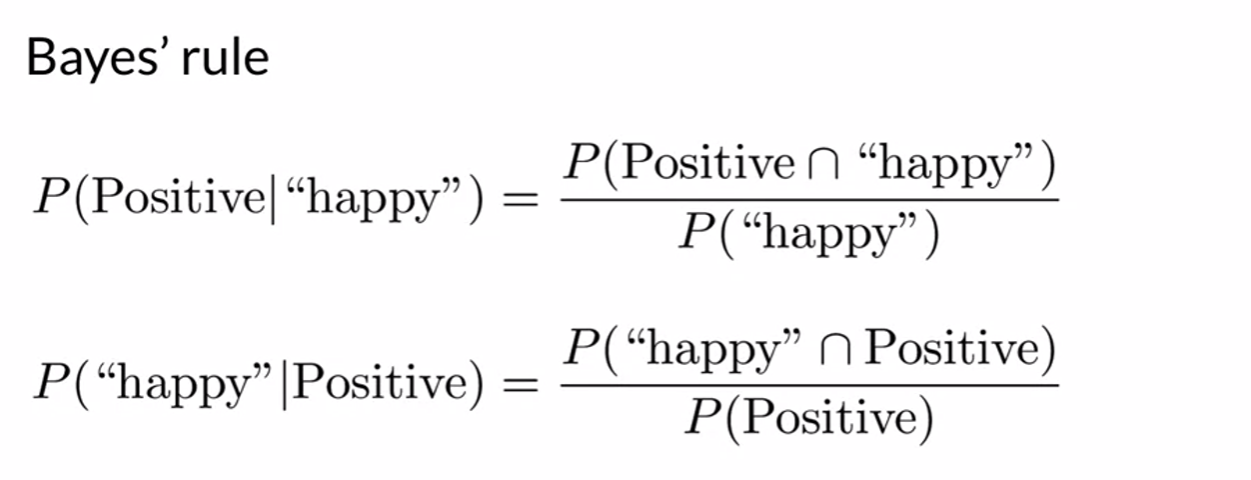

Naïve Bayes Introduction
- naive bayes is example of supervised machine learning
- share many similarities with logistic regression method

- total negative also 13
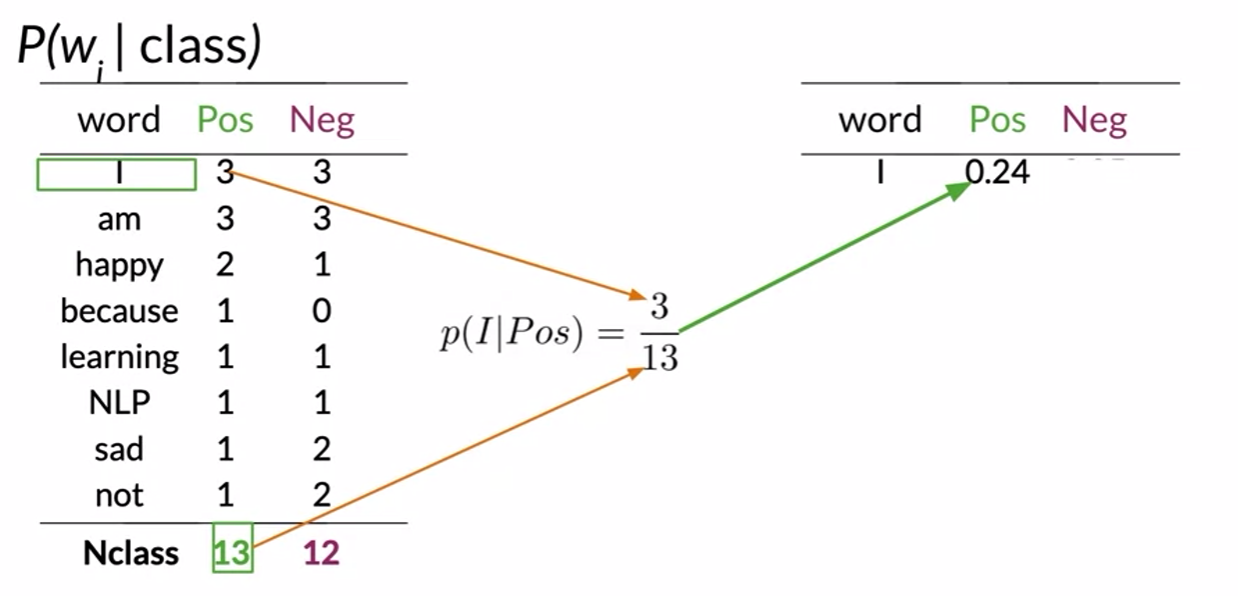


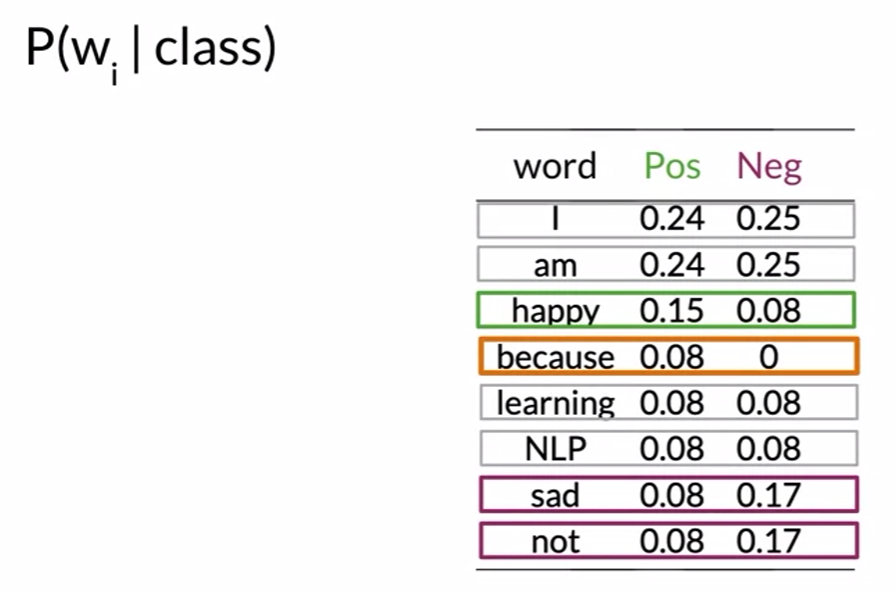
-
neutral words(I, am, learning, NLP), power words(happy, sad, not)
-
problem : because
- to avoid this, smooth probability function

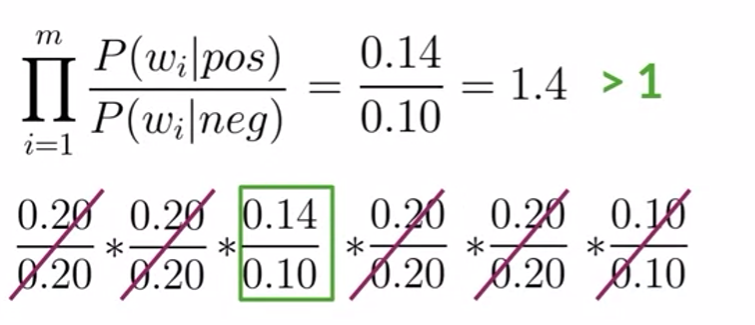
- neutral words will be cancle out in the expression
- rest value is higher than 1, which means more likely correspond to positive sentiment.

Laplacian Smoothing
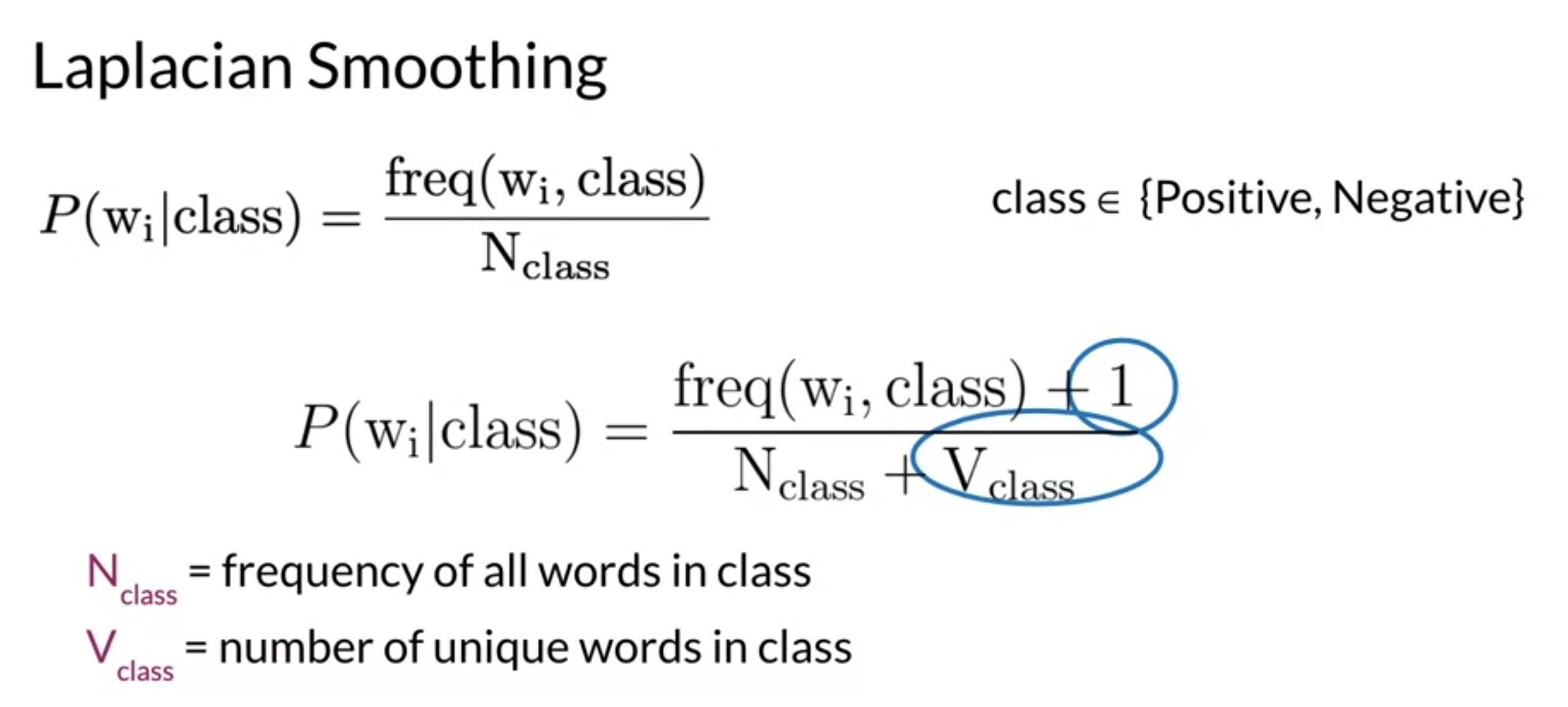
- avoid from probability being zero
- 1을 numerator에 넣어서 0이 될 확률 회피.
- V words to normalize
- denominator에 V를 추가해줌으로써 모든 확률의 합이 1이 된다.



Log Likelihood, Part 1
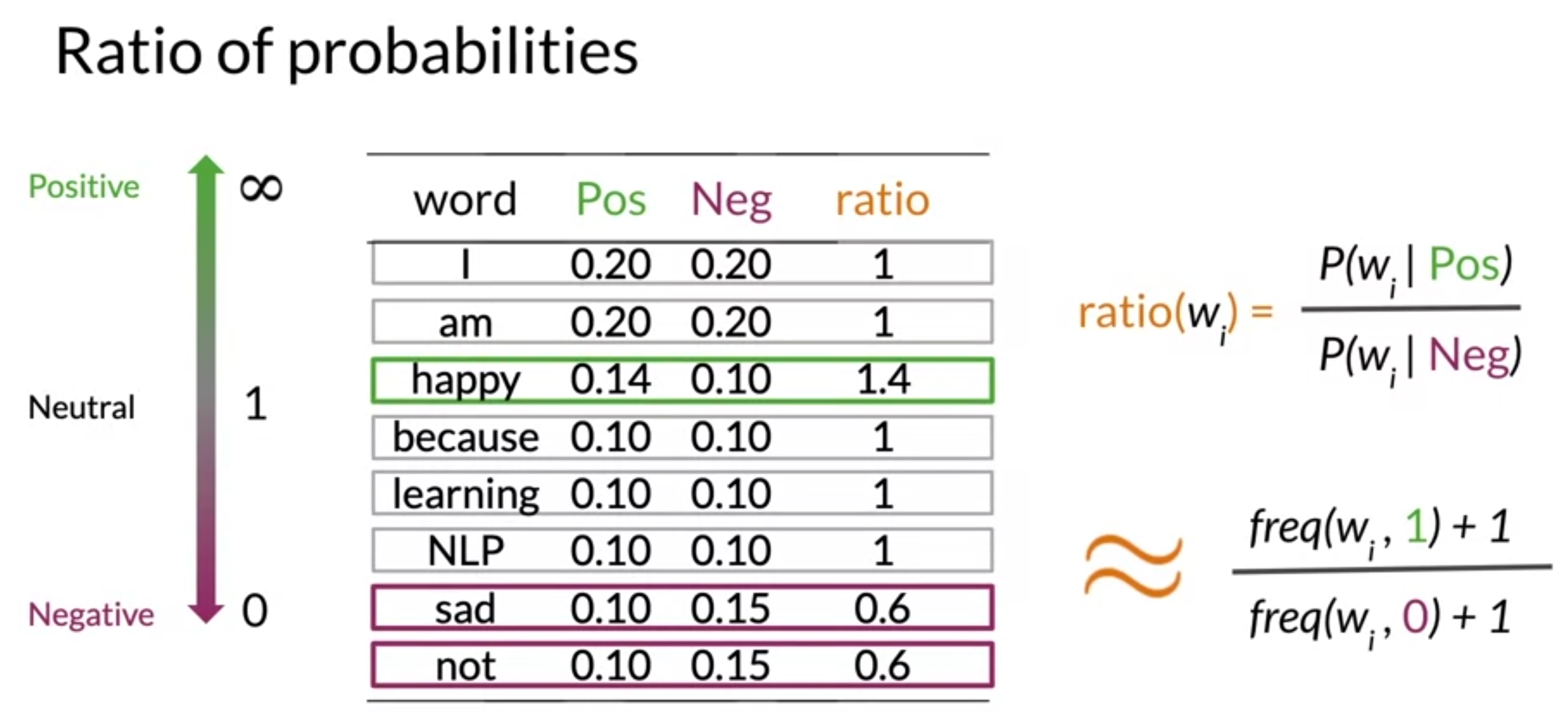
- conditional probabilities를 사용해서 ratio 계산
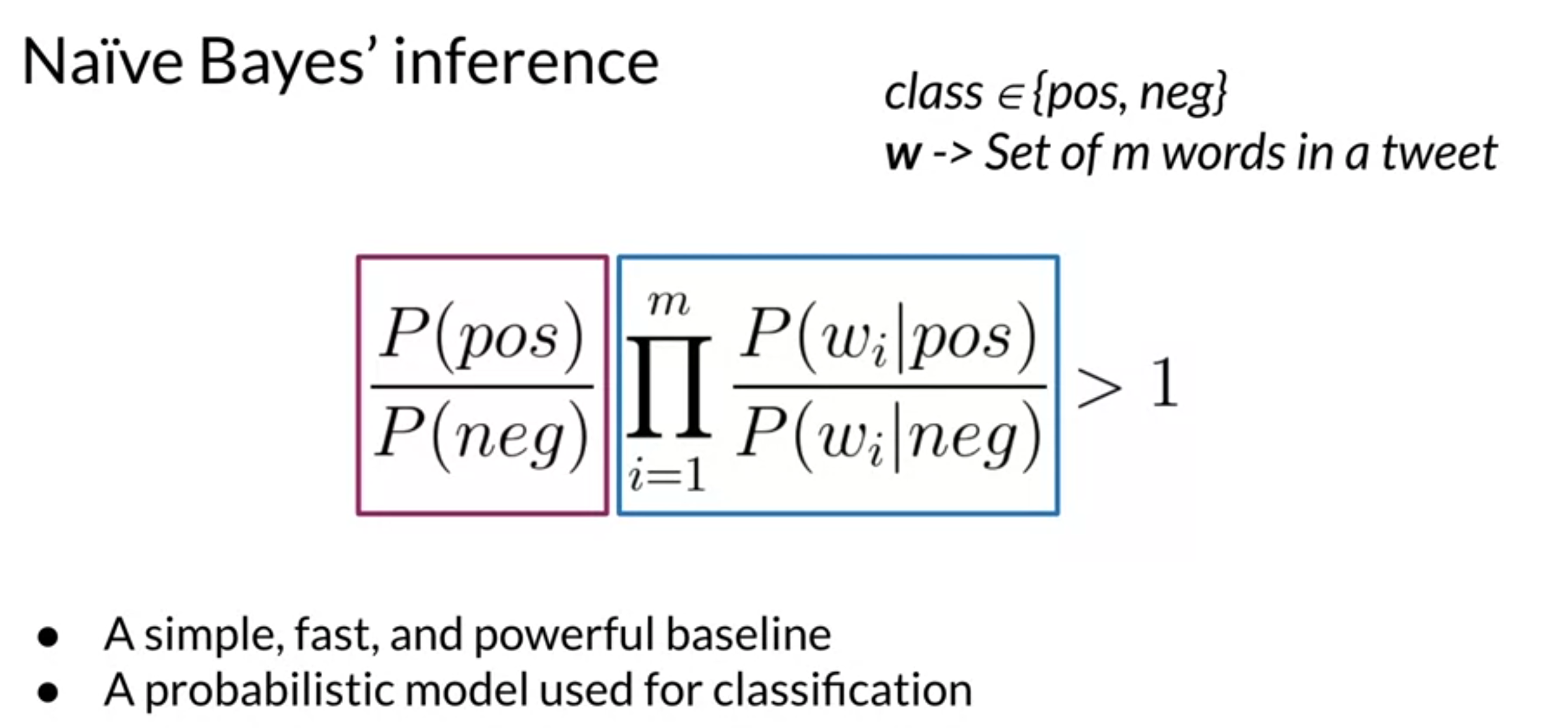

- as m gets larger, numerical underflow risk
- logarithm으로 해결

- lambda : log of the ratio of probability that word is positive devide by the probability negative word

- calculate log score of entire corpus by summing out the lambdas

- category by dividing conditional probabilities
- reduce risk of numerical underflow by using logarithm we called lambda
Log Likelihood, Part 2

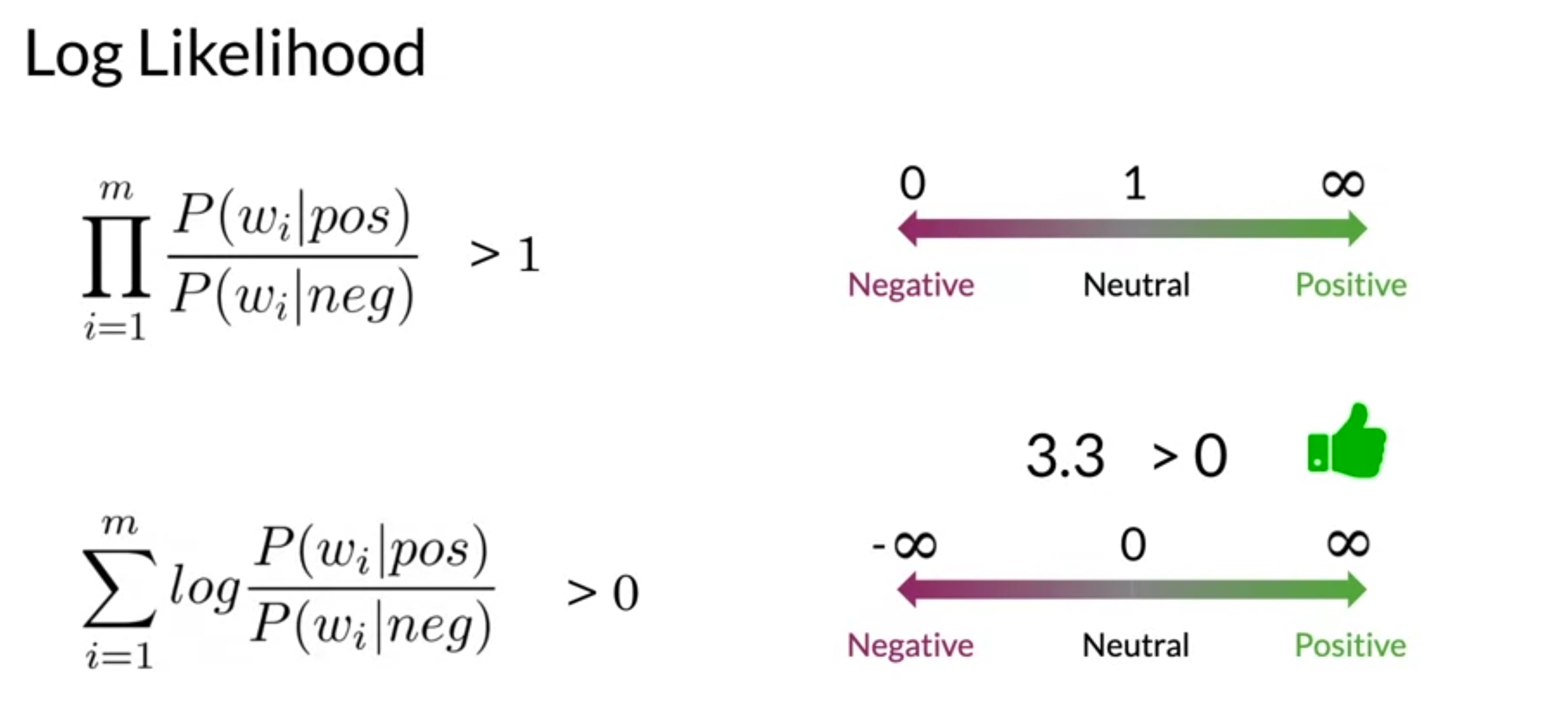
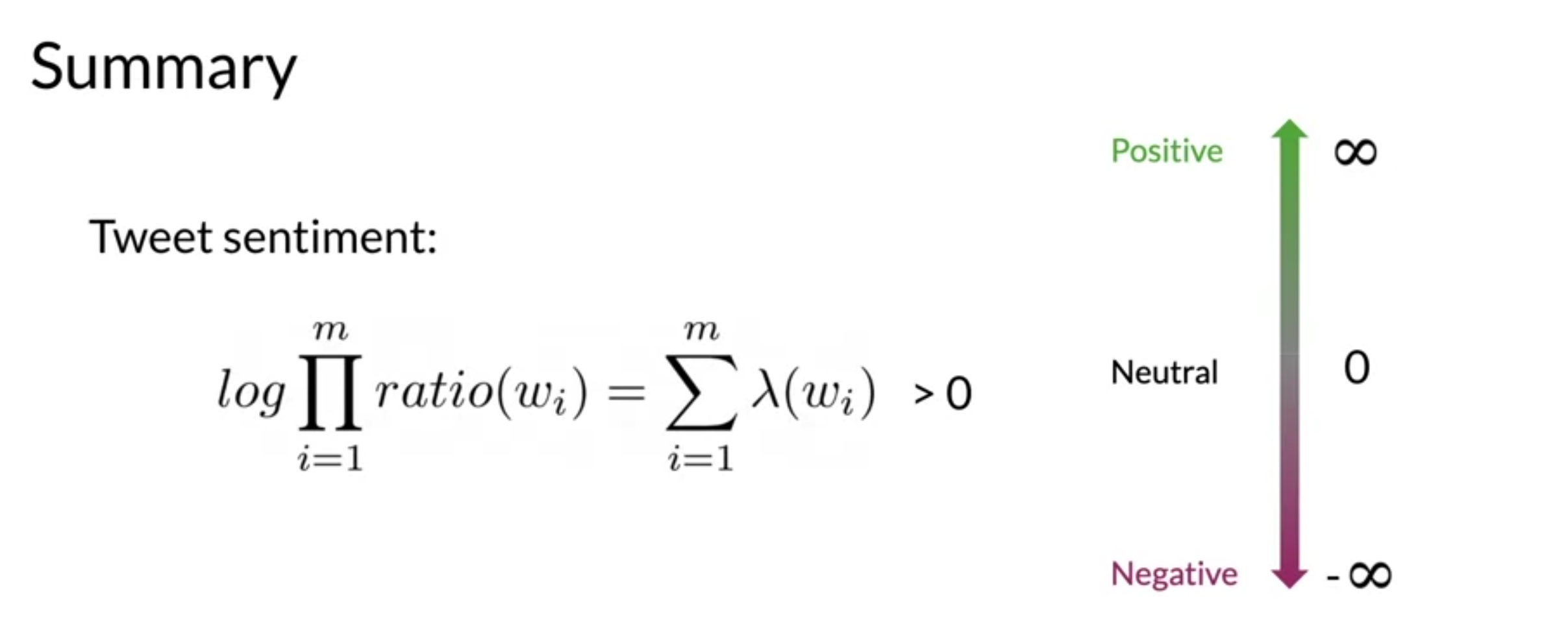
- for the log-likelihood decision threshold is zero
Training Naïve Bayes
- no gredient descent just counting frequencies of words in corpus
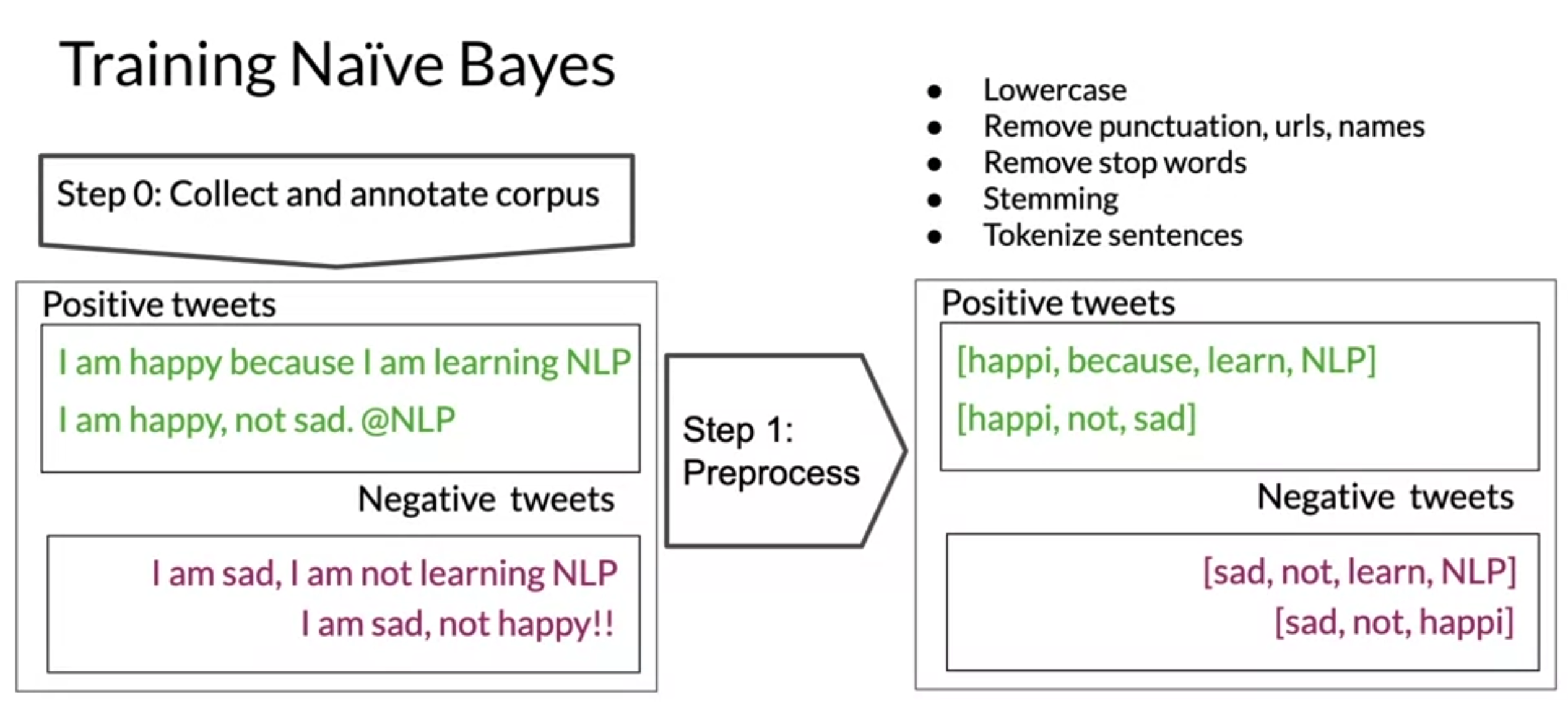
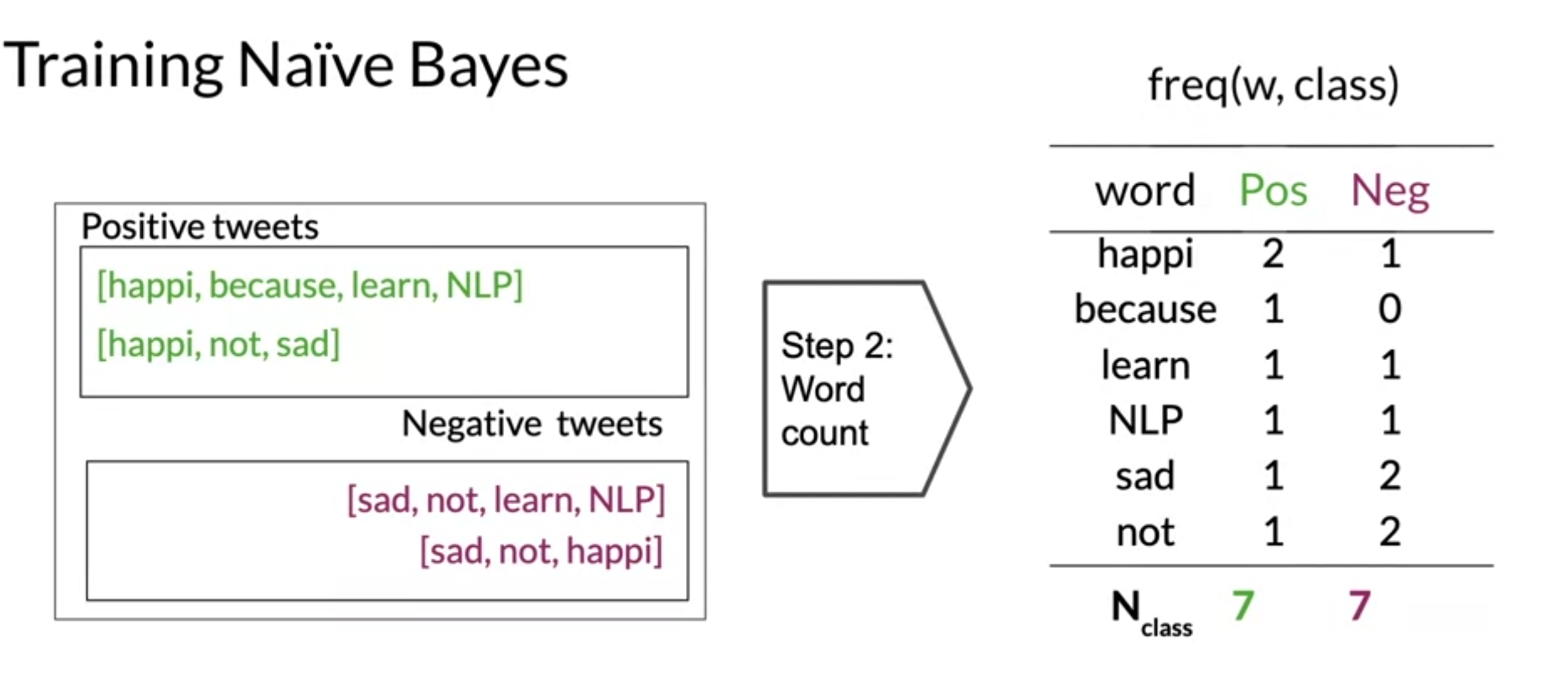
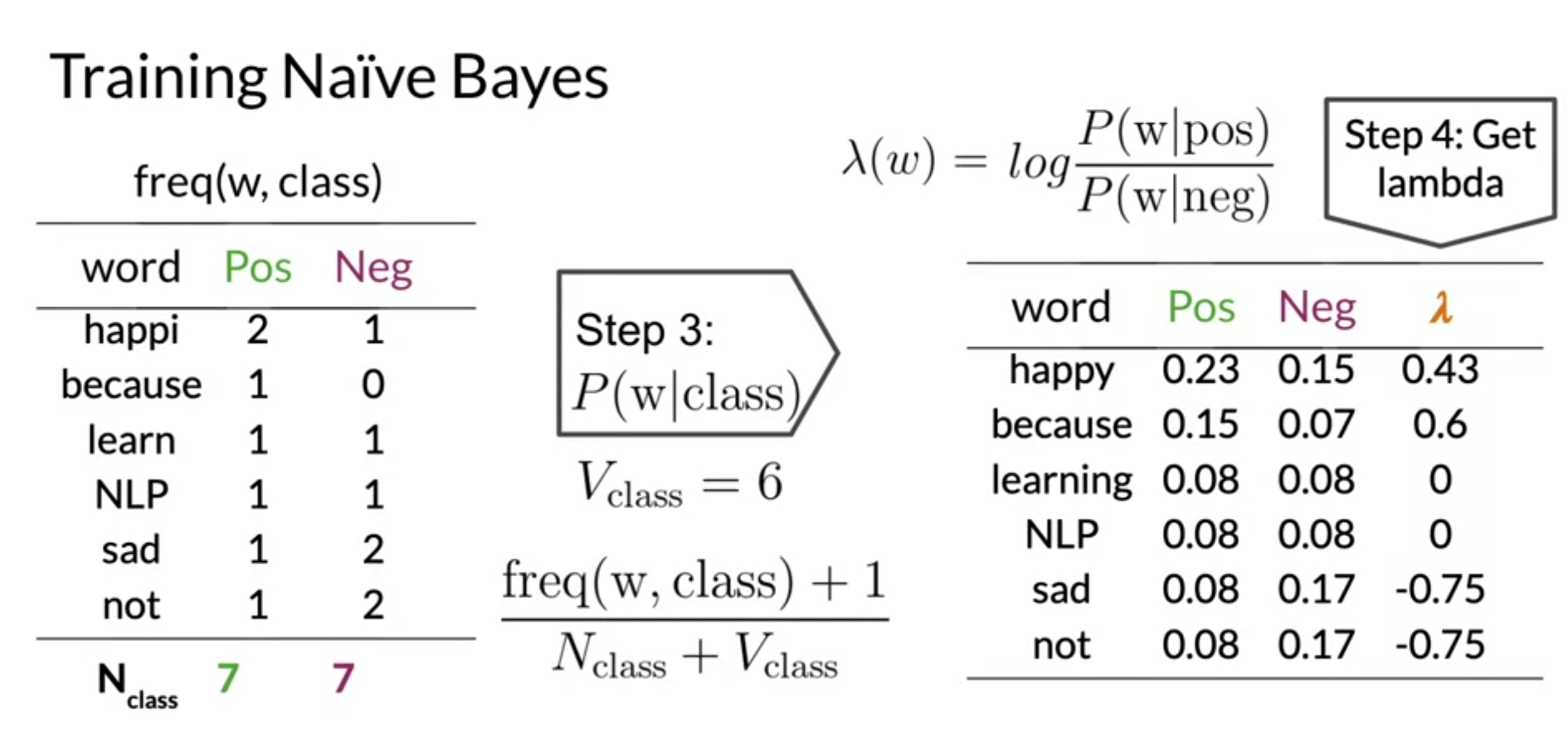
- get conditional probabilities by using Laplacian smoothing formula
- get the lambda score


Testing Naïve Bayes
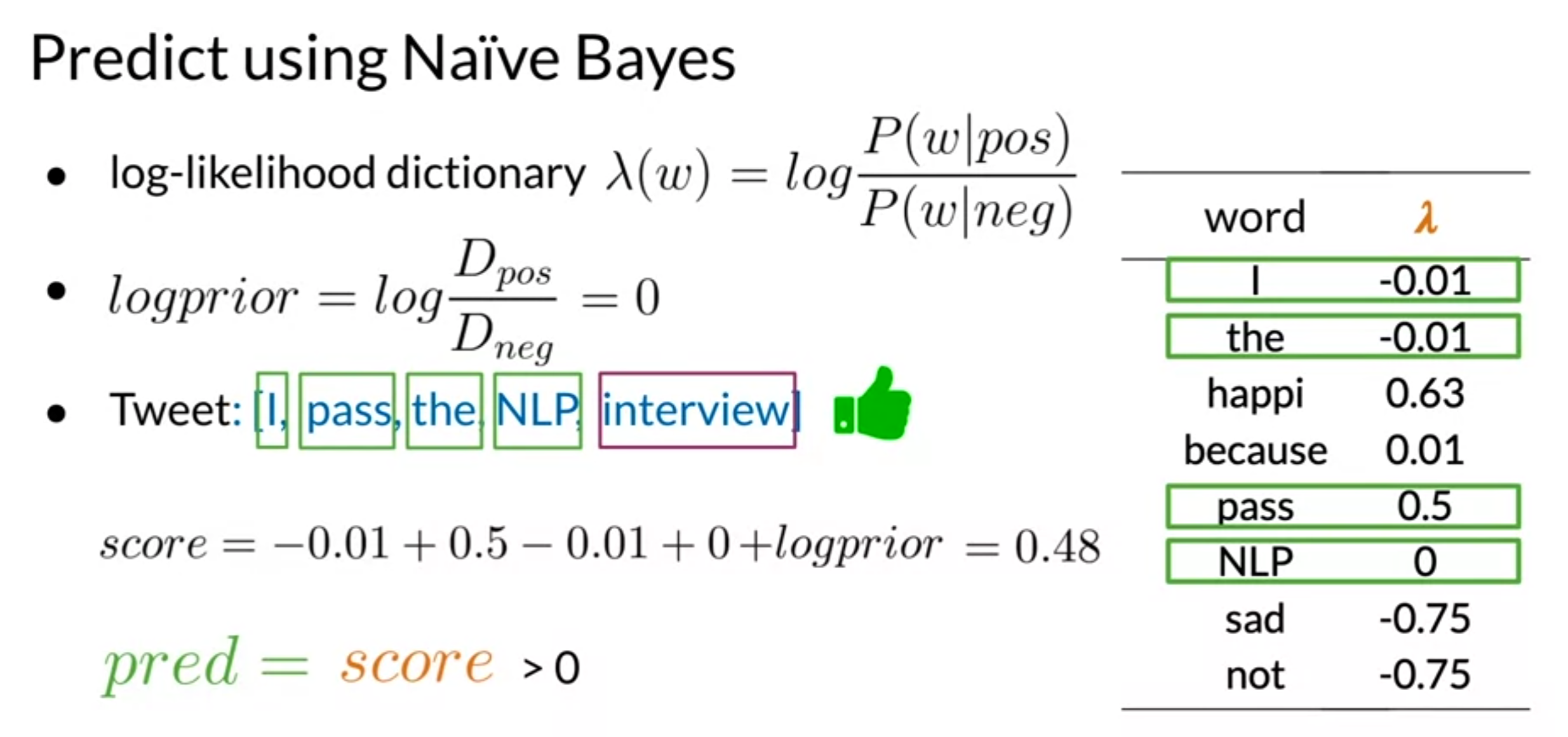
- interview no contributes

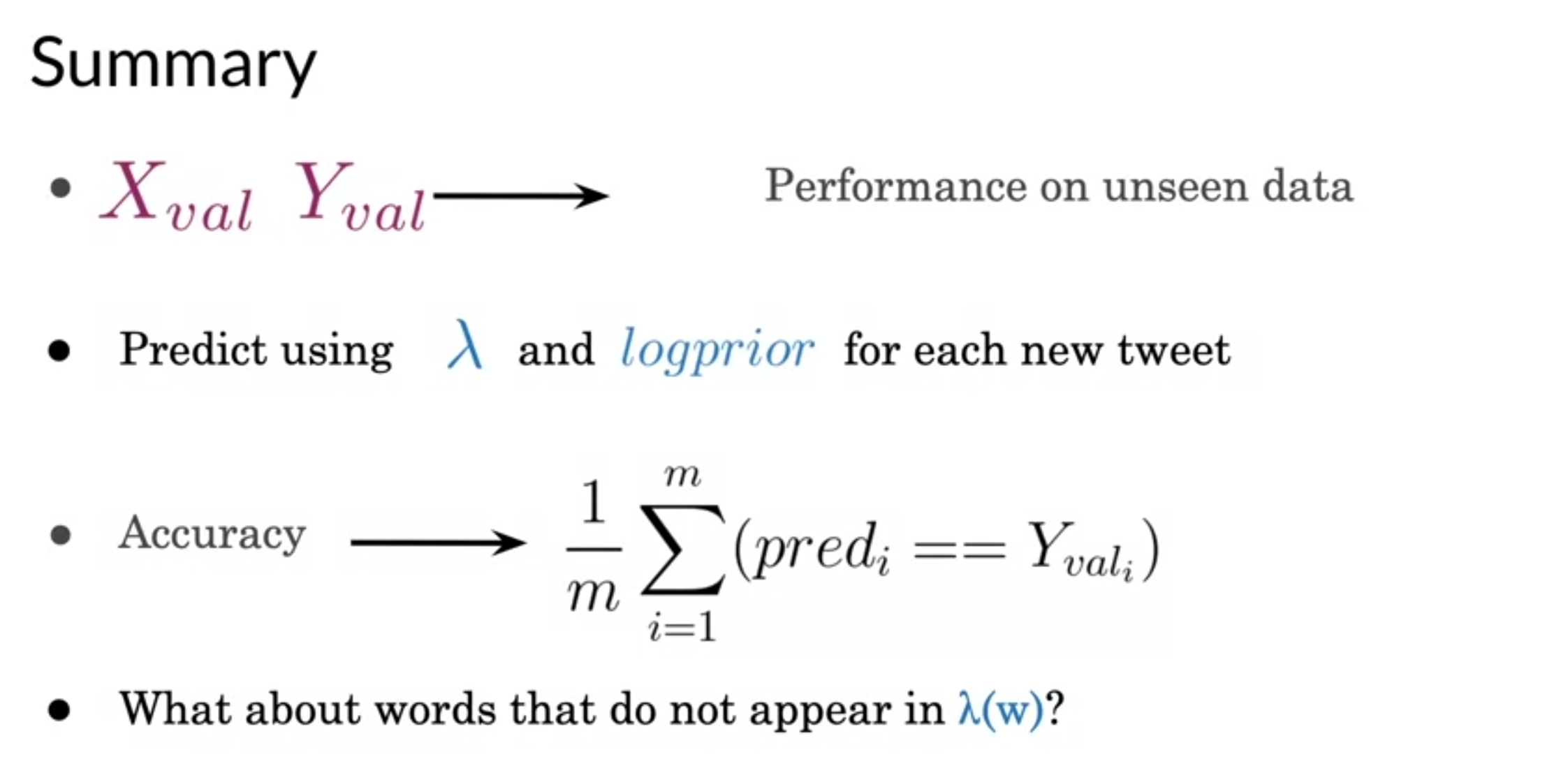
- words not appeared in lambda table are treated as neutral words
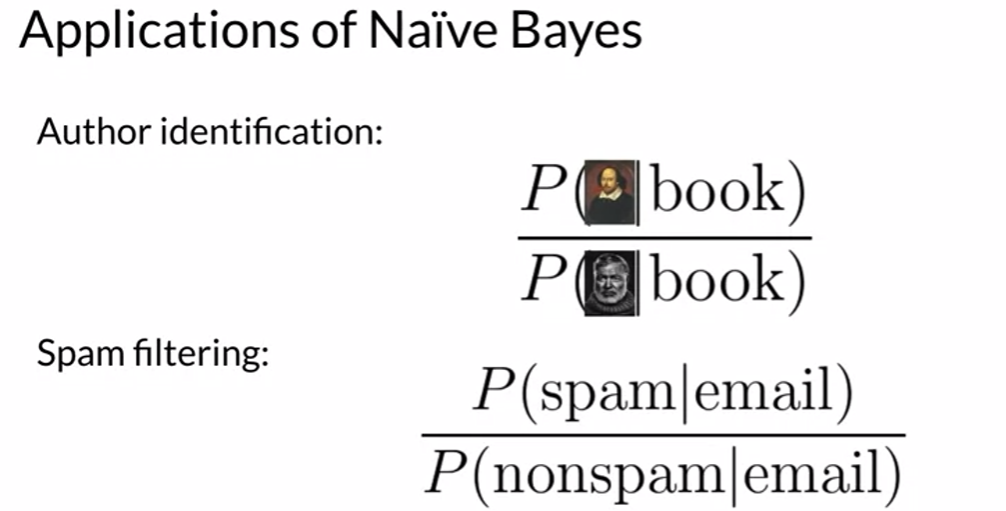
Applications of Naïve Bayes

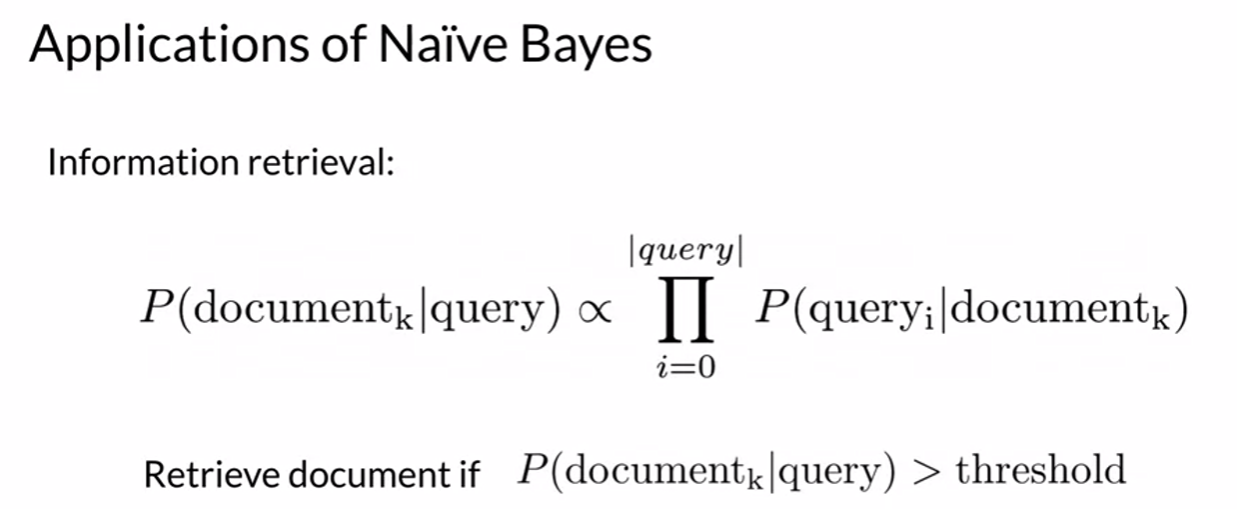


Naïve Bayes Assumptions


- sunny and hot is actually not independent but naive bayes assume it independent

- under or over estimation of naive bayes

- inappropriate words might been banned by platform

Error Analysis


- check out what actual sentences look like


- word order

