Effective Skill Unlearning through Intervention and Abstention
code: https://github.com/trustworthy-ml-lab/effective_skill_unlearning
paper: https://arxiv.org/pdf/2503.21730
published: 25.03.29(NAACL 2025 Main Conference Long Papers)
| 구분 | 내용 |
|---|---|
| Category | unlearning(간단하게 말하면 지식 삭제) |
| 훈련 여부 | X |
| 한계 | 프로빙 데이터셋이 존재하지 않을 경우 구현이 어렵다. 프로빙 데이터셋이 민감 데이터일 경우, 법적으로 한계가 존재함. 하이퍼 파라미터 튜닝을 자동화하는 방법이 없음 |
읽기 전
해당 분야에 약했지만, NAACL 의 제일 맨위에 올라온 논문을 안읽으면 인생 손해볼 것 같아서 읽어보려고 한다. 분석에 헛점이 많을 것 같지만, 나름대로 최선을 다해 분석하려고 한다.
- 논문에서 다양한 실험을 통해 해당 방법론을 제안한 근거를 탄탄하게 제공한다. 한번쯤 들어가서 직접 보고 어떤 아이디어로 출발하여 이런 분석을 실행했는지에 대한 사고흐름을 보면 좋을 것 같다.
모르는 용어- 프로빙 데이터셋: 모델의 내부 상태를 관찰(probe)하기 위해 사용하는 입력 데이터
일단, 이 장르가 생소해서 왜 unlearning이 중요한지 찾아봤다. 크게, 4가지 이유 때문에 해당 연구가 진행되고 있다고 말한다.
보안 프라이버시 보호
학습 중에 개인정보, 민감 정보, 혹은 저작권 침해 요소 등을 무단 학습했을 가능성이 존재하기 때문에, 해당 정보를 단순히 “답하지 않도록 막는 것” 보다, 모델 내부에서 진짜 그 지식을 제거하는 게 더 중요하다.
사용자가 요청 시, 자신에 관한 정보를 지우라고 요구할 수 있는 GDPR '잊혀질 권리'의 기술적 실현.
악용 가능성 차단
LLM이 너무 똑똑하면 악용될 위험도 커진다.(예: 해킹 코드, 마약 제조법, 불법 금융 도구 등.)
이런 악용 지식을 사후적으로 지워야 할 필요가 있는데, 이때 모델 전체를 다시 학습시키는 건 너무 비효율적이다. 따라서 훈련 없이도 특정 능력을 “까먹게 만드는” 기법이 유용하다.
특정 능력의 제거로 인한 통제 가능성
모델이 과하게 어떤 능력(예: 수학, 논리적 추론 등)에 의존하면, 문맥상 맞지 않는 경우에도 자꾸 그 능력을 사용하려고 시도한다.
( 예: 간단한 질문에도 "chain-of-thought" 답변을 억지로 하려는 현상.)
이때 해당 능력을 부분적으로 억제하거나 제거하면 모델의 행동 양식을 제어할 수 있다.
연구적 측면 – 모델 해석성과 모듈화
특정 능력을 제거할 수 있다면, 그 능력이 모델 내 어디에 저장되어 있는지를 알아낼 수 있음을 의미한다. 즉, 모델이 어떤 모듈적 구조로 기능을 수행하는지 분석할 수 있어, 해석 가능한 AI(Interpretable AI)에 한 걸음 더 다가가는 것이다.
다 논리적으로 타당하다고 판단된다. 정리를 계속해도 되겠다.
연구배경
앞서 언급했던 unlearning의 필요성 뿐만 아니라, 기존 연구에서의 한계점이 존재한다.
기존 방법과 한계
1. 특정 데이터셋에 대한 지식을 제거 후 파인튜닝
→ LLM에서의 파인튜닝 기반 방법은 비효율적(비용/시간)
2.모델의 특정 뉴런 집합을 잘라내는 가지치기 기법
→ 단순 뉴런 제거 방식은 모델 뉴런들의 다기능성 때문에 전체 능력에 예기치 않은 손상을 줄 수 있음
Contribution
- 새로운 기법 제안
피드포워드 신경망 층의 뉴런 활성화 분포 변화와 키 공간에서의 쿼리 벡터 군집화 현상에 착안하여, Neuron Adjust와 Key Space Detection이라는 두 가지 방법을 제안함 - 강력한 망각 성능 및 유지 능력 입증
수학 문제 풀이, 파이썬 코딩, 다국어 이해 능력에 대한 망각 실험을 통해, 제안한 기법들이 80% 이상의 상대적 성능 저하를 보였으며, 일반 지식에 대한 성능 저하는 10% 미만으로 억제함
제안 방법
모델 내부 개입(intervention)을 통한 방법과 응답 기권(abstention)을 통한 방법, 두 가지를 제안한다.
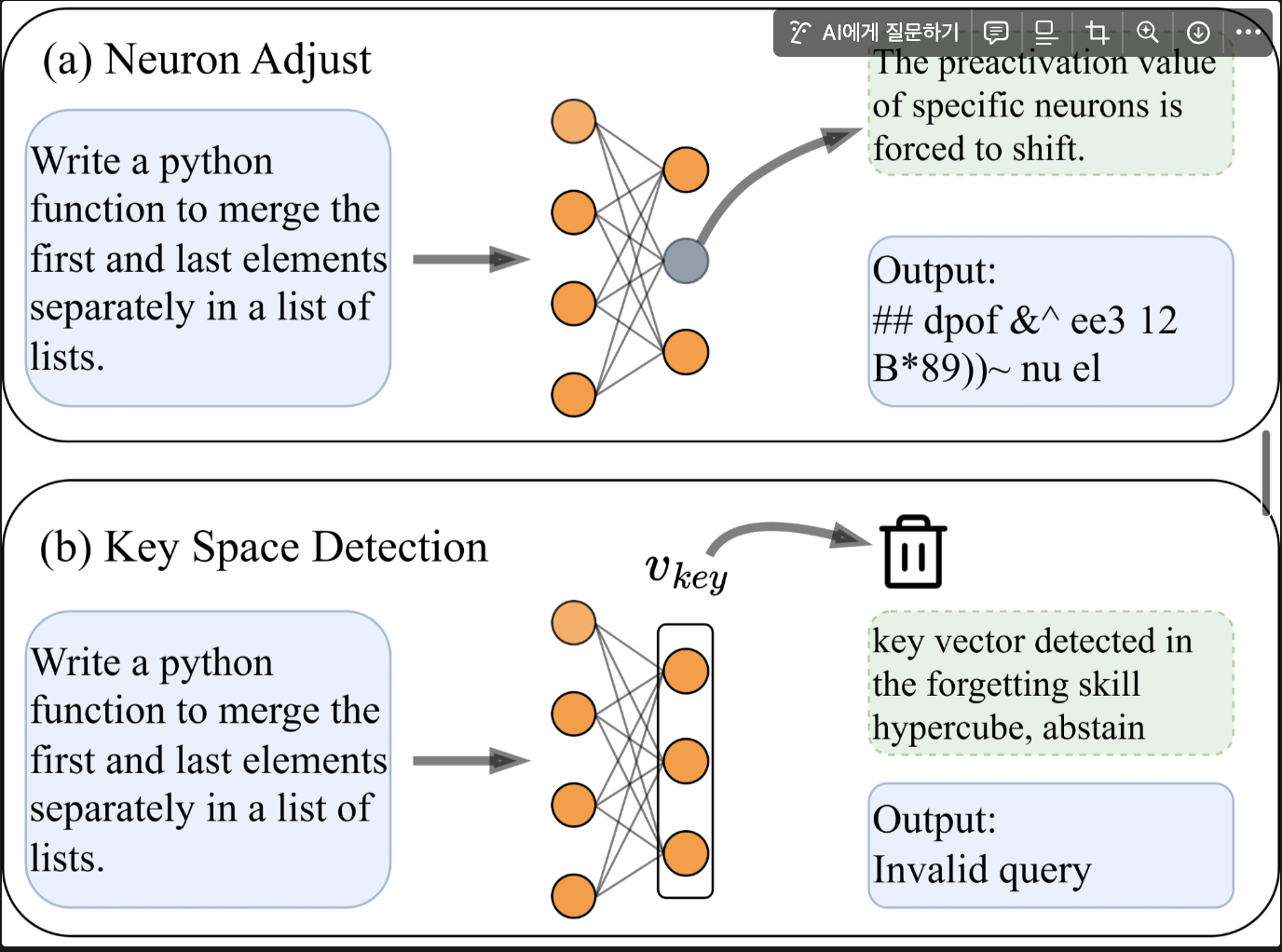
- 첫 번째 기법 Neuron Adjust는 뉴런 활성값을 조정하여 특정 능력을 억제하고자 함
- 두 번째 Key Space Detection은 특정 능력에 해당하는 내부 표현을 탐지하여 아예 답변을 생성하지 않도록 함
2.1 뉴런 값 조정 기법: Neuron Adjust
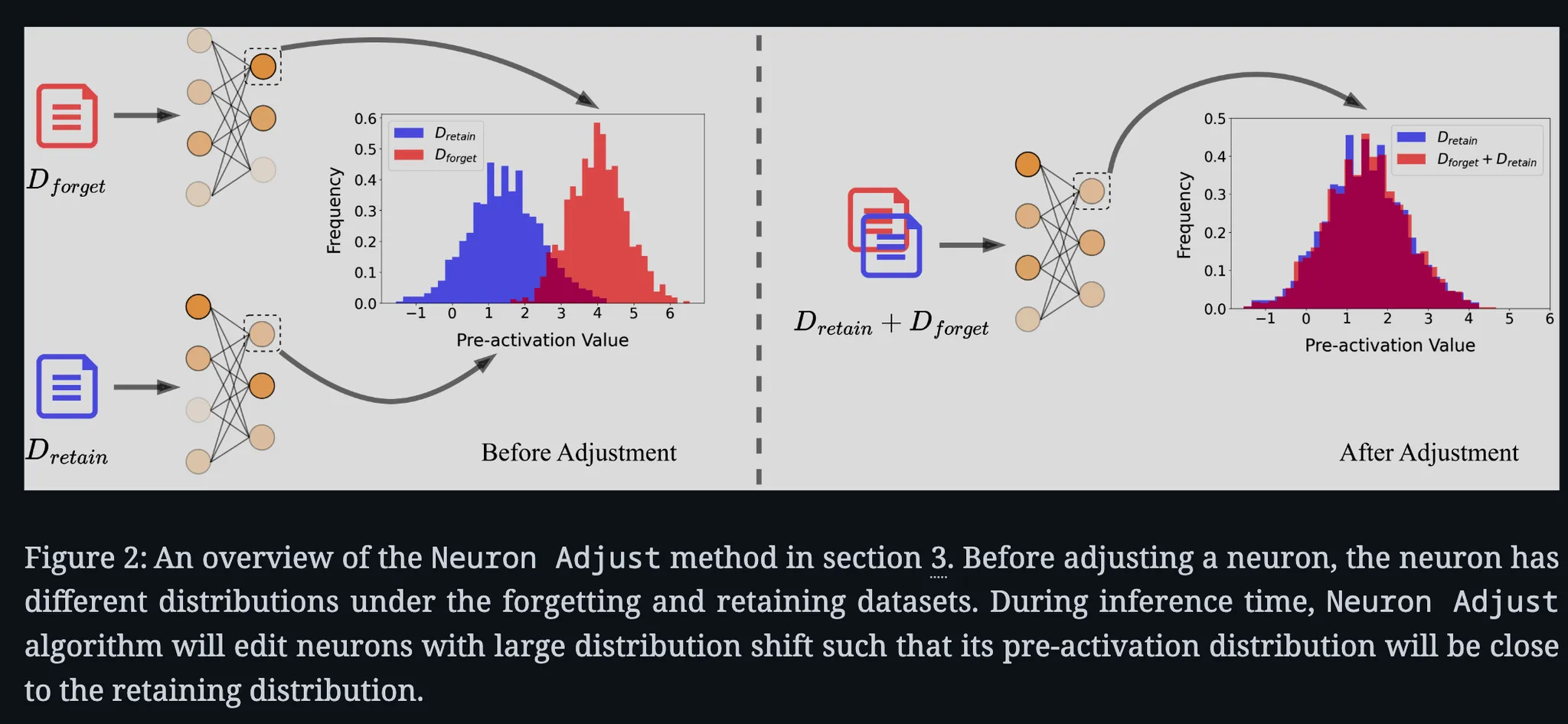
Neuron Adjust가 단순 제거가 아닌 우도 기반 조정이라는 사실을 강조함. 알고리즘1과 직접 연관.
추론 시 피드포워드 층 뉴런의 프리액티베이션 값을 동적으로 조정함으로써 특정 능력을 망각시키는 방법
아이디어: 모델이 서로 다른 능력을 발휘할 때 뉴런들의 활성화 분포가 달라짐
실험: 실제 Gamma-2B을 수학 문제와 코딩 문제로 프로빙하여 개별 뉴런의 활성화 값 분포를 비교함
결과:
1. 수학 데이터를 넣었을 때와 코딩 이터를 넣었을 때 활성화값의 분포가 뚜렷이 달라지는 현상을 확인
2. 코딩 관련 토큰과 수식 관련 토큰 모두에 활성화되는 등 여러 의미를 혼합적으로 담당하는 뉴런도 존재함
→ 정교한 교정이 필요하다.
방법론 : Shifting

- 망각 대상 능력(예: 코딩)과 유지할 능력(예: 수학 혹은 일반 능력)에 각각 특화된 프로빙 데이터셋을 모델에 입력하여, 각 뉴런이 두 경우에 나타내는 프리액티베이션 값들을 수집한다.
- 각 뉴런별로 망각 대상 능력에서의 값 분포와 유지 능력에서의 값 분포를 가우시안(정규분포)으로 근사하고, 그 평균과 표준편차를 계산해 저장한다.
- 추론 단계마다, 각 뉴런의 현재 프리액티베이션 값이 앞서 구한 두 분포 중 어디에서 나왔을 법한지 우도(likelihood)를 계산한다.
- 어떤 뉴런의 활성값이 망각하려는 능력의 분포에서 나왔을 가능성이 더 높다면, 해당 값이 유지 능력 분포에 더 가까워지도록 값을 이동시킨다.
- 반대로, 이미 유지 능력 분포에서 발생한 것이라면 그대로 둔다.
위의 알고리즘을 코드로 반영하면 다음과 같다.(정확하지 않음으로, 후에 깃허브를 뒤져봐야겠다)
import numpy as np
from scipy.stats import norm
def neuron_adjust(v, mu_r, sigma_r, mu_f, sigma_f):
"""
v: float, inference-time pre-activation value of a neuron
mu_r, sigma_r: mean and std of the retaining distribution
mu_f, sigma_f: mean and std of the forgetting distribution
returns: adjusted value vadjust
"""
# 1. 확률 계산 (정규분포의 PDF 이용)
pr = norm.pdf(v, loc=mu_r, scale=sigma_r)
pf = norm.pdf(v, loc=mu_f, scale=sigma_f)
# 2. 조정 여부 판단
if pr < pf:
alpha = pf / (pr + pf)
if np.random.rand() < alpha:
# 대칭 보정 방식
vadjust = 2 * mu_r - ((v - mu_f) * (sigma_r / sigma_f) + mu_r)
else:
vadjust = v
else:
vadjust = v
return vadjust
def estimate_distribution(activations: np.ndarray):
"""
activations: shape (N,), collected pre-activation values
return: (mean, std)
"""
return np.mean(activations), np.std(activations) + 1e-8
def get_pre_activations(model, dataset, layer_idx, neuron_idx):
pre_acts = []
for input_ids in dataset:
with torch.no_grad():
hidden = model.embed(input_ids)
z = layernorm(hidden)
pre_act = model.mlp[layer_idx].W_up(z)
pre_acts.append(pre_act[:, neuron_idx].cpu().numpy())
return np.concatenate(pre_acts)
v_retain = get_pre_activations(model, D_retain, layer_idx=17, neuron_idx=693)
v_forget = get_pre_activations(model, D_forget, layer_idx=17, neuron_idx=693)
mu_r, sigma_r = estimate_distribution(v_retain)
mu_f, sigma_f = estimate_distribution(v_forget)
v = current_pre_activation_value
v_adjusted = neuron_adjust(v, mu_r, sigma_r, mu_f, sigma_f)
2.2 키 공간 감지 기법: Key Space Detection
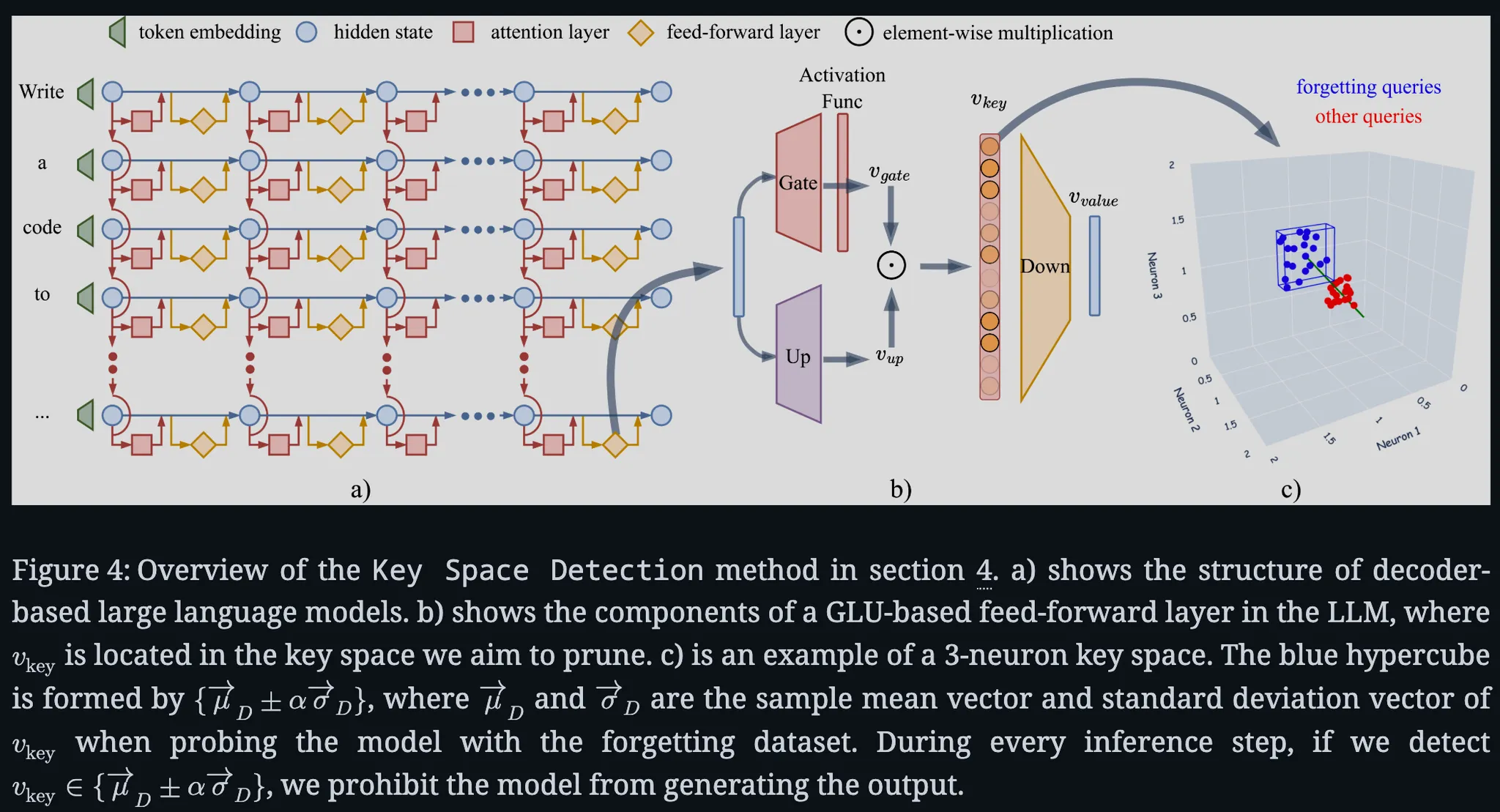
뉴런 개별 조정 대신 다수 뉴런의 공동 패턴을 한꺼번에 활용한다는 점에서 Neuron Adjust와 대조적임
방법론: 모델 내부 피드포워드 층의 고차원 활성 공간에서 특정 능력에 대응하는 쿼리 벡터들이 모여 있는 영역(클러스터) 을 찾아내고, 그 영역에 속하는 입력 쿼리에 대해서는 아예 모델이 응답을 생성하지 못하도록 막는 방법
아이디어 : 특정 능력을 이끌어내는 입력은 모델 내부에서 서로 유사한 활성화 패턴을 보일 것(가정)
실험: Llama 계열 모델에 수학 문제(GSM8K)와 코딩 문제(MBPP)를 각각 입력한 경우, 두 종류의 입력에서 발생하는 FFL 활성화 벡터들이 고차원 공간에서 뚜렷이 구분되는 클러스터를 형성이 보임
결과:
1. 피드포워드 층의 '키 공간(key space)'에서 특정 능력 관련 쿼리들의 활성화 벡터가 조밀하게 모임
2. 모델의 계층이 깊어질수록 같은 능력의 쿼리 벡터끼리 더 밀집된 초입방체(hypercube) 형태로 모이고, 서로 다른 능력의 클러스터 간 거리도 점차 증가**하는 등 분리가 뚜렷함
1. 능력별 하이퍼큐브 정의
- 망각 대상 능력의 프로빙 데이터셋을 사용하여, 선택한 피드포워드 층(예컨대 마지막 MLP 층)의 활성화 벡터들을 모음
- 벡터들의 각 차원별로 평균값과 표준편차를 계산하고, 이를 중심으로 하는 초입방체(hypercube) 영역을 정의
- 하이퍼큐브의 크기는 하이퍼파라미터 로 조절하며, 일반적으로 범위로 설정
- 값을 작게 잡으면 망각하려는 능력의 쿼리만 엄격히 포함하고 다른 입력은 배제하는 좁은 영역이 되고, 를 크게 잡으면 더 많은 벡터(잠재적으로 다른 능력까지) 포함하는 넓은 영역이 된다
- 즉 는 망각 효과와 기타 능력 보존 사이의 트레이드오프를 조절하는 하이퍼파라미터
2. 추론 시 탐지 및 기권
- 추론에서 토큰을 생성할 때 해당 층의 현재 활성화 벡터가 위에서 정의한 하이퍼큐브 안에 속하는지 검사
- 벡터가 망각 대상 능력의 하이퍼큐브 영역 안에 들어오면, 모델이 해당 입력에 대해 그 능력을 발휘하려 한다고 판단하고 곧바로 출력을 중단시킴
- 현재 쿼리 벡터가 해당 영역에 포함되지 않는다면, 모델은 정상적으로 다음 토큰을 생성하며 추론을 이어감
- 출력 기권 조치는 망각시키고자 하는 능력이 발휘될 만한 상황 자체를 차단함으로써, 해당 능력이 겉으로 드러나지 않게 만드는 효과적인 차단 장치임
KSD는 응답을 "거부"하는 형태이므로, 모델이 해당 질문에 지식이 아예 없는 것처럼 만드는 것과는 조금 성격이 다를 수 있다.즉, 망각 대상 능력에 해당하는 질문을 받으면 정답을 못하는 것이 아니라 의도적으로 답변을 회피하는 것이므로, 활용 맥락에 따라서는 이 점을 고려해야 한다. 그럼에도 불구하고, 특정 능력의 출력만 효과적으로 차단하면서도 다른 부분은 손대지 않기 때문에 모델의 전반적 성능을 유지하는 데 매우 유리한 접근으로 보인다.
실험 결과
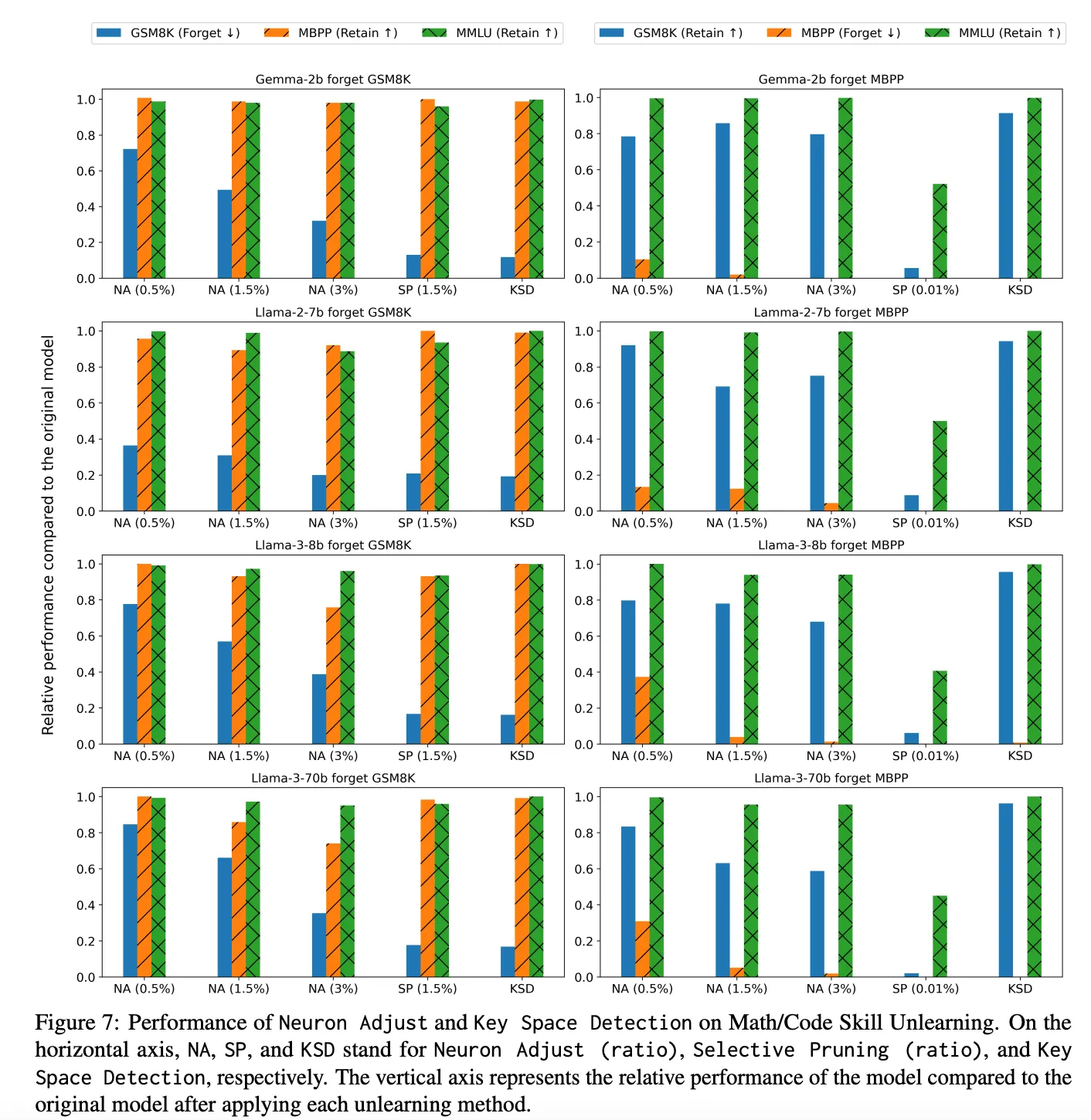
1. 수학/코딩 능력 망각 실험 (GSM8K / MBPP)
목적:
수학 능력(GSM8K) 또는 파이썬 코딩 능력(MBPP)을 선택적으로 제거
동시에 모델의 일반 상식(MMLU)이나 다른 능력은 유지
| 방법 | 망각 성능 ↓ (target skill) | 유지 성능 유지 ↑ (MMLU/비타겟) |
|---|---|---|
| Neuron Adjust (NA) | 최대 80% 이상 감소 가능 | 성능 손실 < 10%, 조정비율에 따라 다름 |
| Key Space Detection (KSD) | 최고 성능: 거의 완전한 망각 | 거의 0% 감소 – 가장 강력한 선택성 |
| Selective Pruning (SP) | 수학은 잘 잊지만 코딩은 문제 발생 | 코딩 능력 잊을 때 다른 능력 손상 심함 |
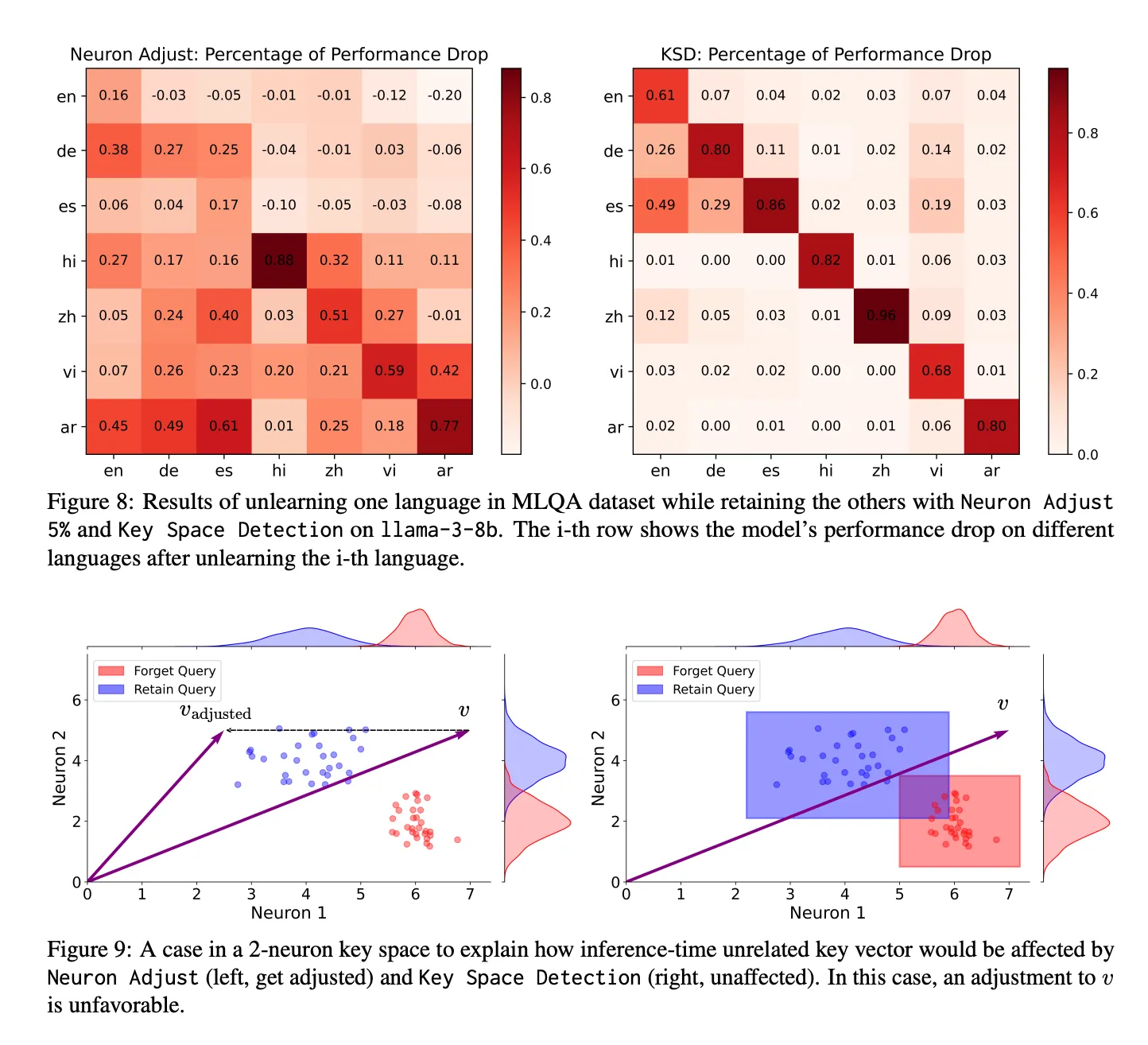
2. 다국어 언어 이해 능력 망각 (MLQA)
목적:
영어, 독일어, 중국어 등 특정 언어 질문응답 능력만 제거
다른 언어 능력은 유지
- Neuron Adjust:
- 영어, 힌디어, 스페인어 등은 잘 선택적 망각 가능
- 독일어, 중국어 등은 망각 시 다른 언어에도 영향 발생
- KSD:
- 모든 언어에서 목표 언어만 선택적으로 망각
- 다른 언어 성능은 거의 변화 없음
해석:
- KSD는 언어 능력 간 뉴런 공간 분리를 잘 활용함
- NA는 능력이 얽혀 있으면 부작용이 있을 수 있음
3. 다중 능력 망각 (MBPP + GSM8K 동시 제거)
목적:
동시에 두 개의 능력을 잊을 수 있는가?
모델의 기본 능력(MMLU)은 유지되는가?
| 항목 | 원래 모델 | KSD 적용 후 |
|---|---|---|
| GSM8K | 47.5% | 8.1% |
| MBPP | 61.1% | 0.5% |
| MBPP+ | 51.1% | 0.5% |
| MMLU | 64.9% | 64.8% |
종합적으로 해당 논문을 바탕으로 결과를 내보면 아래 표로 깔끔하게 정리되는 것 같다.
| 비교 항목 | Neuron Adjust (NA) | Key Space Detection (KSD) | Selective Pruning (SP) |
|---|---|---|---|
| 망각 효과 | 좋음 | 매우 강함 | 보통 ~ 강함 |
| 유지 능력 보존 | 대부분 가능 | 가장 잘 보존됨 | 심각한 손상 가능성 |
| 다국어 선택성 | 언어에 따라 제한 | 모든 언어에 효과적 | 불명확 |
| 다중 능력 망각 | 한계 있음 | 확장 가능함 | 미지원 |
| 효율성 | O(1), 경량 | O(1), 가장 효율적 | 가벼우나 효과 미지수 |
한계점
논문을 읽다보니까 든 한계점은
프로빙 데이터셋이 존재하지 않을 경우 구현이 어렵다.
프로빙 데이터셋이 민감 데이터일 경우, 법적으로 한계가 있지 않을까?
하이퍼 파라미터 튜닝이 좀 힘들것 같다.
다음 연구로는 공통 뉴런을 건들여보는 연구를 진행할 것 같다.
라는 생각이 들었다. 실제로 논문에서도 한계점을 설명하고 있다.
1. 프로빙 데이터셋에 의존
“우리 방법은 특정 기능이 잘 반영된 데이터셋이 존재할 때에만 작동 가능하다.”
특히 Out-of-Distribution 능력이나 사후적으로 우연히 학습된 정보는 대표 데이터로 포착하기 어렵기 때문에 한계.
2. 서로 얽힌 능력을 분리하기 어려움
“상호의존적인 능력을 지우면서 유지 능력까지 보존하려면 더 정밀한 조정이 필요하다.”
- 예를 들어, 독일어와 네덜란드어처럼 내부 뉴런 표현이 겹치는 언어 능력들은 하나만 지우기 어려움.
- Neuron Adjust는 뉴런 단위로 조정하지만, 이들은 공유 뉴런에 의존할 수 있어 유지 능력도 손상될 수 있음.
3. 하이퍼파라미터 튜닝 자동화가 미흡
“Neuron Adjust의 조정 비율 β, KSD의 하이퍼큐브 크기 α를 자동으로 정하는 기법이 없다.”
4. KSD는 비망각 영역에 대한 보장은 있지만,
“KSD는 하이퍼큐브 외 영역에 대해서는 영향이 없지만, 망각 능력이 비볼록(non-convex)한 영역에 퍼져 있다면 일부를 놓칠 수 있다.”
개인적으로 인상 깊었던 부분
"모델 내부의 표현 공간에서 서로 다른 능력(skill)이 층이 깊어질수록 더 명확히 분리되어 있는가?"를 검증하기 위해 구조적으로 하이퍼 큐브 크기를 검증함 (하이퍼 큐브 크기: max value−min value)
