PA-RAG: RAG Alignment via Multi-Perspective Preference Optimization
code: https://github.com/wujwyi/PA-RAG
paper: https://arxiv.org/abs/2412.14510
Published: 2024.12.19(NAACL 2025 Main Conference - Long Papers)
| Module | Generative Model |
|---|---|
| Type | 모델 학습 방법론 또는 데이터셋 구축 방법론 |
| 학습 필요 여부 | O |
| Main Idea | 인용 데이터셋 구축 및 3단계 DPO를 통한 응답의 정보성, 견고성, 인용의 품질 최적화 |
요약하자면…
기존 RAG 시스템은 end2end(self-rag, RetRobust-13B )과 파이프라인 시스템으로 구분할 수 있다. 해당 방법론들의 문제점은 응답의 정보성, 응답의 견고성, 인용의 품질에서 부족하다.
이를 해결하기 위해 훈련 데이터셋의 구축 방법을 제안하고 SFT(IFT)와 3단계의 DPO를 거쳐 기존 방법 보다 뛰어난 end2end RAG system PA-RAG를 제안한다.
결과:
정답 정확도(EM)에서 평균 +13.97%p 향상,
인용 재현율은 +49.77%p 향상
인용 정밀도는 +39.58%p 상승
기여 사항
- RAG 생성기의 포괄적 정렬 방법 제안: PA-RAG라는 새로운 학습 프레임워크를 통해, 대규모 언어 모델을 여러 관점의 선호 기준에 맞게 다단계 학습시킴으로써 특정 RAG 요구사항에 포괄적으로 부합하도록 만드는 방법을 제시함
- 고품질 학습 데이터셋(chatgpt로 생성된 데이터셋): 5.89만개의 SFT 데이터셋, 4.87만개의 선호 데이터셋
- 다각도 선호 최적화의 효과 입증: 광범위한 실험을 통해 각 관점별 선호 최적화가 개별적으로 그리고 종합적으로 성능 향상에 기여함을 보였습니다.
- 또한 DPO 기반의 선호 학습이 기존 SFT 대비 효과적이라는 것을 보여주어, 향후 유사한 LLM 정렬 과제에 활용될 수 있는 실용적 통찰을 제공했습니다.
배경 및 기존의 한계
배경: 응답의 정보성, 응답의 견고성, 인용의 품질을 해결하기 위해 제안됨
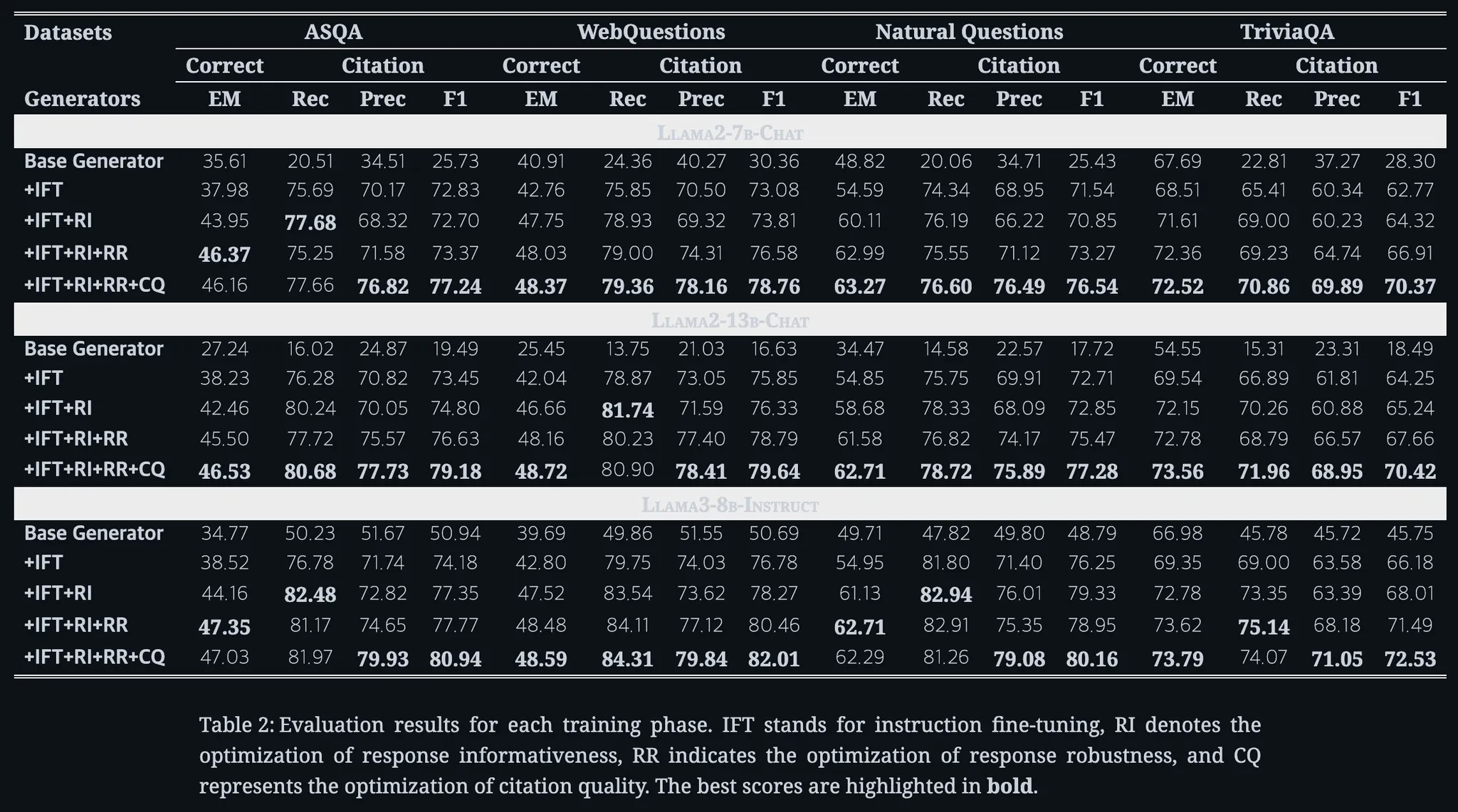
범용 LLM을 RAG 생성기로 그대로 사용하면 응답의 정보성, 응답의 견고성, 인용의 품질 측면에서 부족함이 관찰된다. 아래 실험 결과에서 Base Generator는 BSE LLM + RAG를 결합한 시스템이다.
이를 통해 비교했을 때, 모든 부분에서 제안된 방법론보다 떨어지는 것을 확인할 수 있다.
-
응답 정보성(Response Informativeness)
생성된 답변이 주어진 문서의 유용한 정보를 빠짐없이 포함하여 완전한 답을 제공해야 합니다. 고품질 정보와 불필요한 정보가 혼재된 프롬프트라면, 중요한 내용은 적극 활용하고 관련 없는 부분은 무시하는 능력이 필요합니다
-
응답 견고성(Response Robustness)
잡음이 섞인 문서 환경에서도 오류에 흔들리지 않고 정확성을 유지해야 합니다. 잘못된 또는 오해의 소지가 있는 정보가 포함되더라도 이를 걸러내고, 입력 컨텍스트가 불완전해도 일관되고 정확한 답변을 생성할 수 있어야 합니다
-
인용 품질(Citation Quality)
제공된 문서에 근거해 답변하고 출처를 명확히 표시해야 합니다. 답변의 각 주장(claim)은 출처 문서에 의해 충분히 뒷받침되어야 하며, 불필요하거나 무관한 문서를 인용하지 않아야 합니다. 올바른 출처 표기를 통해 생성 내용의 사실적 정확성과 추적 가능성을 확보해야 합니다.
기존 방식의 한계
RAG 시스템은 크게 End2End System과 Pipeline System으로 구성된다.
-
엔드투엔드
대상 도메인에 맞춰 지도학습 미세조정(Supervised Fine-Tuning, SFT)
- 실험
- 고품질 데이터로 RAG 시나리오의 모범 답안을 학습시켜 생성기의 응답 품질을 높이고자 했습니다.(Yoran et al, Feiteng Fang)
- 결과
- SFT 기반 방법은 특정 데이터 조건에서는 성능을 보이지만 전반적인 RAG 요구조건을 모두 만족시키지는 못했습니다.
- 원인
- 단일 단계의 SFT 만으로 위의 RAG System의 요구사항을 맞추기 힘듬
- 문맥 상황에 따라 달라지는 복합적인 요구들을 SFT만으로 학습하기 어려움
- 세부 선호도(preference) 정보가 반영되지 않음
- 실험
-
파이프라인
문서 재정렬 또는 필터링, 사후 검증 등을 통해 생성 답변의 신뢰도를 높이는 것
- 실험
- 검색된 문서를 재정렬하거나 불필요한 정보를 필터링하는 단계를 추가(Dong, Yu)
- 생성된 답변의 출처를 사후 검증/수정하여 품질을 개선하는 Vtg 기법 제안( Sun 등(2023),
- 결과
- 견고성 또는 인용 정확성 향상됨
- 다른 요구사항을 만족시키지 못함
- 추가 단계들은 추가적인 연산 비용과 지연을 야기하여 대규모 실시간 시스템에 적용하기에 비효율적일 수 있습니다.
- 실험
제안 방법: PA-RAG
목표 : 다중 단계의 학습 과정을 통해 LLM 기반 생성기가 응답 정보성, 응답 견고성, 인용 품질 등의 RAG 요구사항에 모두 부합하도록 조율하는 것을 목표
사용되는 테크닉
IFT + DPO를 통해 엔드투엔드 구조를 유지하면서도 생성기에 다양한 관점의 선호 정보를 학습시킴
Instruction Fine-Tuning(IFT)
목표: 문서를 활용하고 출처를 표기하는 것을 학습하는 것
프로세스: QA 데이터셋 → (골든 도큐먼트)검색 코퍼스에서 관련 문서 중 정답을 포함하는 문서만 5개 선택 → 인용 재작성 메커니즘 → 검증 → SFT 진행
결과: IFT를 거친 모델은 문서를 보고 정답을 추출 및 통합하고, 출처를 표시하는 방법을 기본적으로 학습하게 됩니다.
- 훈련 데이터 구축
훈련 데이터 구축 용 모델: ChatGPT-3.5( GPT-3.5-Turbo-1106 )
특이사항 :
인용 재작성 메커니즘을 도입
ChatGPT 프롬프트에 지침과 단답형 힌트를 통해 답변 질을 높임
- 기존 데이터셋에서 제공하는 질문과 단답형 답변을 확보한 후 고품질 문서를 확보해야함
- RAG 검색기를 통해 질문과 관련성이 높은 상위 100개의 문서(ex. 위키피디아)를 검색
- 단답형 답변을 포함하는 골든 문서(정답을 실제로 포함)만 필터링하여 유지
- 모든 정답 조각(short answers)이 포함되어야함
- 골든 문서 5개를 선택하여 컨텍스트로 삽입
- 단답형 답변을 포함하는 골든 문서(정답을 실제로 포함)만 필터링하여 유지
- ChatGPT를 이용한 답변 생성
- 프롬프트
Instruction: Write an accurate, engaging, and concise answer for the given question using only the
provided search results (some of which might be irrelevant) and cite them properly. Use an unbiased and
journalistic tone. Always cite for any factual claim.
When citing several search results, use [1][2][3]. Cite
at least one document and at most three documents
in each sentence. If multiple documents support the
sentence, only cite a minimum sufficient subset of
the documents.
Qustion: {Question}
The final answer should contain the following short
answers: {Short answers}
Documents: {Documents}
Answer:특별 지시문(instruction)과 정답 힌트(short answer hint)도 함께 제공하여 답변의 완전성을 높이려 했습니다
- 인용 재작성 메커니즘
ChatGPT의 답변에 포함된 출처 표기의 품질을 개선하기 위해 인용 재작성 메커니즘을 도입합니다. 아래의 단계를 통해 모든 주장에 대해 정확한 문서만 인용된 답변을 얻을 수 있습니다.- 첫째 , 인용문을 검증합니다. 답변의 각 문장(statement)에 대해, 해당 문장이 인용한 문서(전제)들이 그 주장(가설)을 만족시키는지 자연어 추론(NLI) 모델로 확인합니다
- 둘째 , 인용문을 구성합니다. 첫 번째 단계의 인용문이 주장을 뒷받침할 수 없는 경우, 실행 가능한 인용 체계를 탐색하기 위해 모든 프롬프트 문서의 인용문으로 멱 집합(power set)을 탐색합니다. 즉, 어떤 문서 조합을 인용하면 주장이 만족되는지 모두 시도해보아, 대체 가능한 올바른 인용을 구축합니다.
- 셋째 , 인용문을 단순화합니다. 인용문이 주장을 뒷받침할 수 있는 경우, 인용문이 주장과 관련이 없는지 하나씩 확인하고 관련이 없는 인용문을 제거합니다.
- 첫째 , 인용문을 검증합니다. 답변의 각 문장(statement)에 대해, 해당 문장이 인용한 문서(전제)들이 그 주장(가설)을 만족시키는지 자연어 추론(NLI) 모델로 확인합니다
- 최종 데이터 선별: 마지막으로, 생성된 답변 중에서 모든 정답을 포함하고 있으며 인용이 정확하게 달린 답변만 선별합니다.
이렇게 거의 완벽에 가까운 답변들을 Instruction 튜닝 데이터로 활용합니다. 최종적으로 약 5.89만 쌍의 질문-답변 데이터가 구축되었으며, 이를 가지고 범용 LLM을 전체 파라미터 미세조정(full fine-tuning)하여 RAG 생성기의 기본기를 익히게 합니다. IFT를 거친 모델은 문서를 보고 정답을 추출 및 통합하고, 출처를 표시하는 방법을 기본적으로 학습하게 됩니다.
Direct Preference Optimization (DPO)
선호도 최적화 단계에서 응답 정보성, 응답 견고성, 인용 품질 측면에서 생성기를 순차적으로 최적화합니다.
DPO는 모델을 과적합시키지 않으면서 선호도를 학습시키고, 상이한 목표를 연속으로 최적화할 때 catastrophic forgetting(파국적 망각)을 줄이는 장점이 있습니다.
본 실험에서는 정보성, 견고성, 인용 품질 각각에 대해 선호 데이터 쌍이 구축되었으며, 이를 순차적으로 학습시킵니다. (총 3단계의 DPO 진행, 열등 답변만, IFT 모델에서 생성함)
데이터셋 구축
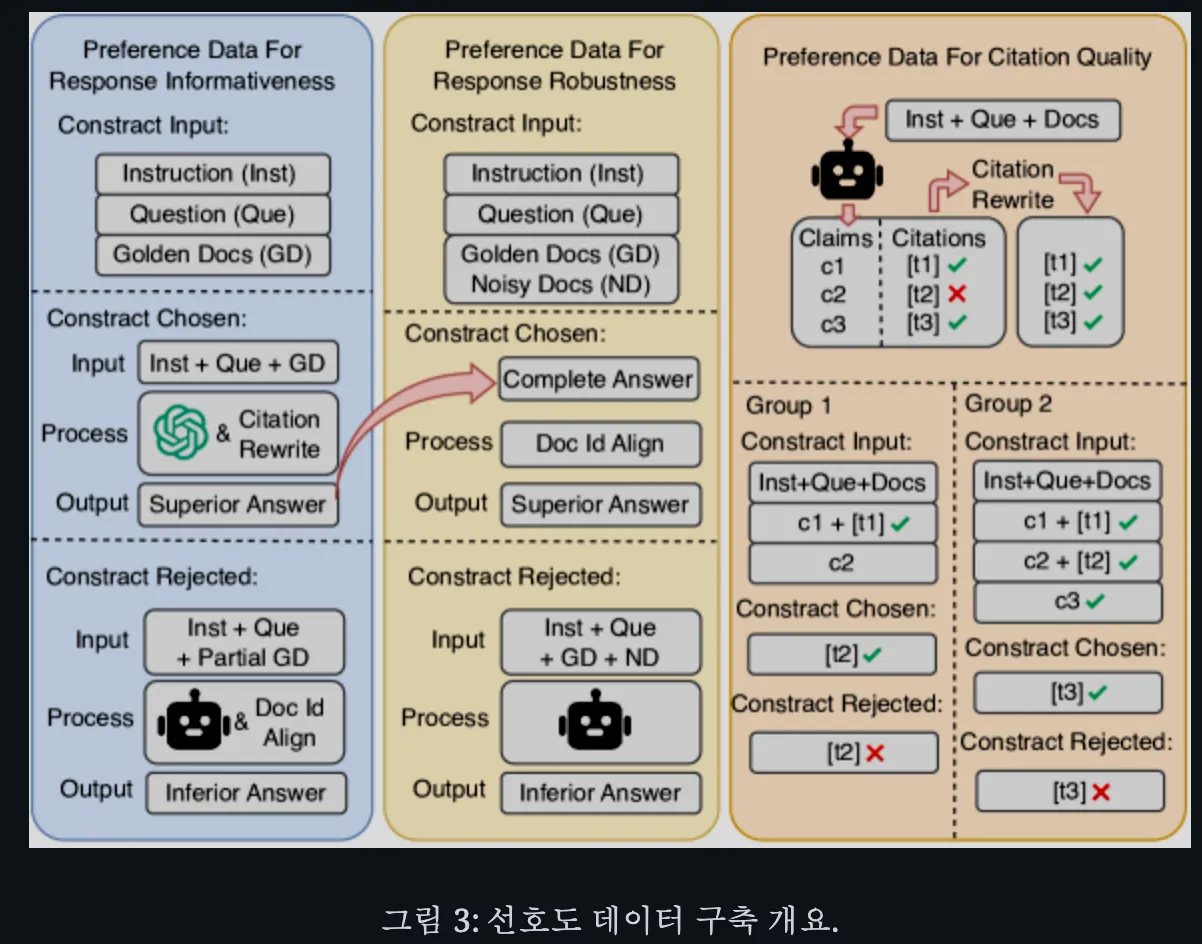
선호도 최적화는 입력, 우수한 답변(선택된 출력), 그리고 열등한 답변(거부된 출력)을 포함한 선호도 정보를 바탕으로 데이터를 구축하는 것을 요구합니다.
응답 정보성 최적화
응답 정보성은 답변의 완전성을 의미하며, 주어진 문서 내에 있는 모든 정답 정보를 빠짐없이 활용하는지를 평가합니다. 생성기가 정답을 담은 문서를 최대한 활용하여 완전한 답을 내도록 하는 것입니다.
- 데이터 구조
-
입력
질문, 지시문, 그리고 최대 5개의 골든 문서(모든 정답을 포함하는 문서들)을 포함함
-
우수답변
ChatGPT-3.5와 인용 재작성을 통해 얻은 완전한 정답 및 정확한 인용이 포함된 모범 답변을 사용함. 모든 골든 문서를 모두 활용하여 모든 정답을 포함하고 있으므로 정보성이 최고인 경우입니다. DPO 학습에서 모델은 이 답변을 선호해야 할 답변으로 학습함
-
열등답변
정보가 누락된 열등 답변을 인위적으로 생성하여 대비군으로 사용합니다.
일부 골든 문서들을 입력 프롬프트에서 제거한 후 현재 생성기 모델(IFT를 마친 상태의 모델)로 답변을 생성합니다.
-
응답 견고성 최적화
응답 견고성은 모델이 방해 요소에 저항하는 능력을 뜻합니다. 즉, 노이즈가 있는 입력에서도 정확한 답변을 유지하는지를 평가합니다. 생성기가 노이즈 문서를 무시하고 중요한 정보만으로 답변하도록 만드는 것이 목표
노이즈 문서 혼합
두 가지 유형의 노이즈를 혼합함
1. 질문과 관련은 있지만 정답을 포함하지 않은 문서(예: 해당 주제 주변부 내용)
2. 질문과 무관한 문서
1개의 질문에 대해서 각각의 유형에서 두 개씩 문서를 무작위 선택하여 총 4개의 노이즈 문서를 준비함
- 데이터 구조
- 입력: 질문, 지시문, 최대 5개의 골든 문서, 그리고 4개의 노이즈 문서를 함께 프롬프트로 제공합니다. 문서 품질이 혼재된 상황을 시뮬레이션 진행함
- 우수답변: 노이즈 상황에서의 이상적인 답변은, 노이즈 문서를 모두 무시하고 골든 문서만 활용하여 완전한 답을 하는 것입니다.
(응답 정보성 단계의 우수 답변(노이즈가 없던 상황에서 생성된 완전한 답변)을 활용)
(다만 노이즈 문서로 인해 인용 번호 등이 달라졌을 수 있으므로, 해당 우수 답변의 인용 표기를 현재 입력 구성에 맞게 재정렬합니다) - 열등답변: 준비된 혼합 입력(골든+노이즈)을 현 상태의 모델로 생성하여 열등 답변을 얻습니다. 노이즈가 섞이면 모델이 혼동을 일으켜 정답 일부를 놓치거나 불완전한 답변을 할 가능성이 높습니다. 그런 불완전한 응답을 필터링하여 선별하고, 이를 열등 사례로 사용합니다.
인용 품질 최적화
인용 품질은 모델의 정확한 출처 표기 능력을 의미합니다.
관련 문서만 인용하고 무관한 문서는 인용하지 않는 것이 목표입니다.
- 데이터 구조
-
입력: 질문, 지시문, 프롬프트 문서들, 그리고 오류가 발생한 해당 부분까지의 답변 텍스트를 입력으로 구성합니다.
오류가 발생한 해당부분까지의 답변 텍스트:
내용적으로는 완전하지만 출처 표시가 잘못된 사례들을 일부러 생성합니다.
(예: 정답은 다 담았으나 한 두 개 주장에서 잘못된 문서를 인용한 답변). 이 답변에서 잘못된 인용이 등장하는 부분까지의 내용을 입력에 포함시킵니다.
-
열등 답변:
위 입력에 이어서 잘못된 인용을 달았던 사례를 열등 출력으로 지정합니다
이 열등 답변은 NLI 검증에 실패한 출처 또는 무관한 문서를 인용한 출처를 포함하고 있습니다.
-
우수 답변:
해당 열등 답변에서 잘못된 인용 부분만 인용 재작성 기법을 통해 올바르게 수정한 답변을 우수 사례로 사용합니다. 즉, NLI 검증을 통과하고 불필요한 문서를 제거하여 모든 인용이 정확한 답변을 얻습니다. 결과적으로 모델은 동일한 맥락에서 틀린 인용 대신 올바른 인용을 달도록 선호를 학습하게 됩니다.
-
실험 환경
데이터셋
- 4가지 오픈도메인 QA 데이터셋
- ASQA
- WebQuestions
- Natural Questions
- TriviaQA(테스트 세트를 통해 out of domain 평가)
비교 모델(Base Model)
모델 크기나 종류에 상관없이 일관된 개선을 주는지 검증하기 위해 다양한 모델 사용
- Llama2-7B-Chat,
- Llama2-13B-Chat (Meta의 채팅 최적화 LLM),
- Llama3-8B-Instruct
비교 기법(Base Technique)
- RetRobust-13B
- Self-RAG-13B
- SFT on Chosen
검색코퍼스
- Wikipedia 덤프(2018년 12월 20일 판)
부가 모듈
- GTR(Ni et al., 2022, Dense retriever)를 통해 관련 문서 검색함
- NLI 모델로는 TRUE(Honovich et al., 2022)라는 T5-11B 기반 모델을 통해 인용 재작성과 평가
평가 지표
- 정확성: Exact Match
- 인용 품질: citation recall / citation precision
- 인용 재현율: 생성된 답변의 모든 주장들이 실제 인용 문서들에 의해 뒷받침되는지를 나타냄, 모델이 필요한 모든 문서를 제대로 인용했는가를 측정합니다.
- 인용 정밀도: 생성된 답변이 불필요한 문서를 인용하지 않았는지, 즉 인용한 문서들이 실제로 관련 있는지를 평가합니다.
- 모든 주장-출처 쌍을 NLI로 검증하여 올바른 인용 매칭을 판정했습니다.(ALEC, vtg 방식)
실험 결과
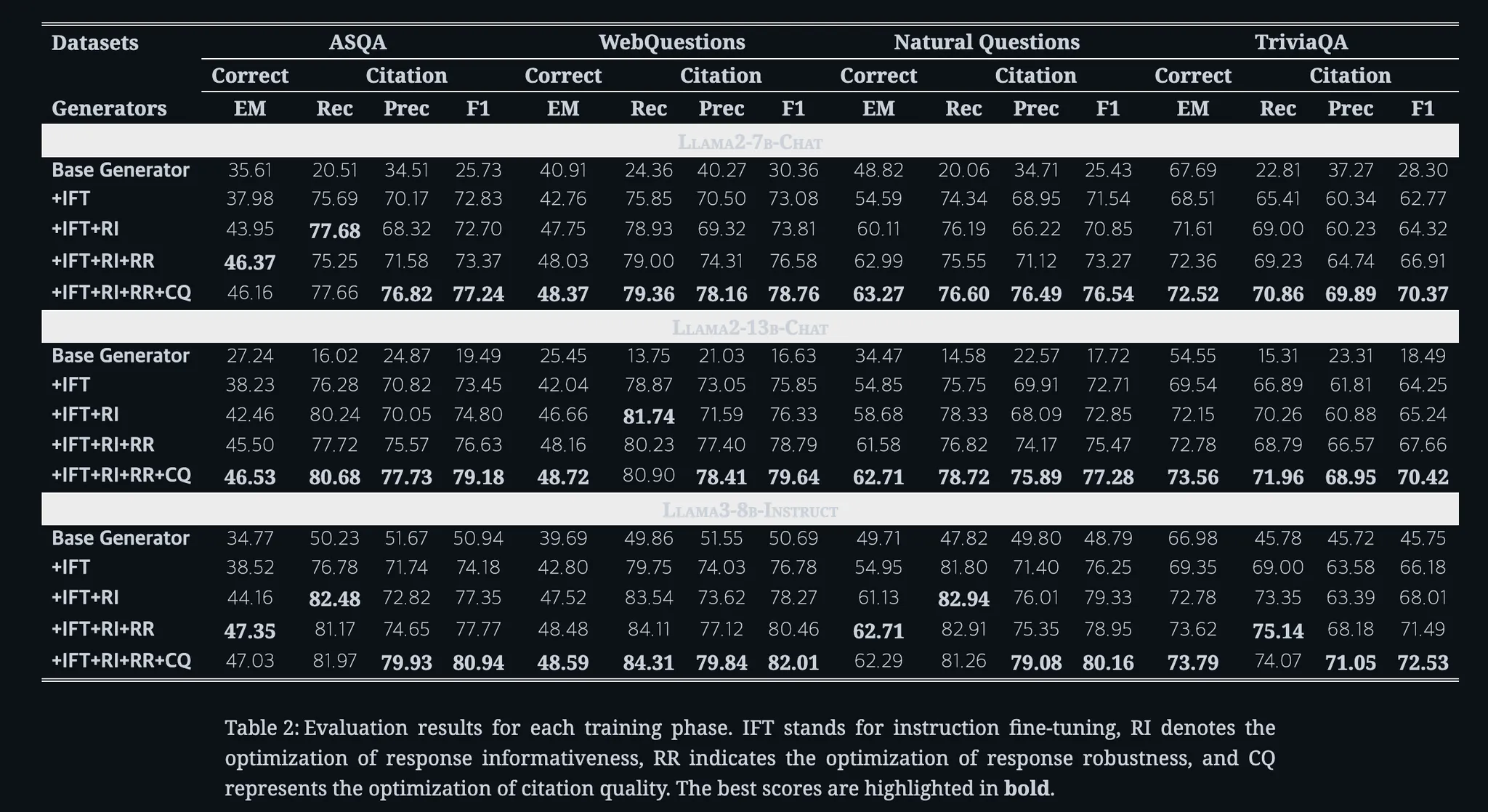
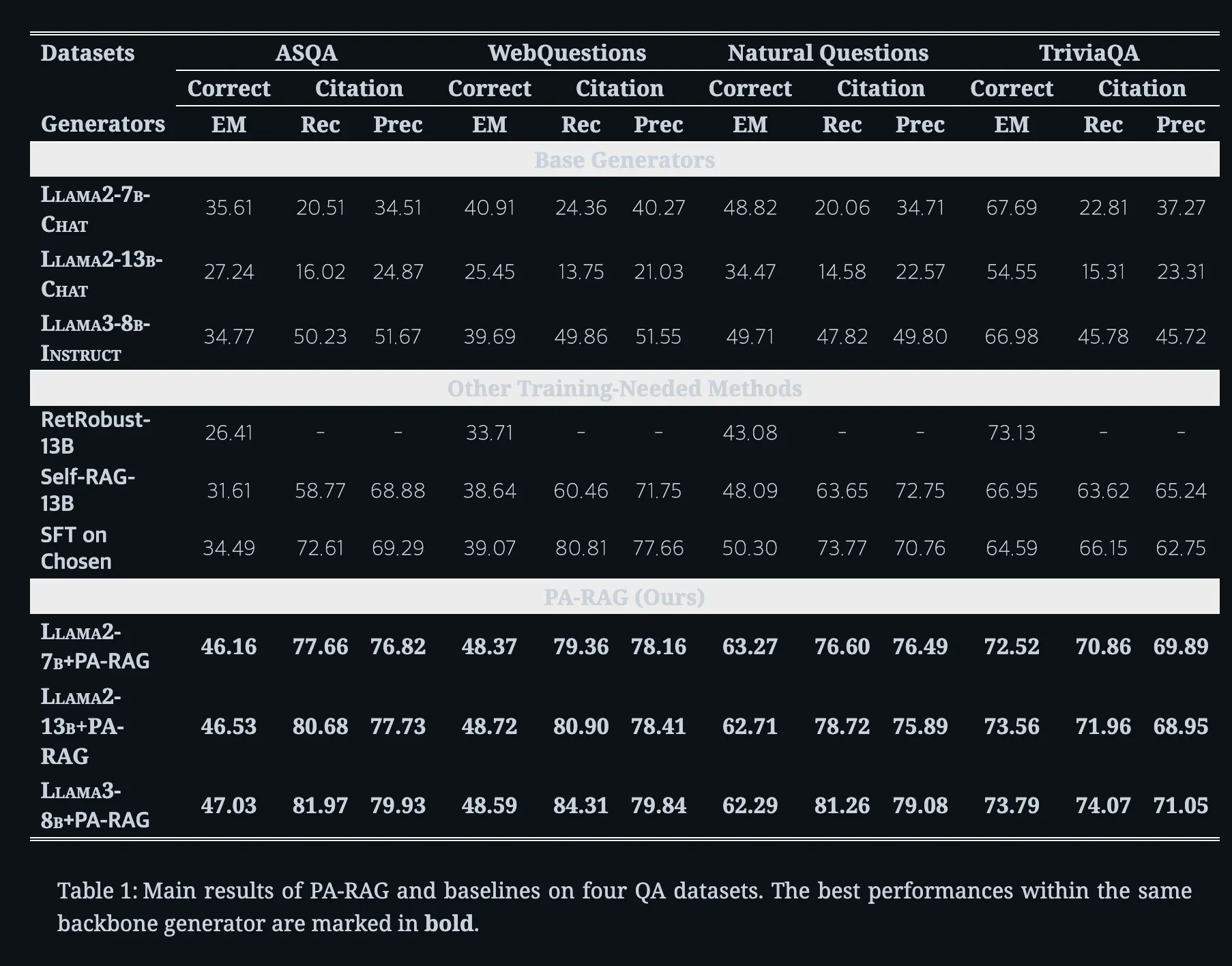
PA-RAG
정답 정확도(EM)에서 평균 +13.97%p 향상,
인용 재현율은 +49.77%p 향상
인용 정밀도는 +39.58%p 상승
(흥미롭게도 출력되는 답변의 유창성(fluency)은 기존 모델과 비교해 저하되지 않았는데, 인간 평가에서도 문장 자연스러움이 유지됨이 확인되었습니다)
한계점 및 내가 생각하는 단점
- 학습 과정의 복잡성
- 제안된 방법은 총 4단계(IFT 1회 + 선호 최적화 3회)에 걸쳐 생성기를 미세조정해야 한다.
- 각 단계마다 학습해야 할 하이퍼파라미터가 다르고 튜닝할 요소가 많아, 최적의 설정을 찾기 위한 비용이 상당해보인다.
- LLM에 대한 의존성
- 훈련 데이터를 구축하는 데 범용 LLM 모델을 사용함. 이에 따라, LLM 모델이 안전하고 강력한 모델인지의 여부가 중요해 보임.
