LightGBM
-
XGBoost보다 학습에 걸리는 시간이 훨씬 적음
-
더 작은 메모리 사용량
-
카테고리형 피처의 자동 변환과 최적 분할 (원-핫 인코딩등을 사용하지 않고도 카테고리형 피처를 최적으로 변환하고 이에 따른 노드 분할 수행)
-
GPU 지원
-
일반 GBM 계열의 트리 분할 방법과 다르게 리프 중심 트리 분할(Leaf Wise) 방식을 사용.

※ 기존의 대부분 트리 기반 알고리즘은 트리의 깊이를 효과적으로 줄이기 위한 균형 트리 분할 (Level Wise)방식을 사용하며 최대한 균형 잡힌 트리를 유지하면서 분할하기 때문에 트리의 깊이가 최소화될 수 있음.
→ 오버피팅에 보다 더 강한 구조를 가질 수 있음, 균형을 맞추기 위한 시간이 필요
※ LightGBM의 리프 중심 트리 분할 방식은 트리의 균형을 맞추지 않고, 최대 손실 값(max delta loss)을 가지는 리프 노드를 지속적으로 분할하면서 트리의 깊이가 깊어지고 비대칭적인 규칙 트리가 생성.
이렇게 최대 손실값을 가지는 리프 노드를 지속적으로 분할해 생성된 규칙 트리는 학습을 반복할수록 결국은 균형 트리 분할 방식보다 예측 오류 손실을 최소화할 수 있음
- 하이퍼 파라미터

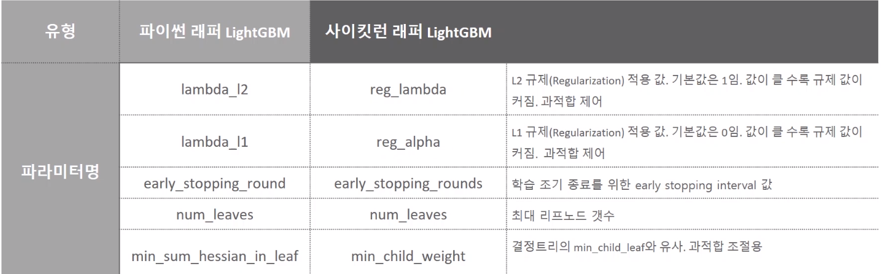
num_leaves의 개수를 중심으로 min_child_samples(min_data_in_leaf), max_depth를 함께 조정하면서 모델의 복잡도를 줄이는 것이 기본 튜닝 방안

from lightgbm import LGBMClassifier
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=11)
model = LGBMClassifier(n_estimators=400)
evals = [(X_test, y_test)]
# 원래 evals 데이터는 검증 데이터 셋을 별도로 둬야되는데 여기서는 테스트 데이터 사용
model.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="logloss",
eval_set=evals, verbose=True)
# 예측
preds = model.predict(X_test)
pred_proba = model.predict_proba(X_test)[:, 1]- 평가
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.metrics import precision_score, recall_score
from sklearn.metrics import f1_score, roc_auc_score
def get_clf_eval(y_test, pred=None, pred_proba=None):
confusion = confusion_matrix( y_test, pred)
accuracy = accuracy_score(y_test , pred)
precision = precision_score(y_test , pred)
recall = recall_score(y_test , pred)
f1 = f1_score(y_test,pred)
roc_auc = roc_auc_score(y_test, pred_proba)
print('오차 행렬')
print(confusion)
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f},\
F1: {3:.4f}, AUC:{4:.4f}'.format(accuracy, precision, recall, f1, roc_auc), '\n')
get_clf_eval(y_test, preds, pred_proba)