핵심 주제
- 11.1. Queries, Keys, and Values
- 11.2. Attention Pooling by Similarity
- 11.3. Attention Scoring Functions
- 11.4. The Bahdanau Attention Mechanism
- 11.5. Multi-Head Attention
- 11.6. Self-Attention and Positional Encoding
- 11.7. The Transformer Architecture
학습 내용 정리
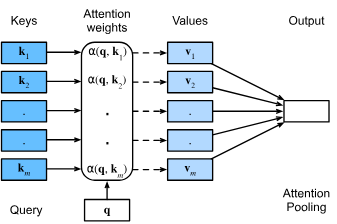
11.1. Queries, Keys, and Values
- Attention 메커니즘의 기본 구성 요소인 Query, Key, Value를 소개합니다. 전통적인 신경망이 가변 크기의 입력을 처리하는 데 어려움을 겪는 문제가 있고, attention 메커니즘이 데이터의이 문제를 어떻게 해결하는지 설명합니다.
데이터베이스
- 데이터베이스는 키와 밸류로 구성되며, 쿼리를 사용하여 정보를 검색합니다. 쿼리가 키-밸류 쌍과 상호 작용하여 데이터베이스 크기에 관계없이 관련 정보를 추출할 수 있습니다.
- 딥러닝에서의 attention 메커니즘은 데이터베이스 작업을 수행하는 것과 유사합니다. 여기서 attention 메커니즘은 쿼리와 키에 기반하여 데이터의 특정 값(Value)에 선택적으로 집중합니다.
Attention 메커니즘
- 밸류의 가중합으로 정의되며, 각 밸류에 할당된 가중치는 데이터베이스 내 해당 키 와 쿼리 의 호환성 함수에 의해 계산됩니다.
- 은 스칼라 어텐션 가중치
- 특별한 경우
- 가중치 이 모두 음수가 아닐 경우
-
지수화를 통해 만들 수 있다. 이를 정규화하면 다음과 같다.
-
- 가중치 이 convex combination일 경우 : and 일반적인 딥러닝 세팅
-
다음과 같이 정규화를 통해 만들 수 있다.
-
- 가중치 이 하나만 1이고 전부 0일 경우 : 전통적인 데이터베이스 쿼리와 유사
- 모든 가중치가 동일 (즉, ) : 전체 데이터베이스에 대한 평균화에 해당하며 딥 러닝에서는 average pooling이라 한다.
- 가중치 이 모두 음수가 아닐 경우
- 밸류의 가중합으로 정의되며, 각 밸류에 할당된 가중치는 데이터베이스 내 해당 키 와 쿼리 의 호환성 함수에 의해 계산됩니다.
# PyTorch와 d2l 툴킷을 임포트합니다.
import torch
from d2l import torch as d2l
#@save
# 주목 가중치 행렬을 시각화하는 함수를 정의합니다.
def show_heatmaps(matrices, xlabel, ylabel, titles=None, figsize=(2.5, 2.5),
cmap='Reds'):
"""Show heatmaps of matrices."""
# SVG 형식으로 그래프를 표시하도록 설정합니다.
d2l.use_svg_display()
# 행렬의 크기를 구합니다.
num_rows, num_cols, _, _ = matrices.shape
# 서브플롯을 생성합니다.
fig, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize,
sharex=True, sharey=True, squeeze=False)
# 각 행렬에 대해 반복하며 히트맵을 그립니다.
for i, (row_axes, row_matrices) in enumerate(zip(axes, matrices)):
for j, (ax, matrix) in enumerate(zip(row_axes, row_matrices)):
# 행렬을 히트맵으로 시각화합니다.
pcm = ax.imshow(matrix.detach().numpy(), cmap=cmap)
# x축 라벨을 설정합니다.
if i == num_rows - 1:
ax.set_xlabel(xlabel)
# y축 라벨을 설정합니다.
if j == 0:
ax.set_ylabel(ylabel)
# 제목이 있으면 설정합니다.
if titles:
ax.set_title(titles[j])
# 컬러바를 추가합니다.
fig.colorbar(pcm, ax=axes, shrink=0.6);
# 10x10 단위 행렬을 생성하여 주목 가중치로 사용합니다.
attention_weights = torch.eye(10).reshape((1, 1, 10, 10))
# 주목 가중치 히트맵을 시각화합니다.
show_heatmaps(attention_weights, xlabel='Keys', ylabel='Queries')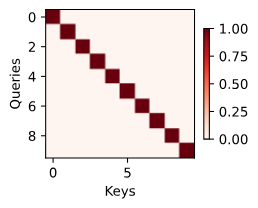
11.2. Attention Pooling by Similarity
커널 종류
regression
커널과 데이터
# 필요한 라이브러리를 임포트합니다.
import numpy as np
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
# SVG 형식으로 그래프를 표시하도록 설정합니다.
d2l.use_svg_display()
# 다양한 커널 함수를 정의합니다.
def gaussian(x):
return torch.exp(-x**2 / 2)
def boxcar(x):
return torch.abs(x) < 1.0
def constant(x):
return 1.0 + 0 * x
def epanechikov(x):
return torch.max(1 - torch.abs(x), torch.zeros_like(x))
# 커널 함수를 시각화합니다.
fig, axes = d2l.plt.subplots(1, 4, sharey=True, figsize=(12, 3))
kernels = (gaussian, boxcar, constant, epanechikov)
names = ('Gaussian', 'Boxcar', 'Constant', 'Epanechikov')
x = torch.arange(-2.5, 2.5, 0.1)
for kernel, name, ax in zip(kernels, names, axes):
ax.plot(x.detach().numpy(), kernel(x).detach().numpy())
ax.set_xlabel(name)
d2l.plt.show()
# 간단한 함수를 정의합니다.
def f(x):
return 2 * torch.sin(x) + x
# 학습 데이터를 생성합니다.
n = 40
x_train, _ = torch.sort(torch.rand(n) * 5)
y_train = f(x_train) + torch.randn(n)
x_val = torch.arange(0, 5, 0.1)
y_val = f(x_val)-
Nadaraya–Watson Regression을 통한 Attention Pooling
-
Nadaraya–Watson estimation을 보기 위해 다음과 같이 training data를 정의
def f(x): return 2 * torch.sin(x) + x n = 40 x_train, _ = torch.sort(torch.rand(n) * 5) y_train = f(x_train) + torch.randn(n) x_val = torch.arange(0, 5, 0.1) y_val = f(x_val) -
각 validation feature를 쿼리로 만들고 각 training feature-레이블 쌍을 키-value 쌍으로 만듭니다. 결과적으로 정규화된 상대 커널 가중치(
attention_w)는 attention 가중치 입니다.# 나다라야-왓슨 커널 회귀 함수를 정의합니다. def nadaraya_watson(x_train, y_train, x_val, kernel): # 훈련 데이터와 검증 데이터 간의 거리를 계산합니다. dists = x_train.reshape((-1, 1)) - x_val.reshape((1, -1)) # 각 쿼리/키에 해당하는 각 열/행 k = kernel(dists).type(torch.float32) # 각 쿼리에 대한 키들의 정규화 attention_w = k / k.sum(0) # 예측값을 계산합니다. y_hat = y_train@attention_w return y_hat, attention_w # 나다라야-왓슨 회귀 결과와 주목 가중치를 시각화하는 함수를 정의합니다. def plot(x_train, y_train, x_val, y_val, kernels, names, attention=False): fig, axes = d2l.plt.subplots(1, 4, sharey=True, figsize=(12, 3)) for kernel, name, ax in zip(kernels, names, axes): # 나다라야-왓슨 회귀를 수행합니다. y_hat, attention_w = nadaraya_watson(x_train, y_train, x_val, kernel) if attention: # 주목 가중치를 히트맵으로 시각화합니다. pcm = ax.imshow(attention_w.detach().numpy(), cmap='Reds') else: # 예측 결과와 실제 값을 플롯합니다. ax.plot(x_val, y_hat) ax.plot(x_val, y_val, 'm--') ax.plot(x_train, y_train, 'o', alpha=0.5); ax.set_xlabel(name) if not attention: ax.legend(['y_hat', 'y']) if attention: # 컬러바를 추가합니다. fig.colorbar(pcm, ax=axes, shrink=0.7) # 나다라야-왓슨 회귀 결과와 주목 가중치를 시각화합니다. plot(x_train, y_train, x_val, y_val, kernels, names)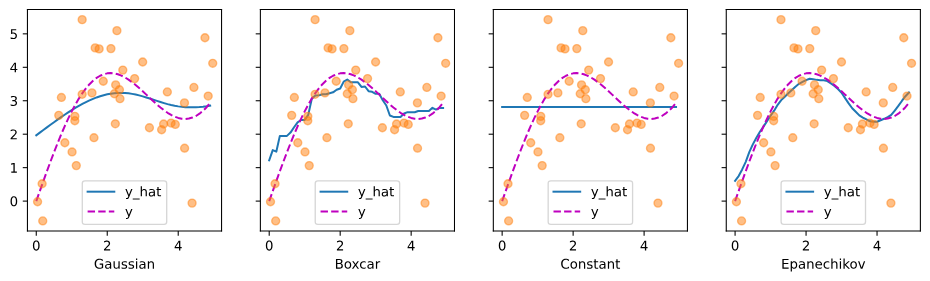
plot(x_train, y_train, x_val, y_val, kernels, names, attention=True)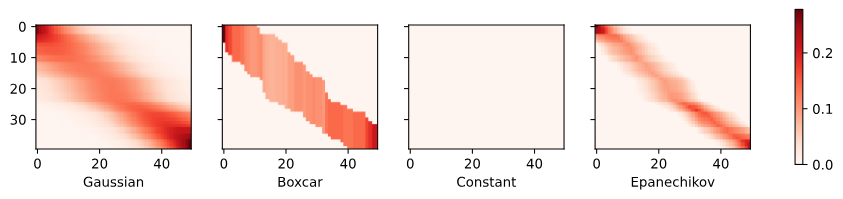
-
Gaussian, Boxcar, Epanechikov의 attention weights이 비슷한 것을 확인할 수 있다.
-
-
Adapting Attention Pooling
-
Gaussian kernel에서 width를 다르게 했을 때, 즉 를 다르게 했을 때 결과는 아래와 같다.
# 다양한 폭(sigma) 값을 정의합니다. sigmas = (0.1, 0.2, 0.5, 1) # 각 sigma에 대한 이름을 생성합니다. names = ['Sigma ' + str(sigma) for sigma in sigmas] # 주어진 폭(sigma)을 가진 가우시안 커널 함수를 생성하는 함수를 정의합니다. def gaussian_with_width(sigma): return (lambda x: torch.exp(-x**2 / (2*sigma**2))) # 다양한 폭을 가진 가우시안 커널 함수들의 리스트를 생성합니다. kernels = [gaussian_with_width(sigma) for sigma in sigmas] # 나다라야-왓슨 회귀 결과와 주목 가중치를 시각화합니다. plot(x_train, y_train, x_val, y_val, kernels, names)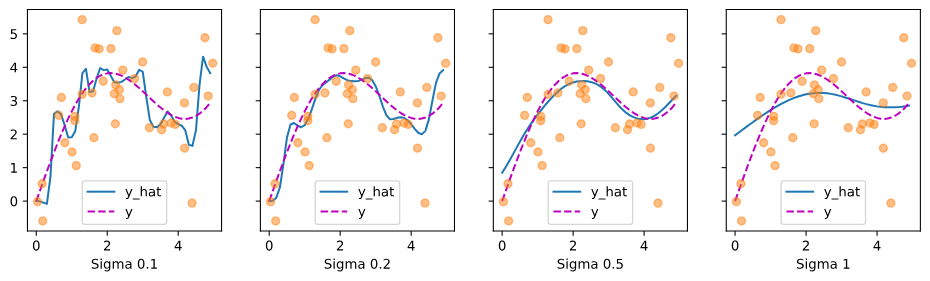
-
커널이 좁아질수록(width가 작을수록), 추정이 덜 smooth 해진다.
plot(x_train, y_train, x_val, y_val, kernels, names, attention=True)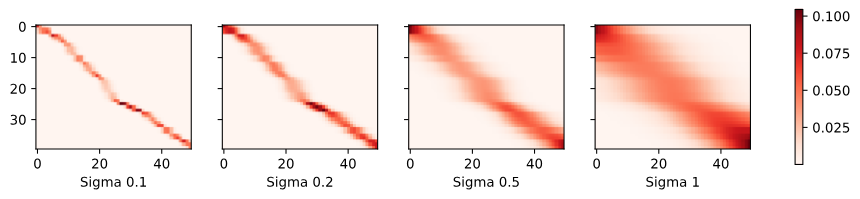
-
커널이 좁아질수록(width가 작을수록), 높은 값을 가진 attention weights의 범위(heatmap의 빨간 부분)가 좁아진다.
- 커널의 폭(sigma)이 좁다는 것은 커널 함수가 빠르게 감소하여 0에 가까워진다는 것을 의미합니다. 즉, 쿼리 지점에서 멀리 떨어진 키(데이터 포인트)에는 매우 낮은 가중치가 할당됩니다. 결과적으로 좁은 커널은 쿼리 지점에 가까운 소수의 키에만 높은 attention 가중치를 할당하고, 나머지 키에는 거의 할당하지 않게 됩니다. 이는 모델이 쿼리 지점에 가까운 데이터에 더 집중하게 만듭니다.
- 동일한 폭을 선택하는 것이 이상적이지 않을 수 있다는 것을 보여줍니다.
- 커널의 폭(sigma)이 좁다는 것은 커널 함수가 빠르게 감소하여 0에 가까워진다는 것을 의미합니다. 즉, 쿼리 지점에서 멀리 떨어진 키(데이터 포인트)에는 매우 낮은 가중치가 할당됩니다. 결과적으로 좁은 커널은 쿼리 지점에 가까운 소수의 키에만 높은 attention 가중치를 할당하고, 나머지 키에는 거의 할당하지 않게 됩니다. 이는 모델이 쿼리 지점에 가까운 데이터에 더 집중하게 만듭니다.
-
-
결론
- Nadaraya–Watson Regression은 Attention Weights를 시각화하기에 매우 적합합니다. 이를 통해 모델이 데이터의 어떤 부분에 높은 attention 가중치를 할당하는지 직관적으로 이해할 수 있으며, Attention Mechanism을 시각적으로 보여줄 수 있습니다.
- 이 방법은 Hand-Crafted Attention Mechanism의 한계를 보여줍니다. 즉, 사전에 정의된 규칙이나 함수를 사용하여 Attention을 결정하는 방식은 데이터의 복잡성과 다양성을 완전히 포착하거나, 특정 작업에 최적화되기 어려운 것을 확인할 수 있습니다.
11.3. Attention Scoring Functions
Dot Product Attention
-
Gaussian kernel의 attention 함수는 다음과 같다.
-
만약 우리가 쿼리와 키 벡터의 크기가 일정하다고 가정한다면 과 은 모두 상수가 됩니다. 이 상수들은 softmax 함수를 적용할 때 스케일링과 정규화 과정에서 상쇄되고, 결국 attention weight에 영향을 미치지 않습니다. 따라서, 이 상수 항들을 무시하고 attention scoring 함수를 단순화할 수 있습니다.
-
만약 우리가 추가적으로 점곱 결과를 벡터의 차원 의 제곱근으로 나누어 스케일링한다면, 우리는 스케일된 Dot Product Attention scoring 함수를 얻게 됩니다.
-
이 과정들을 마치고 난 Dot Product Attention scoring 함수
-
attention weights 은 여전히 정규화가 필요하다. softmax를 통해 진행하면 다음과 같습니다.
-
Scaled Dot Product Attention
Additive Attention
- 쿼리와 키가 다른 차원을 가진다면 Additive Attention(Bahdanau Attention)을 사용할 수 있습니다. 식은 다음과 같습니다.
11.4. The Bahdanau Attention Mechanism
-
Bahdanau Attention 매커니즘을 사용하는 이유
- 기존 RNN 인코더-디코더 구조는 긴 시퀀스를 처리할 때 정보를 압축하는 데 한계가 있습니다. 모든 관련 정보를 고정된 크기의 상태 변수로 압축하려고 하면, 긴 문장이나 복잡한 문장을 번역할 때 정보 손실이 발생할 수 있습니다.
-
모델 구조
-
고정된 컨텍스트 변수 대신, 각 디코딩 시간 단계마다 동적으로 업데이트되는 컨텍스트 변수를 사용합니다. 이는 인코더의 모든 은닉 상태와 디코더의 이전 시간 단계의 은닉 상태를 고려하여 계산됩니다.
-
변수 정의
- cₜ': 시간 단계 t'에서의 컨텍스트 벡터. 이는 디코더의 현재 상태에 대한 입력 시퀀스의 가중합 표현입니다.
- sₜ'-1: 시간 단계 t'-1에서의 디코더의 은닉 상태(쿼리).
- hₜ: 시간 단계 t에서의 인코더의 은닉 상태(키 및 값).
- α(sₜ'-1, hₜ): 디코더의 이전 상태 sₜ'-1와 인코더의 각 상태 hₜ 사이의 주목 가중치. 이는 쿼리와 각 키 사이의 유사성을 나타내며, 주목 메커니즘에 의해 계산됩니다.
- T: 입력 시퀀스의 총 길이.
-
attention weight 계산
- α(sₜ'-1, hₜ): attention score 함수(예: 가산 주목)를 사용하여 계산됩니다. 이 함수는 디코더의 이전 상태와 각 인코더 상태 사이의 유사성을 평가하여, 현재 디코더 상태에 가장 관련이 높은 입력 시퀀스 부분에 높은 가중치를 할당합니다.
-
컨텍스트 벡터 생성
-
계산된 주목 가중치를 각 인코더 상태 hₜ에 적용하고, 이들의 가중합을 계산하여 컨텍스트 벡터 cₜ'를 생성합니다. 이 컨텍스트 벡터는 입력 시퀀스의 다양한 부분에 대한 정보를 집계한 것으로, 디코더가 다음 토큰을 생성할 때 참조합니다.
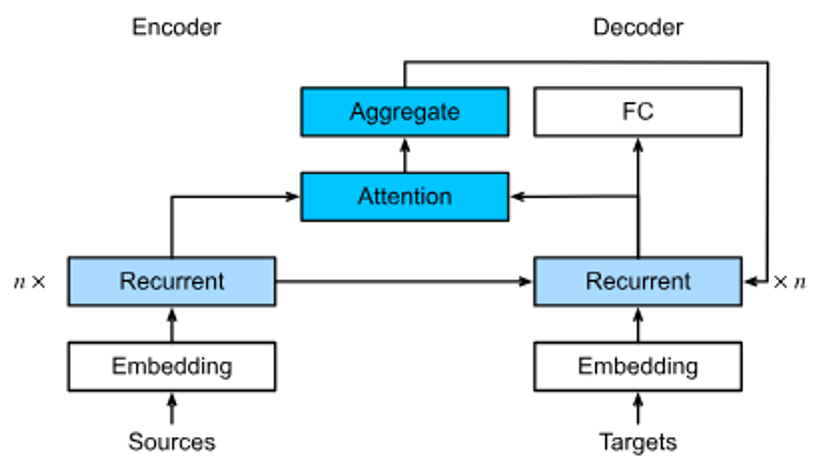
Bahdanau Attention 메커니즘을 갖춘 RNN 인코더-디코더 모델의 레이어
-
-
-
코드 구현
import torch
from torch import nn
from d2l import torch as d2l
# 주목 기반 디코더의 기본 인터페이스 정의
class AttentionDecoder(d2l.Decoder): #@save
"""The base attention-based decoder interface."""
def __init__(self):
super().__init__()
@property
def attention_weights(self):
raise NotImplementedError
# 바다나우 주목 메커니즘을 사용하는 디코더 구현
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0):
super().__init__()
# 가산 주목 메커니즘 초기화
self.attention = d2l.AdditiveAttention(num_hiddens, dropout)
# 임베딩 레이어 초기화
self.embedding = nn.Embedding(vocab_size, embed_size)
# GRU 레이어 초기화
self.rnn = nn.GRU(
embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
# 출력을 어휘 크기의 벡터로 변환하는 완전 연결 레이어 초기화
self.dense = nn.LazyLinear(vocab_size)
# 모델 파라미터 초기화
self.apply(d2l.init_seq2seq)
# 인코더의 출력과 유효 길이를 사용하여 디코더의 초기 상태를 초기화하는 메서드
def init_state(self, enc_outputs, enc_valid_lens):
outputs, hidden_state = enc_outputs
return (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)
# 디코더의 순전파를 수행하는 메서드
def forward(self, X, state):
enc_outputs, hidden_state, enc_valid_lens = state
X = self.embedding(X).permute(1, 0, 2)
outputs, self._attention_weights = [], []
for x in X:
query = torch.unsqueeze(hidden_state[-1], dim=1)
context = self.attention(
query, enc_outputs, enc_outputs, enc_valid_lens)
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,
enc_valid_lens]
# 주목 가중치를 반환하는 프로퍼티
@property
def attention_weights(self):
return self._attention_weights
# 모델 파라미터 설정
vocab_size, embed_size, num_hiddens, num_layers = 10, 8, 16, 2
batch_size, num_steps = 4, 7
# 인코더 초기화
encoder = d2l.Seq2SeqEncoder(vocab_size, embed_size, num_hiddens, num_layers)
# 디코더 초기화
decoder = Seq2SeqAttentionDecoder(vocab_size, embed_size, num_hiddens,
num_layers)
# 입력 데이터 준비
X = torch.zeros((batch_size, num_steps), dtype=torch.long)
# 디코더의 초기 상태 설정
state = decoder.init_state(encoder(X), None)
# 디코더 순전파 수행
output, state = decoder(X, state)
# 출력과 상태의 차원 확인
d2l.check_shape(output, (batch_size, num_steps, vocab_size))
d2l.check_shape(state[0], (batch_size, num_steps, num_hiddens))
d2l.check_shape(state[1][0], (batch_size, num_hiddens))
# 데이터 로딩 및 모델 설정
data = d2l.MTFraEng(batch_size=128)
embed_size, num_hiddens, num_layers, dropout = 256, 256, 2, 0.2
encoder = d2l.Seq2SeqEncoder(
len(data.src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(
len(data.tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
model = d2l.Seq2Seq(encoder, decoder, tgt_pad=data.tgt_vocab['<pad>'],
lr=0.005)
# 트레이너 설정 및 모델 훈련
trainer = d2l.Trainer(max_epochs=30, gradient_clip_val=1, num_gpus=1)
trainer.fit(model, data)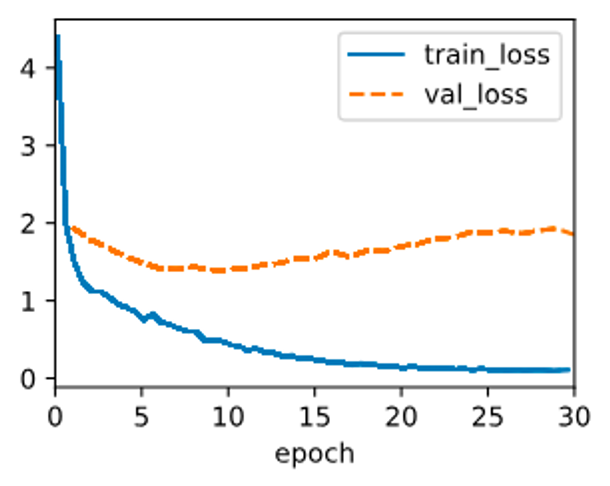
# 영어 문장을 프랑스어로 번역하고 BLEU 점수로 평가
engs = ['go .', 'i lost .', 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
preds, _ = model.predict_step(
data.build(engs, fras), d2l.try_gpu(), data.num_steps)
for en, fr, p in zip(engs, fras, preds):
translation = []
for token in data.tgt_vocab.to_tokens(p):
if token == '<eos>':
break
translation.append(token)
print(f'{en} => {translation}, bleu,'
f'{d2l.bleu(" ".join(translation), fr, k=2):.3f}')
# 디코더의 주목 가중치 시각화
_, dec_attention_weights = model.predict_step(
data.build([engs[-1]], [fras[-1]]), d2l.try_gpu(), data.num_steps, True)
attention_weights = torch.cat(
[step[0][0][0] for step in dec_attention_weights], 0)
attention_weights = attention_weights.reshape((1, 1, -1, data.num_steps))
# 주목 가중치 히트맵 시각화
# 입력 문장의 각 단어에 대한 디코더의 주목을 보여줍니다
d2l.show_heatmaps(
attention_weights[:, :, :, :len(engs[-1].split()) + 1].cpu(),
xlabel='Key positions', ylabel='Query positions')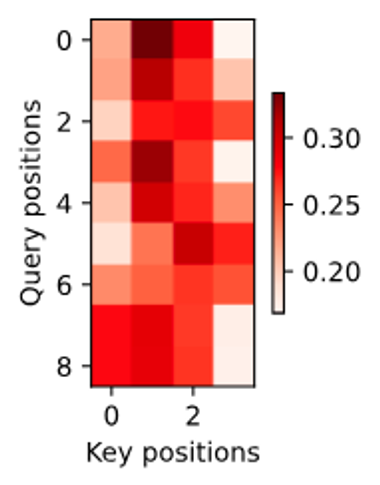
11.5. Multi-Head Attention
-
Multi-Head Attention을 사용하는 이유
-
상상해보세요, 당신이 한 책을 여러 전문가에게 읽게 하여 각자의 해석을 듣는다고 합니다. 한 전문가는 이야기의 감정적인 측면에 집중할 수 있고, 다른 전문가는 플롯의 복잡성에 주목할 수 있습니다. 결국, 이러한 다양한 해석을 결합하면 책에 대한 더 풍부하고 다면적인 이해를 얻을 수 있습니다.
-
Multi-Head Attention도 비슷한 방식으로 작동합니다. 모델이 주어진 쿼리(질문), 키(정보), 값(답변) 세트를 사용할 때, 단일 주목 메커니즘 대신 여러 '헤드'를 사용합니다. 각 헤드는 독립적으로 학습된 변환을 통해 쿼리, 키, 값의 다른 '부공간'을 탐색하고, 이를 통해 데이터의 다양한 측면을 포착합니다. 예를 들어, 어떤 헤드는 문장 내의 가까운 단어들 사이의 관계에 주목할 수 있고(짧은 범위 의존성), 다른 헤드는 더 멀리 떨어진 단어들 사이의 관계에 주목할 수 있습니다(긴 범위 의존성).
-
이렇게 독립적으로 작동하는 여러 헤드의 결과는 병렬로 계산되어 각각의 주목 결과를 제공합니다. 그런 다음 이러한 결과들은 연결되어 하나의 통합된 출력을 생성하기 위해 추가적인 변환을 거칩니다. 이렇게 함으로써, 모델은 입력 데이터의 다양한 부분에 대해 더욱 정교하게 주목할 수 있으며, 이는 전체적인 이해력과 성능을 향상시킵니다.
-
간단히 말해, Multi-Head Attention은 모델이 데이터를 여러 다른 관점에서 동시에 이해하고 처리할 수 있게 함으로써, 더 풍부하고 다층적인 데이터 표현을 학습하고, 더 나은 예측과 해석을 제공합니다.
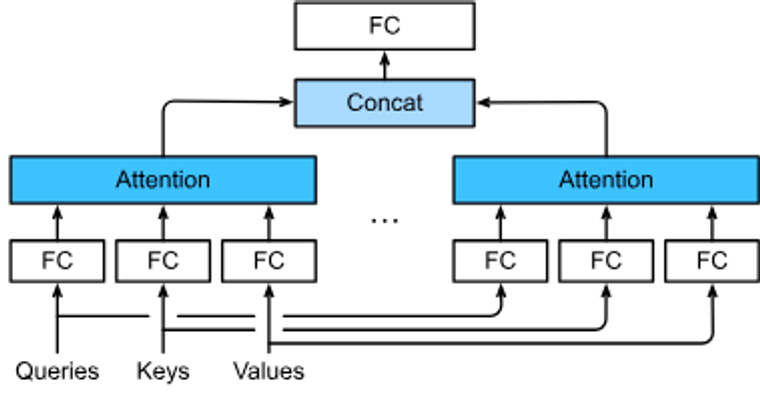
Multi-head attention, multiple heads가 연결된 후 선형 변환됩니다.
-
-
모델
- 각각의 attention head 는 다음과 같이 계산됩니다.
- 각 헤드의 출력 벡터 들을 위아래로 연결(concatenate)하여 하나의 큰 벡터를 만듭니다. 이렇게 연결된 벡터는 모든 헤드의 정보를 포함하고 있습니다.
- 연결된 헤드 출력 벡터에 가중치 행렬를 곱하여 최종 출력 벡터를 생성합니다. 이 최종 출력 벡터는 Multi-Head Attention의 결과로 사용됩니다.
- 각각의 attention head 는 다음과 같이 계산됩니다.
구현(코드)
-
Multi-head attention의 multiple heads 의 계산 비용을 줄이기 위해 와 같이 설정합니다.
- 쿼리, 키, 값에 대한 선형 변환의 출력 수를 와 같이 설정하면 헤드를 병렬로 계산할 수 있습니다.
- 코드에서 은num_hiddens를 통해 지정됩니다.import math import torch from torch import nn from d2l import torch as d2l # Multi-Head Attention 클래스 정의 class MultiHeadAttention(d2l.Module): #@save """Multi-head attention.""" def __init__(self, num_hiddens, num_heads, dropout, bias=False, **kwargs): super().__init__() self.num_heads = num_heads # 헤드의 수 설정 # 스케일된 점곱 주목 메커니즘 초기화 self.attention = d2l.DotProductAttention(dropout) # 쿼리, 키, 값에 대한 선형 변환을 위한 가중치 행렬 초기화 self.W_q = nn.LazyLinear(num_hiddens, bias=bias) self.W_k = nn.LazyLinear(num_hiddens, bias=bias) self.W_v = nn.LazyLinear(num_hiddens, bias=bias) # 최종 출력을 위한 선형 변환 가중치 행렬 초기화 self.W_o = nn.LazyLinear(num_hiddens, bias=bias) # Multi-Head Attention의 순전파 정의 def forward(self, queries, keys, values, valid_lens): # 쿼리, 키, 값에 대한 선형 변환 수행 queries = self.transpose_qkv(self.W_q(queries)) keys = self.transpose_qkv(self.W_k(keys)) values = self.transpose_qkv(self.W_v(values)) # 유효 길이 처리 if valid_lens is not None: valid_lens = torch.repeat_interleave( valid_lens, repeats=self.num_heads, dim=0) # 스케일된 점곱 주목 수행 output = self.attention(queries, keys, values, valid_lens) # 병렬로 계산된 헤드의 출력을 연결 output_concat = self.transpose_output(output) # 최종 출력 생성 return self.W_o(output_concat) # 병렬 계산을 위한 쿼리, 키, 값의 변환 함수 @d2l.add_to_class(MultiHeadAttention) #@save def transpose_qkv(self, X): """Transposition for parallel computation of multiple attention heads.""" # 입력 X의 차원을 재조정하고 순서를 변경하여 병렬 계산을 위한 형태로 변환 X = X.reshape(X.shape[0], X.shape[1], self.num_heads, -1) X = X.permute(0, 2, 1, 3) return X.reshape(-1, X.shape[2], X.shape[3]) # 병렬로 계산된 출력의 형태를 원래대로 되돌리는 함수 @d2l.add_to_class(MultiHeadAttention) #@save def transpose_output(self, X): """Reverse the operation of transpose_qkv.""" # 병렬로 계산된 출력의 차원을 재조정하고 순서를 변경하여 원래 형태로 변환 X = X.reshape(-1, self.num_heads, X.shape[1], X.shape[2]) X = X.permute(0, 2, 1, 3) return X.reshape(X.shape[0], X.shape[1], -1) # 모델 파라미터 설정 및 인스턴스 생성 num_hiddens, num_heads = 100, 5 attention = MultiHeadAttention(num_hiddens, num_heads, 0.5) # 입력 데이터 및 유효 길이 설정 batch_size, num_queries, num_kvpairs = 2, 4, 6 valid_lens = torch.tensor([3, 2]) X = torch.ones((batch_size, num_queries, num_hiddens)) Y = torch.ones((batch_size, num_kvpairs, num_hiddens)) # Multi-Head Attention의 출력 차원 확인 d2l.check_shape(attention(X, Y, Y, valid_lens), (batch_size, num_queries, num_hiddens))
-
11.6. Self-Attention and Positional Encoding
-
Self-Attention을 사용하는 이유
- 일반적으로 시퀀스 데이터를 처리할 때 CNN(합성곱 신경망)이나 RNN(순환 신경망)을 사용합니다. 하지만 자기 주목 메커니즘을 사용하면, 각 토큰이 자신만의 쿼리(Query), 키(Key), 값(Value)을 가지고 다른 모든 토큰과 상호작용할 수 있습니다.
- 상상해보세요, 당신이 문장을 읽고 있고, 각 단어가 다른 모든 단어에 '주목'할 수 있다고 합니다. 각 단어(토큰)는 자신의 쿼리 벡터를 사용하여 다른 모든 단어의 키 벡터와 매칭되어 attention score를 계산합니다. 이 점수를 사용하여, 각 단어는 문장 내 다른 모든 단어의 정보를 가중합하여 자신의 새로운 표현을 계산합니다.
- 이렇게 모든 단어가 서로에게 주목하는 구조를 'self-attention' 또는 'intra-attention'이라고 합니다. 이 방식은 각 단어가 문장 전체의 맥락을 이해하고, 그 맥락에 기반한 풍부한 표현을 생성할 수 있게 해줍니다.
-
Self-Attention
- self-attention은 동일한 길이의 시퀀스를 출력합니다.
# 필요한 라이브러리와 모듈을 임포트합니다. import torch from d2l import torch as d2l # Multi-Head Attention의 파라미터를 설정합니다. num_hiddens, num_heads = 100, 5 # num_hiddens: 은닉 상태의 크기, num_heads: 헤드의 수 # Multi-Head Attention 인스턴스를 생성합니다. # num_hiddens: 각 헤드의 차원, num_heads: 헤드의 수, 0.5: 드롭아웃 비율 attention = d2l.MultiHeadAttention(num_hiddens, num_heads, 0.5) # 입력 데이터의 크기를 설정합니다. batch_size, num_queries = 2, 4 # batch_size: 배치 크기, num_queries: 쿼리의 수 valid_lens = torch.tensor([3, 2]) # 각 시퀀스의 유효한 길이 # 입력 데이터 X를 생성합니다. 여기서는 모든 값을 1로 설정했습니다. # (batch_size, num_queries, num_hiddens) 크기의 텐서를 생성합니다. X = torch.ones((batch_size, num_queries, num_hiddens)) # Multi-Head Attention을 수행합니다. # X를 쿼리, 키, 값으로 사용하고, valid_lens로 유효한 길이 정보를 제공합니다. # attention(X, X, X, valid_lens)는 Multi-Head Attention의 출력을 반환합니다. output = attention(X, X, X, valid_lens) # 출력의 형태를 확인합니다. # 출력은 (batch_size, num_queries, num_hiddens)의 형태를 가져야 합니다. d2l.check_shape(output, (batch_size, num_queries, num_hiddens)) - self-attention은 동일한 길이의 시퀀스를 출력합니다.
-
CNN, RNN 및 Self-Attention 비교
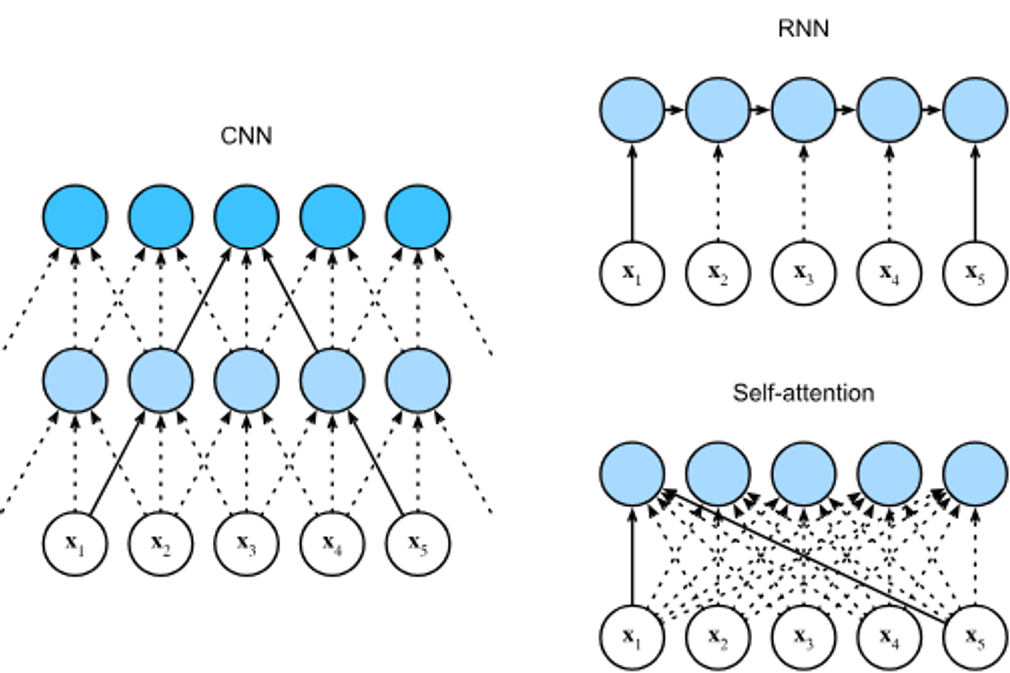
CNN(패딩 토큰은 생략), RNN 및 self-attention 아키텍처 비교.
- CNN
- CNN은 지역적 특징을 처리할 수 있으며, 계산 복잡성은 입니다. CNN은 계층적 구조를 가지므로, 경로 길이가 입니다.
- RNN
- RNN은 순차적 연산을 필요로 하며, 계산 복잡성은 입니다. RNN은 각 단계마다 이전 단계에 의존하기 때문에, 최대 경로 길이도 입니다.
- self-attention
- self-attention은 병렬 계산을 가능하게 하며, 계산 복잡성은 입니다. self-attention은 모든 토큰이 서로 직접 연결되어 있기 때문에, 최대 경로 길이가 입니다.
- CNN
-
Positional Encoding
- self-attention
- RNN과 달리, self-attention은 시퀀스의 토큰을 순차적으로 처리하는 대신 병렬 계산을 사용합니다. 이는 계산 효율성을 크게 향상시킵니다. 하지만, self-attention 자체는 토큰의 순서 정보를 보존하지 않습니다.
- 많은 자연어 처리 작업에서 토큰의 순서는 매우 중요합니다. 예를 들어, "나는 밥을 먹었다"와 "밥을 먹었다 나는"은 같은 단어를 포함하지만 전혀 다른 의미를 가집니다.
- positional encoding
- positional encoding은 모델에게 각 토큰의 위치 정보를 추가적인 입력으로 제공하여 순서 정보를 보존하는 방법입니다.
- 위치 인코딩은 학습 가능하거나 미리 고정된 방식으로 구현될 수 있습니다. Vaswani et al. (2017)에서 제안된 고정된 방식은 사인과 코사인 함수를 사용하여 각 위치에 대한 고유한 인코딩을 생성합니다.
- self-attention
-
입력 표현 는 시퀀스의 개 토큰에 대한 -차원 임베딩을 포함합니다.
- positional encoding은 positional embedding matrix 를 사용하여 출력 를 생성합니다. 이 행렬은 입력 표현과 같은 형태를 가지며, 각 요소는 특정 위치와 차원에 대한 사인 또는 코사인 값을 가집니다.
import torch from torch import nn from d2l import torch as d2l # PositionalEncoding 클래스 정의 class PositionalEncoding(nn.Module): #@save """Positional encoding.""" def __init__(self, num_hiddens, dropout, max_len=1000): super().__init__() self.dropout = nn.Dropout(dropout) # 드롭아웃 설정 # 위치 인코딩 행렬 P를 생성합니다. 이 행렬은 충분히 길게 설정됩니다. self.P = torch.zeros((1, max_len, num_hiddens)) # 위치 정보를 계산하기 위한 행렬 X를 생성합니다. X = torch.arange(max_len, dtype=torch.float32).reshape( -1, 1) / torch.pow(10000, torch.arange( 0, num_hiddens, 2, dtype=torch.float32) / num_hiddens) # 사인 함수를 사용하여 짝수 인덱스에 위치 인코딩을 적용합니다. self.P[:, :, 0::2] = torch.sin(X) # 코사인 함수를 사용하여 홀수 인덱스에 위치 인코딩을 적용합니다. self.P[:, :, 1::2] = torch.cos(X) # 순전파 함수 def forward(self, X): # 입력 X에 위치 인코딩 P를 더하고, 장치(device)를 맞춥니다. X = X + self.P[:, :X.shape[1], :].to(X.device) # 드롭아웃을 적용한 후 결과를 반환합니다. return self.dropout(X) # 인코딩 차원과 시퀀스 길이를 설정합니다. encoding_dim, num_steps = 32, 60 # PositionalEncoding 인스턴스를 생성합니다. pos_encoding = PositionalEncoding(encoding_dim, 0) # 입력 데이터 X를 생성합니다. X = pos_encoding(torch.zeros((1, num_steps, encoding_dim))) # 위치 인코딩 행렬 P를 추출합니다. P = pos_encoding.P[:, :X.shape[1], :] # 위치 인코딩의 일부를 시각화합니다. d2l.plot(torch.arange(num_steps), P[0, :, 6:10].T, xlabel='Row (position)', figsize=(6, 2.5), legend=["Col %d" % d for d in torch.arange(6, 10)])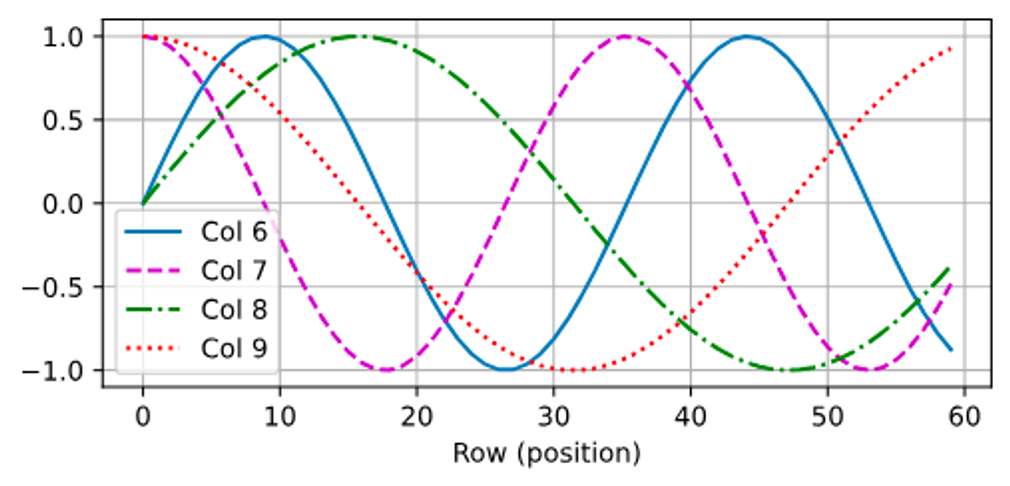
- Absolute Positional Information
# 0부터 7까지의 숫자를 이진수로 출력합니다. for i in range(8): # f-string을 사용하여 각 숫자를 이진수로 변환하고 출력합니다. # {i:>03b}는 숫자 i를 이진수로 변환하고, 총 3자리를 차지하도록 오른쪽 정렬합니다. print(f'{i} in binary is {i:>03b}') # 이진 표현에서 높은 비트는 낮은 비트보다 낮은 주파수를 갖습니다. # 위치 인코딩에서도 비슷한 원리가 적용됩니다. 삼각 함수를 사용하여 인코딩 차원을 따라 주파수를 감소시킵니다. # 이는 위치 인코딩이 각 위치에 대해 고유한 패턴을 생성할 수 있도록 합니다. # 위치 인코딩 행렬 P를 조작하여 히트맵에 적합한 형태로 만듭니다. P = P[0, :, :].unsqueeze(0).unsqueeze(0) # P의 차원을 조정합니다. # 위치 인코딩 행렬 P의 히트맵을 시각화합니다. # xlabel과 ylabel은 각각 히트맵의 x축과 y축 레이블을 지정합니다. # figsize는 히트맵의 크기를 지정합니다. # cmap은 히트맵의 색상 맵을 지정합니다. d2l.show_heatmaps(P, xlabel='Column (encoding dimension)', ylabel='Row (position)', figsize=(3.5, 4), cmap='Blues')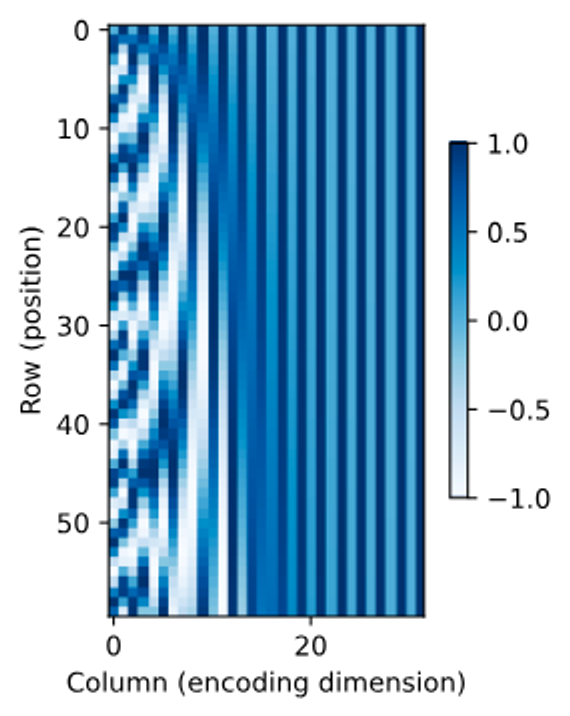
- positional encoding은 positional embedding matrix 를 사용하여 출력 를 생성합니다. 이 행렬은 입력 표현과 같은 형태를 가지며, 각 요소는 특정 위치와 차원에 대한 사인 또는 코사인 값을 가집니다.
Relative Positional Information
- p(i, 2j)와 p(i, 2j+1):
- 위치 에 대한 인코딩 값으로, 각각 사인과 코사인 함수를 통해 계산됩니다. 이 값들은 시퀀스 내 각 위치의 고유한 패턴을 나타냅니다.
- 회전 행렬(Rotation Matrix):
- 는 2D 공간에서의 회전을 나타내는 행렬입니다. 이 행렬은 벡터를 각도 만큼 회전시키는 역할을 합니다.
- 벡터 곱셈(Vector Multiplication):
- 회전 행렬과 위치 의 인코딩 값을 곱하면, 위치 의 인코딩이 만큼 이동한 새로운 위치 의 인코딩 값을 얻을 수 있습니다. 이는 위치 인코딩이 시퀀스 내에서 어떻게 이동할 수 있는지를 보여줍니다.
- 삼각 함수의 합성(Composition of Trigonometric Functions):
- 사인 함수의 합성: 는 사인 함수의 합성 공식을 사용하여 로 간소화됩니다.
- 코사인 함수의 합성:는 코사인 함수의 합성 공식을 사용하여 로 간소화됩니다.
11.7. The Transformer Architecture
-
Transformer의 등장
- 초기의 self-attention 모델들은 입력 표현을 위해 여전히 RNN을 사용했습니다. 하지만 Transformer는 CNN이나 RNN을 전혀 사용하지 않고 오직 self-attention 메커니즘만을 기반으로 합니다. 이는 모델을 더 간단하고 효율적으로 만들며, 깊은 네트워크에서도 안정적인 학습을 가능하게 합니다.
- 처음에는 텍스트 데이터에 대한 sequence-to-sequence 학습을 위해 제안되었지만, Transformer는 언어, 비전, 음성, 강화 학습 등 다양한 분야에서 폭넓게 사용되고 있습니다. 이는 Transformer의 강력한 표현력과 범용성을 보여줍니다.
-
모델
-
이전에는 Bahdanau attention이 sequence-to-sequence 학습에 사용되었습니다. 이 방식은 RNN과 결합하여 입력 시퀀스의 각 요소에 대한 컨텍스트 벡터를 생성합니다.
-
Transformer는 Bahdanau 주목과 달리 RNN을 사용하지 않고, 오직 self-attention 메커니즘만을 사용하여 입력과 출력 시퀀스를 처리합니다.
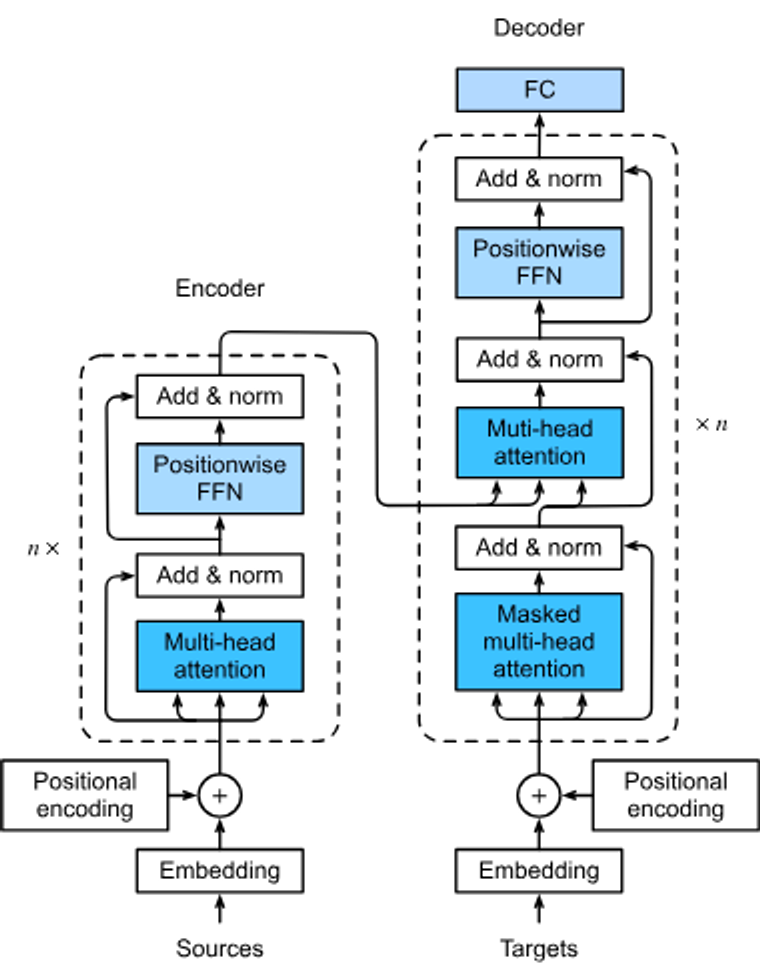
Transformer 아키텍처
-
Transformer 인코더
- Transformer 인코더는 여러 개의 동일한 레이어를 쌓아서 만들어집니다. 각 레이어는 두 개의 서브레이어로 구성됩니다: Multi Head Self Attention과 위치별 Feed Forward 네트워크입니다.
- 인코더의 Self Attention에서 쿼리, 키, 값은 모두 이전 인코더 레이어의 출력에서 옵니다. 이를 통해 각 요소가 시퀀스 내의 모든 다른 요소와 관계를 맺을 수 있습니다.
- 각 서브레이어 주변에는 ResNet에서 영감을 받은 잔차 연결이 적용되며, 이어서 레이어 정규화가 수행됩니다. 이는 깊은 네트워크에서 안정적인 학습을 가능하게 합니다.
- 인코더는 입력 시퀀스의 각 위치에 대한 다차원 벡터 표현을 출력합니다.
-
Transformer 디코더
- 디코더 역시 여러 개의 동일한 레이어를 쌓아서 만들어지며, 잔차 연결과 레이어 정규화를 포함합니다.
- 인코더에 있는 두 개의 서브레이어 외에, 디코더는 세 번째 서브레이어인 인코더-디코더 attention을 추가합니다. 이 서브레이어에서 쿼리는 디코더의 자기 주목 서브레이어의 출력에서, 키와 값은 인코더의 출력에서 옵니다.
- 디코더의 Self Attention에서는 각 위치가 그 위치까지의 디코더 위치만 attention할 수 있습니다. 이는 자동 회귀적 특성을 보존하며, 예측이 생성된 토큰에만 의존하도록 합니다.
-
-
Positionwise Feed-Forward Networks
import torch from torch import nn # PositionWiseFFN 클래스 정의 class PositionWiseFFN(nn.Module): #@save """The positionwise feed-forward network.""" def __init__(self, ffn_num_hiddens, ffn_num_outputs): super().__init__() # 첫 번째 레이어: 입력을 ffn_num_hiddens 차원으로 변환 self.dense1 = nn.LazyLinear(ffn_num_hiddens) # 활성화 함수로 ReLU 사용 self.relu = nn.ReLU() # 두 번째 레이어: 첫 번째 레이어의 출력을 ffn_num_outputs 차원으로 변환 self.dense2 = nn.LazyLinear(ffn_num_outputs) # 순전파 함수 def forward(self, X): # 입력 X를 첫 번째 레이어를 통과시키고, ReLU 활성화 함수를 적용한 후, # 두 번째 레이어를 통과시켜 결과를 반환합니다. return self.dense2(self.relu(self.dense1(X))) # PositionWiseFFN 인스턴스 생성 # ffn_num_hiddens: 첫 번째 레이어의 출력 차원, ffn_num_outputs: 두 번째 레이어의 출력 차원 ffn = PositionWiseFFN(4, 8) ffn.eval() # 모델을 평가 모드로 설정 # 입력 텐서 생성: (배치 크기, 시퀀스 길이, 특징 차원) = (2, 3, 4) # 이 텐서는 모든 위치에서 동일한 MLP를 통해 변환됩니다. input_tensor = torch.ones((2, 3, 4)) # PositionWiseFFN을 통과시킨 결과를 출력 # 출력 텐서의 차원은 (배치 크기, 시퀀스 길이, ffn_num_outputs) = (2, 3, 8)이 됩니다. print(ffn(input_tensor)[0])- 위치별 Feed-Forward 네트워크(PositionWiseFFN)를 구현합니다. 이 네트워크는 시퀀스의 모든 위치에서 동일한 다층 퍼셉트론(MLP)을 사용하여 각 위치의 표현을 변환합니다. 첫 번째 레이어는 입력을 중간 차원으로 변환하고, ReLU 활성화 함수를 적용한 후, 두 번째 레이어는 최종 출력 차원으로 변환합니다. 입력 텐서가 네트워크를 통과할 때, 내부 차원은
ffn_num_outputs로 변경됩니다. 모든 위치에서 동일한 MLP가 적용되기 때문에, 입력이 동일하면 출력도 동일합니다.
- 위치별 Feed-Forward 네트워크(PositionWiseFFN)를 구현합니다. 이 네트워크는 시퀀스의 모든 위치에서 동일한 다층 퍼셉트론(MLP)을 사용하여 각 위치의 표현을 변환합니다. 첫 번째 레이어는 입력을 중간 차원으로 변환하고, ReLU 활성화 함수를 적용한 후, 두 번째 레이어는 최종 출력 차원으로 변환합니다. 입력 텐서가 네트워크를 통과할 때, 내부 차원은
-
Residual Connection and Layer Normalization
import torch from torch import nn from d2l import torch as d2l # LayerNorm과 BatchNorm을 비교하기 위한 코드 ln = nn.LayerNorm(2) # 2개의 특징을 가진 레이어 정규화 bn = nn.LazyBatchNorm1d() # 1차원 배치 정규화 X = torch.tensor([[1, 2], [2, 3]], dtype=torch.float32) # 입력 텐서 # 레이어 정규화와 배치 정규화를 적용하여 결과를 출력합니다. print('layer norm:', ln(X), '\nbatch norm:', bn(X)) # AddNorm 클래스 정의 class AddNorm(nn.Module): #@save """The residual connection followed by layer normalization.""" def __init__(self, norm_shape, dropout): super().__init__() self.dropout = nn.Dropout(dropout) # 드롭아웃 설정 self.ln = nn.LayerNorm(norm_shape) # 레이어 정규화 설정 # 순전파 함수 def forward(self, X, Y): # 잔차 연결 후 드롭아웃을 적용하고, 레이어 정규화를 수행합니다. return self.ln(self.dropout(Y) + X) # AddNorm 인스턴스 생성 add_norm = AddNorm(4, 0.5) # 4개의 특징을 가진 레이어 정규화와 0.5의 드롭아웃 비율 shape = (2, 3, 4) # 입력 텐서의 형태 # AddNorm을 통과시킨 결과의 형태를 확인합니다. # 입력과 출력의 형태가 동일해야 합니다 (잔차 연결의 요구사항). d2l.check_shape(add_norm(torch.ones(shape), torch.ones(shape)), shape)- 레이어 정규화(Layer Normalization): 레이어 정규화는 배치 정규화와 유사하지만, 특징 차원을 따라 정규화를 수행합니다. 이는 입력 시퀀스의 길이가 다양한 자연어 처리 작업에서 특히 유용합니다.
- 잔차 연결(Residual Connection): 잔차 연결은 입력 와 변환된 출력 를 더하여, 깊은 네트워크에서도 안정적인 학습을 가능하게 합니다. 이를 위해 입력과 출력의 형태가 동일해야 합니다.
- 드롭아웃(Dropout): 드롭아웃은 과적합을 방지하기 위해 네트워크의 일부 연결을 무작위로 끊는 정규화 기법입니다.
-
Encoder
import torch from torch import nn import math from d2l import torch as d2l # TransformerEncoderBlock 클래스 정의 class TransformerEncoderBlock(nn.Module): #@save """The Transformer encoder block.""" def __init__(self, num_hiddens, ffn_num_hiddens, num_heads, dropout, use_bias=False): super().__init__() # 멀티-헤드 자기 주목 서브레이어 self.attention = d2l.MultiHeadAttention(num_hiddens, num_heads, dropout, use_bias) # 첫 번째 Add & Norm 서브레이어 self.addnorm1 = AddNorm(num_hiddens, dropout) # 위치별 피드포워드 네트워크 서브레이어 self.ffn = PositionWiseFFN(ffn_num_hiddens, num_hiddens) # 두 번째 Add & Norm 서브레이어 self.addnorm2 = AddNorm(num_hiddens, dropout) # 순전파 함수 def forward(self, X, valid_lens): # 첫 번째 서브레이어를 통과한 후 두 번째 서브레이어를 통과합니다. Y = self.addnorm1(X, self.attention(X, X, X, valid_lens)) return self.addnorm2(Y, self.ffn(Y)) # TransformerEncoderBlock 인스턴스 생성 및 형태 확인 X = torch.ones((2, 100, 24)) valid_lens = torch.tensor([3, 2]) encoder_blk = TransformerEncoderBlock(24, 48, 8, 0.5) encoder_blk.eval() d2l.check_shape(encoder_blk(X, valid_lens), X.shape) # TransformerEncoder 클래스 정의 class TransformerEncoder(d2l.Encoder): #@save """The Transformer encoder.""" def __init__(self, vocab_size, num_hiddens, ffn_num_hiddens, num_heads, num_blks, dropout, use_bias=False): super().__init__() self.num_hiddens = num_hiddens # 임베딩 레이어 self.embedding = nn.Embedding(vocab_size, num_hiddens) # 위치 인코딩 self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout) # 여러 개의 TransformerEncoderBlock을 쌓아서 인코더를 구성합니다. self.blks = nn.Sequential() for i in range(num_blks): self.blks.add_module("block"+str(i), TransformerEncoderBlock( num_hiddens, ffn_num_hiddens, num_heads, dropout, use_bias)) # 순전파 함수 def forward(self, X, valid_lens): # 임베딩과 위치 인코딩을 적용합니다. X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens)) self.attention_weights = [None] * len(self.blks) for i, blk in enumerate(self.blks): X = blk(X, valid_lens) self.attention_weights[i] = blk.attention.attention.attention_weights return X # TransformerEncoder 인스턴스 생성 및 형태 확인 encoder = TransformerEncoder(200, 24, 48, 8, 2, 0.5) d2l.check_shape(encoder(torch.ones((2, 100), dtype=torch.long), valid_lens), (2, 100, 24))- TransformerEncoderBlock: 이는 Multi Head Self Attention과 위치별 Feed-Forward 네트워크를 포함하는 인코더의 한 레이어입니다. 각 서브레이어 주변에는 잔차 연결과 레이어 정규화가 적용됩니다.
- TransformerEncoder: 이는 여러 개의
TransformerEncoderBlock레이어를 쌓아서 만든 전체 인코더입니다. 각 입력에 대해 임베딩과 위치 인코딩을 적용한 후, 이를 여러 인코더 블록을 통과시켜 최종 출력을 생성합니다. - 임베딩과 위치 인코딩: 입력 시퀀스는 먼저 임베딩 레이어를 통과하여 고정된 차원의 벡터로 변환됩니다. 그 후 위치 인코딩이 추가되어 시퀀스의 순서 정보가 포함됩니다. 위치 인코딩 값은 항상 -1과 1 사이이므로, 임베딩 값은 임베딩 차원의 제곱근으로 스케일링됩니다.
- 인코더 블록: 각 인코더 블록은 Self-Attention 메커니즘을 사용하여 입력 시퀀스의 각 위치에서 전체 시퀀스에 대한 정보를 집계합니다. 이후 위치별 Feed-Forward 네트워크를 통과하여 추가적인 변환을 수행합니다. 각 서브레이어의 출력은 잔차 연결을 통해 입력과 더해지고, 레이어 정규화를 통해 정규화됩니다.
- 자기 주목과 잔차 연결: Self-Attention 메커니즘은 시퀀스 내의 모든 위치에서 다른 모든 위치의 정보를 통합할 수 있게 해줍니다. 잔차 연결은 깊은 네트워크에서도 그래디언트가 효과적으로 전파될 수 있도록 돕습니다.
- 출력: 인코더는 입력 시퀀스의 각 위치에 대해 고차원의 표현을 출력합니다. 이 표현은 디코더로 전달되어 최종 출력 시퀀스를 생성하는 데 사용됩니다.
-
Decoder
import torch from torch import nn from d2l import torch as d2l import math # TransformerDecoderBlock 클래스 정의 class TransformerDecoderBlock(nn.Module): """The i-th block in the Transformer decoder""" def __init__(self, num_hiddens, ffn_num_hiddens, num_heads, dropout, i): super().__init__() self.i = i # 블록의 인덱스 # 첫 번째 서브레이어: 멀티-헤드 자기 주목 self.attention1 = d2l.MultiHeadAttention(num_hiddens, num_heads, dropout) # 첫 번째 Add & Norm self.addnorm1 = AddNorm(num_hiddens, dropout) # 두 번째 서브레이어: 인코더-디코더 주목 self.attention2 = d2l.MultiHeadAttention(num_hiddens, num_heads, dropout) # 두 번째 Add & Norm self.addnorm2 = AddNorm(num_hiddens, dropout) # 세 번째 서브레이어: 위치별 피드포워드 네트워크 self.ffn = PositionWiseFFN(ffn_num_hiddens, num_hiddens) # 세 번째 Add & Norm self.addnorm3 = AddNorm(num_hiddens, dropout) # 순전파 함수 def forward(self, X, state): enc_outputs, enc_valid_lens = state[0], state[1] # 인코더 출력과 유효 길이 # 디코더 자기 주목을 위한 키와 값 if state[2][self.i] is None: key_values = X else: key_values = torch.cat((state[2][self.i], X), dim=1) state[2][self.i] = key_values # 디코더 자기 주목 X2 = self.attention1(X, key_values, key_values, dec_valid_lens) Y = self.addnorm1(X, X2) # 인코더-디코더 주목 Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens) Z = self.addnorm2(Y, Y2) # 위치별 피드포워드 네트워크와 세 번째 Add & Norm return self.addnorm3(Z, self.ffn(Z)), state # TransformerDecoder 클래스 정의 class TransformerDecoder(d2l.AttentionDecoder): """The Transformer decoder.""" def __init__(self, vocab_size, num_hiddens, ffn_num_hiddens, num_heads, num_blks, dropout): super().__init__() self.num_hiddens = num_hiddens self.num_blks = num_blks # 임베딩 레이어 self.embedding = nn.Embedding(vocab_size, num_hiddens) # 위치 인코딩 self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout) # 여러 개의 TransformerDecoderBlock을 쌓아서 디코더를 구성합니다. self.blks = nn.Sequential() for i in range(num_blks): self.blks.add_module("block"+str(i), TransformerDecoderBlock( num_hiddens, ffn_num_hiddens, num_heads, dropout, i)) # 최종 출력을 위한 완전 연결 레이어 self.dense = nn.LazyLinear(vocab_size) # 초기 상태 설정 함수 def init_state(self, enc_outputs, enc_valid_lens): return [enc_outputs, enc_valid_lens, [None] * self.num_blks] # 순전파 함수 def forward(self, X, state): # 임베딩과 위치 인코딩을 적용합니다. X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens)) self._attention_weights = [[None] * len(self.blks) for _ in range(2)] for i, blk in enumerate(self.blks): X, state = blk(X, state) # 디코더 자기 주목 가중치 self._attention_weights[0][i] = blk.attention1.attention.attention_weights # 인코더-디코더 주목 가중치 self._attention_weights[1][i] = blk.attention2.attention.attention_weights return self.dense(X), state # 주목 가중치를 반환하는 속성 @property def attention_weights(self): return self._attention_weights- TransformerDecoderBlock: 이는 디코더의 한 레이어로, 세 개의 서브레이어를 포함합니다. 각 서브레이어 주변에는 잔차 연결과 레이어 정규화가 적용됩니다.
- Decoder Self-Attention: 이 서브레이어는 디코더의 이전 레이어 출력에서 쿼리, 키, 값이 모두 옵니다. 이를 통해 각 요소가 이전 시간 단계의 모든 요소와 관계를 맺을 수 있습니다.
- Encoder-Decoder Attention: 이 서브레이어는 디코더의 쿼리와 인코더의 키 및 값 사이의 관계를 모델링합니다. 이를 통해 디코더가 인코더의 출력에 주목할 수 있습니다.
- 위치별 피드포워드 네트워크(Positionwise Feed-Forward Network): 이 서브레이어는 추가적인 변환을 수행합니다.
- TransformerDecoder: 이는 여러 개의
TransformerDecoderBlock레이어를 쌓아서 만든 전체 디코더입니다. 각 입력에 대해 임베딩과 위치 인코딩을 적용한 후, 이를 여러 디코더 블록을 통과시켜 최종 출력을 생성합니다. 마지막으로, 완전 연결 레이어를 통해 모든 가능한 출력 토큰에 대한 예측을 계산합니다.- 디코더의 Self Attention Weight와 인코더-디코더 Attention Weight: 두가지 attention weight는 나중에 시각화를 위해 저장됩니다.
- TransformerDecoderBlock: 이는 디코더의 한 레이어로, 세 개의 서브레이어를 포함합니다. 각 서브레이어 주변에는 잔차 연결과 레이어 정규화가 적용됩니다.
-
Training
from d2l import torch as d2l import torch # 데이터 로딩: 영어-프랑스어 기계 번역 데이터셋 data = d2l.MTFraEng(batch_size=128) # 하이퍼파라미터 설정 num_hiddens, num_blks, dropout = 256, 2, 0.2 # 은닉 유닛 수, 블록 수, 드롭아웃 비율 ffn_num_hiddens, num_heads = 64, 4 # 피드포워드 네트워크의 은닉 유닛 수, 멀티헤드 주목의 헤드 수 # Transformer 인코더 인스턴스 생성 encoder = TransformerEncoder( len(data.src_vocab), # 소스 어휘 크기 num_hiddens, # 은닉 유닛 수 ffn_num_hiddens, # 피드포워드 네트워크의 은닉 유닛 수 num_heads, # 멀티헤드 주목의 헤드 수 num_blks, # 블록 수 dropout # 드롭아웃 비율 ) # Transformer 디코더 인스턴스 생성 decoder = TransformerDecoder( len(data.tgt_vocab), # 타겟 어휘 크기 num_hiddens, # 은닉 유닛 수 ffn_num_hiddens, # 피드포워드 네트워크의 은닉 유닛 수 num_heads, # 멀티헤드 주목의 헤드 수 num_blks, # 블록 수 dropout # 드롭아웃 비율 ) # Seq2Seq 모델 생성 model = d2l.Seq2Seq( encoder, # 인코더 decoder, # 디코더 tgt_pad=data.tgt_vocab['<pad>'], # 타겟 패딩 토큰 lr=0.001 # 학습률 ) # 훈련 설정 trainer = d2l.Trainer( max_epochs=30, # 최대 에포크 수 gradient_clip_val=1, # 그래디언트 클리핑 값 num_gpus=1 # 사용할 GPU 수 ) # 모델 훈련 trainer.fit(model, data)-
데이터 로딩:
d2l.MTFraEng을 사용하여 영어-프랑스어 기계 번역 데이터셋을 로드합니다. -
인코더와 디코더 생성:
TransformerEncoder와TransformerDecoder클래스를 사용하여 인코더와 디코더를 생성합니다. 이들은 각각 2개의 레이어와 4개의 멀티헤드 주목을 사용합니다. -
Seq2Seq 모델 생성: 인코더와 디코더를 결합하여 Seq2Seq 모델을 생성합니다. 타겟 시퀀스의 패딩 토큰과 학습률도 설정합니다.
-
훈련:
d2l.Trainer를 사용하여 모델을 훈련합니다. 최대 에포크 수, 그래디언트 클리핑 값, 사용할 GPU 수를 지정합니다.
# 영어 문장과 해당 프랑스어 번역 engs = ['go .', 'i lost .', 'he\'s calm .', 'i\'m home .'] fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .'] # 모델을 사용하여 번역 예측 preds, _ = model.predict_step( data.build(engs, fras), d2l.try_gpu(), data.num_steps) # 예측된 번역과 BLEU 점수 출력 for en, fr, p in zip(engs, fras, preds): translation = [] # 타겟 어휘집을 사용하여 토큰을 단어로 변환 for token in data.tgt_vocab.to_tokens(p): if token == '<eos>': # 문장의 끝을 나타내는 토큰 break translation.append(token) # 원문, 번역문, BLEU 점수 출력 print(f'{en} => {translation}, bleu,' f'{d2l.bleu(" ".join(translation), fr, k=2):.3f}') -
번역과 BLEU 점수 계산: 주어진 영어 문장(
engs)을 프랑스어(fras)로 번역하고, 각 번역에 대한 BLEU 점수를 계산합니다. BLEU 점수는 번역의 품질을 평가하는 데 사용되며, 높을수록 좋은 번역을 나타냅니다.# 디코더의 주목 가중치 시각화 _, dec_attention_weights = model.predict_step( data.build([engs[-1]], [fras[-1]]), d2l.try_gpu(), data.num_steps, True) # 인코더의 주목 가중치 추출 및 형태 변환 enc_attention_weights = torch.cat(model.encoder.attention_weights, 0) shape = (num_blks, num_heads, -1, data.num_steps) enc_attention_weights = enc_attention_weights.reshape(shape) # 인코더 주목 가중치의 형태 확인 d2l.check_shape(enc_attention_weights, (num_blks, num_heads, data.num_steps, data.num_steps)) # 인코더 자기 주목 가중치 시각화 d2l.show_heatmaps( enc_attention_weights.cpu(), xlabel='Key positions', ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)], figsize=(7, 3.5)) -
디코더 Attention Weight 시각화: 마지막 영어 문장에 대한 디코더의 Attention Weight을 계산하고 시각화합니다. 이를 통해 모델이 번역하는 동안 입력 시퀀스의 어떤 부분에 주목하는지 확인할 수 있습니다.
-
인코더 Self-Attention Weight 시각화: 인코더의 Self-Attention Weight을 시각화하여, 모델이 입력 시퀀스의 어떤 부분에 주목하는지 확인합니다. 각 헤드는 독립적으로 주목 패턴을 학습하므로, 다양한 관점에서 입력 데이터를 분석할 수 있습니다.
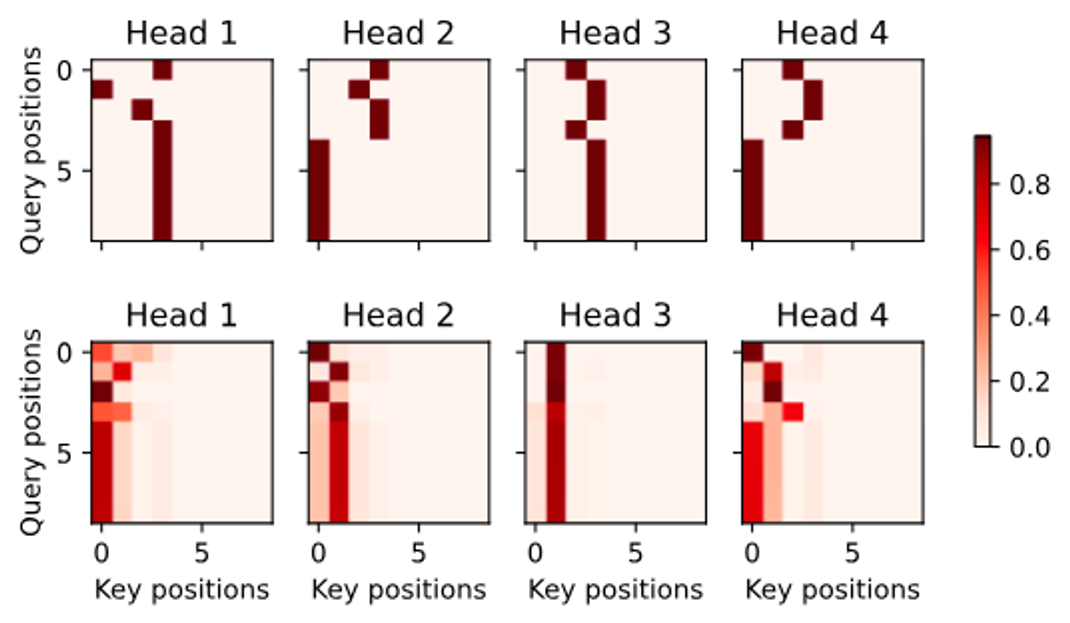
import torch import pandas as pd from d2l import torch as d2l # 디코더 주목 가중치를 2차원 리스트로 변환 dec_attention_weights_2d = [head[0].tolist() for step in dec_attention_weights # 각 스텝별로 for attn in step # 각 주목 블록별로 for blk in attn # 각 레이어별로 for head in blk] # 각 헤드별로 # 마스크된 주목 가중치를 0으로 채움 dec_attention_weights_filled = torch.tensor( pd.DataFrame(dec_attention_weights_2d).fillna(0.0).values) # 주목 가중치의 형태를 변환 shape = (-1, 2, num_blks, num_heads, data.num_steps) dec_attention_weights = dec_attention_weights_filled.reshape(shape) # 디코더 자기 주목 가중치와 인코더-디코더 주목 가중치 분리 dec_self_attention_weights, dec_inter_attention_weights = \ dec_attention_weights.permute(1, 2, 3, 0, 4) # 주목 가중치의 형태 확인 d2l.check_shape(dec_self_attention_weights, (num_blks, num_heads, data.num_steps, data.num_steps)) d2l.check_shape(dec_inter_attention_weights, (num_blks, num_heads, data.num_steps, data.num_steps)) # 디코더 자기 주목 가중치 시각화 d2l.show_heatmaps( dec_self_attention_weights[:, :, :, :], xlabel='Key positions', ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)], figsize=(7, 3.5)) -
Self-Attention 변환: 디코더의 주목 가중치를 2차원 리스트로 변환하고, 마스크된 위치를 0으로 채웁니다. 이렇게 하면 시각화할 때 누락된 값에 대해 고려할 필요가 없습니다.
-
Self-Attention 형태 변환: 주목 가중치의 형태를
dec_self_attention_weights와dec_inter_attention_weights를 분리합니다. 이렇게 분리함으로써 각각을 별도로 시각화할 수 있습니다. -
Self-Attention 시각화:
dec_self_attention_weights를 시각화합니다. 이 시각화는 모델이 디코더의 각 위치에서 어떤 입력 위치에 주목하는지 보여줍니다. 디코더의 Self-Attention은 자동 회귀적 특성을 가지므로, 각 쿼리는 쿼리 위치 이후의 키-값 쌍에 주목하지 않습니다.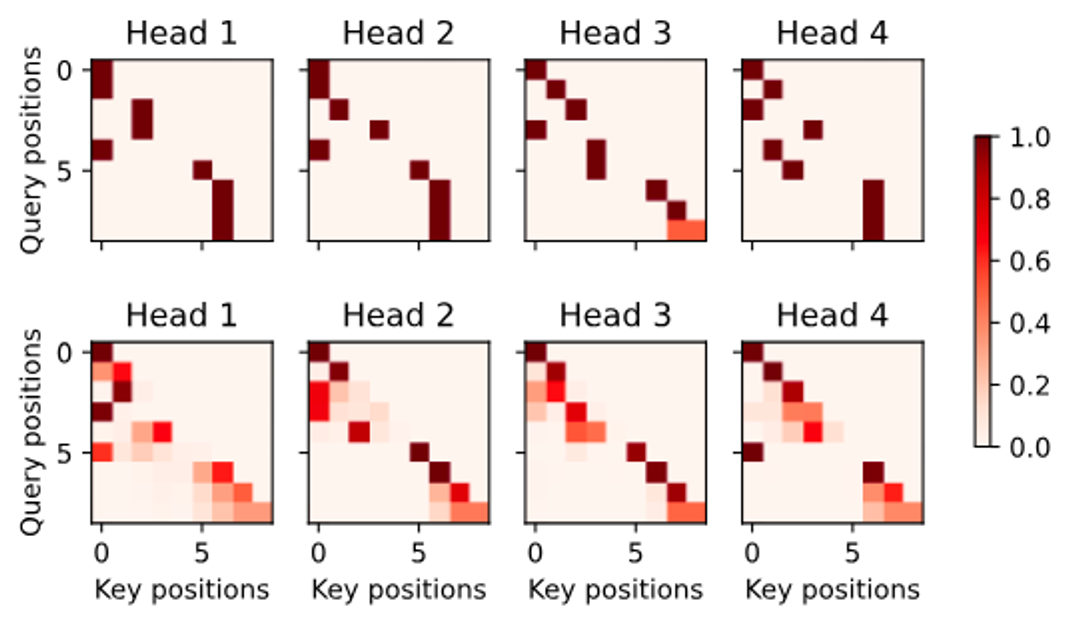
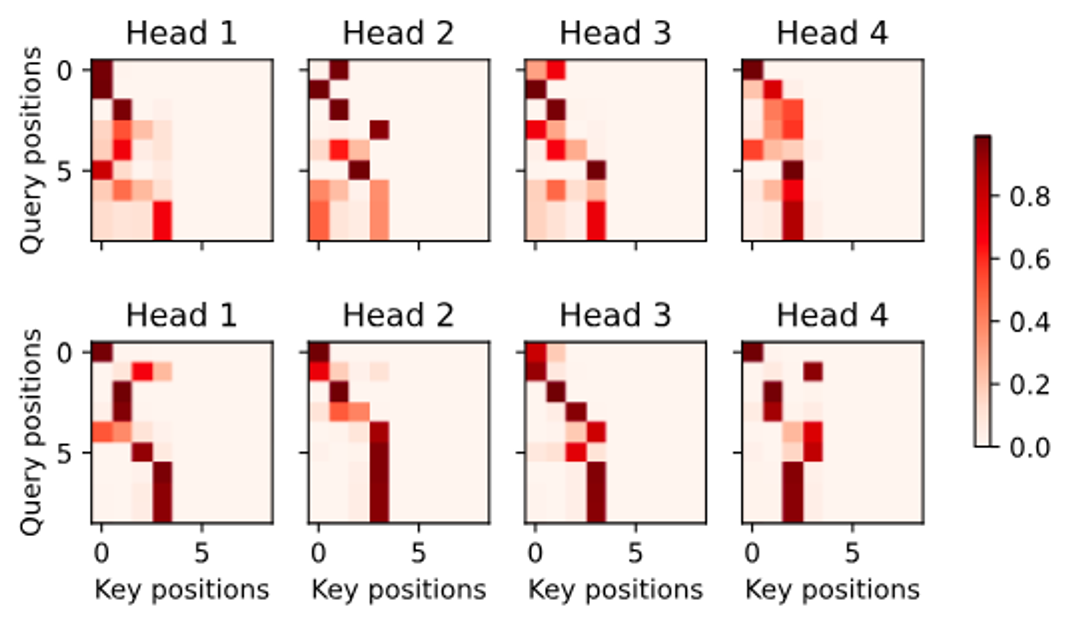
# 인코더-디코더 주목 가중치 시각화 d2l.show_heatmaps( dec_inter_attention_weights, # 인코더-디코더 주목 가중치 xlabel='Key positions', # x축 레이블: 키 위치 ylabel='Query positions', # y축 레이블: 쿼리 위치 titles=['Head %d' % i for i in range(1, 5)], # 각 헤드의 제목 figsize=(7, 3.5) # 그림 크기 ) # Transformer 아키텍처의 다양한 응용에 대한 설명 # Transformer는 원래 시퀀스-투-시퀀스 학습을 위해 제안되었지만, # 책에서 나중에 알게 되겠지만, Transformer 인코더나 디코더는 # 종종 다양한 딥러닝 작업에 개별적으로 사용됩니다. -
인코더-디코더 Attention Weight 시각화: 디코더의 인코더-디코더 Attention Weight을 시각화합니다. 이 시각화는 디코더의 출력 시퀀스의 각 위치에서 인코더의 입력 시퀀스의 어떤 위치에 주목하는지 보여줍니다. 입력 시퀀스의 유효 길이를 지정함으로써, 출력 시퀀스의 어떤 쿼리도 입력 시퀀스의 패딩 토큰에 주목하지 않습니다.
-
