스터디 그룹 주제 및 진행방법
- Dive into Deep Learning 학습
- 각자 관심분야를 선정하여 일주일에 한 챕터씩 공부해, 주 1회 공부한 내용을 팀원들에게 발표.
공부한 챕터 목록
-
Chapter 3) Linear Neural Networks for Regression
-
Chapter 5) Multilayer Perceptrons
-
Chapter 10) Long Short-Term Memory / LSTM
-
Chapter 11) Attention Mechanisms and Transformers
-
Chapter 14) Computer Vision
-
Chapter 20) Generative Adversarial Networks
- 스터디 그룹에서 다룬 챕터 목록은 다음과 같습니다. 저는 Chapter 11) Attention Mechanisms and Transformers을 공부해 팀원들과 공유했습니다.
스터디 그룹 학습 내용
Chapter 3) Linear Neural Networks for Regression
-
해당 모델의 형태
-
Loss function의 정의 및 수학적으로 loss function을 최소화 하는 parameter를 찾는 방법
- Loss function은 실제값 예측 값의 거리를 잰다.
- 전체 데이터셋에서 모델의 질의 평가하려면 훈련데이터의 loss의 평균을 구한다.
- 모델을 훈련할때는 전체 훈련데이터에서 전체 loss를 최소화하는 파라미터 를 찾는다.
- Loss function은 실제값 예측 값의 거리를 잰다.
-
Analytic Solution
- 가 invertible할 때만 유일한 답을 찾을 수 있다.
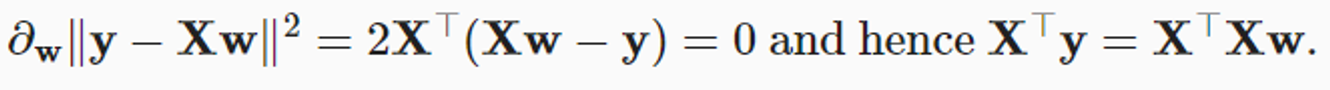
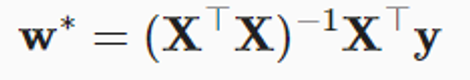
- 가 invertible할 때만 유일한 답을 찾을 수 있다.
-
Loss function을 최소화 하는 parameter를 찾는 또 다른 방법 (Minibatch Stochastic Gradient Descent)
- 모델의 해를 찾을 수 없는 상황에서도 모델을 효율적으로 훈련시킬 수 있따.
- Gradient descent : 반복해서 parameter를 업데이트해서 에러를 줄이는 방법
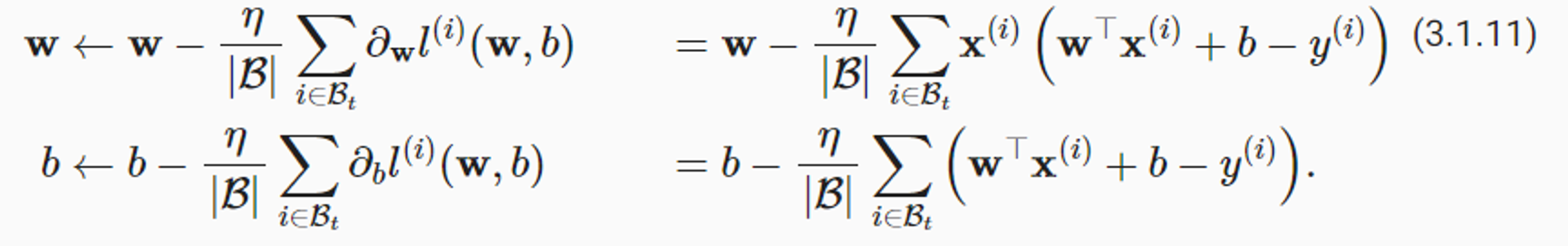
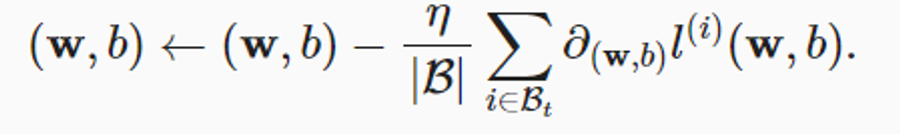
- 는 minibatch. 안에는 정해는 수의 훈련데이터 가 들어가 있다.
Chapter 5) Multilayer Perceptrons
-
Multilayer perceptrons의 정의
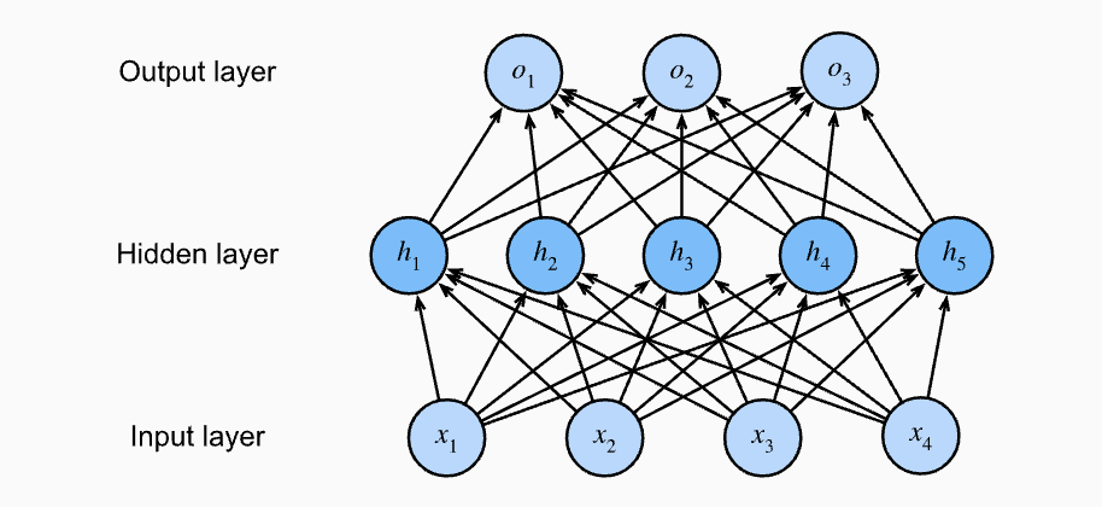
- 특정 뉴런은 이전 층의 모든 뉴런들과 연결고리가 존재하는 구조로 Fully-Connected layers(FCs)의 동의어로 사용된다. 순전파(forward) 과정은 Input값이 weight와 bias의 선형결합을 거쳐 활성화 함수를 통해 비선형 변환을 수행한다.
-
Multilayer perceptrons의 구조
- 노드(node) / 뉴런(neuron) : Transition(z) + Activation Function
- 레이어 / 층(Layer) : 입력층 (Input Layer), 은닉층 (Hidden Layer), 출력층 (Output Layer)
- 엣지(edge) / 커넥션(connection) : 가중치(weight)를 의미
-
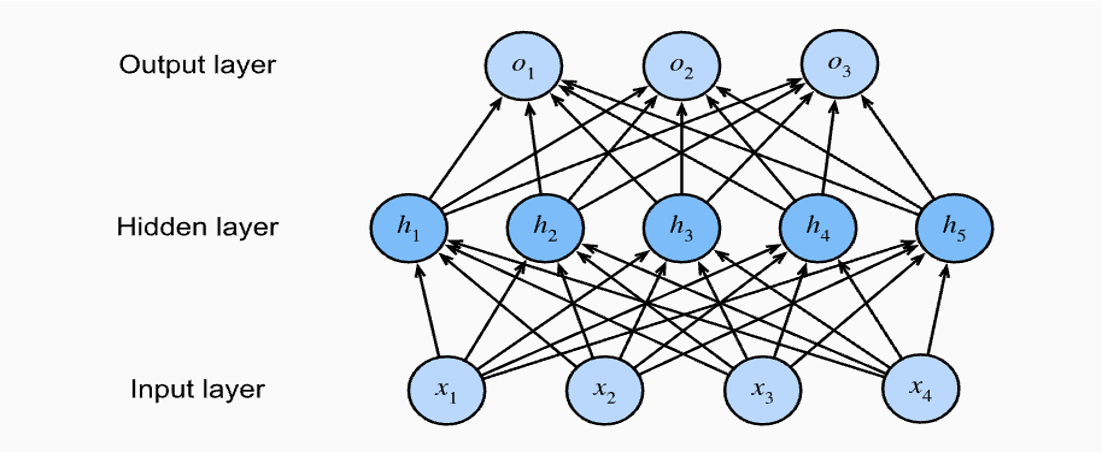
활성화 함수를 사용해야 하는 이유
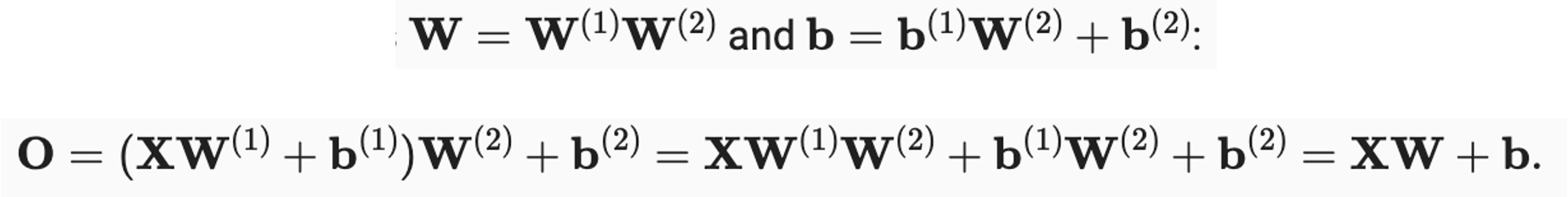
- 활성화 함수를 사용하는 이유는 활성화 함수가 없는 다층 퍼셉트론의 경우는 단순한 선형식을 계산한 결과와 같기 때문이다. 선형식 보다는 비선형식으로 구분하는게 성능이 더 좋을 때가 많으며 선형식으로는 복잡한 문제를 잘 풀 수 없다.
Chapter 10) Long Short-Term Memory / LSTM
-
LSTM의 등장 배경 및 정의
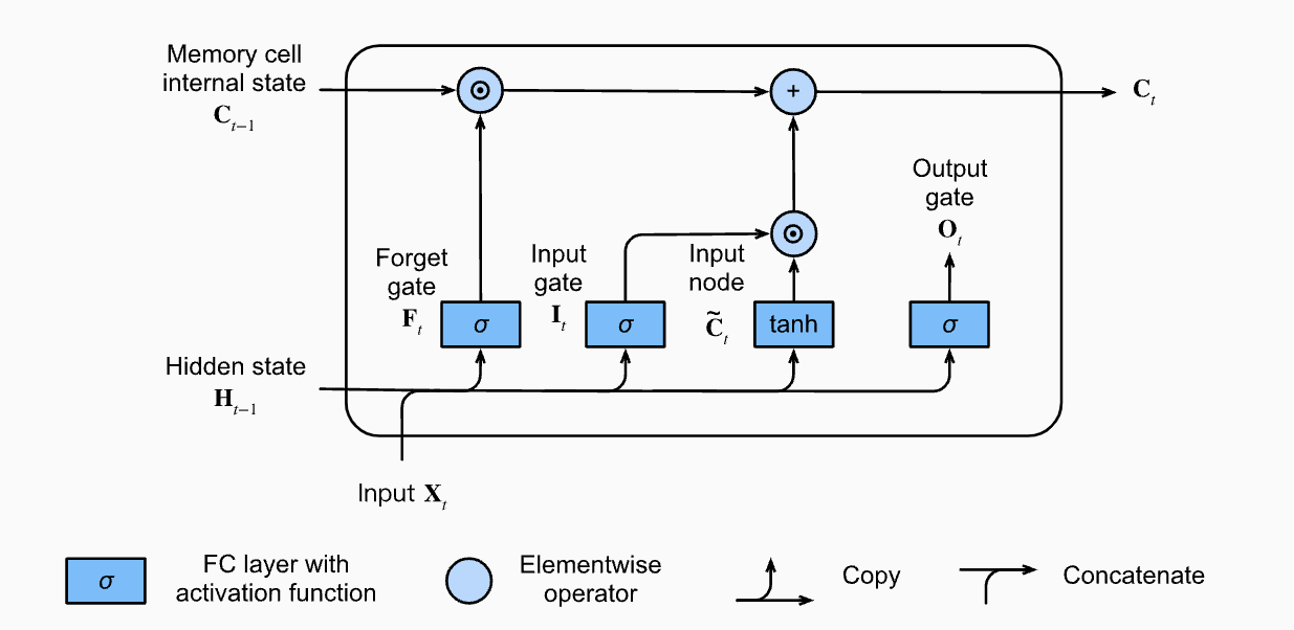
- LSTM은 Long Term Short Memory의 약자로 시퀀스형 데이터의 경우 층이 깊어지거나 데이터의 길이가 길어질수록 앞의 정보가 전달이 잘 되지 않는다는 문제를 보완하기 위해 등장하였다. Cell State와 Hidden State를 통해 정보들이 전달이 되며 3개의 Gate (Forget gate, Input gate, Output gate)를 통해 각각의 정보를 얼마나 잃어버릴지, 얼마나 가져갈지를 계산하게 된다.
-
LSTM의 구성 요소
(1) Input Node
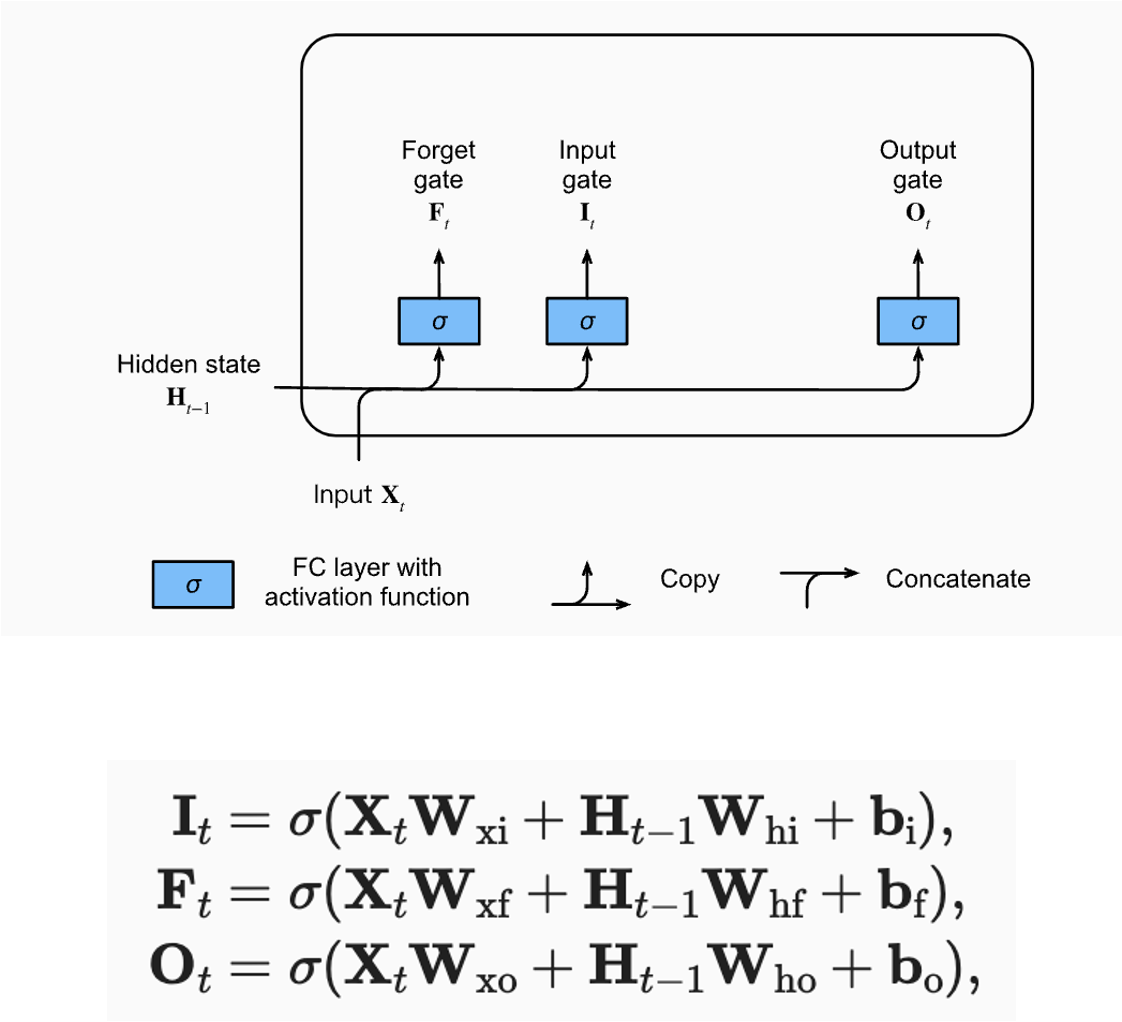
- 각각의 Gate마다 서로 다른 Weight와 Bias값을 가지며 활성화 함수로는 Sigmoid 함수를 사용.
- Forget gate : LSTM에서 가장 첫 단계 중 하나이며 기존 정보 중 어떤 정보를 버릴지 선택한다.
- Input gate : 입력 데이터 중 어떤 정보를 다음 상태로 저장할지 결정한다.
- Output gate : 다음 상태로 어떤 정보를 내보낼지 선택한다.
- 각각의 Gate마다 서로 다른 Weight와 Bias값을 가지며 활성화 함수로는 Sigmoid 함수를 사용.
(2) Memory Cell Internal State
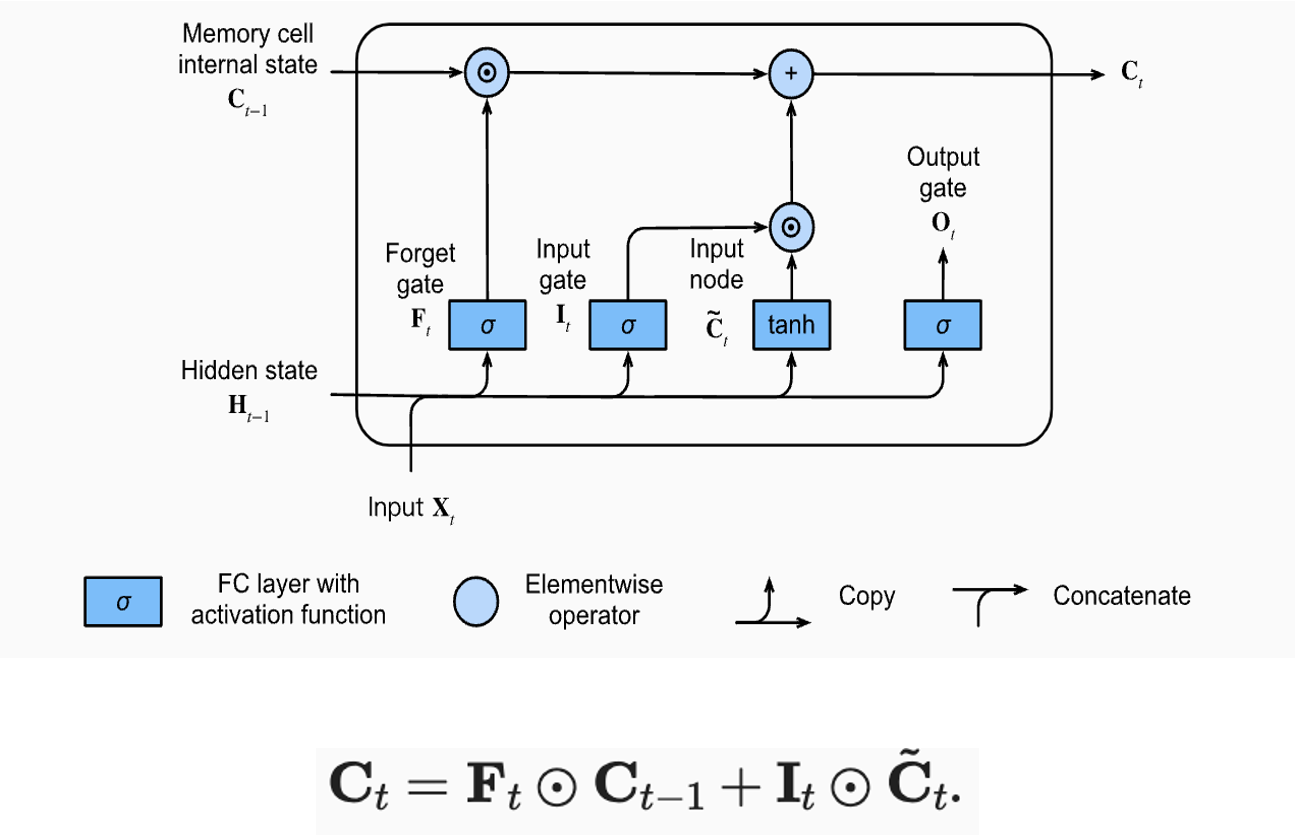
- Forget gate를 통해 계산된 값과 이전 Memory cell의 값을 elementwise 곱을 수행한 뒤 Input Node의 값을 계산한 결과와 합하여 현재 state의 Memory cell을 계산한다.
(3) Hidden State
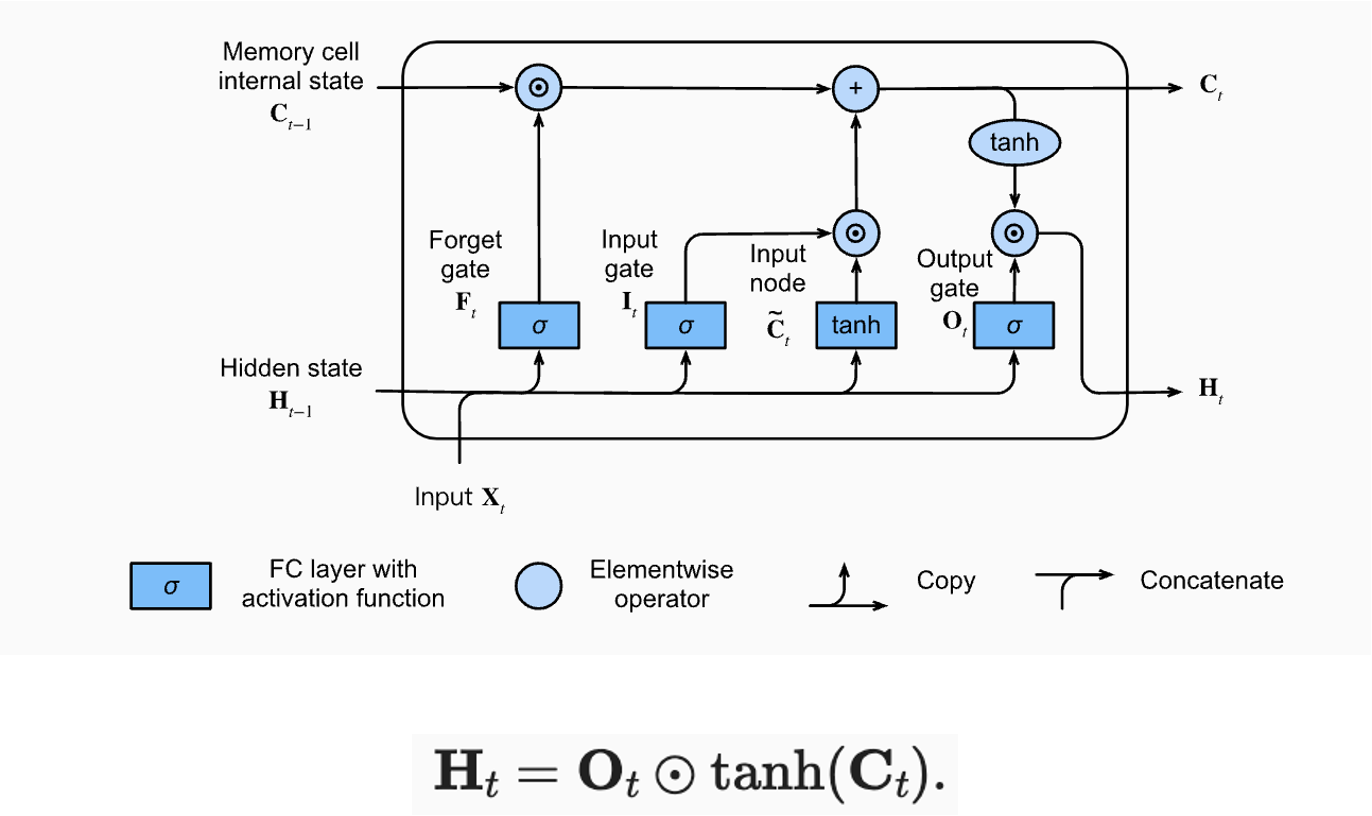
- Output gate를 통해 계산된 값과 현재 업데이트된 Cell State값에 tanh 활성화 함수를 취한 값을 elementwise한 값을 통해 계산된다. 이렇게 계산된 값이 다음 step의 Hidden State로 전달.
Chapter 20) Generative Adversarial Networks
(1) Generative Adversarial Networks
- GAN의 작동 원리에 대한 기본 아이디어를 소개하고 균등 분포나 정규 분포와 같이 간단하고 샘플링하기 쉬운 분포에서 샘플을 추출하여 특정 데이터 세트의 분포와 일치하는 것처럼 보이는 샘플로 변환할 수 있다는 것을 보여주었습니다. 2D 가우스 분포를 매칭하는 예시를 직접 실행해봅니다.
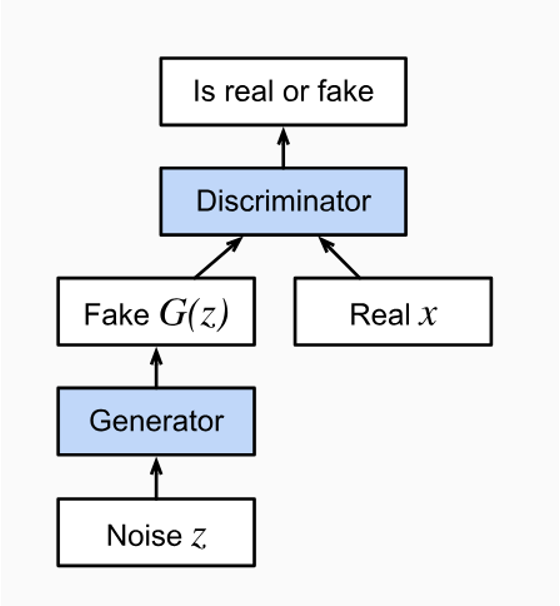
- Generator Network
- 실제 데이터와 유사한 데이터를 생성할 수 있는 장치가 필요합니다. 이 장치의 목표는 실제 데이터를 가능한 한 정확하게 모방하는 것입니다.
- Discriminator Network
- 이 네트워크는 가짜 데이터와 실제 데이터를 구별하려고 합니다. 두 네트워크는 서로 경쟁하며 Generator 네트워크는 discriminator 네트워크를 속이려고 합니다. 그러면 discriminator 네트워크는 새로운 가짜 데이터에 적응합니다. 이 정보는 차례로 Generator 네트워크를 개선하는 데 사용되며, 이런 식으로 학습이 진행됩니다.
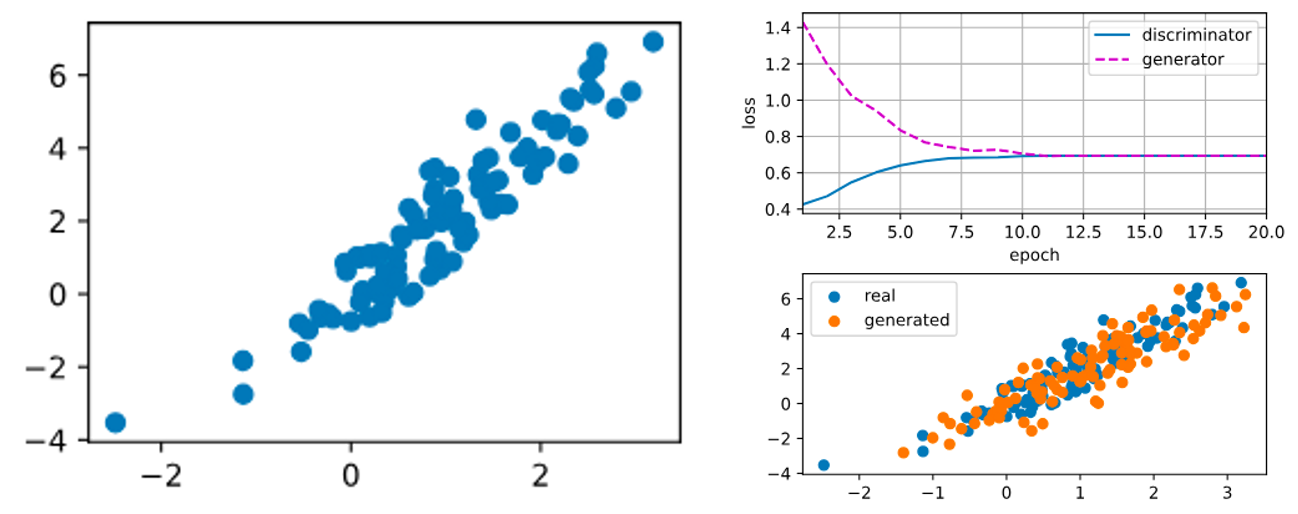
- 생성된 "실제" 데이터를 시각화하고 공분산 행렬을 계산합니다.
- Generator 정의 : Generator는 가장 간단한 형태, 즉 단일 계층의 선형 모델로 구성됩니다. 따라서 이 네트워크는 "완벽하게 가짜 데이터를 생성하는" 방법을 학습해야 합니다. 이는 실제 데이터의 통계적 특성을 가짜 데이터가 잘 반영하도록 학습하는 것을 의미합니다.
- Discriminator 정의 : 3계층의 다층 퍼셉트론(Multi-Layer Perceptron, MLP)을 사용하며, 각 계층은 선형 계층(nn.Linear)와 활성화 함수(nn.Tanh())로 이루어져 있습니다.
- Training : 각각의 네트워크는 이진 로지스틱 회귀를 수행하며, 교차 엔트로피 손실을 사용합니다. 훈련 과정을 안정화하기 위해 Adam 최적화 알고리즘을 사용합니다. 각 반복마다 먼저 판별기를 업데이트한 다음 생성기를 업데이트합니다. 손실과 생성된 예시를 시각화합니다.
(2) Deep Convolutional Generative Adversarial Networks
- GAN을 사용하여 사실적인 이미지를 생성하는 방법을 보여줍니다. 여기서는 Radford 외(2015)에서 소개한 심층 컨볼루션 GAN(DCGAN)을 기반으로 모델을 만들고 discriminative 컴퓨터 비전 문제에서 성공적인 것으로 입증된 컨볼루션 아키텍처를 차용하여 GAN을 통해 사실적인 이미지를 생성하는 데 어떻게 활용할 수 있는지 보여줍니다.
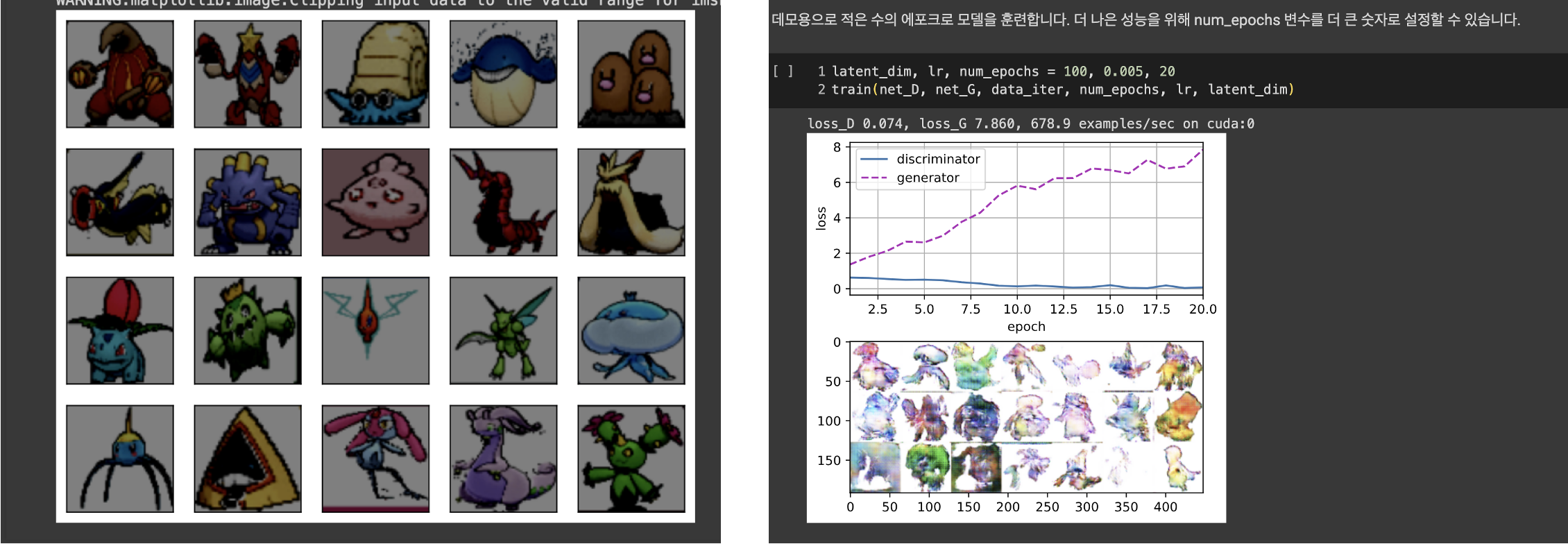
- DCGAN 아키텍처에는 Discriminator를 위한 4개의 컨볼루션 레이어와 Generator를 위한 4개의 "fractionally stride" 컨볼루션 레이어가 있습니다. Discriminator는 일괄 정규화(입력 레이어 제외)와 leaky ReLU 활성화가 있는 4계층 stride 컨볼루션입니다. leaky ReLU는 음수 입력에 대해 0이 아닌 출력을 제공하는 비선형 함수입니다. 이 함수는 '죽어가는 ReLU' 문제를 해결하고 아키텍처를 통해 그래디언트가 더 쉽게 흐르도록 도와줍니다.
개인 발표 내용 : Chapter 11) Attention Mechanisms and Transformers
- 제가 발표한 내용을 아래 링크에 정리해두었습니다.
https://velog.io/@yoru/Dive-into-Deep-Learning-11.-Attention-Mechanisms-and-Transformers
스터디 피드백 내용
- 이론적인 내용을 공부해 보는 것도 좋지만, 현재 상황에서는 코드를 중심으로 공부해 보는 것도 좋은 방법일 것 같다.
- 코드를 중심으로 공부할 때에는 공부한 내용을 완전히 구현할 수 있는 만큼 공부하는 것보다는 데이터셋을 바꿔서 코드를 돌릴 수 있을 정도로 공부하는 것이 효율적일 방법일 수 있다.

!!