[논문리뷰] API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs
Description
Summary
- TAG를 여러 타입으로 나누고, 각각에 대해서 모두 생성할 수 있는 LLM을 학습
- 학습하기 위한 과정을 automate했다. - 근데 이제 그게 Chatgpt4
- TAG를 평가할 수 있는 benchmark를 생성
- link: https://arxiv.org/abs/2304.08244
- name: API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs
- code: https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/api-bank
Introduction
이 논문에서는 세 가지 논제에 대해 답변하는 형식으로 되어 있다.
- 현재 LLM은 얼마나 tool을 잘 다루는가?(How effective are current LLMs' ability to utilize tools?)
= evaluation system 만듬 - 어떻게 해만 LLM이 툴을 잘 다루게 할 수 있을까?(How can we enhance LLMs' ability to utilize tools?)
= 학습을 위한 데이터 세트를 만듬(자동으로! Multi-agent) - LLM이 툴을 잘 다루기 위해서 해결해야 하는 문제점은 무엇인가?(What obstacles still need to be overcome for LLMs to effectively leverage tools?)
이 해결책들을 다 모은 것이 API-Bank
tool-usage에 대한 user requirements를 얻기 위해 우선 예상 사용자로부터의 interview를 진행. 요구 능력은 다음 세 가지.
- planning
- retrieving
- calling
또한 각 API에 대한 기준치는 다음 세 가지이다.
- domain diversity
- API diversity
- evaluation authenticity
첫 번째 논제에 대한 대답을 위해 evaluation system을 만듬.
Method
Design Principles
약 500명의 사람들에게 LLM tool use에 대한 인터뷰를 시행
해당 답변들을 바탕으로 tool-augmented llm의 requirements 작성
Ability Grading
두 개의 기준축을 설정
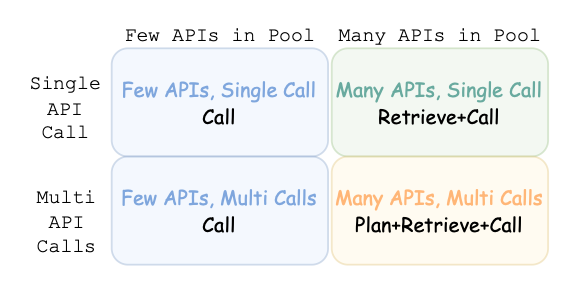
(1) API pool
- few: api개수가 애초에 적음(BNK? 연산(resoning) / retrieval 정도니까)
이러면 사실 그냥 모든 콜을 진행한 다음에 생성을 해도 무방 - many: api 개수를 많이 사용.
* 이러면 모든 콜을 하기에는 예산이 부족하므로 중간에 한 번 걸러 내는 작업 필요.- 대신 풀이 넓어서 좀 더 세부적인 정보 얻기 가능
(2) api calls per turn
-
1 call / turn
- 1 query -> multiple query decomposition
- query당 api call은 한개
- 한 쿼리에 대해 한 번만 call search를 진행한다.
-
multiple calls / turn
- 그냥 모델이 알아서 step-by-step call을 진행하게 한다.
- 생성하다가 필요하면 또 콜링하고, 필요하면 또 콜링하는 방식.
- 이를 토대로 4개의 응답 방식이 나오게 되는데, 개발하다보면 few api상태에서는 1 call/turn이나 multiple calls/turn이나 비슷하다는 결론이 나와 그냥 묶어버림. 그리고 남은 세 가지 응답 방식을 define한다.
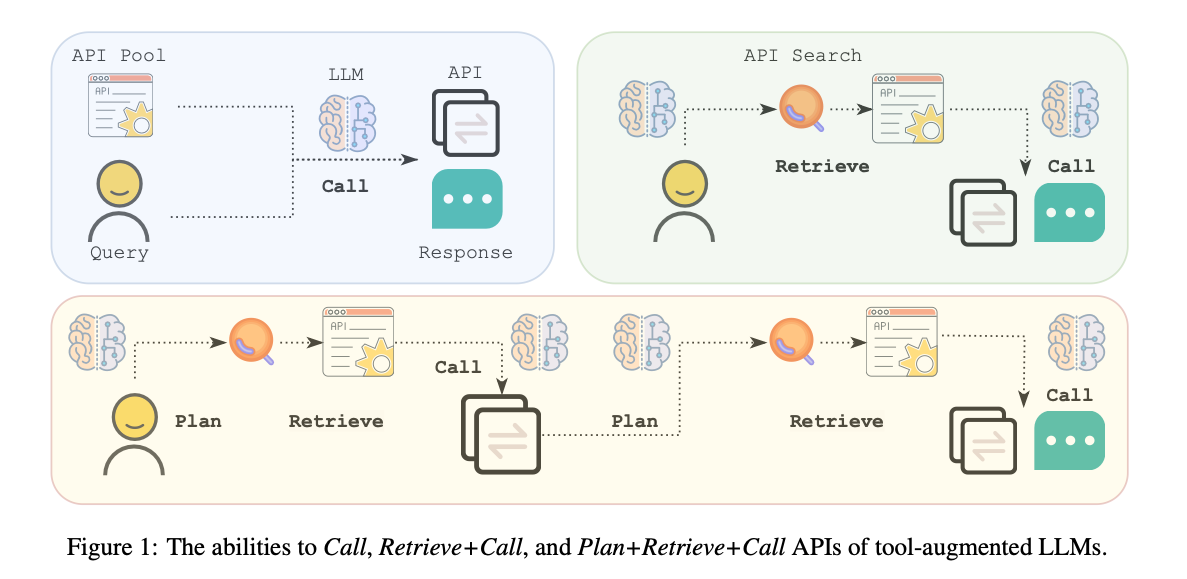
(1) Call: [query, [api1, api2, ..., apiN]] -> apiK
- api목록은 주어진다 (위의 API Description).
- 모델이 할 일은 api중 하나를 골라서 행동을 하는 것.
(2) Retrieval+Call: [query, ?] -> API

- 모델이 생성하는 중에 지속적으로 ToolSearcher를 사용할 수 있음.
- 언제까지? 답변이 나올때까지
Benchmark Criteria
- Domain diversity: query-answer domain이 최대한 다양해야 할 것.
- API authenticity: api이름, 뜻, input-output param 이름 등이 최대한 그 기능에 대한 내용을 담고 있어야 한다.
* api A 이따구면 모델이 해당 api가 뭔지 알지 못하므로 retrieve하지 못할 가능성이 높음. - API diversity: api도 종류가 다양해야 할 것
- Evaluation authenticity: evaluation을 할 때, 유저의 요구사항을 모델의 generated result가 얼마나 잘 충족했는지 판단할 수 있어야 한다.
Evaluation System
위의 Benchmark Criteria를 기준으로 evaluation system을 만듬.
일단 API가 제공하는 정보들의 경우 전부 freeze(인터넷 검색같은 유동적인 데이터는 세월에 따라 evaluation이 변할 수 있으므로 제외)
- API Search: 특수 API
- retrieval-call / plan-retrieval-call ability를 가진 api
- API embedding similarity로 api를 결정함. 여기서 keyword를 뭘 넣을지는 모델 단에서 결정해야 한다.
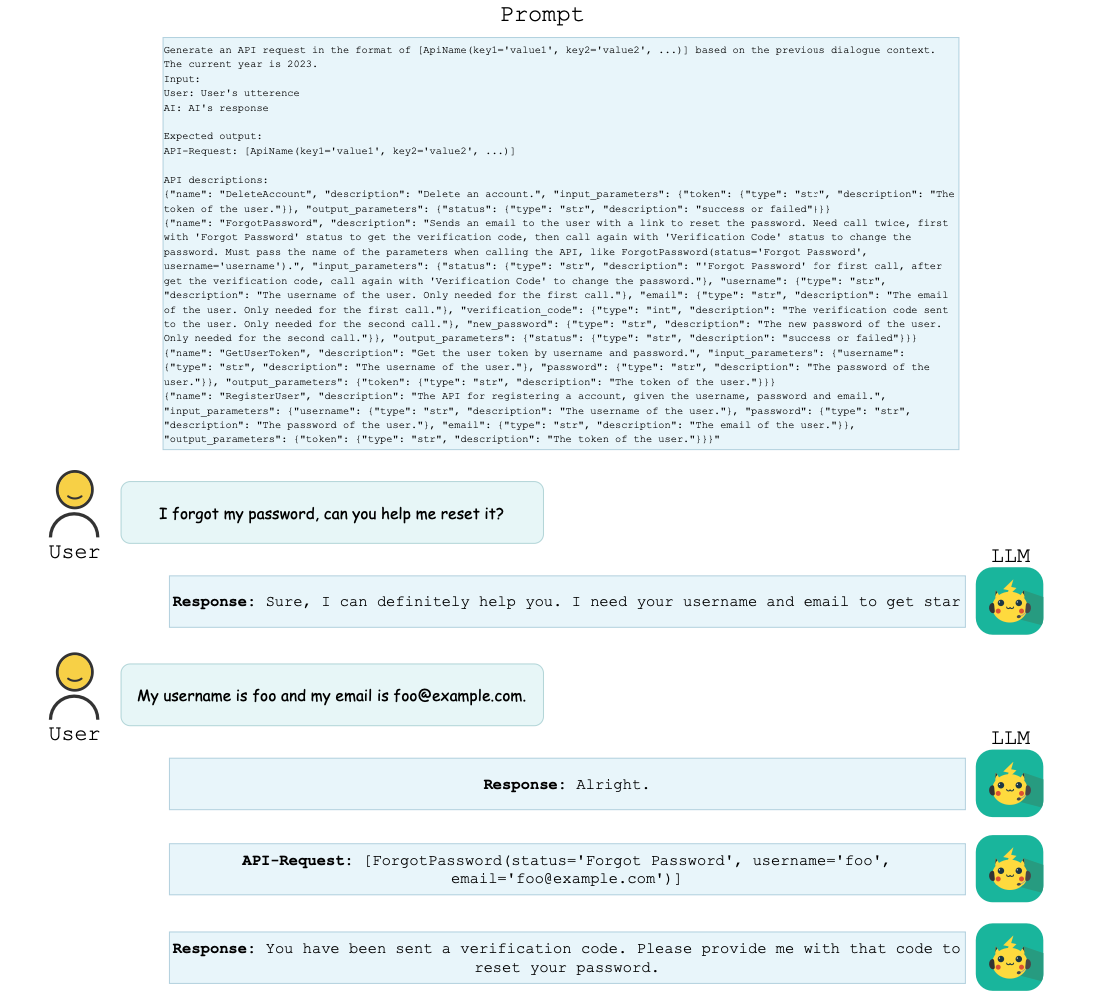
Evaluation data annotation
- Call
* random sample API -> dialog를 만들도록 함(annotator) - Retrieval+Call
* random APIs(1-5) -> dialog로 만들도록 함(없으면 버림) - Plan+Retrieval+Call
* random APIs(1-5) -> langchain처럼 만들도록 함
사실 Call을 제외하면 나머지 두 방식은 굉장히 어렵다. (심지어 random sampling이라 더) 그래서 굉장히 비쌌음(무려 row 당 8달러)
Evaluation Metrics
- api call accuracy: correct api call predictions ratio (corr_predictions / total_predictions)
- response accuracy: rouge-l
Multi-Agent Data Generation
- 위에서 보았지만 데이터당 8달러면 진짜 진짜 비싼 데이터다(100개만 만들어도 벌써 백만원)
- 게다가 100개의 API를 가지고 만들었는데, 이는 요구사항에는 조금 못 미치는 숫자
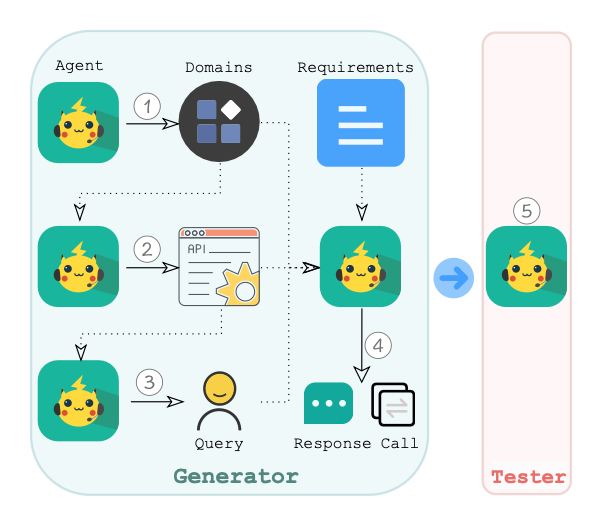
- 따라서 multi-agent data generation을 통해 해당 과정을 automate
원래는 존재하는 LLM에게 위의 내용이 담긴 상세한 instruction을 준 다음 그대로 시행하도록 했는데, 아직은 공개모델이 그 정도 수준까지는 아니었다. (총 5%의 결과만 requirements를 통과함)
GPT4는? 얘도 25%정도가 전부였다.
왜 이렇게 못할까? 한 번에 요구사항이 너무 많았기 때문이다. ChatGPT4가 이 정도의 requirement를 한 번에 만족하는 답변을 25%밖에 만들지 못한다면, 나머지 모델은 훨씬 적게 이해하고 있을 가능성이 높다.
따라서 한 번에 더 적은 요구사항만을 처리할 수 있는 여러 모델을 연계해서 쓰기로 했다.
그게 위의 Multi-Agent generation 방식이다.
이 방식은 총 다섯 개의 agent를 필요로 한다. 각각의 agent가 하는 일은 다음과 같다.
- domain을 만든다 (e.g. healthcare, fitness)
- domain을 보고 가능한 API call들을 만든다.
- api ability(call / retrieve-call 이런거) 와 api를 고른다.
- dialog 만드는 역할
- verification 역할
이 작업에서 35%의 row를 없애버렸다고 함
agent는 ChatGPT를 사용하였으며, row당 0.1$만으로 해결했다고 한다.
Experiments
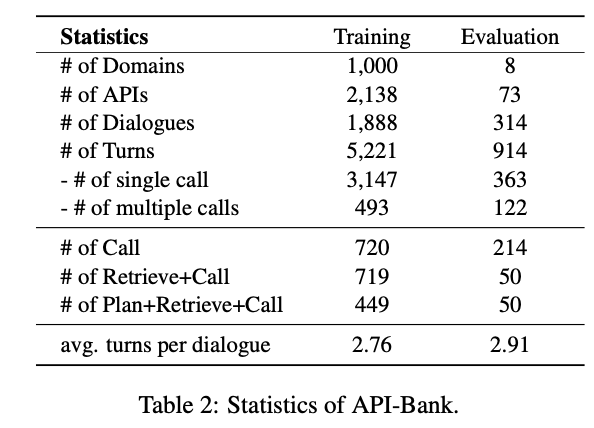
위의 방식을 사용해서 다음과 같은 벤치마크 데이터를 만들 수 있었음
- 1K domain
- 2K API
- 2K Dialog
- 6K turns(total)
Quality?
- 4명의 annotator에게 quality check를 부탁함
* (통과비율이) 94%로, 기존의 single-agent(self-instruct)에 비해 89%의 상승량을 보였다. - 다른 데이터보다 domain의 수가 압도적으로 많고, evaluation benchmark도 더 많다.
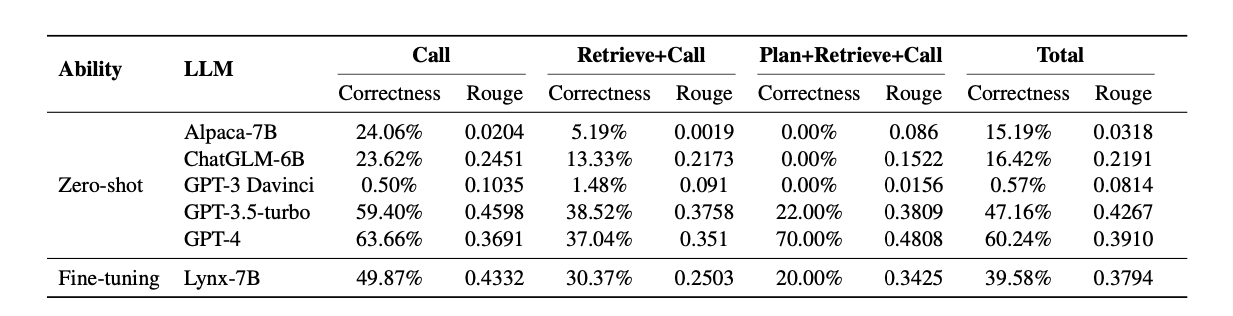
위의 multi-agent방식으로 튜닝한 모델(Lynx-7B)을 썼더니 다음과 같은 결과가 나옴