[논문리뷰] LongLLaMA: Focused Transformer Training for Context Scaling
0
Description
Summary
- 자른 다음에 attention을 합친다.
- context에 없는 경우 negative token으로 간주한다.
- name: LongLLaMA: Focused Transformer Training for Context Scaling
- code: https://github.com/CStanKonrad/long_llama
- training - easyLM based :sob:
- inference - HF OK
Introduction
모델의 입력을 늘이는 방법에 대한 연구이다. 이 논문에서는 모델의 입력을 늘렸을 때 생기는 가장 큰 문제점을 distraction issue라고 가정하고, 이를 해결하는 방법을 제시하고 있다.
Distraction Issue
- document의 사이즈가 증가할수록, 문제 해결을 위한 중요한 토큰 / 중요하지 않은 토큰의 비가 급격히 줄어든다.
- 기존 학습법에서는 중요하지 않은 값들과 중요한 값들과 연결된 키들이 겹치는 경우가 많다. 이렇게 되면 모델이 해당 값들을 더 구분하기 어려워진다.
Proposed Method
contrastive learning
- query와의 관련성을 positive / negative로 두면 contrastive learning과 비슷한 objective를 지니게 된다.
- knn을 통해 (K, V)쌍을 줄여서 attention 연산을 할 수 있게 함.
Methods
Focused Transformer(FoT)는 크게 두 가지로 이루어져 있다.
memory attention layer는 effective expansion에 관여한다.
CrossBatch training은 모델이 (k, v)에 대해 더 잘 배우도록 돕는다.
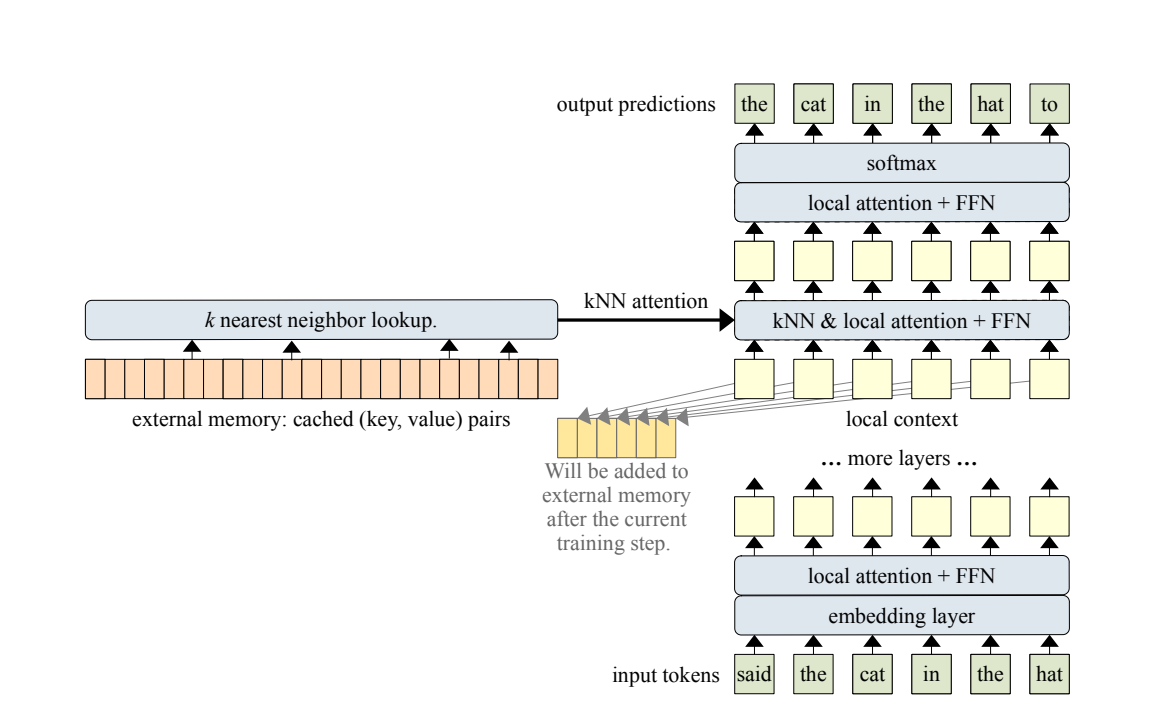
Memory Attention Layer
memorizing-transformers.md (ICLR 22, spotlight) 라는 논문에서 주로 아이디어를 가져왔다고 한다.
- 각 레이어의 query가 가장 잘 매치된 top-k key를 가져온다.
- 가져오는 방식이 kNN (FAISS꺼를 가져왔다)
- memorizing-transformers.md와 다른 점이라고 한다면 MT에서는 두 attention을 더할 때 gating network를 사용했는데, FoT에서는 gating을 사용하지 않고 전부 동등한 attention 취급을 했다(그냥 더해서 attention연산에 넣어버림)
CrossBatch
- crossbatch를 바로 생각했다기보다는 contrastive learning을 llm식으로 적용하기 위해 해당 기법을 사용했다는 것이 맞다.
- contrastive learning에서 positive sample의 개념을 '현재 컨텍스트'로 잡고, negative sample의 개념을 '현재 컨텍스트가 아닌 다른 컨텍스트'로 잡았다. 따라서 관련있는 / 없는 정보가 섞인 사이에서 instruction에 따를 수 있도록 하는 것이 목표. contrasitve learning 자체를 쓰지는 않은 것으로 보인다.
Discussion
- inference에도 통하지 않을까? 하는 희망. MT는 인퍼런스 때에 했으니까!
- 긴 데이터가 필요가 없었다고 했다. crossbatch때문에 필요가 없었던 것 같다. 긴 데이터 구축이 어려운 한국어의 경우에 괜찮을 느낌

NLP / LLM