[논문리뷰] Better & Faster Large Language Models via Multi-token Prediction
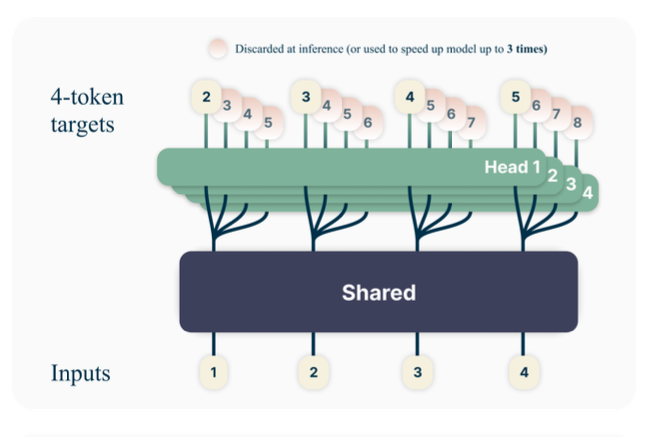
이 논문에서는 한 번에 여러 토큰을 생성하게 해서 모델이 로컬 패턴을 더 잘 볼 수 있게 함과 동시에 생성 가속화를 할 수 있게 한다.
기존의 메두사와 상당히 유사한데, 메두사에 있던 tree-based attention을 없애고 더 간단하게 구현되었으며, 생성 코스트도 감소시킨 모델.
원래 로스가 이거라면,
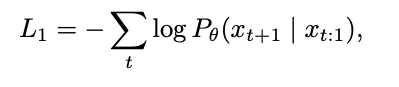
멀티 토큰을 만들기 때문에
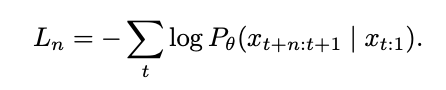
이렇게 바뀌게 된다. 여기서 헤드가 많아지면서 발생하는 메모리 오버헤드를 방지하기 위해 다음과 같은 트릭을 쓴다.
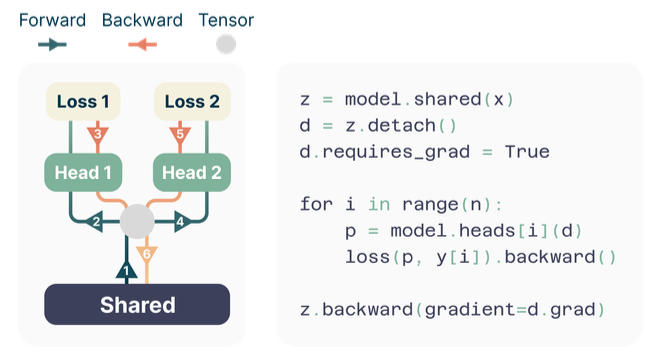
이렇게 순차적으로 업데이트하는 것. shared, 공통 부분은 기존 TF부분이고, 원래 모델의 lm head(linear layer)가 늘어나는 형태로 구현된다.
코드 단에서는 성능 향상이 많았는데, lm평가에서는 좋지 못했다(근데 nlu평가에 가까워서 딱히 생성능력과 큰 연관은 없다). 그래도 생성형 태스크인 요약쪽에서는 나름 조그만 성능 향상이 있었다.
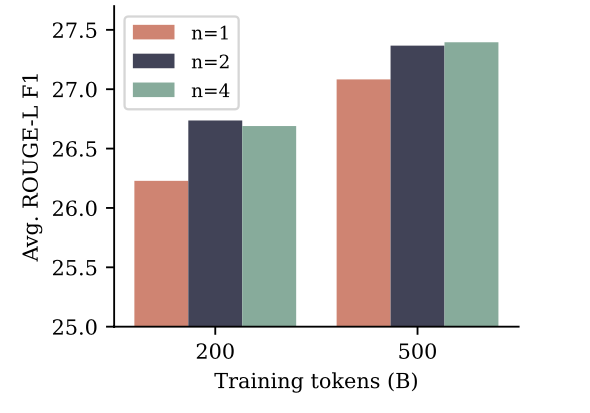
모델이 클수록 효과가 좋은 모양
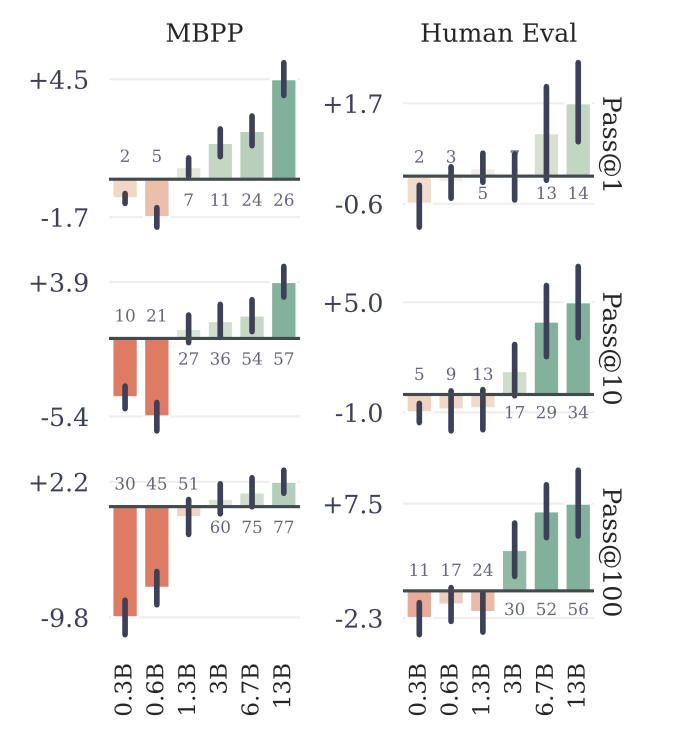
평가가 코드쪽에 치중된 느낌이라 조금 아쉽다.

NLP / LLM