[논문리뷰] PROVING TEST SET CONTAMINATION IN BLACK BOX LANGUAGE MODELS
Introduction
Data Contamination
- data contamination: 학습데이터에 테스트 데이터가 꼈음
- LLM의 경우 수없이 많은 공개데이터를 가지고 학습을 한다(특히 PLM때). 보통 테스트 데이터는 학습에 쓰지 않는 것이 정석이지만, PLM같은 경우 최대한 그 언어에 대한 정보를 많이 넣어야 하기 때문에 공개데이터를 전부 끌어다 쓰게 된다. 이 과정에서 테스트 데이터가 들어갔을 수도 있음!!!
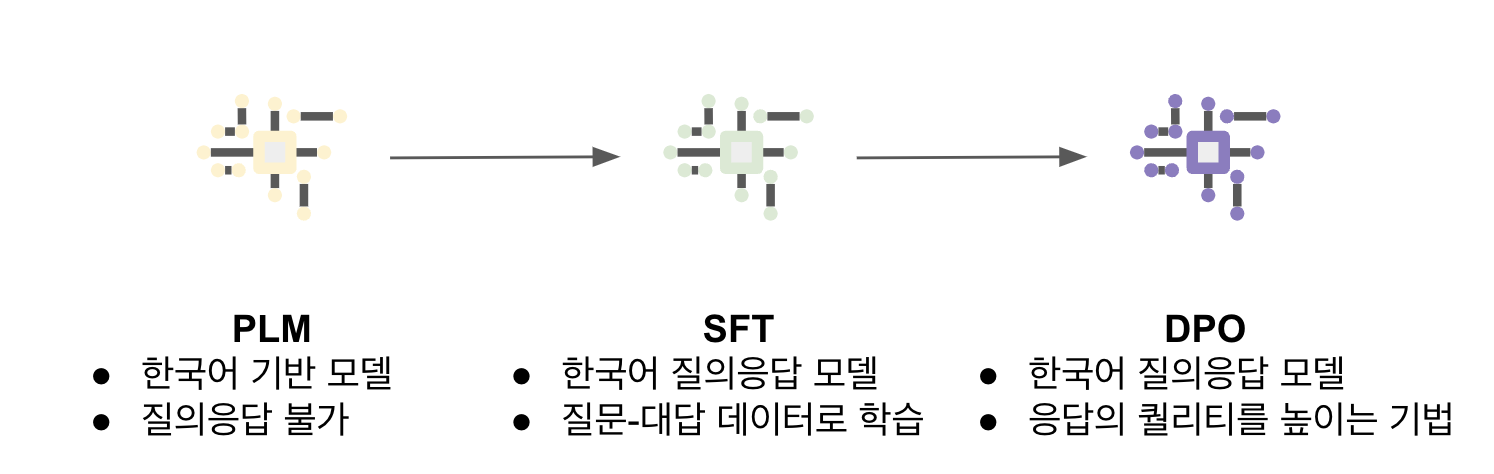
저는 학습할 때 테스트 데이터는 빼고 썼는데요? -> 원래 언어모델 학습 과정은 다음과 같이 진행되는데, SFT나 DPO에서 테스트 데이터를 쓰지 않더라도 PLM에서 학습데이터가 들어갔을 가능성이 있다. 내 모델이 '잘 하는건지' '잘 아는건지'를 구분하기 위해서라도 contamination 여부를 보는 것은 중요하다.
지금까지의 논문에서는 리버스 엔지니어링(reverse engineering) 개념으로 주로 contamination을 측정했는데, 예를 들어 테스트 셋에 대해 큰 logprob을 가지면 당신은 contaminated! 와 같은 기법이다.
문제는 확실하게 증거로 내밀 수가 없다는 것 - 휴리스틱한 메소드가 대부분이기 때문에 다음과 같은 질문이 나올 수 있다.
- logprob이 얼마나 차이 나야 contaminated인가?
- 해당 샘플과 유사한 다른 샘플과 학습해서 저렇게 나왔을 수도 있는데?
따라서 저자는 이러한 contamination을 측정할 수 있는 테스트를 준비하고, 이것이 통계적으로 유의미한 결과임을 말한다.
Method
이 테스트를 만들기 위해서 한 가지 가정이 필요하다.
모든 테스트 데이터는 exchangable하다.
exchangability란 데이터의 순서를 서로 바꾸어도 같은 distribution을 갖는다는 말이다. 여기서 같은 distribution에 속해 있다는 것은, 예를 들어서 순서를 바꿔서 inference를 한다고 해도 그 데이터가 가지는 hidden state가 변하면 안된다는 것이다.
그리고 저자의 아이디어는 만약에 모델이 해당 데이터로 학습이 되었다면, 순서를 바꾸게 되면 전체 sequence의 logprob 정도가 차이가 날 것이다 - 로 시작한다. 여기서 순서가 바뀌지 않은 시퀀스를 라고 하자. 순서가 바뀐 시퀀스(들)은 로 표기한다.
그럼 얼마나 차이가 나야 하나요? 여기서 one-sided t-test를 시작한다.
쉽게 말해서 정규분포를 가지는 어떤 B에 대해서, a값이 나왔는데 이게 B의 분포에 속하는 게 맞나요? 에 대한 테스트이다. one-sided라는 것은 a값이 B분포보다 큰 게 맞나요(혹은 작은 게 맞나요)
그러면 뭐가 정규분포일까요~ 바로 의 logprob이 보다 작을 확률이다. exchangability의 정의에 따라 학습되지 않은 데이터에 대해서 모델은 유사한 logprob을 보여야 하기 떄문.
물론 모든 시퀀스에 대해서 진행할 수 없다. 테스트 개수가 1000개면 1000개의 permutation에 대해서 실험할 수는 없으니까~~ 그래서 대신 랜덤하게 특정 수만큼 샘플링을 해 와서 작은 표본에 대해서 검정을 시행한다. m+1이 되는 이유는 finite-sample correction을 진행해 줘서.
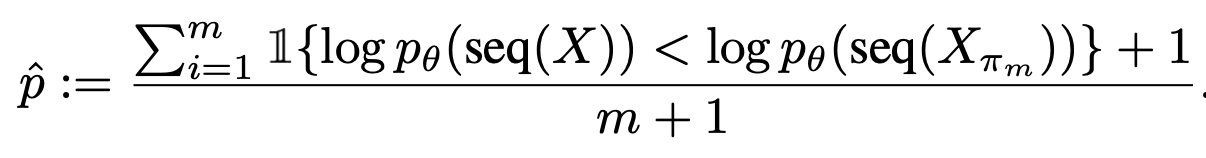
이제 표본(m)들에 대해서 logprob을 구한 다음에 p값을 구했더니 0.05보다 작네요? -> 당신은 정상분포에 들어가있지 않습니다~~ 로 통계적으로 검정이 가능해졌다.
Sharded Likelihood Comparison Test
위의 테스트를 편의상 naive permutation test라고 부르기로 하자. 여기서의 문제점은?
m수가 작으면 단순 permutation을 해도 되지만, m수가 크다면 또 한 가지 문제점이 있다. 우리 모델은 챗지피티가 아니기 때문에 안타깝게도 20샷도 넘기기 힘들다. 그 와중에 저 logprob을 계산하기 위해서는 1000샷을 해야 하는데, 절대로 불가.
따라서 우회하기 위해 택한 것이 sharded comparison test이다.
우선 를 k개의 작은 shard로 나눈다. 그리고 각각의 shard에 대해 동일하게 연산한다. shard 안의 row수가 5라고 치면 맥시멈 고작 정도의 추가 permutation이 생긴다.
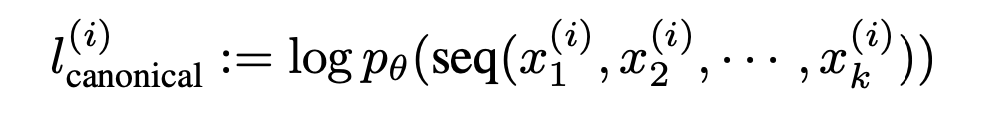
그리고 비교할 연산을 다음과 같이 바꾼다.

각 shard의 logprob 차이를 더한 것을 다시 로 두면 동일하게 다시 test가 가능해진다.

Experiments
이 방법을 검증하기 위해서(+p threshold를 정하려고) 간단하게 학습을 통해 진행했다.
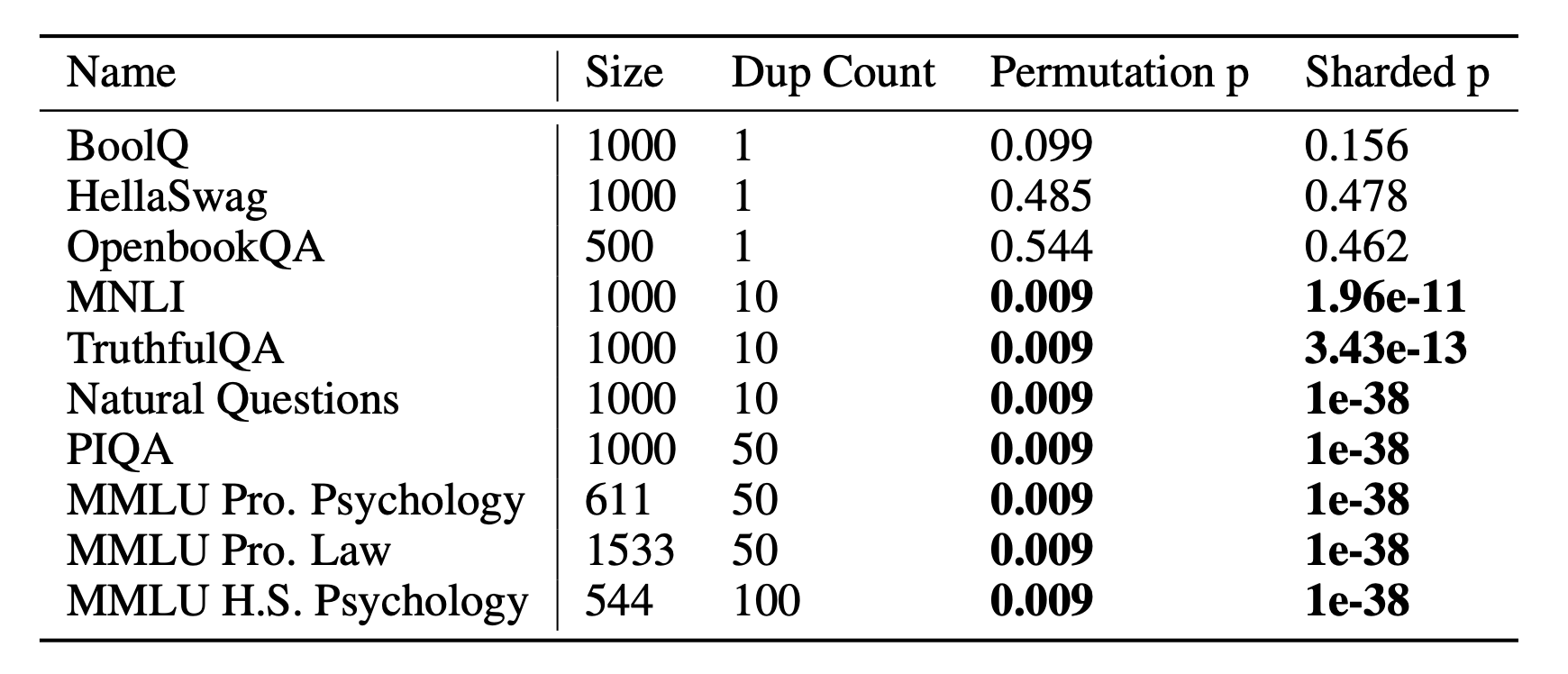
(전부 다 넣어서 한 번에 학습함)
이걸 보면 약간 애매한게 학습 때 이 데이터를 10번 넘게 넣었다는 말인데... 살짝 신뢰도를 잃었다.
여기서도 1에서는 발견하지 못했다고 슬퍼하는 저자들이 있는데, 원래 contamination 논문들에서 기본적으로 10번 이상 데이터를 봤을 떄 패턴 말고 데이터 자체를 외운다는 결과가 자주 나와서 넘어갔다.
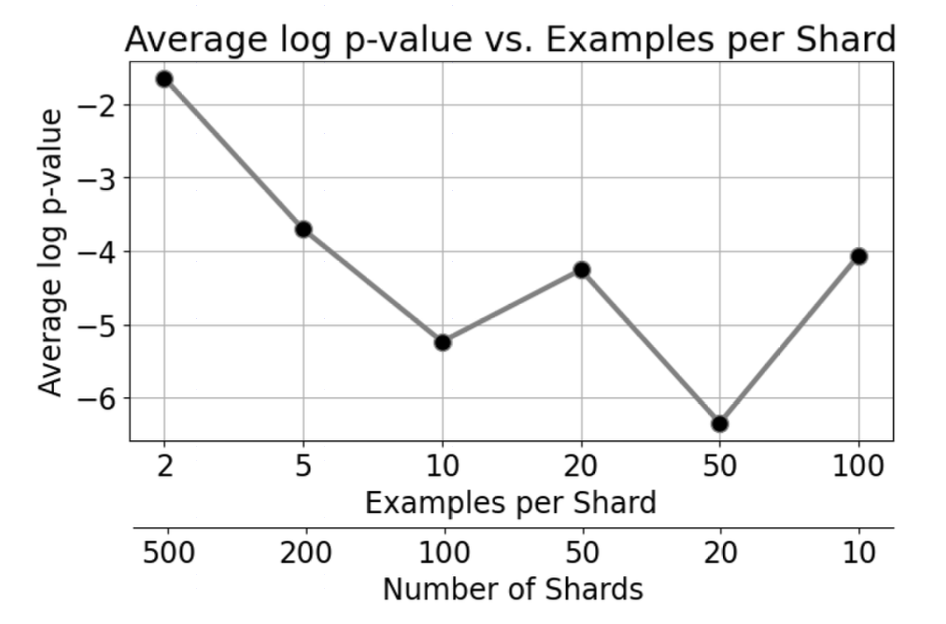
위 이미지는 contamination없는 모델에 대해서 실험해서 적절한 샤드 버켓 사이즈를 알이보기 위한 것이다. 샤드 수가 너무 작으면 검정에 의미가 없으니 최소 10개 이상은 놔라.
마지막으로 실험의 꽃인 공개모델
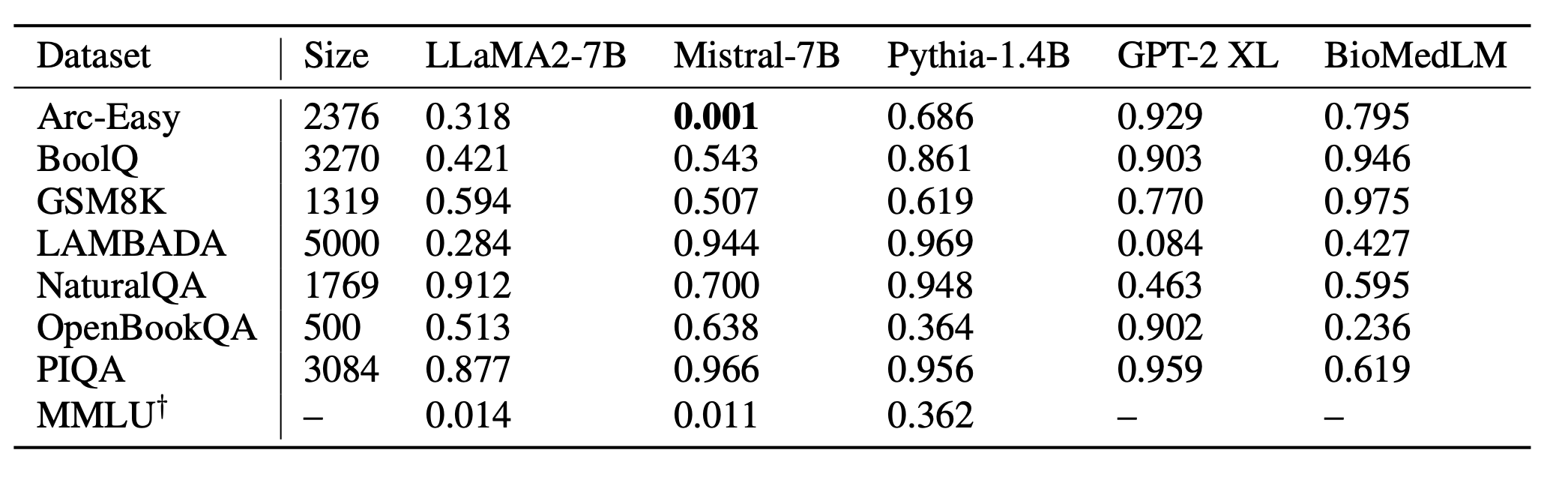
유효숫자를 0.005로 해뒀다. 미스트랄은 Arc-Easy를 썼구나!라고 의심해 볼 수 있다고 한다.
