[논문리뷰] LongLoRA: EFFICIENT FINE-TUNING OF LONG- CONTEXT LARGE LANGUAGE MODELS
Description
Summary
- 긴 context에 대고 학습을 할 수 있게 해준다.
- shift sliding attention을 통해 학습이 가능하게 한다.
- LoRA를 사용했다. 이 때 embedding & normalization 꼭 해줌
- perplexity가 길이가 늘어나도 비교적 안정적으로 유지된다.
Introduction
- llm의 context를 늘리고 싶다.
- 2K -> 4K로 늘리는 데 드는 computation cost는 16배.
- efficient하면서도 input길이를 늘릴 수 있는 방법이 필요함.
- FT할 때 조금 적은 parameter만을 변화시키고 싶다.
- LoRA 및 다양한 parameter-efficient tuning기법이 소개되어 있음.
Method
Pilot Study
- 어떤 attention 방식을 써야 길이를 늘리면서도 perplexity를 유지하는가?
우선 다른 논문들과 비슷하게 긴 길이의 context를 여러 그룹으로 나눈 뒤, attention을 적용하는 방식을 쓴다. 이렇게 되면 한 임베딩이 찾게 되는 다른 임베딩의 크기가 현저히 줄어들기 때문에 연산량이 확 줄어든다.
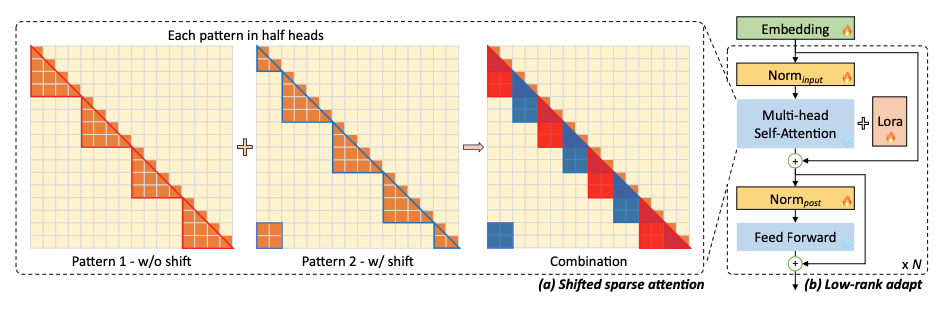
오렌지색 부분이 activate되는 범위를 나타낸다. 그룹 간 attention이 수행되기 때문에, '보는 부분'만 계속 보게 된다. 이건 성능 하락으로 이어진다.

간단한 실험을 통해 확인한 결과. Full Attn의 경우 길이가 길더라도 모든 토큰을 다 보기 때문에 perplexity 값이 일관되어 있지만, Short Attn(위 위 그림에서 w/o shift)의 경우 보지 않는 토큰들이 영향을 크게 미쳐 perplexity 값이 올라가게 된다(낮을수록 좋음)
따라서 생각한 방식이 shift(위 위 그림에서 w/ shift)인데, 각 그룹마다 겹치는 부분이 존재하게 하는 것이다. 저자들은 head의 반은 기존의 non-shift, 나머지 head는 shift를 써서 연산하도록 했다. 이렇게 했더니 perplexity값이 일관되게 나타나는 것을 볼 수 있다.
Implementation
코드 자체는 간단하게 되어 있다. 헤드를 반으로 가른 뒤, 반쪽 헤드는 shift를 하여 sparse attention을 계산한다.
# B: batch size; S: sequence length or number of tokens; G: group size;
# H: number of attention heads; D: dimension of each attention head
# qkv in shape (B, N, 3, H, D), projected queries, keys, and values
# Key line 1: split qkv on H into 2 chunks, and shift G/2 on N
qkv = cat((qkv.chunk(2, 3)[0], qkv.chunk(2, 3)[1].roll(-G/2, 1)), 3).view(B*N/G,G,3,H,D)
# standard self-attention function
out = self_attn(qkv)
# out in shape (B, N, H, D)
# Key line 2: split out on H into 2 chunks, and then roll back G/2 on N
out = cat((out.chunk(2, 2)[0], out.chunk(2, 2)[1].roll(G/2, 1)), 2)첫 줄이 가장 핵심 부분으로, Head(dim=3)을 반으로 가른 다음 roll을 통해 shift를 해 준다. 그 다음 그룹 단위 attention을 시행하면 끝.
이 때 학습은 LoRA를 사용한다. 이 기법을 통해 8개의 80GB A100으로 llama 7B -> 100K 입력 학습이 가능하게 했다.
Experiments
모델은 총 세 가지, 7B / 13B / 70B를 사용했다. max_length는 모델별로 각각 100K, 65K, 32K를 최대한으로 늘려 사용했다.
아무래도 생성모델이다보니 그냥 perplexity를 기준 metric을 잡은 느낌.

Ablation Study: 다른 어텐션 기법과의 비교

어텐션 기법들을 가시화하면 다음과 같다.
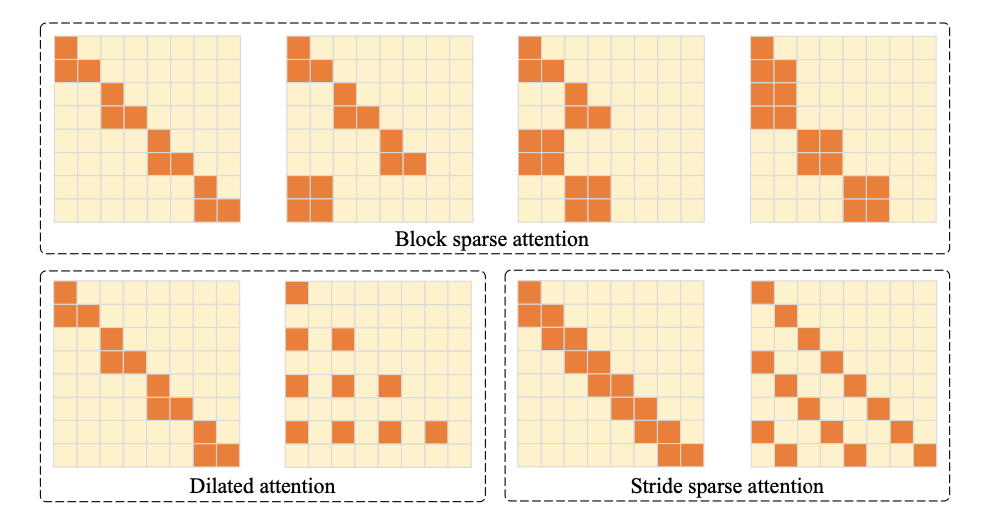
우리 어텐션이 가장 perplexity에서 좋았다.
이게 어디를 반 가를지 선택할 수 있는데, head를 반으로 갈랐을 때가 가장 좋아서 head를 반으로 가르기로 결정.
Ablation Study: 어떤 레이어를 학습시킬까?
LoRA의 측면에서 진행한 실험.
무조건 normalization을 해야 하고 임베딩은 무조건 학습에 넣어야 합니다.

Discussion
학습할 때 배치를 엄청 넣을 수 있겠다!는 희망
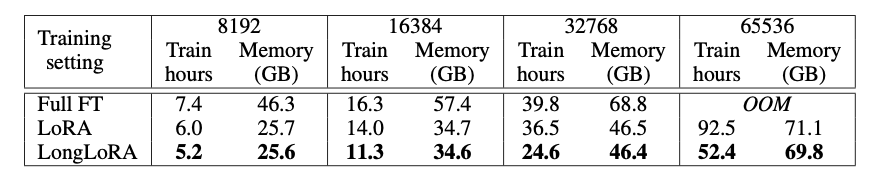
LongAlpaca라는 데이터를 얻었는데, prompt가 일관되어 있기는 해서 robustness에는 문제가 있을 수 있다. generalization 측면에서 데이터는 롱라마의 데이터를 쓰는 게 더 나을 것 같기도
실제 구현은 transformer 모듈을 직접 교체한 후 모델 init때 교체한 모듈로 바꿔치기해서 initialize하는 방식이라 내부가 조금 애매하다. 일단은 inference에도 돌아가기는 하나 잘 되지는 않는다.
