Memorizing Transformers
Description
Summary
- large context -> split into smaller ones
- 각각의 local context에 대하여 attention을 계산, memory cache에 대해서도 kNN을 써서 attention 병합
- ICLR 22 spotlight
Introduction
- attention은 일종의 lookup 과정으로 볼 수 있다.
- 이 lookup과정에서 좀 더 넓은 범위를 보게 하기 위해 kNN을 써보겠다.
Methods
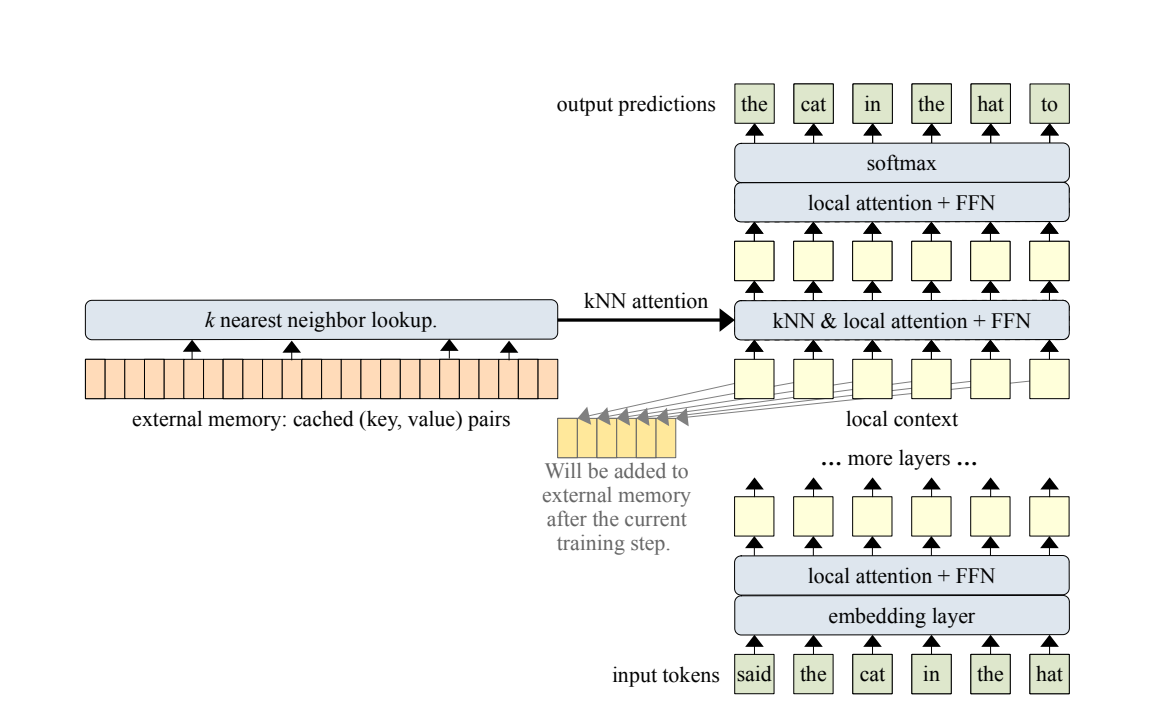
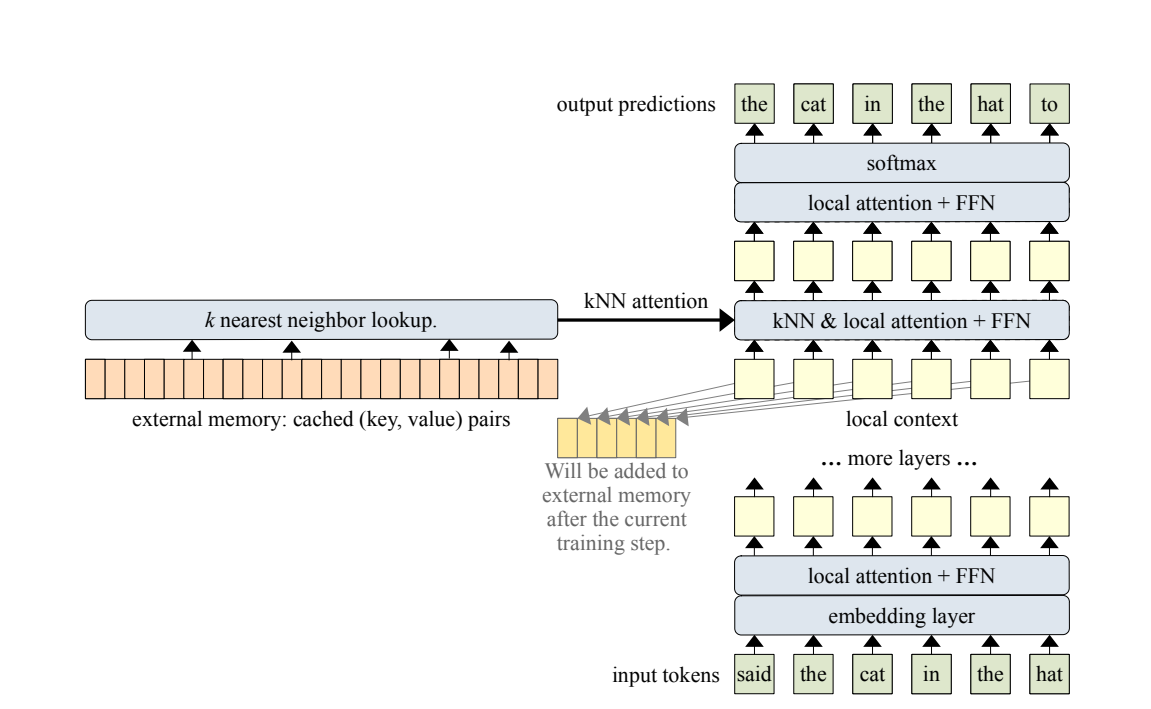
- cache를 사용해서 이전 스텝에서의 k v 값을 저장해 둔 다음 사용한다. 이거는 Transformer XL스타일에서 따온 것이라고 함.
- sliding-window causal mask를 함께 사용했다고 함.
kNN-Augmented Attention Layer
2개 attention의 결합 형태로 되어있다.
- standard dense self-attention(=local context(현재 input값)에 대하여 진행한 attention)
- external memory(cache)에 대한 kNN 서치 값(key, value)값
결합 자체는 learned gate로 더해진다.

NLP / LLM