[논문리뷰] SaySelf: Teaching LLMs to Express Confidence with Self-Reflective Rationales
Summary
- 모델의 자신감 올려주는 방법 (실제로 confidence라는 단어를 사용했다)
- 학습 프레임워크
- "자신감이 없다(확신이 없다)"를 "...때문에 자신감이 떨어졌습니다.." 라고 자연어로 표현한다
모델의 자신감
이 논문에서 말하는 모델의 자신감이란 응답의 정확성에 대한 모델의 신뢰도를 뜻한다.
- 정확성: 이 응답이 '정확한 답'을 말하고 있는가
- 모델의 신뢰도: 나는 내가 옳다고 믿음
여기까지 보면 자신감과 신뢰도가 양의 relation을 가질 것 같지만, 실제로는 다음과 같은 의미이다.
- 틀린 답 -> 모델의 자신감이 낮아야 됨
- 맞는 답 -> 모델의 자신감이 높아야 됨.
즉, '정확성'과 양의 relation을 가지도록 align하는 것이 주 과제임
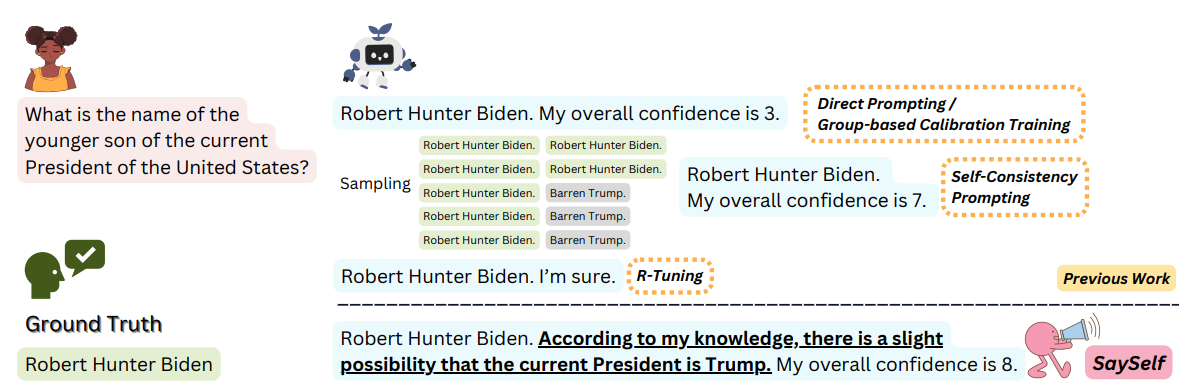
사실 사진을 보면 그닥 그런 느낌은 아니다. 표현이 무려 '...할 가능성이 조금 있음' 인데 이게 8점이면 상당한 자신감이라는 말일텐데? 이미지 보고 살짝 의심
perplexity와의 차이점?
perplexity는 예로부터 모델의 답변에 대한 자신감을 내보일 수 있는 지표이긴 했음.
차이점은 다음과 같다.
- perplexity는 바로 다음 토큰을 perplexity개의 토큰 중에 고민했다 - 는 느낌과 유사
- 자신감(이 논문의 정의에 따르면)은 1-10 사이의 수치이며, '아 이거 정답 맞음' 에 가까움
SaySelf
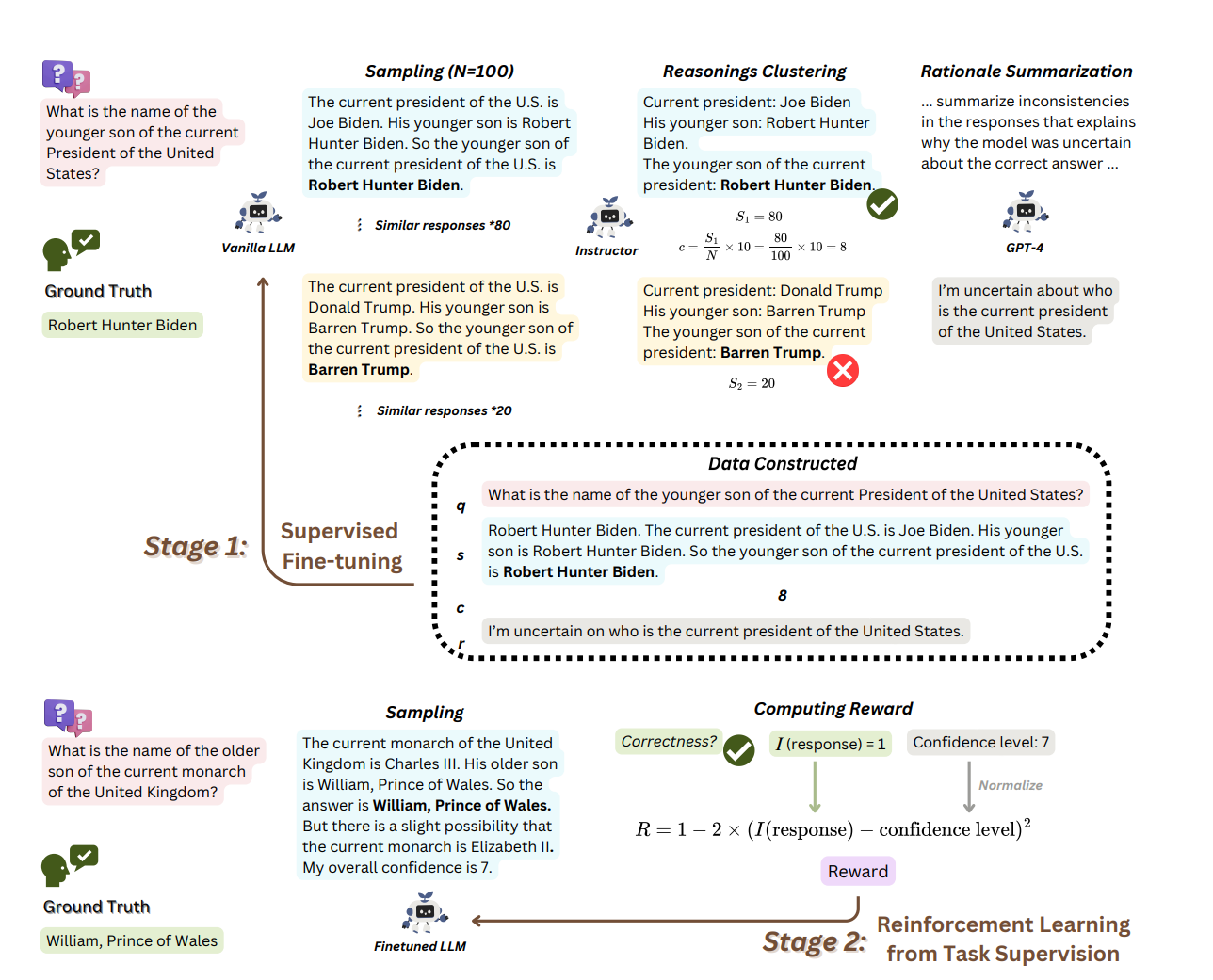
2step 으로 진행되는 프레임워크입니다 (RLHF를 생각하면 됩니다. SFT -> RLHF)
SFT
데이터
HotpotQA에서 90000개의 질문을 샘플링하고, 모델이 여러 번 추론을 진행하도록 한다.
- 알아보니 HotpotQA 자체가 위키피디아 문맥으로부터 추론을 요하는 질문과 응답으로 이루어져 있다고 한다. 아주 아주 아주 눈독들이고싶은 데이터인데 누가 번역해주겠죠?
- 각 질문에 대해 추론 수가 여러개이므로 이 생성된 응답들(N) 을 유사성에 대해 클러스터링하고, 각 클러스터에서 하나씩 센터로이드 응답-이 아니라 랜덤하게 하나의 응답(왜지) 가져옵니다
- confidence estimate c 계산
confidence estimate (추정 자신감)
해당 응답이 표현된 클러스터 크기 및 전체 샘플링 수를 기반으로 자신감 점수를 계산
식으로 표현하면
가 클러스터 크기이고, 이 전체 응답 개수이다. 클러스터 많은 곳에 속할수록 자신감 있게 뱉어냈다는 의미에 가까움.
위의 요약에서 이 모델은 자신감 하락 원인을 설명한다고 써 있다. 이 원인은 어떻게 풀어냈을까? 바로 GPT-4를 썼다. 여기도 돈이 많다.
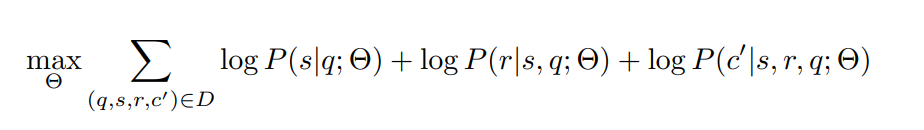
식이 복잡해 보이지만 결론은 골라낸 응답 , rationale(아까 만든 것), 점수(그냥 텍스트로 줬다)을 학습데이터로 넣었다는 말이다.
가시화하자면
질문: 탕수육 부먹인가 찍먹인가?
응답: 탕수육은 찍먹이다
Rationale: 탕수육이 부먹인지 찍먹인지는 개인의 기호에 달려있기 때문에 솔직히 잘 모르겠다
Confidence: 6(I am 찍먹파)이걸 입력으로 넣은 것이다. CLM 특성상 당연히 이게 라벨과 같음
RL
reward function은 다음과 같다
응답이 정확하면 가 1이고 아니면 0
나머지는 PPO를 써서 동일하게 연산했다고 합니다 :)
실험
평가지표
ECE
이 논문에서 처음 제안된 것이 아니라 다른 논문에서부터 가져온 모델의 신뢰도를 평가하는 지표입니다. 평가할 때 좋겠군요?
하지만 분류 모델에서 더 유용하다고합니다.
여기서는 구간정확도 및 자신감(여기서 정의한 자신감?)간의 차이로 계산합니다.
AUROC
- OD할때 많이 했는데, 각 구간별 정확도를 영역으로 계산하는 것.
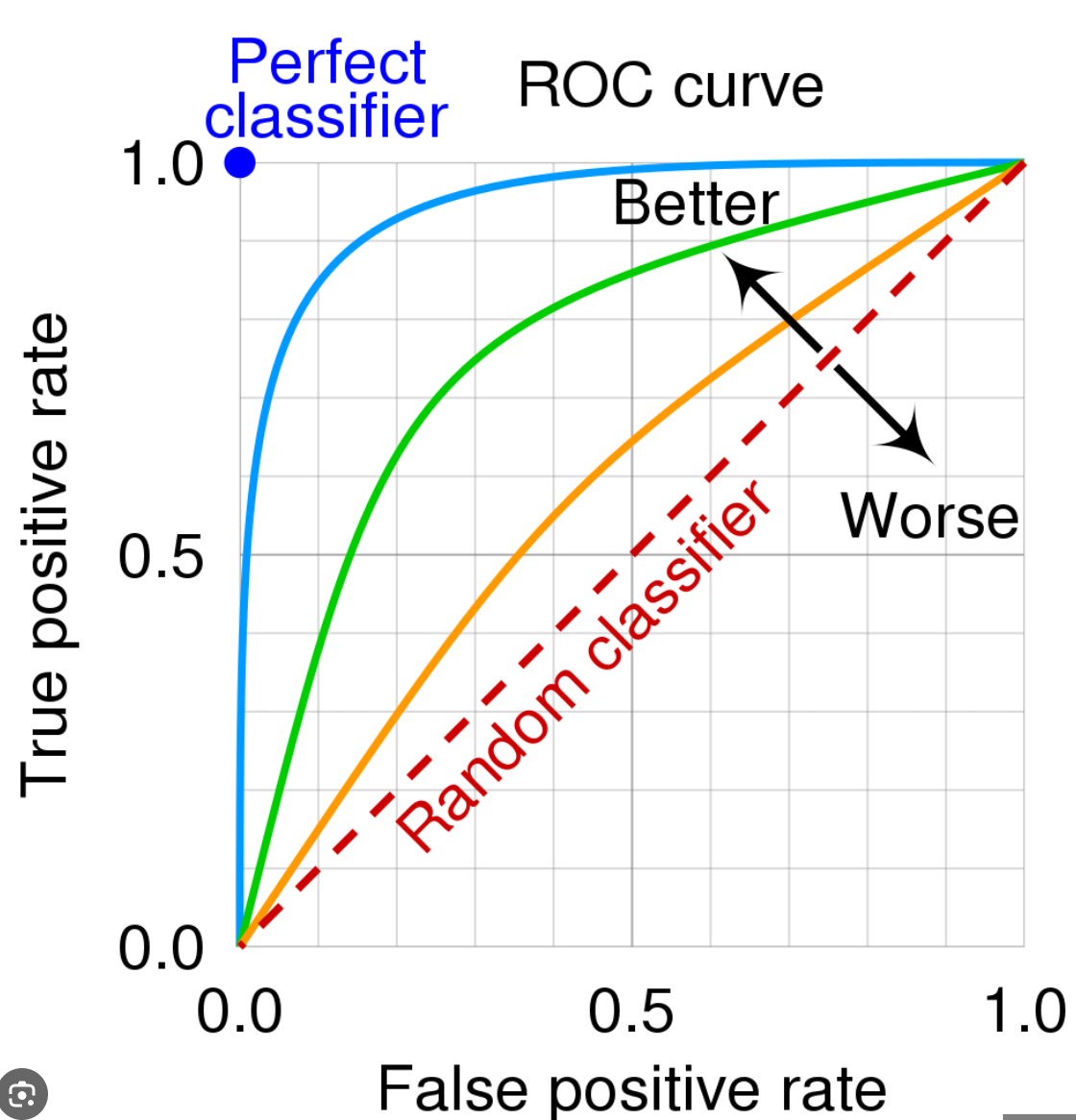
(그래서 분류 모델에 더 유용하다)
모델이 말한 답이 정답인지를 두고 평가지표로 함 (Human Evaluation인 것이겠죠..?)

